







文章目录
1. SAD - 绝对误差和(Sum of absolute difference)
S
A
D
=
∑
i
∣
α
i
−
α
i
∗
∣
SAD = \sum_i|\alpha_i - \alpha^*_i|
SAD=i∑∣αi−αi∗∣
其中,
α
\alpha
α 为 predicted matte,
α
i
∗
\alpha^*_i
αi∗ 为 groundtruth matte。
def matte_sad(pred_matte, gt_matte):
assert (len(pred_matte.shape) == len(gt_matte.shape))
error_sad = np.sum(np.abs(pred_matte - gt_matte))
return error_sad
2. MAD - 平均绝对差值(Mean absolute difference)
M
A
D
=
1
n
∑
i
=
1
n
∣
α
i
−
α
i
∗
∣
MAD = \frac{1}{n}\sum_{i=1}^{n} |\alpha_i - \alpha^*_i|
MAD=n1i=1∑n∣αi−αi∗∣
其中,
α
\alpha
α 为 predicted matte,
α
i
∗
\alpha^*_i
αi∗ 为 groundtruth matte。MAD 与 SAD 类似,二者选其一即可。
def matte_mad(pred_matte, gt_matte):
assert (len(pred_matte.shape) == len(gt_matte.shape))
error_mad = np.mean(np.abs(pred_matte - gt_matte))
return error_mad
3. MSE - 均方误差(Mean squared error)
M
S
E
=
1
n
∑
i
=
1
n
(
α
i
−
α
i
∗
)
2
MSE = \frac{1}{n}\sum_{i=1}^{n} (\alpha_i - \alpha^*_i)^2
MSE=n1i=1∑n(αi−αi∗)2
其中,
α
\alpha
α 为 predicted matte,
α
i
∗
\alpha^*_i
αi∗ 为 groundtruth matte。
def matte_mse(pred_matte, gt_matte):
assert (len(pred_matte.shape) == len(gt_matte.shape))
error_mse = np.mean(np.power(pred_matte - gt_matte, 2))
return error_mse
4. Gradient error
G
r
d
_
e
r
r
o
r
=
∑
(
∇
α
i
−
∇
α
i
∗
)
2
Grd\_error = \sum (\nabla_{\alpha_i} - \nabla_{\alpha^*_i})^2
Grd_error=∑(∇αi−∇αi∗)2
其中,
∇
α
i
\nabla_{\alpha_i}
∇αi 和
∇
α
i
∗
\nabla_{\alpha^*_i}
∇αi∗ 表示对应alpha matte的归一化梯度, 是通过将matte与具有方差sigma的一阶Gaussian导数滤波器进行卷积计算得到的。计算二者差异, 进而累计损失。总体越相似,gradient error越小。
def matte_grad(pred_matte, gt_matte):
assert(len(pred_matte.shape) == len(gt_matte.shape))
# alpha matte 的归一化梯度,标准差 =1.4,1 阶高斯导数的卷积
predict_grad = scipy.ndimage.filters.gaussian_filter(pred_matte, 1.4, order=1)
gt_grad = scipy.ndimage.filters.gaussian_filter(gt_matte, 1.4, order=1)
error_grad = np.sum(np.power(predict_grad - gt_grad, 2))
return error_grad
5. Connectivity error
C
o
n
e
c
_
e
r
r
o
r
=
∑
i
(
φ
(
α
i
,
Ω
)
−
φ
(
α
i
∗
,
Ω
)
)
Conec\_error = \sum_i (\varphi(\alpha_i, \Omega) - \varphi(\alpha_i^*, \Omega))
Conec_error=i∑(φ(αi,Ω)−φ(αi∗,Ω))
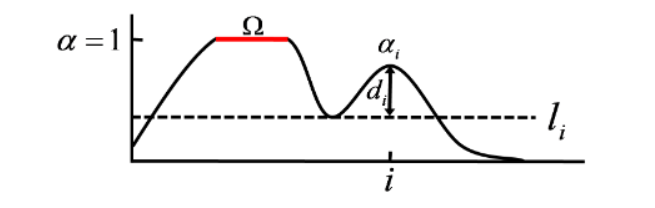
上式给出了连通性误差的计算方法, 是对整个预测出来的alpha matte图和相应的Ground truth的对应的差异的累和。关键在于
φ
(
α
i
,
Ω
)
\varphi(\alpha_i, \Omega)
φ(αi,Ω) 函数,源域
Ω
\Omega
Ω 由最大连通域定义,最大连通域是指alpha matte和它对应的Ground truth都完全不透明的部分(即
α
\alpha
α 都为 1),如上图红线区域大致表示。
连接程度由距离
d
i
d_i
di 决定,
d
i
=
α
i
−
l
i
d_i = \alpha_i - l_i
di=αi−li,其中
l
i
l_i
li 是像素
i
i
i 能四连通到
Ω
\Omega
Ω 的最大阈值,也就是上图中的虚线,阈值大于这个,像素
i
i
i 就与
Ω
\Omega
Ω 不连通了。 用 它 对alpha matte进行二值化,正好处于使像素
i
i
i 与源域连通(实 际 需 要 四 连 通 ) / 不 连 通 的 临 界 . 若 是 对 于 一 个 像 素 而 言 , 它 的 不连通了。用它对alpha matte进行二值化, 正好处于使像素i与源域连通(实际需要四连通)/不连通的临界. 若是对于一个像素而言, 它的不连通了。用它对‘alphamatte‘进行二值化,正好处于使像素i与源域连通(实际需要四连通)/不连通的临界。若是对于一个像素而言,它的
l
i
=
α
i
l_i=\alpha_i
li=αi,那么就可以认为它与源域是全连通的。
i
i
i 点连通度
α
\alpha
α 的定义如下:
φ
(
α
i
,
Ω
)
=
1
−
(
λ
i
⋅
δ
(
d
i
≥
θ
)
⋅
d
i
)
\varphi(\alpha_i, \Omega) = 1 - (\lambda_i \cdot \delta(d_i \ge \theta) \cdot d_i)
φ(αi,Ω)=1−(λi⋅δ(di≥θ)⋅di)
其中,
θ
\theta
θ 为自定义参数,它用在指示函数
δ
\delta
δ 里作为一个阈值, 用以忽略小于它的
d
i
d_i
di 的情况, 认为小于它就已经是全连通了, 使得误差计算更为灵活。
λ
i
=
1
k
∑
k
∈
K
d
i
s
t
k
(
i
)
\lambda_i = \frac{1}{k} \sum_{k \in K} dist_k (i)
λi=k1∑k∈Kdistk(i) 用来对
d
i
d_i
di 进行加权, 这里的
K
K
K 表示
l
i
l_i
li 到
α
i
\alpha_i
αi 间的离散
α
\alpha
α 值的集合,
d
i
s
t
k
dist_k
distk计算了设置为阈值
k
k
k 时, 对于像素
i
i
i 距离最近的连通到源域的像素,与像素
i
i
i 之间的标准化欧式距离。实际情况中,远离连通区域的像素,获得的权重
λ
\lambda
λ 也应该相应会更大些,这样导致得到的
φ
\varphi
φ 会更小些,也就是认为连通度更小。
按公式定义的
λ
\lambda
λ 的计算量太大,在实际应用中计算开销太大,为减小计算可把
λ
i
\lambda_i
λi 直接取为 1。


















 1455
1455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









