







摘要
针对于机器翻译问题,常见的解决思路是基于RNN或者CNN,这些神经网络中包含一个encoder和decoder。性能表现最好的模型会在encoder和decoder之间使用attention来将这两个结构连接起来。本文提出了Transformer,完全基于attention,并摒弃了RNN和CNN。Transformer在机器翻译任务上的表现很好,有望推广到其他领域。
介绍
在机器翻译的领域中,常用的RNN模型有LSTM和GRU网络模型。它们主要存在的问题是,输出有时序性,即当下的输出,依赖于前一个的输出,使得无法进行并行计算。也有一些方法的提出可以加快模型的训练,但是是治标不治本,没有从根本上解决这个RNN的顺序计算的问题。
在现有的模型中,RNN一般和attention机制相结合,attention主要将encoder的内容有效的传递给decoder。
Transformer完全避免了RNN,全部基于attention,可以进行并行化,可以在8个P100的GPU上进行12小时的训练,达到一个好的机器翻译的结果。
背景
由于RNN存在的顺序计算的问题,不能进行并行化计算,有许多网络提出使用CNN。可以并行计算输出和输入之间的隐藏表示。CNN对于长序列难以建模,但优点是可以并行计算,且存在多个输出通道,可以来识别不同的模式。为了达到CNN的多个输出通道的效果,Transformer使用多头注意力机制。
模型架构
编码器attention中同样的输入,作为Query、Key、Value。
masked也是同样如此,为了保持自回归(t看不到t后的输出),将t后的值设置为很小,使得经过softmax后,可以在t后的层输出概率为0。
解码器的attention的Q、K来自编码器,V来自masked的输入。这使得解码器的每个位置都可以覆盖编码器的所有位置。

常见的机器翻译模型都存在一个encoder和decoder,encoder负责将原始的输入(x1…xn)转变为机器可以理解的一些向量(z1…zn)。decoder则是负责将encoder的输入(z1…zn)变成一系列的输出Y(y1…ym)。注意此时的n和m不一定相同,翻译嘛,很正常。Y的输出还依赖于前一个的输出,所以得一个一个得输出。
3.1encoder & decoder
encoder包括两个子层,第一个是多头注意力机制,第二个是全连接层。在这两个子层中,分别做残差连接和layer normalization。为了残差的好计算,将所有的输出都变成512维。
decoder包括3个子层,分别是多头注意力机制、掩码的多头注意力机制以及全连接层,分别对这三个层做layer normalization和残差连接。掩码的多头注意力机制是一个一个的输出,它只能考虑它左边的东西,它没有办法考虑它右边的东西。
| layer normalization | batch normalization |
|---|---|
| 同一个样本的不同维度计算 | 不同样本的同一维度计算 |
| 对于长序列LN,改变自己,影响其他序列小,抖动小 | 对于长序列进行BN,影响其他序列大,抖动大 |
3.2attention
Attention函数可以描述为将query和一组key-value对映射到输出,其中query、key、value和输出都是向量。 输出为value的加权和,其中分配给每个value的权重通过query与相应key的兼容函数来计算。


Attention函数常见的有两种,一个是加法,一个是乘法,本文使用乘法简单。
维度很大,需要抵消维度对于梯度的影响,所以会乘以一个。
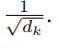
多头注意力机制:多个输出通道,学到不同的模式


3.3FC层
两个线性层(W1,W2),中间加一个ReLU激活函数。W1将自注意力机制输出的512维度变成2048维,W2将2048维度变为512维。MLP主要是将attention提取到的序列信息,映射到高维的语义空间。
3.4Embedding和Positional Encoding
Embedding:给定一个词,映射为一个向量。一般的Embedding相对较小,和Positional Encoding太小,所以乘以一个。
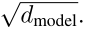
Positional Encoding:为了使用序列的顺序,需要添加位置编码。不加的话,模型对于一个句子打乱输出后的结果和打乱之前一致。
4 why?
以下三列分别为模型复杂度、顺序计算的操作、数据相互流通的距离。
n为序列长度、d为向量长度。
自注意力机制相较于其他模型,复杂度差不多、顺序计算少、数据之间的关系一次计算就可以得到。

5.实验
正则化使用Dropout和Label Smoothing
Label Smoothing增强模型的泛化能力。Label Smoothing公式如下:
参考这篇文章的Label Smoothing

结论
对于未来的展望,Transformer将会被用于各个领域















 6514
6514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









