







YOLOX: 无锚点机制 + 解耦头部设计 + 动态标签分配策略的高性能目标检测器 + Apache-2.0 开源可商用
论文:YOLOX: Exceeding YOLO Series in 2021
代码:https://github.com/Megvii-BaseDetection/YOLOX
YOLOX是YOLO对象检测算法系列的一个重要进展,这些算法以其有效性和效率而闻名。以下是YOLOX中突出的关键改进和特点:
-
无锚检测:YOLOX从以前的YOLO版本使用的传统基于锚的系统转变为无锚方式。这意味着它在没有预定义锚点的情况下预测边界框,简化了模型并可能减少了超参数。
-
解耦头部:模型在其架构中使用了一个解耦头部,这可能意味着它将边界框的预测和类别预测分离到不同的组件中。这可以提高学习和性能,因为每个部分都可以专注于更具体的任务。
-
SimOTA标签分配:使用SimOTA(简化的最优运输分配)进行标签分配。这种先进的策略通过确保使用最相关的预测进行训练,优化了地面真实和预测对象之间的匹配,提高了精度。
-
不同规模的性能:YOLOX在各种模型大小上表现出强大的性能:
- YOLO-Nano:尽管只有0.91百万参数和1.08亿FLOPs,它在COCO数据集上达到了25.3%的AP(平均精度),超过了NanoDet。
- 增强的YOLOv3:将YOLOv3的性能提高到COCO上的47.3% AP。
- YOLOX-L:该版本在Tesla V100 GPU上以68.9帧/秒(FPS)的速度达到了50.0%的AP,与其他高性能模型如YOLOv4-CSP和YOLOv5-L相当,但效率更高。
-
竞赛成功:YOLOX-L在CVPR 2021自动驾驶研讨会上的流媒体感知挑战中获得了第一名,表明了其在动态环境中的实用性和稳健性。
-
部署和支持:该模型支持使用各种框架(如ONNX、TensorRT、NCNN和OpenVINO)进行部署,使其能够适应不同的平台和设备。
-
开源可用性:源代码在GitHub上可用,为开发人员和研究人员提供了使用和适应YOLOX的可能性。
YOLOX代表了对象检测技术的一大飞跃,特别适用于需要实时环境中高性能的应用。其增强功能使其成为从自动驾驶到监控的广泛应用的强有力候选者。
1. Decoupled Head 解耦头
- 子解法1: 引入解耦头部分别处理分类和定位任务。
- 之所以使用解耦头部,是因为分类和定位任务在传统耦合头部中相互干扰,可能会导致性能下降。解耦头部可以让每个任务专注于其特定的功能,从而提高整体检测性能。例如,实验表明替换为解耦头部可以显著提高模型的收敛速度。
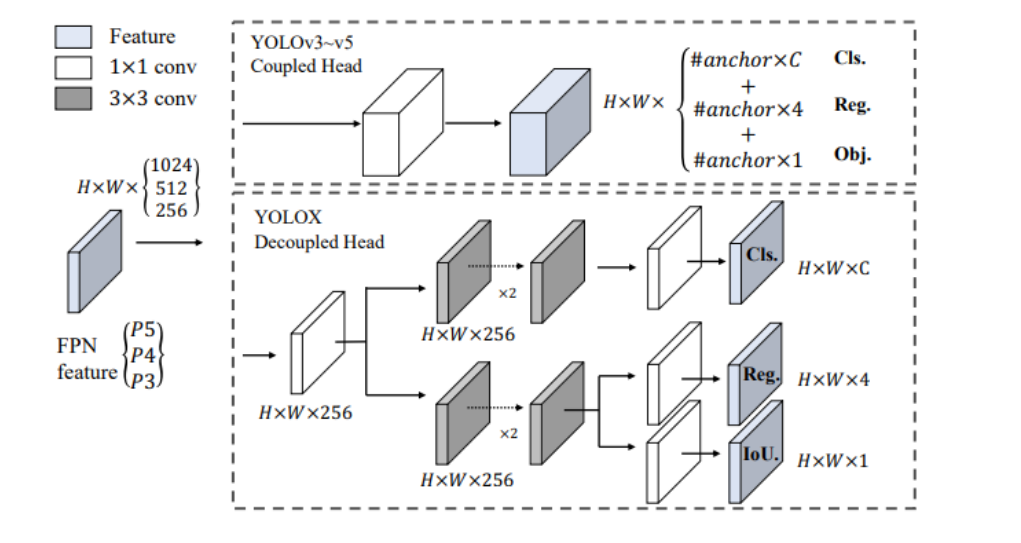
-
YOLOv3的耦合头:
- 使用了耦合头部,这意味着分类(Cls.)、回归(Reg.)、以及目标(Obj.)任务在同一神经网络层中处理。
- 图中展示了从FPN(特征金字塔网络)特征分别经过1x1的卷积层,然后直接输出到一个混合输出层,这个输出层结合了不同的任务预测。
- 输出维度为HxWxC(通道数乘以锚点数乘以(分类数 + 4个回归值 + 1个目标置信度))。
-
YOLOX的解耦头:
- YOLOX采用解耦头部设计,分开处理分类和回归任务,以及一个额外的IoU(交并比)分支。
- 对每个FPN输出特征首先应用1x1的卷积层降低通道数至256,然后分为两个并行分支,每个分支包括两个3x3的卷积层,分别用于分类和回归任务。
- 分类分支输出为HxWxC(每个位置的类别数),回归分支输出为HxWx4(每个位置的四个回归值),IoU分支输出为HxWx1(每个位置的IoU预测)。
这种设计的变化主要是为了改善模型的性能,通过分离任务以减少不同任务间的干扰,提高模型在分类和定位准确性上的效率。
解耦头部允许模型更加专注于每个特定任务的学习,从而在实际应用中提供更准确的预测。
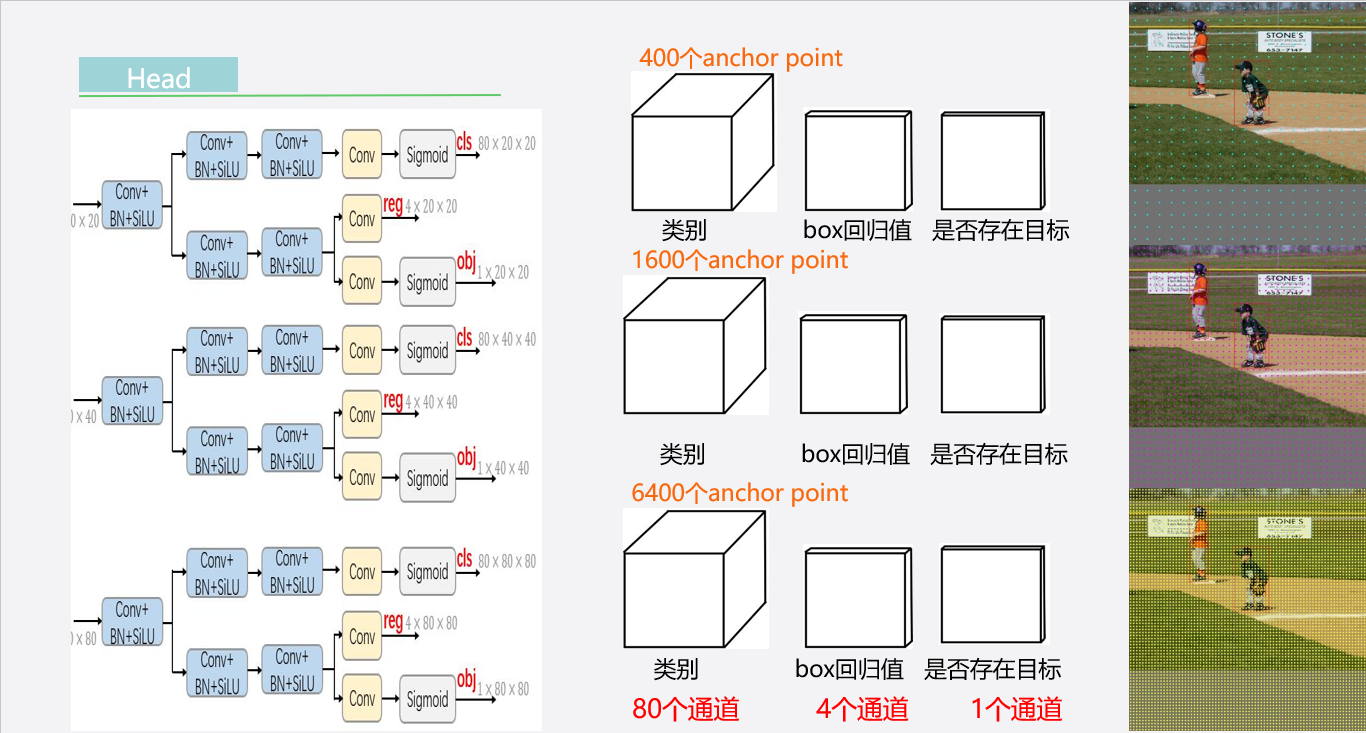
-
Head结构:
- 图的左侧显示了网络头部的多尺度架构,包括多个并行的卷积层和批量归一化层(BN+SiLU),最终通过Sigmoid函数输出。
- 这些层被分成不同的分支,每个分支负责处理不同尺寸的特征图,用于检测不同尺寸的目标。
-
输出解释:
- 每个分支输出包括类别预测(cls)、目标存在性预测(obj)和边界框坐标预测(reg)。这些输出合起来定义了每个预测的目标框。
- cls:分类得分,用Sigmoid函数输出每个类的概率。
- obj:目标存在性得分,表明当前框内是否存在目标。
- reg:边界框的坐标,通常包括框的中心点坐标和宽高。
-
不同尺度的特征图:
- 图的右侧展示了三种不同尺度的特征图(20x20, 40x40, 80x80),每种特征图适合检测不同尺寸的目标。
- 较大的特征图(如80x80)有更多的anchor points(锚点),适用于检测小尺寸的目标,因为它们可以更精细地覆盖图像区域。
- 较小的特征图(如20x20)用于检测大尺寸目标,每个区域覆盖更大的空间,因而anchor points较少。
YOLOX 框架:
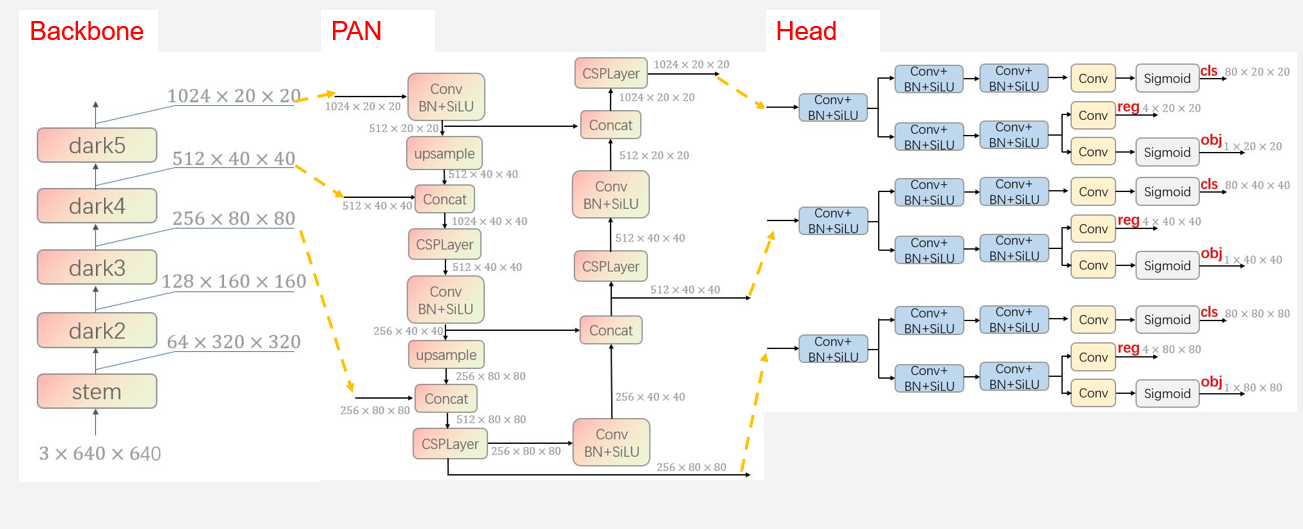
Backbone、PAN 在下文。
2. CSPDarkNet 网络结构
CSPDarkNet 代码地址:https://github.com/WongKinYiu/CrossStagePartialNetworks
CSPDarkNet主要建立在DarkNet神经网络架构的基础上,增加了Cross Stage Partial Network (CSPNet) 的设计,以改善模型的性能并减少计算成本。
- DarkNet53 的深度特征提取能力
- CSPNet 的高效计算方式
DarkNet53 的深度特征提取能力
DarkNet53是一个由53层卷积组成的深度神经网络,原本设计用作YOLOv3的主干网络。
这个网络是为了提取从简单到复杂的特征而精心设计的,具体包括:
- 层级特征提取:DarkNet53通过多层卷积网络逐层提取图像特征,每一层都在前一层的基础上进一步抽象和提炼信息。这种分层方式允许网络捕捉从边缘和纹理到更复杂的对象部分的特征。
- 残差连接:DarkNet53使用残差连接(Residual Connections)帮助解决深层网络中可能出现的梯度消失问题,确保即使在网络很深的情况下也能有效地训练。
- 高效特征利用:通过这种深层次的特征提取,DarkNet53能够识别和处理图像中的各种对象,为后续的分类和定位任务提供了丰富的特征基础。
DarkNet53 类比:图书馆系统
想象DarkNet53像是一座大型图书馆系统,其中包括从基础文献到高级专业书籍的多层次收藏。
每个层次的书籍都建立在前一个层次的基础上,提供更深入、更专业的知识。
- 层级特征提取:就像从图书馆的不同楼层逐层获取知识,每一层都提供更深入的信息。从简单的概念书籍到复杂的研究论文,读者(网络)可以逐步深入理解各种主题。
- 残差连接:如果某个楼层的知识直接与另一个楼层链接,读者可以直接访问需要的资源而无需重复阅读基础材料,类似于跳过已知信息,直接获取新知识。
- 高效特征利用:如同一个高效的图书管理员,DarkNet53可以准确快速地找到并处理所需的信息,无论是简单的查询还是复杂的研究问题。
CSPNet 的高效计算方式
CSPNet 是一种结构,可以用于任何网络。
CSPNet通过改变特征图的传递和处理方式,优化了计算过程,特别适用于在计算资源受限的环境下运行。
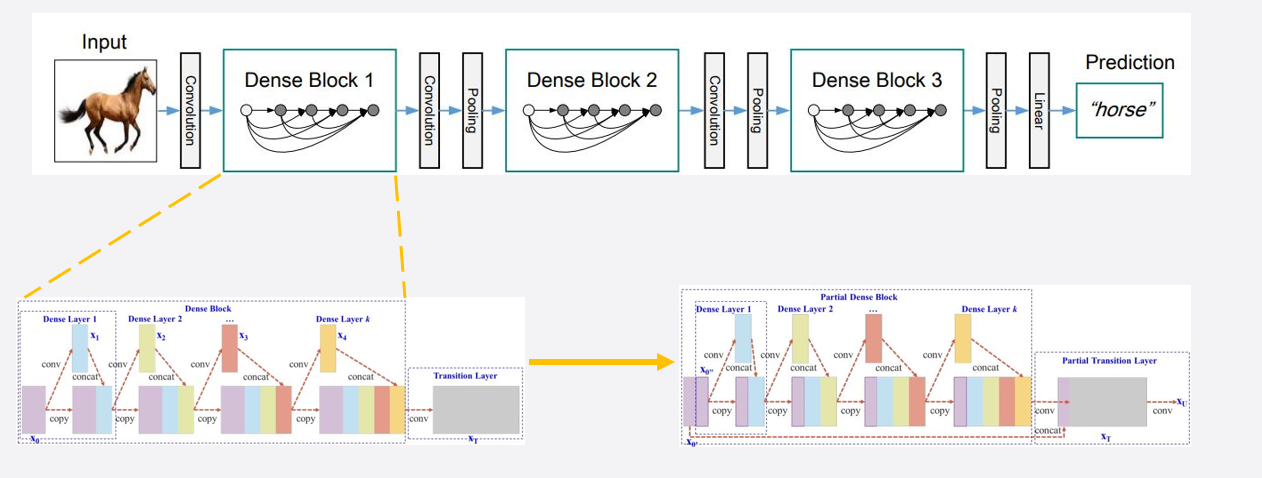
原始的 Dense 网络输入 X 0 X_{0} X0 (左下角),是整块输入的,通过卷积,不断拼接
CSPNet 的 Dense 网络,输入被分割成 2 半,只用一半当输入不断卷积,算完,把另一半直接拼接
CSP结构通过将特征图分成两部分,一部分直接传递,另一部分经过一系列卷积处理后再与直接传递的部分合并,这有助于减少冗余计算和加强特征的多样性。
它的主要优势包括:
- 特征分割和并行处理:CSPNet将来自前一层的特征图分为两部分,一部分直接传递到深层网络,而另一部分则通过额外的卷积层进行处理。这种结构减少了重复计算,使得整个网络的参数更有效地被利用。
- 降低计算成本:通过分割特征图,CSPNet实际上减少了每层的参数数量,这直接降低了模型的训练和推理时的计算成本。
- 增强的特征融合:在网络的后续部分,直接传递的特征与经过卷积处理的特征合并,这样的设计增加了网络在不同级别上特征的融合,提高了模型对复杂场景的适应能力。
CSPNet 类比:文件存储系统
将CSPNet想象为一个高效的文件存储系统,其中文件被划分为直接使用的部分和需要进一步处理的部分。
- 特征分割和并行处理:类似于一个办公室环境,其中一些文件直接存档以备未来快速访问,而其他文件则由不同的团队成员加工和更新。这样做可以减少不必要的重复工作,提高整体效率。
- 降低计算成本:就像将大文件拆分为更小的、更易于处理的部分一样,这使得文件系统更加高效,减少了处理大文件时的资源消耗。
- 增强的特征融合:最终,所有处理过的文件和直接存档的文件会汇总到一起,这就像一个会议,各方信息汇总后提供了一个全面的决策基础。
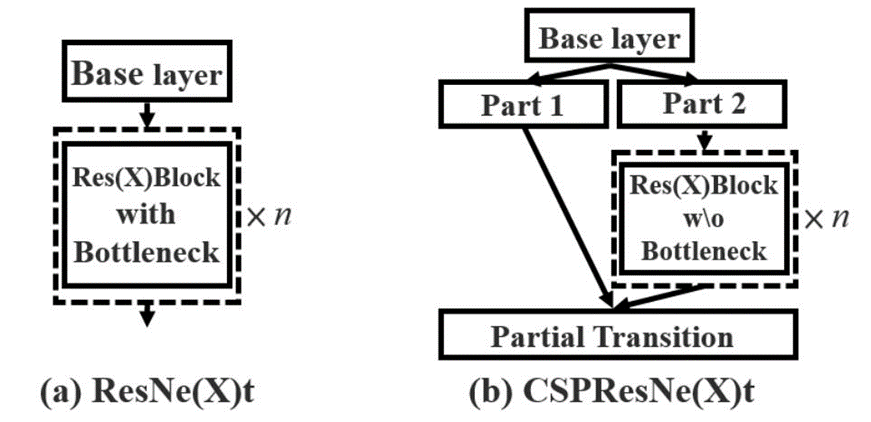
两种不同的网络结构设计:传统的ResNe(X)t和CSPResNe(X)t。
(a) ResNe(X)t
- Base layer:基础层,是网络的输入层,用于接收输入数据。
- Res(X) Block with Bottleneck:包含瓶颈结构的残差块。这种设计通过使用1x1、3x3和再次1x1的卷积核,旨在减少特征维度,从而减少计算量,同时保持网络深度和复杂性。
- 这些块被重复n次,以增加网络的深度,提高其学习复杂表示的能力。
(b) CSPResNe(X)t
- Base layer:同样作为网络的输入层。
- Part 1 and Part 2:在CSPResNe(X)t结构中,特征图在进入残差块之前被分割成两部分。这种分割有助于降低冗余计算,优化内存使用和计算效率。
- Res(X) Block w/o Bottleneck:这里的残差块没有瓶颈设计,意味着它避免了减少特征维度的1x1卷积操作。这可能有助于保持更多的特征信息,虽然可能会增加一些计算负担。
- Partial Transition:部分过渡层用于合并处理过的特征部分,这在网络中提供了一个更加丰富的特征集合,有助于提高最终的性能。
ResNe(X)t 结构致力于通过瓶颈设计减少参数和计算复杂性,而 CSPResNe(X)t 则通过分割特征图和部分过渡来优化训练过程的速度和效率。
CSPResNe(X)t结构尤其适用于需要处理大量数据和在硬件资源受限的环境中运行的应用。
对比ResNe(X)t和CSPResNe(X)t的架构可以通过一个现实生活中的类比来更形象地理解它们的设计差异和相应的优势:
想象一个工厂有两条产品装配线,每条装配线都设计用来制造相同的产品,但每条线的组织结构和流程不同。
- 传统的装配线(ResNe(X)t):
- 像传统的装配线一样,每个工作站(残差块)负责完成产品的一个特定部分,并且在进入下一个工作站之前会通过一系列的精简步骤(瓶颈设计)来确保效率。 这种方法的目的是优化资源使用,通过减少每个工作站所需处理的材料数量(特征维度),从而减少整个生产过程的复杂性和成本。
- 分割任务装配线(CSPResNe(X)t):
- 此装配线将原材料(输入特征)在进入流程前分成两部分。一部分直接进入最后的组装阶段,而另一部分则在多个工作站(残差块)中经过加工处理。 最后,这两部分在装配线的末端(部分过渡层)合并,以完成最终产品。这种结构允许工厂更灵活地管理资源,因为它可以并行处理多个任务,同时减少了因重复工序导致的时间和资源浪费。
优势与用途:
- 传统装配线(ResNe(X)t):适用于资源有限但需要维持高质量输出的情况。通过瓶颈设计,它确保每一步都尽可能高效,适合在资源受限或成本敏感的生产环境中使用。
- 分割任务装配线(CSPResNe(X)t):通过并行处理和优化工作流程的灵活性,这种方法可以更快地处理大量任务,特别适合需要快速响应和高效率的大规模生产环境。
当将DarkNet53的深度特征提取能力与CSPNet的高效计算方式结合时,CSPDarkNet53能够在确保深度和复杂特征提取的同时,保持网络的运行效率。
这种结合使得CSPDarkNet53特别适合用于需要实时处理的目标检测任务中,如视频监控和自动驾驶,因为它可以快速且准确地处理大量图像数据。
这种结构优化的目标是在不牺牲性能的情况下提供更高的速度和效率,使得CSPDarkNet53成为计算资源受限环境中的理想选择。
CSP、DarkNet 怎么做结合?
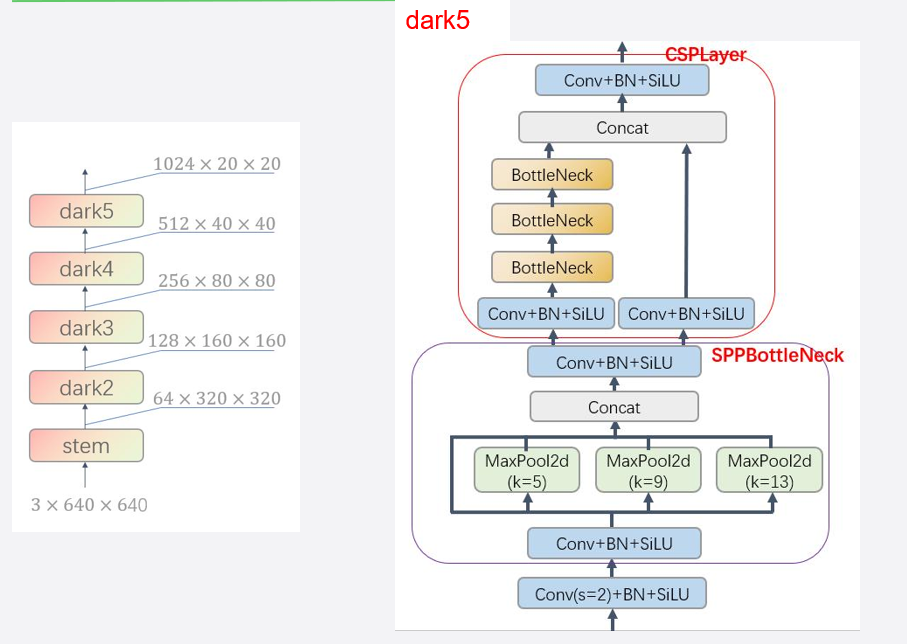
DarkNet 是由 “dark2”,“dark3”,和“dark4” 、“dark5”组成的:
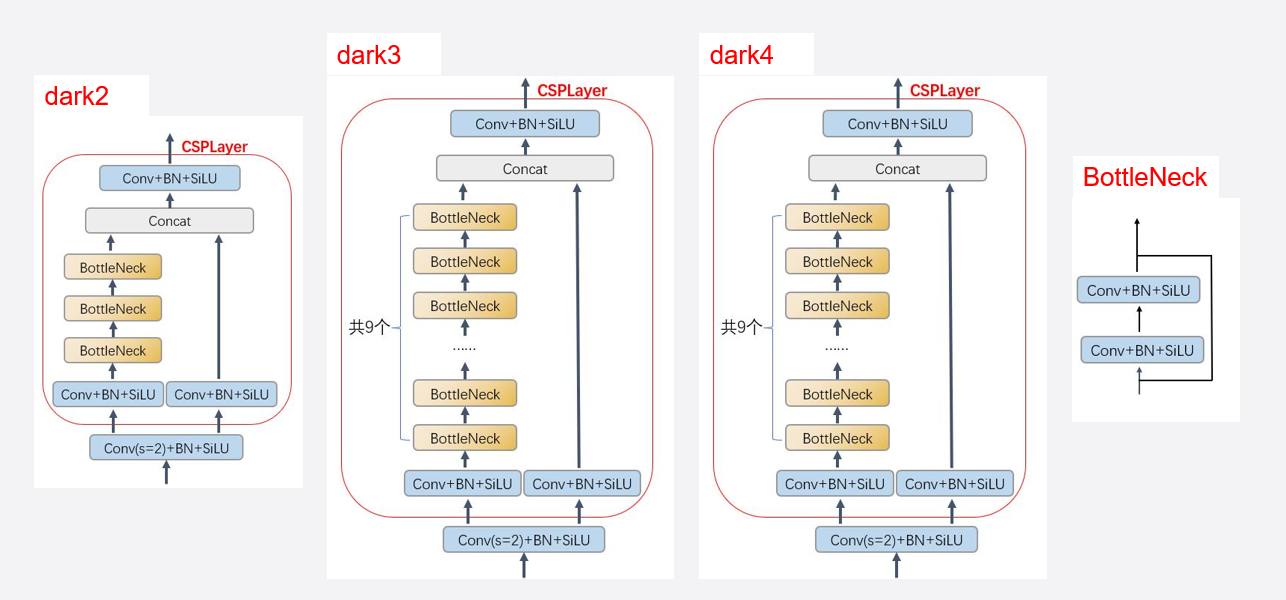
他们区别是通道数(卷积层更多),越后面的块,处理的特征越复杂。
“dark2”,“dark3”,和“dark4” 有残差结构(BottleNeck),“dark5” 没有。
在CSP结构中,通过使用Concat操作,而不是简单的相加操作来合并特征,这有助于保留更多的信息和提高特征的利用效率。
合并操作后,通常会跟随一个卷积层来融合这些特征,确保网络可以处理来自不同路径的信息。
CSPLayer 都放在了 Concat 操作后面?
将CSPLayer放在Concat操作后面而不是其他网络层后面,主要基于以下几个考虑:
-
特征的全面整合:Concat操作通过将不同路径的特征图合并,提供了一个丰富和多维度的特征集。
这样的合并创建了一个包含多种视角和信息的综合特征表示,为CSPLayer提供了一个理想的输入。
放在其他单一的网络层后面可能无法获取这种多样化的输入。
-
效率和资源优化:在Concat后使用CSPLayer可以直接处理这些合并的特征,减少了在每个单独的特征路径上重复相同计算的需要。
这种方法能够有效降低冗余计算和参数数量,提高网络的运行效率。
如果放在其他网络层,如卷积或激活层后面,可能不足以有效减少计算和参数负担。
-
改善梯度流和训练稳定性:Concat后的CSPLayer有助于维持梯度的良好流动,特别是在深层网络中,这对于避免梯度消失或爆炸至关重要。
其他单一网络层如普通卷积层可能缺乏足够的机制来处理来自多个来源的复杂梯度流。
-
更强的学习能力和特征融合:CSPLayer设计用于增强网络的特征学习和融合能力。
在Concat后立即使用CSPLayer可以确保网络不只是简单地堆叠特征,而是通过额外的学习层(如CSPLayer中的卷积和激活)深度整合和优化这些特征。
如果放在其他层后面,特别是那些仅输出单一类型特征的层,可能不足以实现这种深度的特征融合和优化。
为了最大化特征的综合利用和网络效率,同时保持网络结构的简洁性和实用性。
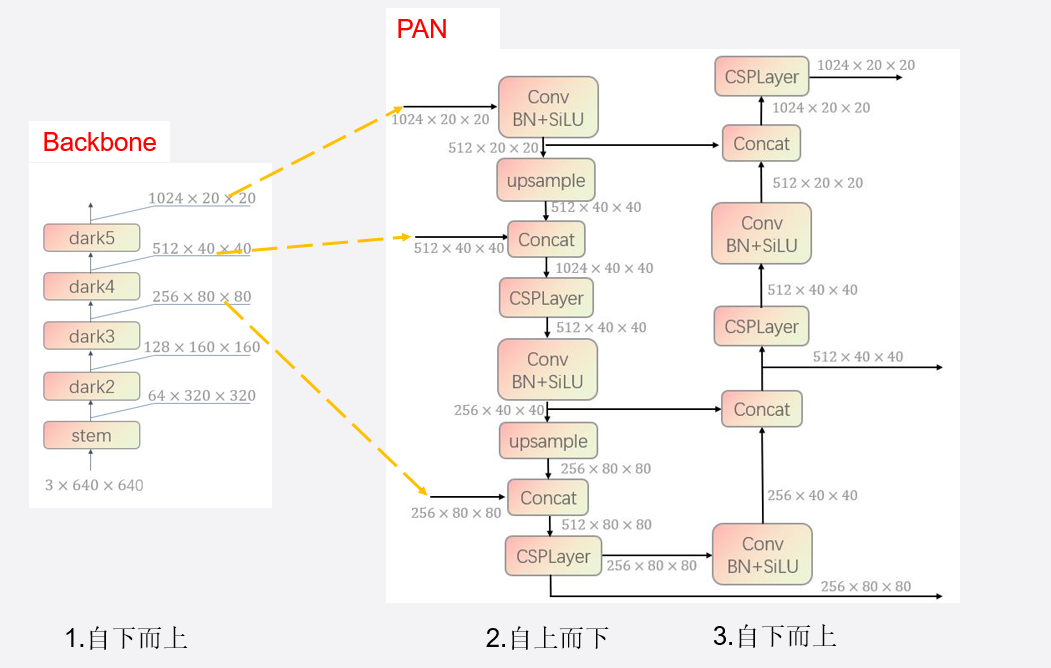
3. PAFPN
https://github.com/ShuLiu1993/PANet
PAFPN 是 FPN 的升级:
- FPN = 自下而上 + 自上而下
- PAFPN = 自下而上 + 自上而下 + 自下而上
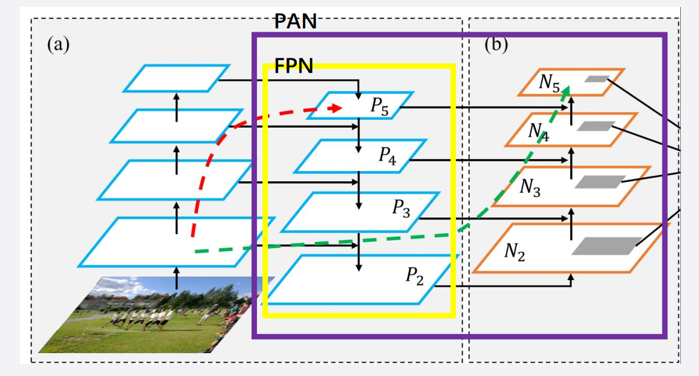
PAFPN通过增加额外的自下而上的路径,有效地增强了特征金字塔的多尺度信息融合,提高了对细节的捕捉能力和模型的整体性能。
在标准的FPN中,自上而下的路径主要负责将高层次的语义信息传递给低层次的特征图。
然而,这种单向下传的结构可能不足以充分利用低层次的细节信息。
通过在FPN的基础上增加一个自下而上的路径,PAFPN允许低层次的细节特征再次向上传递并与高层次特征进行更深入的整合。
-
增强低层特征和高层特征的融合:这样可以提高特征图的丰富性和有用性,尤其是在目标检测和分割任务中对小物体的识别上更为有效。
-
改善特征金字塔的信息流:这种双向特征流动确保了从不同尺度获得的信息都得到了最大化的利用,对于改进模型的泛化能力和精确度非常有帮助。
-
减少信息丢失:在传统的FPN中,随着特征从高层向低层传递,可能会出现信息丢失的情况,尤其是在多层次的结构中。PAFPN通过增加向上的反馈路径,帮助恢复那些在自上而下传递过程中可能丢失的低级信息,使得每一层的输出都更加信息丰富和精确。
-
优化网络的计算效率:尽管增加自下而上的路径可能看起来会增加计算负担,但这种设计实际上可以通过更精确的特征表示减少后续处理阶段的计算需求。更好的特征表示通常意味着可以使用更简单的分类器或回归器来达到相同甚至更好的效果,从而在整体上优化了计算效率。
结合图示:
4. SimOTA正负样本分配策略
Anchor Based 的问题
目标检测任务,是对滑窗区域的分类任务。
- 通过分类来识别图像中的对象种类
- 并通过回归来确定这些对象的精确位置
直接使用分类模型的 Backbone,构造分类损失函数。
每个滑窗区域就是一个样本:
- 正样本:含有目标的样本
- 负样本:背景样本
滑窗的数量为M×N。
与传统的图像分类任务相比,每张图片中有很多个样本。
网络的输出不再是1个 vector, 而是M×N个Vector。
检测框都是提前预设的(9种不同尺寸的预测框), 很多目标只能得到相对合适的框, 而无法得到贴合目标的框。

额外增加1个回归分支,用于预测真值与滑窗区域之间的差异(∆x、∆y、∆w、∆h);对于负样本,没有回归值。
相应地,需要增加1个回归损失函数(不考虑负样本);将分类损失和回归损失加权求和,作为最终的损失函数。
Anchor Based目标检测器的缺点:
- Anchor的大小、数量、和宽高比 (aspect ratio)
Anchor是预设的一系列框,它们覆盖在输入图像的不同位置、不同尺寸和不同宽高比。目标检测模型使用这些框来预测真实对象的位置。
- 缺点:
- 选择复杂:Anchor的大小、数量和形状(宽高比)对检测性能影响很大,必须根据具体的应用和数据集进行仔细选择和调整。如果选择不当,可能会导致模型性能不佳。
- 需要定制:不同的任务和数据集可能需要不同的Anchor设置,这意味着在新的应用场景下可能需要重新设计这些参数,增加了部署的复杂性。
- 高召回率需求下的大量Anchor
为了确保几乎所有真实对象都能被检测到(即高召回率),系统会生成大量的Anchor。这意味着大多数Anchor并没有覆盖到真正的对象,成为了“负样本”。
- 缺点:
- 正负样本不均衡:大量的负样本(不包含对象的Anchor)与少量的正样本(正确覆盖对象的Anchor)之间的不平衡,会导致训练困难,模型可能过于关注负样本,影响检测性能。
- 正负样本分配的计算复杂性
在训练阶段,模型需要决定每一个Anchor是正样本还是负样本。这通常是基于Anchor与真实对象框之间的重叠程度(例如,使用IOU-交并比)来决定的。
- 缺点:
- 计算复杂:这一过程计算量大,尤其是当Anchor数量很多时,影响训练效率。
Anchor Based目标检测器通过使用预设的框来定位和分类图像中的对象,但这种方法依赖于复杂的超参数选择,并面临着正负样本不均衡及高计算成本的问题。
这些因素都可能影响模型的最终性能和效率。
anchor free
在Anchor-Free目标检测算法中,不再依赖于预定义的锚框。
相反,它直接通过网络结构来预测目标物体的位置和尺度,而不需要预先定义或采样锚框。
Anchor-Free算法的优点之一是减少了预定义的锚框的数量和大小的选择,减少了设计和调整的复杂性。
此外,Anchor-Free方法对于不规则形状的目标物体有更好的适应性,因为它不依赖于预定义的矩形锚框。
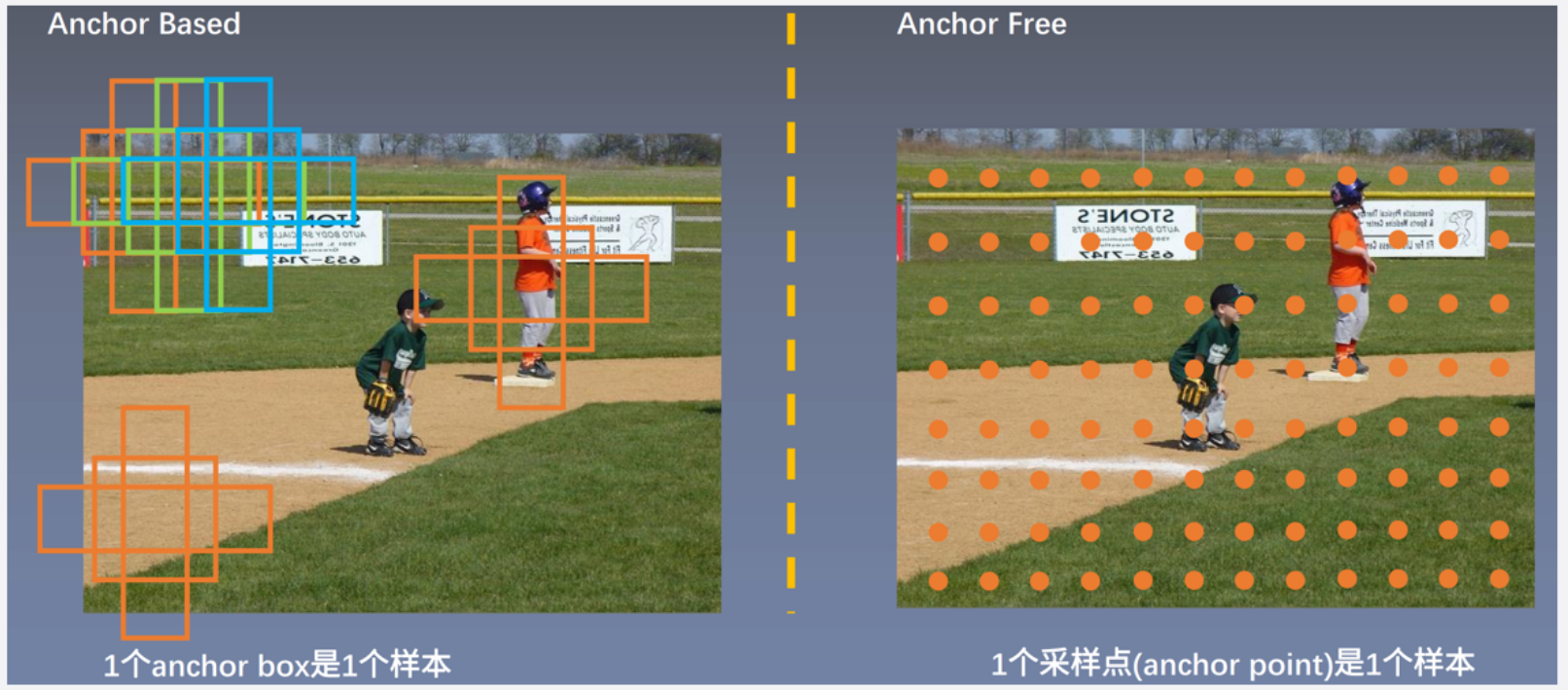
基于锚点(左侧图示)
- 锚点框(Anchor Boxes):显示了多种尺寸和比例的锚点框覆盖在图像上,每个锚点框用于检测特定大小和形状的目标。这些框是预定义的,并在模型训练过程中学习调整以适应不同目标的最佳位置和尺寸。
- 特点:基于锚点的方法通常会生成大量候选框,每个框都需要评估和调整,以找到最符合目标的框。
无锚点(右侧图示)
- 锚点(Anchor Points):图中的橙色点表示锚点,这些点均匀分布在整个图像上。在无锚点检测系统中,这些点直接用于预测目标的中心或其他特征位置,而不是依赖预先定义的框。
- 特点:无锚点方法直接在每个锚点位置预测目标的存在性及其边界框属性(如宽度、高度),从而省去了处理大量候选框的需要。
好处:
- 简化处理:无锚点方法简化了目标检测的流程,因为它不需要为每个目标生成和调整多个候选框,减少了计算负担。
- 灵活性提升:由于无锚点方法不依赖于预定义的框尺寸和比例,它能更灵活地适应各种尺寸和形状的目标。
- 效率和速度:无锚点系统通常可以更快地处理图像,因为它减少了需要评估的候选框数量,尤其在高分辨率图像中效果更明显。
无锚点方法 生成的锚点,一般是够用的,如果是密集场景,那锚点方法更好。
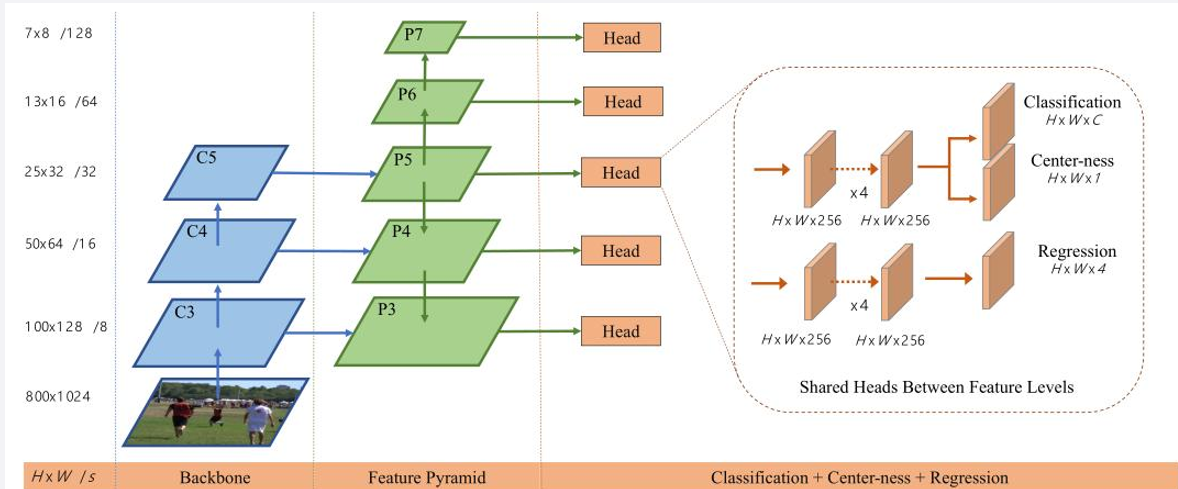
无锚点方法 的 锚点生成,使用FPN——不同的采样步长。
- 对于手套,属于小目标,那锚点生成就会特别密集(步长最小)
- 对于行人,属于中等目标,那锚点生成就会比较密集(步长中等)
- 对于草坪,属于大目标,那锚点生成就会比较宽松(步长较大)

YOLOX 有 5 种步长:
正负样本分配方法

在这个过程中,模型需要决定哪些点(采样点)可能是对象的一部分。
-
选择采样点:
- 从模型的不同输出中选取一些点,这些点可能包含我们要检测的对象。
-
确定哪些点是正样本(即这些点属于某个对象):
- 内部点:选择那些直接在对象标记的区域内的点。
- 中心点:选择那些靠近对象中心的点。
- 合并点:将上述两种点合并,增加被选择为正样本的机会。
- 交集点:只选择同时满足内部和中心条件的点。
-
为每个候选正样本创建预测框:
- 根据模型,为每个选中的点生成一个框,预测这个框可能是对象的位置。
-
评估预测框:
- IoU计算:比较预测框和实际对象框的重叠程度。
- IoULoss计算:根据重叠程度计算损失,以帮助模型学习。
- 交叉熵损失计算:评估预测框的分类准确性。
如何基于已经计算好的损失值(包括IoU损失和分类损失)来进行最终的样本选择和匹配。
选择GT(真实对象)需要的正样本数量:
- 对每个GT,挑选前10个IoU最大的正样本。
- 对每个GT对应的10个IoU值进行排序,并选出其中一个最优的样本。
- 根据某些策略(可能是基于损失最小化),决定最终的正样本GT匹配。每个GT只选择一个最佳匹配的样本,然后不再使用其他样本。
对每个GT从正样本候选中选择最佳正样本:
- 对每个GT从正样本候选中选择具有最小总损失的正样本。
- 通过“损失惩罚权重”来调整每个GT候选正样本的cost(成本),基本上是按照每个anchor point的IoU损失与分类损失的加权合计来计算,以此确定每个GT的最佳匹配anchor。
在这个过程中,系统通过计算每个候选正样本与真实对象框(GT)之间的IoU损失和分类损失,然后结合这些损失来决定哪些候选最适合作为正样本。
最后,每个真实对象框选择与之匹配最好(即总损失最低)的候选正样本。
损失函数
X. 目标检测算法轻量化技巧

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









