






基础认知
关于SFT这个称呼,也就是所谓的有监督的微调(supervised fine-tuning),通常会被大家第一直觉定位到prompt+generation的范式,形式基本如LLM构建的第二个指令对⻬阶段所描述:
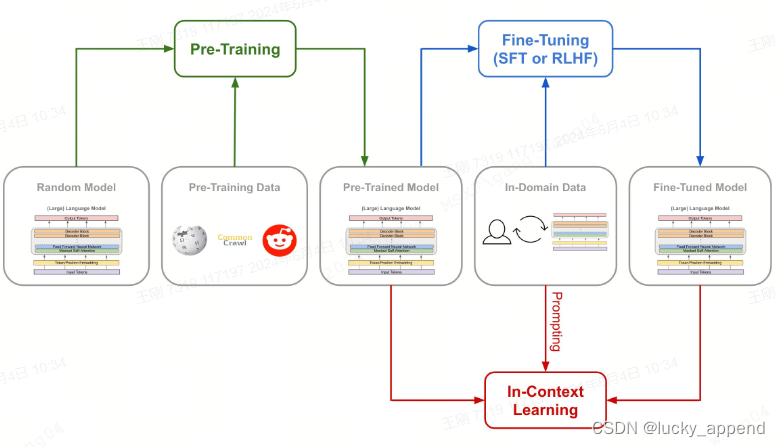
明明在 RLHF 阶段,训练同样也是 supervised 的,而为什么偏偏在二阶段要强调这个词。大抵的由来,笔者认为源自于Google的T5模型之后,NLP任务的范式开始转向由 prompt+generation 统一,往后的一系列工作包括Zero-shot、Few-shot或者COT等都在试图利用这种新的范式更好的完成下游任务。
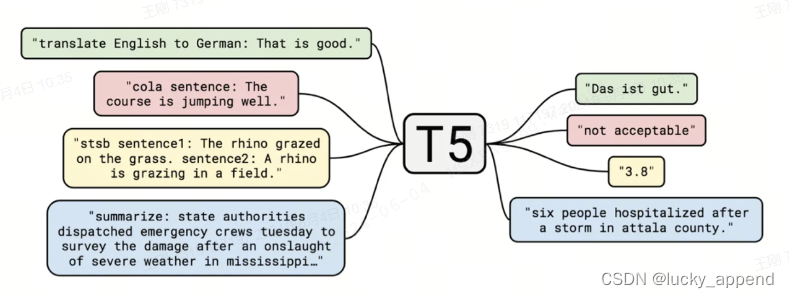
但是事与愿违,很多时候我们的基座模型并无法仅通过prompt的方式就完美得做好下游任务。这时候需要增加一些 supervised data 来进行微调。
我们通常会因为数据管理安全、资源限制、输出精度高等要求。把一个完整任务切割成pipeline形式,分多个模型处理各个环节。根据任务切分的颗粒度和复杂程度,大家讨论的SFT可以分为两种,分别叫做拟合和对⻬
拟合
如果工作拆解比较细,每个模型只执行1个或少数几个任务的,此时 SFT 所做的工作更接近于早几年BERT+Fine-tuning的模型,可以称之为拟合。
常⻅场景:针对一个或多个特定任务,对泛化要求不高,通常会优先在LLM上做一些prompt engineering。但尝试了之后发现无法完美支持。此时选择用一些标注数据让模型朝着特定方向(过)拟合。
目的:
- 追求更好的稳定性:让输出偏向固定模板、固定语言⻛格等。
- 追求更好的准确性:提升、强化模型对特定指令的执行能力,比如抽取、总结、改写等。
对齐
如果我们的业务要求模型具备比较强的综合能力,比如说要构建一个日常智能助理,或者比如说coding copilot等,那就要从更宏大的⻆度去看待SFT。目前一个比较主流的共识是,知识和能力都是在预训练期间train进模型的,而后续训练中,针对的不管是指令、对话还是偏好,统统是为了理解和遵循人类的命令,是的大模型能够通过 zero-shot 的方式被使用。在这个基础上,SFT 所做的工作,可以称之为对⻬:
常⻅场景:构建一个综合能力强大的大模型,模型需要兼具多项能力,对泛化要求高。当我们从头pretrain一个大模型,或者利用垂直领域数据continue pretrain完大模型后,此时需要使用SFT完成能力的激活。
目的:
- 激发模型的指令遵循能力,对⻬人类意图
- 激活知识,面对人类的Question,使大模型对⻬已获得的Knowledge和需要回复的Answer
关于SFT的方法,目前仍有许多存在争议的部分,笔者认为很大一部分原因在于到底如何界定单一任务和多项任务,以及人们也仍未解释清楚关于知识和能力之间的关联。这两条路径使得SFT的训练方式迥异,以下从一些⻆度对SFT的观察和思考。
knowledge
SFT可以注入知识吗?即使我们还不能很好得描述什么是“知识”,但笔者认为“知识”至少不应该是一个映射表,不是让模型强行记住 <中国-首都-北京> 这样的三元组。对大模型来说,In-context Learning显然是一种更优雅的方式。
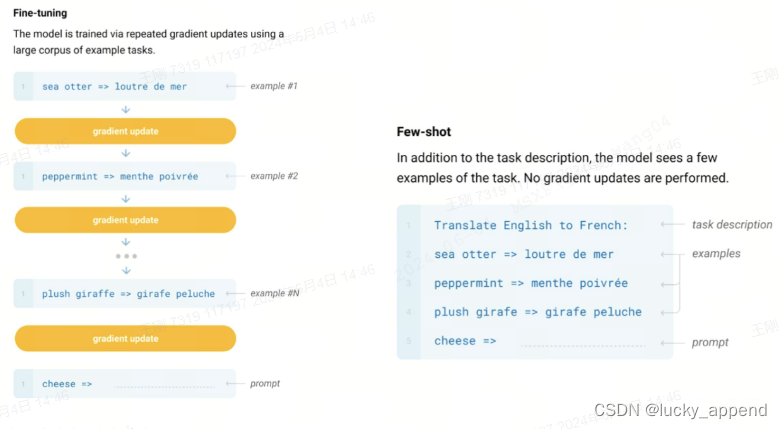
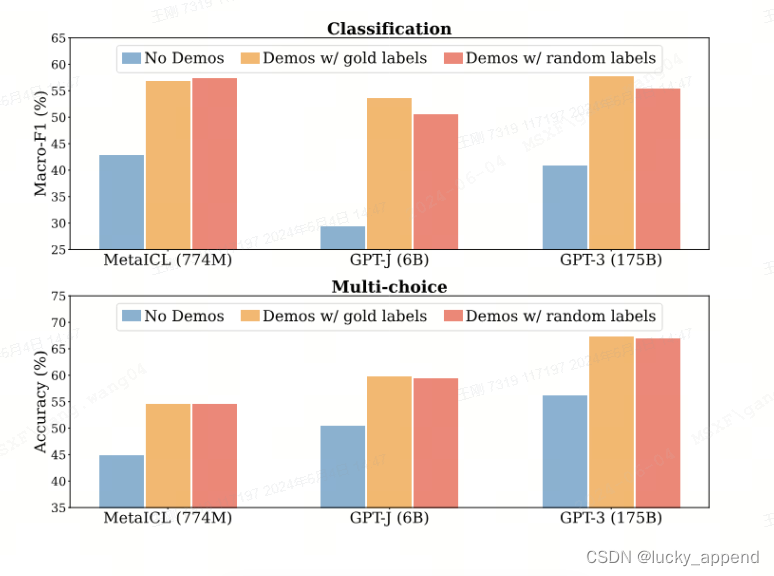
过往也有相关文章如"Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? "(ACL22) 讨论过 In-Context Learning 并没有从例子中去学习映射。作者把样本示例中的<x_i, y_i> 正确答案y_i随机替换掉,并不影响In-Context Learning的效果,这起码说明一点是 In-Conetxt Learning并没有提供给 LLM 那个 x 映射到 y 的映射函数 y=f(x)
使用SFT注入知识会发生什么
先说结论:可以完成想要的效果,但是会鼓励模型产生幻觉。
这篇工作"Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations"(24.05 Google) 做了若干测试:
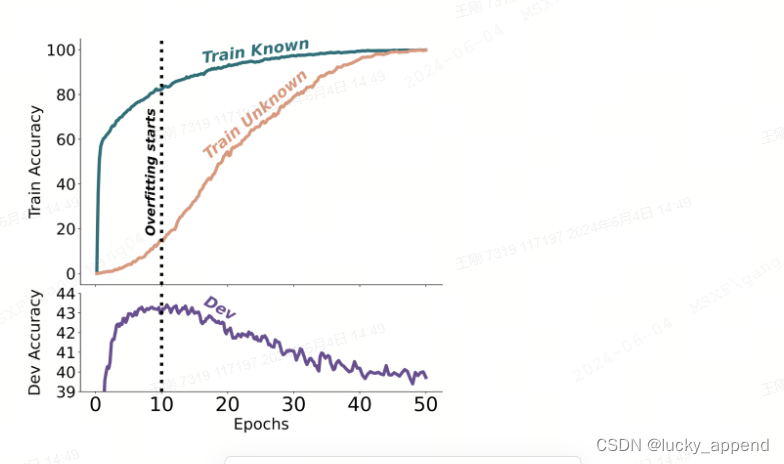
实验结果表明,模型在微调阶段遇到的新的知识,可能会鼓励模型产生幻觉,即使预训练已完成了知识学习,模型仍旧生成与事实不符的错误信息。
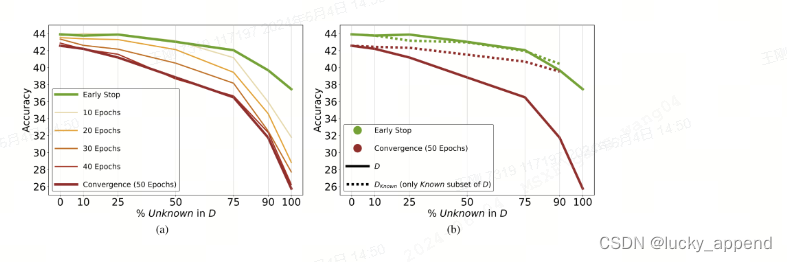
另一方面,作者设计了一个控制实验,实验任务是让模型做 closed-book QA。结果表明,unknown知识的占比越大,模型最终性能越差。
我们可以得到结论,通过 SFT ,最终确实可以把特定知识以类似映射表的形式强行train进模型,但是代价是:
(1)模型通过微调获得新知识,比调用模型已有知识显然是更困难的,整体训练会较慢。
(2)牺牲模型的泛化能力,并可能引入更严重的幻觉问题
引入RAG是个解决Hallucinations的好办法
在有些场景中,我们发现大模型在回答时发生幻觉,已经决定引入RAG的模式来优化。
但是RAG本身也会存在一些问题:
- 知识可能从检索的途径下没有获取到,
- 检索的知识与大模型的内部知识存在冲突。
此时,我们能通过SFT注入知识改善吗?直接上结论,
这篇工作讨论了这个问题:"How faithful are RAG models? Quantifying the tug-of-war between RAG and LLM's internal prior" (24.04 Stanford)
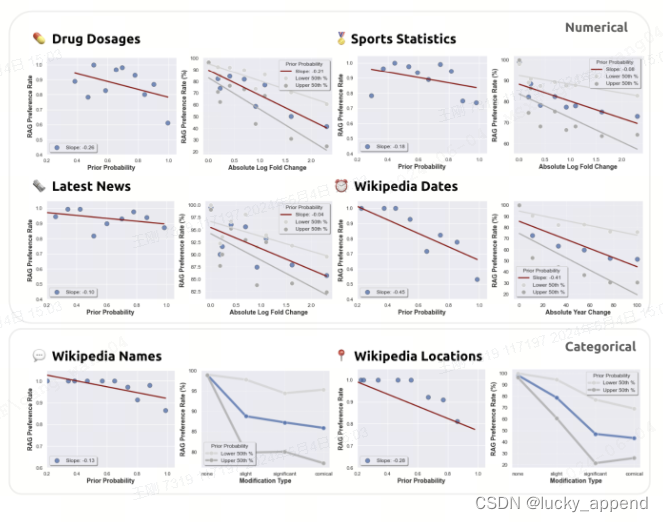
作者发现,LLM对检索信息的偏好与自身先验知识概率呈现负相关的联系。换句话说就是,如果两者发生冲突,随着偏离的程度加大,大模型会逐渐更倾向于内部知识。
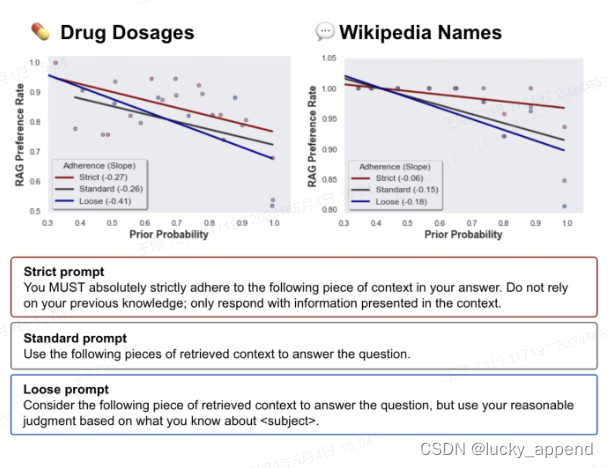
同时,Prompt技术的选择也对大模型RAG偏好有显著影响,作者用不同严格程度的prompt做了横向测试,结果表明更加严格的prompt可以提高RAG的遵循率。
小结
综上,笔者认为既然选择了RAG这条路来改善 "Knowledge" 问题,核心工作或许更应该提升检索模块的质量,权衡好大模型的遵循能力。在有条件的情况下,采用continue-pretrain的方式为大模型注入知识,避免直接微调注入知识儿导致其他能力的丧失。
数据量与数据配比问题
其他开源模型的SFT数据集
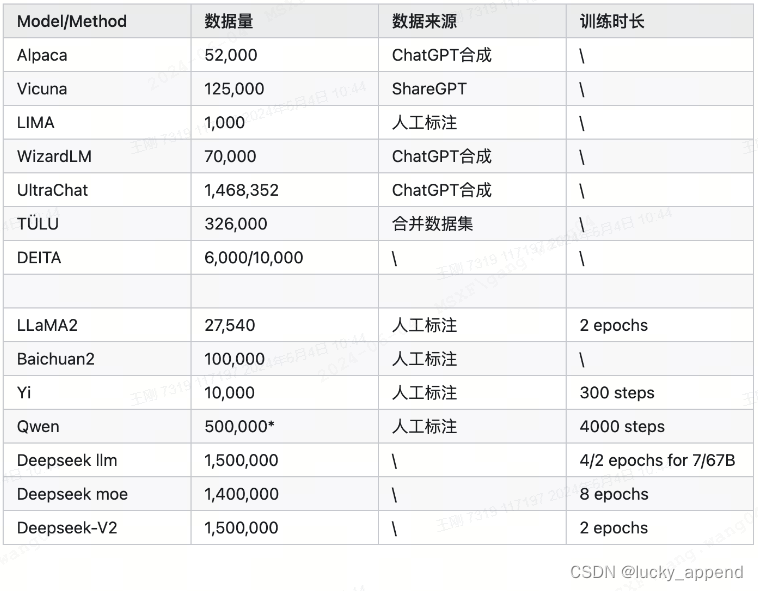
其中最为知名的,莫过于23年的 LIMA,作者仅用了 1000 条数据就达到非常好的效果。作者在论文中一句话表达了他的核心观点:
Superficial Alignment Hypothesis: A model's knowledge and capabilities are learnt almost entirely during pretraining, while alignment teaches it which subdistribution of formats should be used when interacting with users.
即,SFT的目的是行为标准或准则的对⻬,本质在于 align 而非 learning
在其他各开源LLM技术报告中提到的策略和一些共识:
Llama2:不同样本使用special token分割开;把样本拼接起来打满max length
Qwen:主要基于对话数据做的标注,强调chat模板对sft训练的必要性
Baichuan2:标注时使用交叉验证确保质量
Yi:坚持质量大于数量;仿照WizardLM提高指令复杂度;基于SFT数据的标签分布来保证指令多样性;确保SFT涉及的知识被pretrain覆盖,避免幻觉;着重处理了重复生成问题;
DeepSeek:认为数据量同样重要,数据量到达一定程度,某些能力才配激活。质量对于某些开放型写作问题很重要;另外也发现math类数据的占比对重复生成问题影响显著;
关于如何做数据配比的思路
模型能力相对应的指令数据配比问题,其实是每个算法项目的核心技术之一。一方面要评估当前业务是需要做拟合还是做对⻬,另一方面根据业务特性本身因地制宜。没有统一标准的方法论,但我们不妨从下面这篇工作中部分结论中窥得一些思路:
"How Abilities In Large Language Models Are Affected By Supervised Fine-Tuning Data Composition" (23.11 Ali)
作者在这篇工作中探究了通用能力(ShareGPT)、数学推理能力(GSM8K RFT),、代码生成能力(Code Alpaca)在数据配比、数据量、模型参数和SFT训练策略上对最终效果的影响
实验一:三种数据集按不同比例(1, 1/4, 1/16, 1/64, 1/256)混合,在不同尺寸大模型下的实验效果:
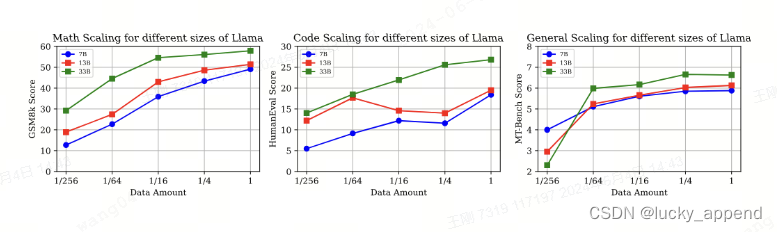
结论一:数据充足下,模型越大性能越强;同时,不同能力在不同尺寸下的data scaling有差异;实验二:对比一下单一能力的数据,和三种数据集按不同比例(1, 1/4, 1/16, 1/64, 1/256)混合的效果
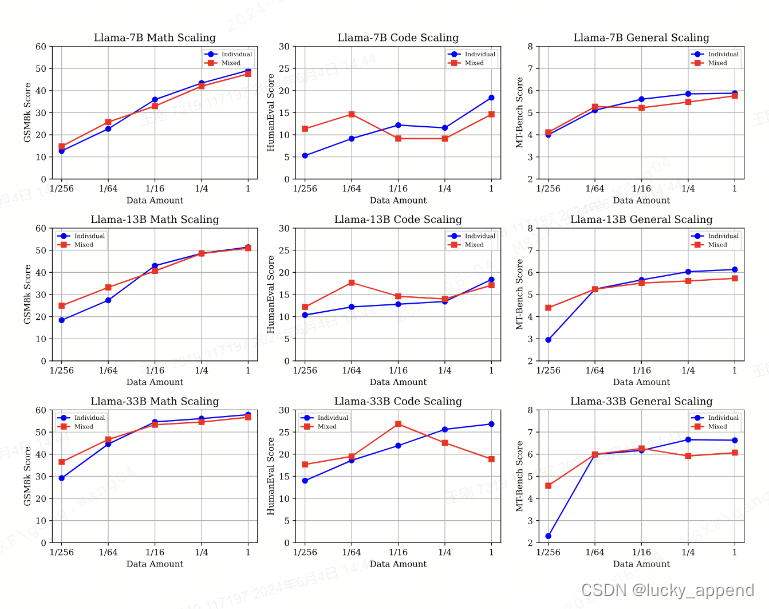
结论二:低资源增益,高资源冲突。简单理解就是,如果数据量比较小,几种能力混合在一起可以得到增益的效果。如果数据量比较大了,如果追究单一任务的性能,不如直接使用一种数据走“拟合”路线;
结论三:当模型尺寸放大之后,数学推理和通用能力在低资源的情况下,收益增加
实验三:为了探究什么是产生性能冲突的关键因素,设计了三种配比思路
(1)固定通用数据,缩放特定能力数据:Fix general + k (code, math)
(2)固定特定能力数据,缩放通用数据:Fix (code, math) + k general
(3)固定 1/64 通用数据,缩放特定能力数据:Fix 1/64 geneeral + k (code, math)
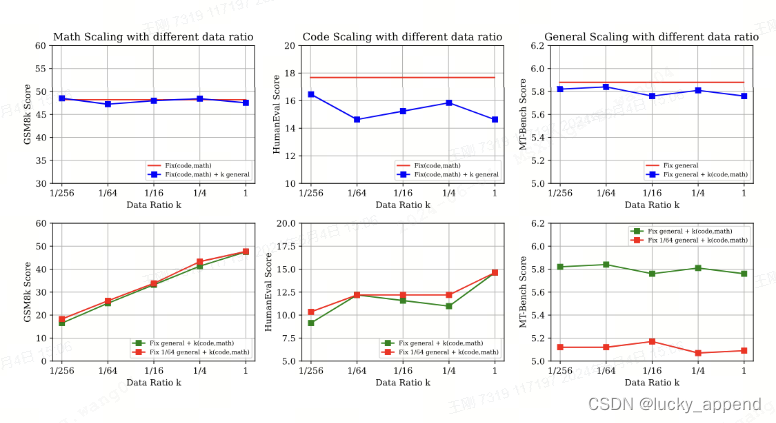
结论四:不同SFT能力之间的任务格式和数据分布很重要;如果不相似(比如数学和通用),数据配比的影响较小;如果比较相似(代码和通用),数据配比对性能有显著波动;
结论五:通用能力在数据配比中,受其他特定能力数据集影响比较小;
小结
(1)判断你手上的工作如果是做对⻬,高质量、多样性是最重要的;尽量避免知识无覆盖导致幻觉;尽量控制数据量和训练量防止过拟合;
(2)如果你完全确认目前的工作是做拟合,那么笔者认为可以抛弃 'LIMA',工业应用 More is more。大家大抵可以通过下面这个pipeline去刷数据,大力出奇迹:

需要注意的是,在3.2节介绍的工作实验中表明,低资源下混合通用能力是有收益的。换句话说就是可能因为各种限制,我们自动产生的数据集不够多,此时可以考虑混入一些基座模型原有的sft指令,可能会带来更好的指标。
数据该怎么挑
对SFT数据集的要求,我们基本上可以概括在三个方面,质量、复杂性(覆盖度)、多样性。关于数据构建的方法论又是另一个庞大的话题,业界可以查到的研究有包括针对庞大训练数据集进行筛选的方案;有基于已有验证集,有具体场景,从数据集挑选对这个场景有增益的数据;也有主动构建复杂样本、多样样本等方案。以下简单窥探一二,以供参考。
筛选数据-IFD
设置三个关键指标分别评估
(1)CA:给定指令下生成正确答案的能力,考察模型生成这个指令生成正确答案的难度;
(2)DA:不给指令,单独生成答案的难度;
(3)IFD:CA与DA的比值;通过评估IFD的值来决定指令,比如超过1是异常,0.x ~ 0.x 之间是难等等。
筛选数据-Superfiltering
是IFD的同一个作者,为了提高效率问题,在IFD中关注指令样本得分,但是如果是train一个110B的模型,挑起来会很慢。不如用一个小的来做挑选的动作,比如用13B,然后不关注得分(大模型对难易的感知可能会有更低的困惑度),只关注先后排名。
筛选数据-MoDS
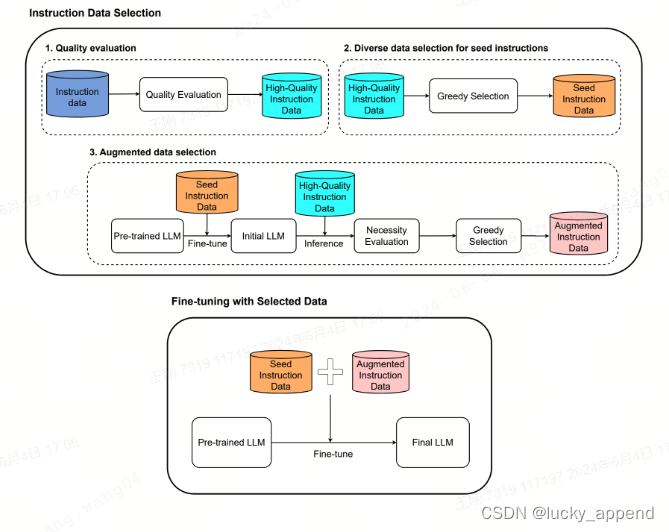
围绕三个点质量(Quality),覆盖度(Coverage),必要性(Necessity)
(1)用reward-model-deberta-v3-large-v2给海量候选打分,挑出来的算高质量
(2)用 k-center 聚类,从高质量的数据里挑出多样性的数据(seed instruction data),这里关注coverage
(3)用(2)挑出来种子数据来train模型,train完后对第一步的高质量数据计算loss,用loss衡量是不是necessity(大的话就不是)
合成数据-Self Instruct
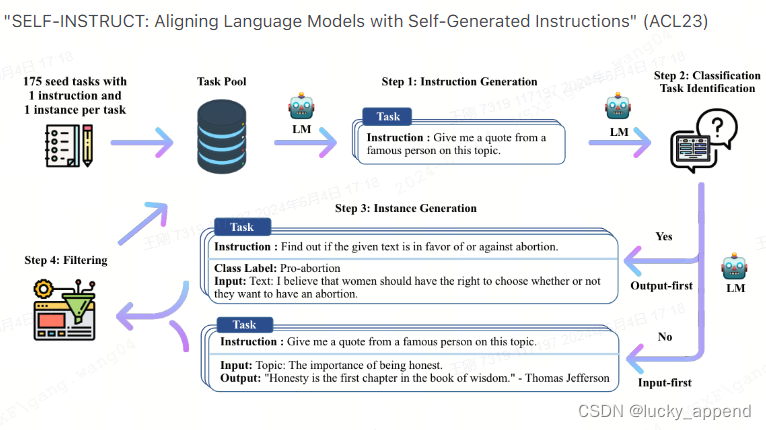
目前最常⻅的多样性构建方案,核心就是用一个好一点的chat模型,基于种子数据持续迭代扩展,让chat模型产生更多场景相似、形式不同的instructions
总结
- 永远建议优先做 prompt enginering,很多问题可能基座是有这个能力解决的,多比较几个基座;
- 做垂直应用的话,考虑是不是做拟合任务,是的话就多刷点数据train小模型,经济实惠;
- 如果考虑保留大模型的泛化能力,建议优先方案: base基座 + 领域数据 continue pretrain + SFT;
- 模型尺寸怎么选,资源允许的条件下,能选大的选大的;
- 训练数据注重什么,
- 确保回答格式和⻛格统一;
- 数据集既要包含难也要包含易;
- 注意任务的多样性和标签的平衡;
- 避免引入模型在预训练阶段为接触过的知识;
- 微调方法选什么,推荐Lora,稳定且效果不错,原有模型的泛化能力可以尽可能保留;
可以参考DeepMind的一篇工作 "When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method" (ICLR24) ,文章探讨了不同数据量下不同训练方式的效果和对泛化性的影响。实验结果表示,如果数据量只有几千条,P-tuning最好;数据量在几千到几万条,Lora更合适;数据量达到百万级别时,Full-tuning最好;


















 521
521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









