







 ALiBi是一种新型的注意力机制,通过引入非学习的线性偏差来处理长于训练序列的输入,无需额外参数或显著增加内存。它解决了现有位置编码方法在长序列外推中的局限,提高了模型的性能和训练效率。
ALiBi是一种新型的注意力机制,通过引入非学习的线性偏差来处理长于训练序列的输入,无需额外参数或显著增加内存。它解决了现有位置编码方法在长序列外推中的局限,提高了模型的性能和训练效率。
论文:https://arxiv.org/pdf/2108.12409.pdf
代码:https://github.com/ofirpress/attention_with_linear_biases
核心问题:如何使Transformer模型在推理时有效处理长于训练时序列的输入,同时提高训练效率并减少资源需求?
解法名字: Attention with Linear Biases (ALiBi)
之所以选择 ALiBi,是因为:
- 现有的位置编码方法(如正弦位置嵌入、旋转位置嵌入和T5偏差)在处理超出训练序列长度的输入时效率低下或资源需求高。
- ALiBi通过引入静态、非学习的线性偏差到注意力机制,提供了一种无需增加额外计算负担即可有效外推输入长度的解决方案。
ALiBi 本质是,通过在注意力机制中加入基于查询和键之间距离的线性偏差,来提升Transformer模型对长序列的处理能力,无需增加位置嵌入或改变模型结构。
- 子问题1: 如何在不增加额外运行时开销和参数的情况下,使模型能够处理更长的序列?
- 子解法1: ALiBi通过在注意力计算中引入固定斜率的静态线性偏差,而不是添加位置嵌入,实现对长序列的有效处理。
- 例子: 通过修改模型的遮罩矩阵来加入线性偏差,使得训练在短序列上的模型能在推理时有效处理长序列,无需额外参数或显著增加内存。
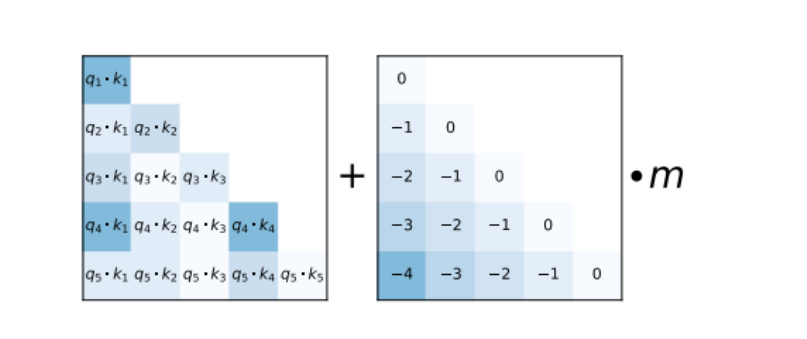
在计算注意力分数时,Attention with Linear Biases (ALiBi) 方法如何工作。
在这个方法中,一个恒定的偏差(右侧矩阵)被添加到每个头的注意力分数计算中(左侧矩阵)。
这个偏差是通过将一个头特定的固定标量 ( m ) 乘以一个下三角矩阵来实现的,其中下三角矩阵的值由查询(( q ))和键(( k ))之间的距离决定,这样更远的键将收到更大的惩罚。
然后将softmax函数应用于这些经过偏差调整的分数。
这个过程不涉及学习,也就是说,斜率 ( m ) 在训练过程中是固定的,不进行调整。这种方法使模型能够更好地处理超出训练时看到的序列长度的输入。
在使用ALiBi时,网络底部不会添加位置嵌入。
- 子问题2: 如何在使用较少计算资源的情况下,达到或超越使用传统位置编码方法的模型性能?
- 子解法2: 在大规模数据集上使用ALiBi训练模型,实现了相似或更佳的性能,同时运行更快且使用更少内存。
- 例子: 在CC100+RoBERTa数据集上训练的1.3B参数ALiBi模型与传统正弦位置编码方法相比,在保持相似困惑度的同时减少了训练时间和内存使用。
- 子问题3: 如何确保方法的泛化性和在多种文本域上的有效性?
- 子解法3: 使用固定斜率集合的ALiBi方法,在不同文本域的数据集上未经修改即展现出强大的结果。
- 例子: 在WikiText-103和书籍域的数据集上,ALiBi展现了其超参数的通用性,无需调整即在外推长序列时超越了正弦位置编码基线。
ALiBi提供了一种有效的解决方案,解决了在推理时处理长于训练时序列长度的输入的问题,同时提高了训练效率并减少了资源需求。
与传统的位置编码方法相比,ALiBi展现了更好的外推能力、更高的训练效率和更低的资源需求。
通过在不同文本域和数据集大小上的测试,ALiBi证明了其泛化能力和有效性,为未来的NLP任务提供了新的方向。
具体问题:当前位置编码方法不支持高效的序列长度外推。
问题 2:
- 当前位置编码方法不支持高效的序列长度外推
是问题 1 的具体细细节:
- 如何使Transformer模型在推理时有效处理长于训练时序列的输入,同时提高训练效率并减少资源需求?
这个问题是广泛的,关注于如何优化Transformer模型以适应更长的输入序列,而不仅仅是限于训练时见过的长度。
它还包含了提高训练效率和减少资源需求的目标,这是实现大规模NLP模型可行性的关键考虑因素。
具体问题概述: 当前位置编码方法不支持高效的序列长度外推。
这个问题具体指出了实现核心问题目标中遇到的一个主要障碍:现有的位置编码方法限制了模型外推到训练长度之外序列的能力。
位置编码是Transformer模型中一个关键的组成部分,用于提供序列中各个元素的位置信息,这对于模型理解输入序列的结构至关重要。
如果位置编码方法不能高效地支持长序列的处理,那么模型在处理超出训练时序列长度的输入时就会遇到困难,这直接影响到模型的泛化能力和效率。
- 子问题: 为什么传统的正弦位置编码方法不能有效外推?
- 子解法1: 正弦位置编码(sinusoidal position embeddings)。
- 之所以存在问题,是因为: 虽然理论上能够外推,实际上正弦编码的外推能力非常有限,仅能处理比训练时略长的序列,之后性能迅速下降。
- **例子:**当训练序列长度为512时,模型在处理长度为512+20的序列时性能改善,但在512+50之后性能停止提升并开始下降。
- 子问题: 旋转位置编码(rotary position embeddings)相对于正弦编码有何改进?
- 子解法2: 旋转位置编码。
- 之所以用旋转位置编码,是因为: 它在每个注意力层通过乘以正弦编码来注入位置信息,而不是仅在输入层添加,这样的设计可能对外推更有利。
- **例子:**旋转位置编码使模型能够处理比训练时多出200个令牌的序列,但以更慢的训练和推理速度为代价。
- 子问题: T5偏差(T5 bias)方法如何实现更好的外推能力?
- 子解法3: T5偏差。
- 之所以用T5偏差,是因为: 不同于前两种方法,T5偏差通过修改注意力值的计算方式,为每个查询键对分数加上基于它们之间距离的学习偏差,从而允许模型更有效地处理长于训练序列的输入。
- **例子:**使用T5偏差的模型能在训练序列长度为512时外推至1124个令牌的序列,尽管这带来了至少两倍的训练时间增加。
总结:
- 传统正弦位置编码 在处理稍微超出训练长度的序列时能提供一定的性能改善,但其外推能力非常有限。
- 旋转位置编码 通过在每个层注入位置信息,提高了外推能力,但牺牲了训练和推理速度。
- T5偏差 通过一种全新的方法改进了外推能力,允许模型处理远超训练序列长度的输入,但以显著增加的计算成本为代价。
通过比较这些方法,我们看到了在设计用于外推的模型时在性能、效率和计算成本之间的权衡。
尽管T5偏差方法提供了显著的外推能力,但其高计算成本提示我们需要寻找更高效的外推方法,
这正是Attention with Linear Biases (ALiBi)方法被提出的动机。
总结
核心问题:如何让Transformer模型在推理时能有效处理比在训练时见过的序列更长的输入序列?
解法: ALiBi
之所以用ALiBi解法,是因为: 现有的位置编码方法(如正弦位置编码)无法高效地处理远超训练长度的序列,因为它们没有为模型提供处理未见过长度的输入序列的能力。
考虑到核心问题的解决需要一个能够适应不同长度输入的模型,ALiBi提供了一种优雅的方法,它能够在不同的文本长度和域中保持一致的性能,无需为每个新任务重新设计模型架构。
这与原有的位置编码方法形成对比,后者通常需要为每种新的序列长度或数据集调整或重新学习位置编码,这不仅增加了训练成本,也限制了模型的泛化能力。
通过直接调整注意力分数,ALiBi避免了这些限制,提供了一种对长序列更为敏感的方法,从而更好地处理序列外推问题。
具体子问题与子解法:
-
子问题1: 模型如何在处理序列时保持对远处上下文的敏感性?
- 子解法1: ALiBi通过对注意力分数加入与距离成比例的线性偏差,使模型能够自然地给予更远的序列元素更小的权重。
- 例子: 如果一个单词的位置距离当前单词越远,ALiBi方法就会给其注意力分数加上更大的负偏差,模拟了人类阅读时对前文内容的记忆逐渐减弱的自然趋势。
-
子问题2: 如何避免在模型中增加过多的参数,从而节省内存和计算资源?
- 子解法2: ALiBi不添加额外的位置嵌入,而是直接在注意力机制中添加固定的线性偏差,从而不需要额外的参数学习。
- 例子: 与需要学习一个位置嵌入矩阵的方法不同,ALiBi只需要在已有的注意力分数上加上一个预定义的偏差矩阵,这个矩阵是在训练前就固定好的,不占用额外的内存。
-
子问题3: 模型如何在不同的文本域和不同长度的数据集上保持性能?
- 子解法3: ALiBi的线性偏差设置具有泛化性,因此无需针对新的数据集或文本域调整超参数。
- 例子: 无论是在维基百科的文章还是在书籍的章节中,ALiBi通过其固定的偏差模式能够持续提供稳定的性能,无需针对每种类型的文本重新调整模型配置。

















 700
700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









