







谱分析的参数化方法
1. 非参数化方法与参数化方法
1.1 非参数化方法
Parametric Methods of Spectral Aanlysis \text{Parametric Methods of Spectral Aanlysis} Parametric Methods of Spectral Aanlysis
一般来说,谱分析的方法,包括参数化方法和非参数化的方法。
我们可以思考一下之前做谱分析的思路。我们有N个离散的,有限长的数据,我们用这些数据来做功率谱估计
{ Z ( k ) } K = 1 N ⇒ S ^ Z ( ω ) Direct Data Domain \{ Z(k) \}^N_{K=1} \Rightarrow \hat S_Z(\omega) \quad \text{Direct Data Domain} {Z(k)}K=1N⇒S^Z(ω)Direct Data Domain
我们做的时候,并没有对数据进行建模。是直接对数据域进行操作,然后得到了功率谱的估计。我们之前学过了一些谱分析方法,如周期图、滤波器组、Multitaper、Capon都是这样的。这些都是非参数化的谱分析方法。
1.2 参数化方法
而我们还可以用其他方法来进行谱分析。我们可以首先通过有限长的离散数据,对数据进行建模,搞清楚这个数据来源于一个什么样的随机过程,然后再基于我们的模型,计算功率谱。
{ Z ( k ) } K = 1 N ⇒ M o d e l ⇒ S ^ Z ( ω ) \{ Z(k) \}^N_{K=1} \Rightarrow \boxed{Model} \Rightarrow \hat S_Z(\omega) {Z(k)}K=1N⇒Model⇒S^Z(ω)
我们可以举一个形象的例子来说明参数化方法和非参数化方法。就相当于,我们做鱼,可以不看菜谱,直接放到水里煮一煮,虽然可能没有那么香,但是也好吃。我们也可以选择找一本菜谱,选择好一个适当的菜,按部就班的做。但是,如果我们步骤搞错了,鱼可能会做的很难吃,还比不上清水煮一煮。而如果步骤搞对了,鱼会做的非常好吃。
非参数化方法就像清水煮一煮,结果虽然准确性不一定很高,但是也不会错的特别离谱。而参数化的方法,如果模型建立对了,得到的结果准确性会非常好,而一旦模型建立的有问题,得到的结果可能会完全不对。对于非参数化方法来说,性能分数可能是六七十分的及格分。而参数化方法得到的确实非九十及二十的极端分布。
参数化方法的优缺点是非常明显的。
- 优点:性能好 Performance
- 缺点:数据失配 Mismatch
Pros: Performance Cons: Mismatch \text{Pros: Performance} \\ \text{Cons: Mismatch} Pros: PerformanceCons: Mismatch
参数化方法具体的思路就是先用数据去估计模型的参数,然后用模型的参数去估计功率谱
2. 参数化方法模型的建立
2.1 有理谱
使用参数化方法,就必须建立一个合适的模型,我们的模型需要有这样的两个要求
- 普适性:对很多的谱都可以进行逼近
- 简便性:必须方便处理和计算
我们会通过有理谱的方式对功率谱进行描绘。所谓有理谱,就是我们的功率谱密度是一个有理的分式。其中P是一个多项式。Q是另外一个多项式。
Rational Spectrum S Z ( ω ) ⇒ S Z ( ω ) = P ( ω ) Q ( ω ) ⇒ Universal and Simple P ( ω ) = ∑ k p i e x p ( j ω k ) Q ( ω ) = ∑ k q i e x p ( j ω k ) \text{Rational Spectrum } \\ S_Z(\omega)\Rightarrow S_Z(\omega) = \frac{P(\omega)}{Q(\omega)} \Rightarrow \text{Universal and Simple} \\ P(\omega) = \sum_k p_i exp(j \omega k) \quad Q(\omega) = \sum_k q_i exp(j \omega k) Rational Spectrum SZ(ω)⇒SZ(ω)=Q(ω)P(ω)⇒Universal and SimpleP(ω)=k∑piexp(jωk)Q(ω)=k∑qiexp(jωk)
我们使用有理分式的方法去作为模型描绘功率谱是否满足模型建立的两个条件呢?
首先是通用性,多项式可以逼近任何一种连续谱。我们加上分母以后,对连续谱的刻画能力会更强。能够在多项式次数比较低的情况下就完成刻画
同时,多项式本身也比较简单。能够满足我们普适、简单的条件。
2.2 模型的建立
既然使用有理分式进行建模是可行的,下面我们就使用有理分式去进行建模。
因为,功率谱是大于等于0的,所以,我们对我们的多项式也有要求,多项式必须也大于等于0。因此,我们可以把我们的多项式写作更低次有理分式模平方的形式
S Z ( ω ) ≥ 0 ⇒ P ( ω ) Q ( ω ) = ∣ B ( ω ) A ( ω ) ∣ 2 P ( ω ) = ∑ k p i e x p ( j ω k ) Q ( ω ) = ∑ k q i e x p ( j ω k ) S_Z(\omega) \geq 0 \Rightarrow \frac{P(\omega)}{Q(\omega)} = |\frac{B(\omega)}{A(\omega)}|^2 \\ P(\omega) = \sum_k p_i exp(j \omega k) \quad Q(\omega) = \sum_k q_i exp(j \omega k) SZ(ω)≥0⇒Q(ω)P(ω)=∣A(ω)B(ω)∣2P(ω)=k∑piexp(jωk)Q(ω)=k∑qiexp(jωk)
我们希望我们这个低阶有理分式的系数是1,就是k=0的时候,得到的结果是1。我们可以通过提出一个系数的方式来实现。这里符号就不换了。
S Z ( ω ) = ∣ B ( ω ) A ( ω ) ∣ 2 = σ 2 ∣ B ( ω ) A ( ω ) ∣ 2 ( i ) S_Z(\omega) = |\frac{B(\omega)}{A(\omega)}|^2 = \sigma^2|\frac{B(\omega)}{A(\omega)}|^2 \quad\quad(i) SZ(ω)=∣A(ω)B(ω)∣2=σ2∣A(ω)B(ω)∣2(i)
我们得到的式子(i)有三部分组成,分别是:一个常数,一个分式、一个模的平方。这个分式的样子其实非常像传递函数。
对于随机信号的功率谱,我们有这样的认识
- 随机信号的功率谱与相关函数是傅里叶变换对的关系
- 宽平稳随机过程通过线性时不变系统之后,功率谱密度的变化等于输入的功率谱密度乘以传递函数模的平方
- 宽平稳随机过程可以写成谱表示的形式
如果我们把(i)式子看做是一个功率谱乘以一个传递函数模的平方,我们就可以通过找到输入量是什么随机过程,然后得到输出的是一个什么随机过程。
从(i)式可以看出,输入随机过程的功率谱是个常数。而白噪声的功率谱是常数,因此,我们可以把这个模型当做白噪声通过一个线性系统来看待
S Z ( ω ) = ∣ B ( ω ) A ( ω ) ∣ 2 = σ 2 ∣ B ( ω ) A ( ω ) ∣ 2 ⇒ e ( k ) → B ( ω ) A ( ω ) → Z ( k ) S_Z(\omega) = |\frac{B(\omega)}{A(\omega)}|^2 = \sigma^2|\frac{B(\omega)}{A(\omega)}|^2 \\ \Rightarrow e(k) \rightarrow \boxed{\frac{B(\omega)}{A(\omega)}} \rightarrow Z(k) SZ(ω)=∣A(ω)B(ω)∣2=σ2∣A(ω)B(ω)∣2⇒e(k)→A(ω)B(ω)→Z(k)
其中
Z ( k ) = H ( e ( k ) ) H ( Z ) = B ( Z ) A ( Z ) ⇒ { B ( Z ) = ∑ k = 0 n − 1 β k Z k β 0 = 1 A ( Z ) = ∑ k = 0 m − 1 α k Z k α 0 = 1 Z(k) = H(e(k)) \\ H(Z) = \frac{B(Z)}{A(Z)} \Rightarrow \begin{cases} B(Z) = \sum_{k=0}^{n-1} \beta_k Z^k & \beta_0 = 1 \\ \\ A(Z) = \sum_{k=0}^{m-1} \alpha_k Z^k & \alpha_0 = 1 \end{cases} Z(k)=H(e(k))H(Z)=A(Z)B(Z)⇒⎩⎪⎨⎪⎧B(Z)=∑k=0n−1βkZkA(Z)=∑k=0m−1αkZkβ0=1α0=1
因此,我们就完成了我们的建模。我们只要把传递函数中的α和β求解出来,我们就能够得到我们的模型和功率谱
{ Z ( k ) } K = 1 N ⇒ { α k , β k } \{ Z(k) \}^N_{K=1} \Rightarrow \{\alpha_k,\beta_k \} {Z(k)}K=1N⇒{αk,βk}
现在问题变成了,我们要用采样得到的数据,去估计参数α和β。只要我们把这个参数估计清楚了,这个谱自然就出现了
除此之外,我们还需要确定一个东西,就是阶数。但是,参数化方法的阶数是非常难确定的。而且阶数如果估计少了,得到的谱可能会是完全错误的
{ Z ( k ) } K = 1 N ⇒ { α k } k = 0 m − 1 { β k } k = 0 m − 1 ( m , n ) \{ Z(k) \}^N_{K=1} \Rightarrow \{\alpha_k\}_{k=0}^{m-1}\quad \{ \beta_k\}_{k=0}^{m-1} \quad (m,n) {Z(k)}K=1N⇒{αk}k=0m−1{βk}k=0m−1(m,n)
这样的话Z就会满足如下的模型
ARMA Z ( k ) + ∑ i = 1 m − 1 α i Z ( k − i ) = e ( k ) + ∑ i = 1 n − 1 β i e ( k − i ) ( i i ) \text{ARMA} Z(k) + \sum_{i=1}^{m-1} \alpha_i Z(k-i) = e(k) +\sum_{i=1}^{n-1} \beta_i e(k-i) \quad\quad(ii) ARMAZ(k)+i=1∑m−1αiZ(k−i)=e(k)+i=1∑n−1βie(k−i)(ii)
Minimum-Phase H ( Z ) = B ( Z ) A ( Z ) ⇒ ∣ Z ∣ < 1 \text{Minimum-Phase} H(Z) = \frac{B(Z)}{A(Z)} \Rightarrow |Z| <1 Minimum-PhaseH(Z)=A(Z)B(Z)⇒∣Z∣<1
我们认为Z是白噪声激励一个系统得到的输出。并且这个线性系统既有极点也有零点。我们对这个线性系统做一个假设。我们假设这个线性系统具有极小相位。也就是不管是A还是B,他们的零点都在单位圆里面
这个方程有名字,叫做ARMA模型
2.3 ARMA概述
我们来看一下ARMA模型
ARMA Z ( k ) + ∑ i = 1 m − 1 α i Z ( k − i ) = e ( k ) + ∑ i = 1 n − 1 β i e ( k − i ) ( i i ) \text{ARMA} Z(k) + \sum_{i=1}^{m-1} \alpha_i Z(k-i) = e(k) +\sum_{i=1}^{n-1} \beta_i e(k-i) \quad\quad(ii) ARMAZ(k)+i=1∑m−1αiZ(k−i)=e(k)+i=1∑n−1βie(k−i)(ii)
ARMA模型可以看做两部分。前面一部分是自回归模型。回归是用一种对象表达另外一种对象。自回归就是用自身的历史去表征自身的现在。
Auto-Regression(AR) Z ( k ) + ∑ i = 1 m − 1 α i Z ( k − i ) \text{Auto-Regression(AR)} \\ Z(k) + \sum_{i=1}^{m-1} \alpha_i Z(k-i) Auto-Regression(AR)Z(k)+i=1∑m−1αiZ(k−i)
后面部分叫做滑动平均。滑动平均就是,白噪声通过时延得到不同的白噪声,然后通过线性组合得到的数据
Moving Average(MA)
e
(
k
)
+
∑
i
=
1
n
−
1
β
i
e
(
k
−
i
)
\text{Moving Average(MA)} \\ e(k) +\sum_{i=1}^{n-1} \beta_i e(k-i)
Moving Average(MA)e(k)+i=1∑n−1βie(k−i)
同时,ARMA模型还应该带上阶数
A R M A ( m − 1 , n − 1 ) ARMA(m-1,n-1) ARMA(m−1,n−1)
2.4 AR模型与MA模型
ARMA模型有两个特殊情况
- n=1
就只剩下自回归部分了。白噪声部分就没有了。我们称这种模型叫做AR模型
n = 1 ⇒ A R ( m − 1 ) A R : Z ( k ) + ∑ i = 1 m − 1 α i Z ( k − i ) = e ( k ) ( i i i ) n=1 \Rightarrow AR(m-1) \\ AR: Z(k) +\sum_{i=1}^{m-1} \alpha_i Z(k-i) = e(k) \quad\quad(iii) n=1⇒AR(m−1)AR:Z(k)+i=1∑m−1αiZ(k−i)=e(k)(iii)
- m=1
如果m=1,自回归部分就没有了,就只剩下滑动平均了。就叫做MA模型
m = 1 ⇒ M A ( n − 1 ) M A : Z ( k ) = e ( k ) + ∑ i = 1 n − 1 β i e ( k − i ) ( i v ) m=1 \Rightarrow MA(n-1) \\ MA:Z(k) = e(k) +\sum_{i=1}^{n-1} \beta_i e(k-i) \quad\quad(iv) m=1⇒MA(n−1)MA:Z(k)=e(k)+i=1∑n−1βie(k−i)(iv)
3.AR模型
首先介绍一下AR模型实现谱估计
3.1 AR模型的求解
AR模型的求解有两种方法,分布是相关分析法和最小二乘法
n = 1 ⇒ A R ( m − 1 ) A R : Z ( k ) + ∑ i = 1 m − 1 α i Z ( k − i ) = e ( k ) ( i i i ) n=1 \Rightarrow AR(m-1) \\ AR: Z(k) +\sum_{i=1}^{m-1} \alpha_i Z(k-i) = e(k) \quad\quad(iii) n=1⇒AR(m−1)AR:Z(k)+i=1∑m−1αiZ(k−i)=e(k)(iii)
3.1.1 相关分析法
Correlation Analysis \text{Correlation Analysis} Correlation Analysis
相关分析法就是对AR模型左右分别做相关。
Z ( k ) , Z ( k − 1 ) , . . . E ( e 2 ( k ) ) = σ 2 Z(k),Z(k-1),...\\ E(e^2(k)) = \sigma^2 Z(k),Z(k−1),...E(e2(k))=σ2
Correlation Analysis E ( Z ( k ) Z ( k ) ) + ∑ i = 1 m − 1 α i E ( Z ( k − i ) Z ( k ) ) = E ( e ( k ) Z ( k ) ) ( v ) \text{Correlation Analysis} \\ E(Z(k)Z(k)) + \sum_{i=1}^{m-1}\alpha_i E(Z(k-i)Z(k)) = E(e(k)Z(k)) \quad\quad(v) Correlation AnalysisE(Z(k)Z(k))+i=1∑m−1αiE(Z(k−i)Z(k))=E(e(k)Z(k))(v)
从(iii)式子可以看到,Z(k)依赖于k时刻的白噪声和k时刻之前的数据。因此也就等价于Z(k)依赖于k时刻的白噪声和k时刻之前的白噪声。但是白噪声之间是不相关的。因此e(k)Z(k)的相关实际上就是白噪声的方差
所以(v)式子可以化为
⇒
r
0
+
∑
i
=
1
m
−
1
α
i
r
i
=
E
(
e
(
k
)
2
)
=
σ
2
\Rightarrow r_0 +\sum_{i=1}^{m-1}\alpha_i r_i = E(e(k)^2) = \sigma^2
⇒r0+i=1∑m−1αiri=E(e(k)2)=σ2
然后我们再引入其实时刻的数据做相关。因为数据Z(k)只与其之前时刻的白噪声相关,因此,后面的数是0
E ( Z ( k ) Z ( k − l ) ) + ∑ i = 1 m − 1 α i E ( Z ( k − i ) Z ( k − l ) ) = E ( e ( k ) Z ( k − l ) ) ( v i ) ⇒ r l + ∑ i = 1 m − 1 α i r l − i = 0 , l = 1 , 2 , . . . , m − 1 E(Z(k)Z(k-l)) + \sum_{i=1}^{m-1}\alpha_i E(Z(k-i)Z(k-l)) = E(e(k)Z(k-l)) \quad\quad(vi) \\ \Rightarrow r_l +\sum_{i=1}^{m-1}\alpha_i r_{l-i} = 0, \quad l = 1,2,...,m-1 E(Z(k)Z(k−l))+i=1∑m−1αiE(Z(k−i)Z(k−l))=E(e(k)Z(k−l))(vi)⇒rl+i=1∑m−1αirl−i=0,l=1,2,...,m−1
我们把所有的式子全都放到一起,可以得到wiener-hopf方程。也叫做yule-walker方程
Wiener-Hopf ( r 0 r 1 . . . r m − 1 r 1 r 0 . . . r m − 2 . . . . . . . . . . . . r m − 1 r m − 2 . . . r 0 ) ∗ ( 1 α 1 . . . α m − 1 ) = ( σ 2 0 . . . 0 ) \text{Wiener-Hopf}\\ \begin{pmatrix} r_0 & r_1 & ... & r_{m-1} \\ r_1 & r_0 & ... & r_{m-2} \\ ... & ... & ... & ... \\ r_{m-1} & r_{m-2} & ... & r_0 \end{pmatrix}* \begin{pmatrix} 1 \\ \alpha_1 \\ ... \\ \alpha_{m-1} \end{pmatrix} = \begin{pmatrix} \sigma^2 \\ 0 \\ ...\\ 0 \end{pmatrix} Wiener-Hopf⎝⎜⎜⎛r0r1...rm−1r1r0...rm−2............rm−1rm−2...r0⎠⎟⎟⎞∗⎝⎜⎜⎛1α1...αm−1⎠⎟⎟⎞=⎝⎜⎜⎛σ20...0⎠⎟⎟⎞
toplitz矩阵可以使用levension迭代的方法进行求解。
3.1.2 最小二乘法
Least Sauare \text{Least Sauare} Least Sauare
另外一个思路是基于最小二乘来求解AR模型
Z ( k ) + ∑ i = 1 m − 1 α i Z ( k − i ) = e ( k ) Z(k) +\sum_{i=1}^{m-1} \alpha_i Z(k-i) = e(k) Z(k)+i=1∑m−1αiZ(k−i)=e(k)
m i n α E ∣ Z ( k ) − ∑ i = 1 m − 1 α i Z ( k − i ) ∣ 2 min_\alpha E|Z(k) - \sum_{i=1}^{m-1} \alpha_i Z(k-i)|^2 minαE∣Z(k)−i=1∑m−1αiZ(k−i)∣2
但是这里我们需要考虑一下,在这里做最小二乘和AR模型的式子是等价的吗?
最小二乘说,历史的组合应该尽可能逼近现在。而方程式说,现在与之前的组合应该是白噪声
这两件事情看似不同,实际上具有一个交汇点。就是正交性原理
正交性原理说明,最优的误差和所有原材料都是正交的。而对于白噪声来说,白噪声和k时刻之前的数据都是无关的,因此是正交的。因此,白噪声一定是最小二乘的最优估计误差。但是最小二乘的解和AR模型的白噪声却不一定是同一个。但是彼此之间也一定存在倍数关系。因此,是可以用最小二乘得到的系数来求解AR模型的。
因此在信号处理中,经常有这样的事情,当信号组合是白噪声的时候,就可以认为是在做最优逼近。
m i n α E ∣ Z ( k ) − ∑ i = 1 m − 1 α i Z ( k − i ) ∣ 2 ⇔ P r o j { Z ( k − 1 ) , . . , Z ( k − m + 1 ) } Z ( k ) min_\alpha E|Z(k) - \sum_{i=1}^{m-1} \alpha_i Z(k-i)|^2 \Leftrightarrow Proj_{\{Z(k-1),..,Z(k-m+1)\}} Z(k) minαE∣Z(k)−i=1∑m−1αiZ(k−i)∣2⇔Proj{Z(k−1),..,Z(k−m+1)}Z(k)
而对于最小二乘问题的求解,我们已经很熟悉了,这里就不进行展开讨论了。
3.2 AR模型的谱
AR模型得到的谱是这样的
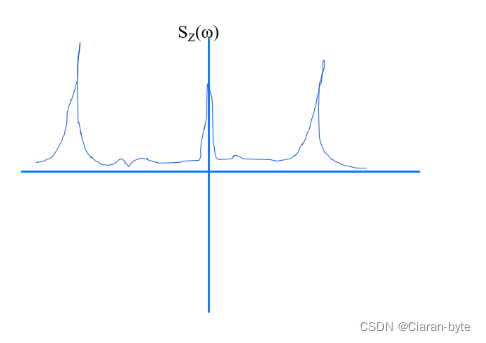
AR模型的谱非常好。不过收益和风险并存。因为AR模型阶数非常关键。对于周期图来说,功率谱尽管存在谱泄漏的问题,单总归功率谱的形状是对的。但是对于AR模型,一旦AR模型的阶数选错了,得到的功率谱结果可能是完全离谱的。如果信号谱中有三个峰,AR模型至少应该是三阶的。如果阶数选的不对,得到的峰就是伪峰。而且是位置完全不对的。
我们如果想确定AR模型的阶数,没有什么特别准确的方法。大部分论文都是paper work。还是要一阶一阶的尝试,直到得到的功率谱形状稳定了为止。
但是这样尝试下去非常耗时间,因此,我们下面要介绍一下AR模型的阶和Capon谱之间的关系。
3.3 AR模型的阶与Capon谱
3.3.1 相关矩阵等式
AR谱得到的功率谱表示为
S ^ A R ( ω ) = σ 2 ∣ 1 + α ^ 1 e x p ( j ω ) + . . . + . . α ^ m − 1 e x p ( j ( m − 1 ) ω ) ∣ 2 \hat S_{AR}(\omega) = \frac{\sigma^2}{|1+\hat \alpha_1 exp(j\omega)+...+..\hat \alpha_{m-1}exp(j(m-1)\omega)|^2} S^AR(ω)=∣1+α^1exp(jω)+...+..α^m−1exp(j(m−1)ω)∣2σ2
之前使用相关分析法的时候,对m-1阶的toplitz矩阵,会得到这样的式子
( r 0 r 1 . . . r m − 1 r 1 r 0 . . . r m − 2 . . . . . . . . . . . . r m − 1 r m − 2 . . . r 0 ) ∗ ( 1 α 1 ( m − 1 ) . . . α m − 1 ( m − 1 ) ) = ( σ 2 0 . . . 0 ) \begin{pmatrix} r_0 & r_1 & ... & r_{m-1} \\ r_1 & r_0 & ... & r_{m-2} \\ ... & ... & ... & ... \\ r_{m-1} & r_{m-2} & ... & r_0 \end{pmatrix}* \begin{pmatrix} 1 \\ \alpha_1^{(m-1)} \\ ... \\ \alpha_{m-1}^{(m-1)} \end{pmatrix} = \begin{pmatrix} \sigma^2 \\ 0 \\ ...\\ 0 \end{pmatrix} ⎝⎜⎜⎛r0r1...rm−1r1r0...rm−2............rm−1rm−2...r0⎠⎟⎟⎞∗⎝⎜⎜⎛1α1(m−1)...αm−1(m−1)⎠⎟⎟⎞=⎝⎜⎜⎛σ20...0⎠⎟⎟⎞
我们知道toplitz矩阵右下角仍然是toplitz矩阵,因此对于m-2阶的矩阵也能得到类似的关系,我们把所有关系组合在一起,可以得到下面的式子
( r 0 r 1 . . . r m − 1 r 1 r 0 . . . r m − 2 . . . . . . . . . . . . r m − 1 r m − 2 . . . r 0 ) ∗ ( 1 α 1 ( m − 1 ) 1 0 . . . α 1 ( m − 2 ) 1 . . . . . . . . . 1 . . . . . . . . . . . . α m − 1 ( m − 1 ) α m − 2 ( m − 2 ) . . . . . . 1 ) = ( σ 2 0 σ 2 ∗ . . . 0 σ 2 . . . . . . . . . . . . . . . . . . . . . . . . 0 0 0 . . . 0 ) \begin{pmatrix} r_0 & r_1 & ... & r_{m-1} \\ r_1 & r_0 & ... & r_{m-2} \\ ... & ... & ... & ... \\ r_{m-1} & r_{m-2} & ... & r_0 \end{pmatrix}* \begin{pmatrix} 1& \\ \alpha_1^{(m-1)}&1&&0 \\ ...&\alpha_1^{(m-2)}&1\\ ...&... &...&1\\ ...&...&...&...\\ \alpha_{m-1}^{(m-1)}&\alpha_{m-2}^{(m-2)}&...&...&1 \end{pmatrix} = \begin{pmatrix} \sigma^2 \\ 0 &\sigma^2 &&*\\ ...&0&\sigma^2\\ ...&...&...&...\\ ...&...&...&...\\ 0&0&0&...&0 \end{pmatrix} ⎝⎜⎜⎛r0r1...rm−1r1r0...rm−2............rm−1rm−2...r0⎠⎟⎟⎞∗⎝⎜⎜⎜⎜⎜⎜⎜⎛1α1(m−1).........αm−1(m−1)1α1(m−2)......αm−2(m−2)1.........01......1⎠⎟⎟⎟⎟⎟⎟⎟⎞=⎝⎜⎜⎜⎜⎜⎜⎛σ20.........0σ20......0σ2......0∗.........0⎠⎟⎟⎟⎟⎟⎟⎞
这里注意一下,左边的α矩阵右上角一定是0,而右边的σ矩阵右上角不一定是0
我们可以得到这样一个结论:Toplitz矩阵乘以对角线元素全为1的下三角,得到一个对角元全是σ2的上三角
3.3.2 相关矩阵的分解
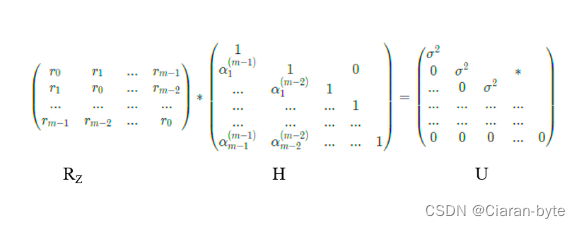
R H = U RH = U RH=U
我们对这个等式左乘一个矩阵构成合同变换
H T R H = H T U = U ~ H^T R H = H^T U = \widetilde U HTRH=HTU=U
H的转置是对角线元全是1的上三角。因此HT*U仍然是一个上三角矩阵。H由于对角线都是1,所有U~的对角线元还是σ2
由于对称矩阵经过合同变换仍然是对称的。因此,右边的矩阵也是对称的。又因为U~还应该是个上三角也就意味着,U~矩阵只能是对角阵。
U ~ ⇒ d i a g ( σ 2 , . . . , σ 2 ) \widetilde U \Rightarrow diag(\sigma^2,...,\sigma^2) U ⇒diag(σ2,...,σ2)
因此,相关矩阵有了另外一种表达方法了
H
T
R
H
=
d
i
a
g
(
σ
2
,
.
.
.
,
σ
2
)
⇒
R
Z
=
(
H
T
)
−
1
d
i
a
g
(
σ
2
,
.
.
.
,
σ
2
)
H
−
1
H^T R H = diag(\sigma^2,...,\sigma^2) \\ \Rightarrow R_Z = (H^T)^{-1}diag(\sigma^2,...,\sigma^2) H^{-1}
HTRH=diag(σ2,...,σ2)⇒RZ=(HT)−1diag(σ2,...,σ2)H−1
这不是特征分解。但是也是找到了另外一种相关矩阵对角化的方法
我们对这个相关矩阵求逆
⇒ R Z − 1 = H d i a g ( 1 σ 2 , . . . , 1 σ 2 ) H T ( 1 ) \Rightarrow R_Z^{-1} = H diag(\frac{1}{\sigma^2},...,\frac{1}{\sigma^2}) H^{T} \quad\quad(1) ⇒RZ−1=Hdiag(σ21,...,σ21)HT(1)
3.3.3 相关矩阵与Capon谱
下面我们来写一个capon谱的表示
S ^ c a p o n ( ω ) = 1 a H ( ω ) R Z − 1 a ( ω ) ( 2 ) a ( ω ) = ( 1 , e x p ( j ω ) , . . . , e x p ( j ( m − 1 ) ω ) T \hat S_{capon}(\omega) = \frac{1}{a^H(\omega)R_Z^{-1}a(\omega)} \quad\quad(2) \\ a(\omega) = (1,exp(j\omega),...,exp(j(m-1)\omega)^T S^capon(ω)=aH(ω)RZ−1a(ω)1(2)a(ω)=(1,exp(jω),...,exp(j(m−1)ω)T
把(1)代入(2)中
S ^ c a p o n ( ω ) = 1 a H ( ω ) H d i a g ( 1 σ 2 , . . . , 1 σ 2 ) H T a ( ω ) \hat S_{capon}(\omega) = \frac{1}{a^H(\omega)H diag(\frac{1}{\sigma^2},...,\frac{1}{\sigma^2}) H^{T}a(\omega)} S^capon(ω)=aH(ω)Hdiag(σ21,...,σ21)HTa(ω)1
H T a ( ω ) = ( 1 α 1 ( m − 1 ) . . . α m − 1 ( m − 1 ) . . . . . . . . . . . . . . 1 ) ∗ ( 1 e x p ( j ω ) . . . e x p ( j ( m − 1 ) ω ) ) = ( 1 + α 1 ( m − 1 ) e x p ( j ω ) + . . . + α m − 1 ( m − 1 ) e x p ( j ( m − 1 ) ω ) e x p ( j ω ) ( 1 + α 1 ( m − 2 ) e x p ( j ω ) + . . . + α m − 2 ( m − 2 ) e x p ( j ( m − 2 ) ω ) ) e x p ( 2 j ω ) ( 1 + α 1 ( m − 3 ) e x p ( j ω ) + . . . + α m − 2 ( m − 3 ) e x p ( j ( m − 3 ) ω ) ) . . . e x p ( j ( m − 1 ) ω ) ) H^T a(\omega) = \begin{pmatrix} 1 &\alpha^{(m-1)}_1 &...&\alpha^{(m-1)}_{m-1}\\ &...&...&... \\ &&..&... \\ &&&1 \end{pmatrix}* \begin{pmatrix} 1\\ exp(j\omega)\\ ...\\ exp(j(m-1)\omega) \end{pmatrix} \\ = \begin{pmatrix} 1+\alpha_1^{(m-1)}exp(j\omega)+...+\alpha_{m-1}^{(m-1)}exp(j(m-1)\omega)\\ exp(j\omega)(1+\alpha_1^{(m-2)}exp(j\omega)+...+\alpha_{m-2}^{(m-2)}exp(j(m-2)\omega))\\ exp(2j\omega)(1+\alpha_1^{(m-3)}exp(j\omega)+...+\alpha_{m-2}^{(m-3)}exp(j(m-3)\omega))\\ ...\\ exp(j(m-1)\omega) \end{pmatrix} HTa(ω)=⎝⎜⎜⎛1α1(m−1)...........αm−1(m−1)......1⎠⎟⎟⎞∗⎝⎜⎜⎛1exp(jω)...exp(j(m−1)ω)⎠⎟⎟⎞=⎝⎜⎜⎜⎜⎜⎛1+α1(m−1)exp(jω)+...+αm−1(m−1)exp(j(m−1)ω)exp(jω)(1+α1(m−2)exp(jω)+...+αm−2(m−2)exp(j(m−2)ω))exp(2jω)(1+α1(m−3)exp(jω)+...+αm−2(m−3)exp(j(m−3)ω))...exp(j(m−1)ω)⎠⎟⎟⎟⎟⎟⎞
我们再表示一下分母
a H ( ω ) H d i a g ( 1 σ 2 , . . . , 1 σ 2 ) H T a ( ω ) = 1 σ 2 ∣ ∣ H T a ( ω ) ∣ ∣ 2 = 1 σ 2 ∑ k = 1 m − 1 ∣ 1 + ∑ i = 1 k α i ( k ) e x p ( j ω k ) ∣ 2 = ∑ k = 1 m − 1 1 S A R ( k ) ( ω ) a^H(\omega)H diag(\frac{1}{\sigma^2},...,\frac{1}{\sigma^2}) H^{T}a(\omega) \\ = \frac{1}{\sigma^2} ||H^T a(\omega)||^2 = \frac{1}{\sigma^2} \sum_{k=1}^{m-1}|1+\sum_{i=1}^k \alpha_i ^{(k)}exp(j\omega k)|^2 = \sum_{k=1}^{m-1}\frac{1}{S_{AR}^{(k)}(\omega)} aH(ω)Hdiag(σ21,...,σ21)HTa(ω)=σ21∣∣HTa(ω)∣∣2=σ21k=1∑m−1∣1+i=1∑kαi(k)exp(jωk)∣2=k=1∑m−1SAR(k)(ω)1
可得
S ^ c a p o n ( ω ) = 1 ∑ k = 1 m − 1 1 S A R ( k ) ( ω ) \hat S_{capon}(\omega) = \frac{1}{\sum_{k=1}^{m-1}\frac{1}{S_{AR}^{(k)}(\omega)}} S^capon(ω)=∑k=1m−1SAR(k)(ω)11
因此,我们发现,capon谱,就是不同阶数的AR谱的调和平均
调和平均就是分之一的和再分之一。最典型的就是并联电路的电阻
所以说capon谱非常好用,因为capon把AR模型的每一阶都试过了。然后用某种方式平均了一下。所以capon谱大家非常喜欢用
因为AR谱分析阶数非常难找,不好用。最好的方法还是一个一个试过去。那还不如用capon
4.MA模型
刚才我们研究了自回归模型,现在我们来看看滑动平均模型
M A : Z ( k ) = e ( k ) + ∑ i = 1 n − 1 β i e ( k − i ) MA:Z(k) = e(k) +\sum_{i=1}^{n-1} \beta_i e(k-i) MA:Z(k)=e(k)+i=1∑n−1βie(k−i)
首先,我们来看功率谱的完整定义
S Z ( ω ) = ∑ k = − ∞ + ∞ r k e x p ( − j ω k ) S_Z(\omega) = \sum_{k=-\infty}^{+\infty} r_k exp(-j\omega k) SZ(ω)=k=−∞∑+∞rkexp(−jωk)
对功率谱估计难的地方在于,我们的数据不是无限长的,因此产生的相关函数也不可能是无限长的。我们必须用有限的数据去估计无限远处的相关函数
{ Z ( k ) } k = 1 N → { r k } k = − ( N − 1 ) N − 1 \{ Z(k)\} _{k=1}^N \rightarrow \{ r_k \}^{N-1}_{k=-(N-1)} {Z(k)}k=1N→{rk}k=−(N−1)N−1
我们其实可以采取截断的方法,远处的相关函数就不要了。事实上,周期图就是这么做的,而且还加了一个窗,隔得远的认为估计会有问题,就抑制了。
但是对于MA来说,这个问题不存在,我们可以直接使用定义式求解功率谱。因为数据是一段白噪声的叠加。如果两个数据相隔的很远,白噪声没有重叠的段,相关函数就会是0,自然而然就被截断了。因此,按理来说,MA可以使用定义式去完美的计算功率谱
r k = 0 ( ∣ k ∣ > n ) ⇒ { r − ( n − 1 ) , r − ( n − 2 ) , . . . , r n − 2 , r n − 1 } r_k = 0 (|k| >n) \Rightarrow \{r_{-(n-1)}, r_{-(n-2)},...,r_{n-2},r_{n-1} \} rk=0(∣k∣>n)⇒{r−(n−1),r−(n−2),...,rn−2,rn−1}
5. ARMA模型
相比于AR模型和MA模型,ARMA模型更加复杂。
Z ( k ) + ∑ i = 1 m − 1 α i Z ( k − i ) = e ( k ) + ∑ i = 1 n − 1 β i e ( k − i ) Z(k) + \sum_{i=1}^{m-1} \alpha_i Z(k-i) = e(k) +\sum_{i=1}^{n-1} \beta_i e(k-i) Z(k)+i=1∑m−1αiZ(k−i)=e(k)+i=1∑n−1βie(k−i)
5.1 相关分析法
与AR模型类似,我们也首先尝试用相关的方法来进行计算。
但是,由于右边有个尾部,Z(k)又是与k时刻之前的白噪声是相关的,我们得想个办法,把尾巴截断掉。
所以,我们可以找到一个跟k距离非常远的数据Z(k-l),使得Z(k-l)与Z(k)的白噪声全部都不相关
Z ( k ) Z ( k − l ) + ∑ i = 1 m − 1 α i Z ( k − i ) Z ( k − l ) = ( e ( k ) + ∑ i = 1 n − 1 β i e ( k − i ) ) ( Z ( k − l ) ) ⇒ r l + ∑ i = 1 m − 1 α i r l − i = 0 ( ∣ l ∣ > n ) ⇒ { α i } Z(k)Z(k-l) + \sum_{i=1}^{m-1} \alpha_i Z(k-i) Z(k-l) = (e(k) +\sum_{i=1}^{n-1} \beta_i e(k-i))(Z(k-l)) \\ \Rightarrow r_l + \sum_{i=1}^{m-1} \alpha_i r_{l-i} = 0 \quad (|l| >n) \Rightarrow \{\alpha_i \} Z(k)Z(k−l)+i=1∑m−1αiZ(k−i)Z(k−l)=(e(k)+i=1∑n−1βie(k−i))(Z(k−l))⇒rl+i=1∑m−1αirl−i=0(∣l∣>n)⇒{αi}
通过这种方法,我们就能够得到AR部分,并且计算出α
我们知道了左端的AR部分的系数以后,就可以把左边作为一个已知的整体,然后把ARMA看做是一个MA模型继续求解
AR ⇒ { α i } ⇒ MA ⇒ { β i } \text{AR} \Rightarrow \{ \alpha_i \} \Rightarrow \text{MA} \Rightarrow \{ \beta_i\} AR⇒{αi}⇒MA⇒{βi}
这里有一个问题。因为相关角标越小,计算的结果越精确。相关角标大,数据就不准确。但是这里,我们相关的角标客观上来说就不会太小,所以,我们做ARMA模型的时候,可能就要求m和n充分小。
⇒ m , n ∈ { 1 , 2 } ⇒ A R M A ( 1 , 1 ) , ( 2 , 1 ) , ( 2 , 2 ) \Rightarrow m,n \in \{1,2 \} \Rightarrow ARMA(1,1),(2,1),(2,2) ⇒m,n∈{1,2}⇒ARMA(1,1),(2,1),(2,2)
5.2 Two-stage LS
基于AR模型可以用最小二乘求解的经验,ARMA也是可以使用最小二乘进行求解的。
我们把ARMA模型变一下形
Z ( k ) = − ∑ i = 1 m − 1 α i Z ( k − i ) + e ( k ) + ∑ i = 1 n − 1 β i e ( k − i ) = ( − Z ( k − 1 ) . . . − Z ( k − m + 1 ) e ( k − 1 ) . . . e ( k − n + 1 ) ) ∗ ( α 1 . . . α m − 1 β 1 . . . β n − 1 ) + e ( k ) Z(k) =-\sum_{i=1}^{m-1} \alpha_i Z(k-i) + e(k) +\sum_{i=1}^{n-1} \beta_i e(k-i) = \begin{pmatrix} -Z(k-1) & ... &-Z(k-m+1) & e(k-1) &... & e(k-n+1) \end{pmatrix} *\begin{pmatrix} \alpha_1 \\ ...\\ \alpha_{m-1} \\ \beta_1 \\ ...\\ \beta_{n-1} \end{pmatrix} + e(k) Z(k)=−i=1∑m−1αiZ(k−i)+e(k)+i=1∑n−1βie(k−i)=(−Z(k−1)...−Z(k−m+1)e(k−1)...e(k−n+1))∗⎝⎜⎜⎜⎜⎜⎜⎛α1...αm−1β1...βn−1⎠⎟⎟⎟⎟⎟⎟⎞+e(k)
让k取很多值,得到不同的方程,就能够做最小二乘了
但是做这个最小二乘有个问题,因为白噪声的部分,我们不知道,所以这个方程就没法解
有一个方法就行,先把白噪声估计出来。
因为我们的系统是白噪声通过线性系统的激励得到的数据。我们通过复分析的方法,可以把传递函数变换为只有分母。但是这种情况下,分母不会是个有限冲激响应,可能是个无限长的分式。
Z ( k ) = A ( Z ) B ( Z ) e ( k ) = 1 B ′ ( Z ) e ( k ) ⇒ Z ( k ) + ∑ i = 1 ∞ α i ~ Z ( k − i ) = e ( k ) Z(k) = \frac{A(Z)}{B(Z)} e(k) = \frac{1}{B'(Z)} e(k) \Rightarrow Z(k) + \sum_{i=1}^{\infty} \widetilde{\alpha_i} Z(k-i) = e(k) Z(k)=B(Z)A(Z)e(k)=B′(Z)1e(k)⇒Z(k)+i=1∑∞αi Z(k−i)=e(k)
然后我们做下近似,让(m+n)的整数倍作为数据长度
AR Z ( k ) = A ( Z ) B ( Z ) e ( k ) = 1 B ′ ( Z ) e ( k ) ⇒ Z ( k ) + ∑ i = 1 N α i ~ Z ( k − i ) = e ( k ) N = L ( m + n ) ⇒ { α i ~ } \text{AR} Z(k) = \frac{A(Z)}{B(Z)} e(k) = \frac{1}{B'(Z)} e(k) \Rightarrow Z(k) + \sum_{i=1}^{N} \widetilde{\alpha_i} Z(k-i) = e(k) \\ N = L(m+n) \\ \Rightarrow \{ \widetilde {\alpha_i}\} ARZ(k)=B(Z)A(Z)e(k)=B′(Z)1e(k)⇒Z(k)+i=1∑Nαi Z(k−i)=e(k)N=L(m+n)⇒{αi }
因此,我们得到了一个AR模型,可以使用AR模型的方法计算系数
这样就能够估计白噪声了。然后再把白噪声的数值代入。这种方法叫做两阶段最小二乘
Two-stage LS \text{Two-stage LS} Two-stage LS
这种方法可能非常不靠谱。因为白噪声在线性框架下是不可估计的。而且这样估计的白噪声不可能没有相关性
事实上,ARMA模型没有非常好的方法。使用第一种相关分析法做低维度的模型,算是比较靠谱的方案了。但是做到两阶以上风险很大。
6. AR模型与最大熵优化
6.1 概述
我们想从另外一个角度诠释AR模型。这里介绍一种最大熵的思想
Maximum Entropy \text{Maximum Entropy} Maximum Entropy
我们做谱分析最大的困难在于,数据长度是有限的,因此我们能够得到的相关也是有限的。我们必须要用有限长度的相关,去估计无穷长度相关得到的功率谱
我们有两种方案,一种方案是把其他得不得的相关函数截断为0。另外一种方案是让其他的相关函数以最自然的形式存在,我们把他们估计出来。
让相关函数以最自然的形式存在,就要尽可能的保留随机过程的随机性。因为从随机到确定的过程会加入很多的先验知识,在这个过程中会加入很多的解析。
因此,相当于,我们就要尽可能的去保留熵
Natural State ⇒ Most Random ⇒ Maximum Entropy \text{Natural State} \Rightarrow \text{Most Random} \Rightarrow \text{ Maximum Entropy} Natural State⇒Most Random⇒ Maximum Entropy
因此,我们下面需要解决这样的问题
- 如何定义宽平稳随机过程的熵
- 我们基于什么样的方案去进行熵最大的优化
我们的思路是这样的
(1)我们假设宽平稳随机过程记做Z,并且定义随机过程的熵H(Z)
{ Z ( k ) } k = − ∞ ∞ = Z W.S.S. Stochastic Processes H ( Z ) Entropy \{ Z(k)\} _{k=-\infty}^{\infty} = Z \quad \text{W.S.S. Stochastic Processes} \\ H(Z) \quad \text{Entropy} {Z(k)}k=−∞∞=ZW.S.S. Stochastic ProcessesH(Z)Entropy
(2) 我们把已知的相关函数作为约束条件,然后以最大熵为目标函数进行优化
m a x Z H ( Z ) s.t. r k = E ( Z ( n ) Z ( n − k ) ) = a k k = − ( N − 1 ) , . . . , ( N − 1 ) max_Z H(Z) \quad \text{s.t.} \quad r_k = E(Z(n)Z(n-k)) = a_k\\ k=-(N-1),...,(N-1) maxZH(Z)s.t.rk=E(Z(n)Z(n−k))=akk=−(N−1),...,(N−1)
6.2 熵的表示
6.2.1 单个随机变量的熵
因此,第一步,我们要明确随机过程的熵是什么。
先介绍一下单个随机变量的熵
H ( Z i ) = − ∫ − ∞ + ∞ f Z i ( x ) l o g f Z i ( x ) d x ( 1 ) H(Z_i) = -\int_{-\infty}^{+\infty} f_{Z_i}(x)log f_{Z_i}(x) dx \quad\quad (1) H(Zi)=−∫−∞+∞fZi(x)logfZi(x)dx(1)
其中,Zi满足f的分布函数
Z i ∼ f Z i ( x ) Z_i \sim f_{Z_i}(x) Zi∼fZi(x)
熵也可以写做这样的形式
H ( Z i ) = − E ( l o g ( f Z i ( Z i ) ) ) ( 2 ) H(Z_i) = -E(log(f_{Z_i}(Z_i))) \quad\quad (2) H(Zi)=−E(log(fZi(Zi)))(2)
我们举一个gaussian的例子
f Z ( x ) = 1 2 π σ e x p ( − ( x − μ ) 2 2 σ 2 ) f_Z(x) = \frac{1}{\sqrt{2 \pi} \sigma} exp(-\frac{(x-\mu)^2}{2 \sigma^2}) fZ(x)=2πσ1exp(−2σ2(x−μ)2)
H ( Z ) = − E ( l o g ( f Z ( Z ) ) ) = − E ( − 1 2 l o g ( 2 π σ 2 ) − ( Z − μ ) 2 2 σ 2 ) = 1 2 l o g ( 2 π σ 2 ) + E ( ( Z − μ ) 2 ) 2 σ 2 = 1 2 l o g ( 2 π σ 2 ) + σ 2 2 σ 2 = 1 2 ( l o g ( 2 π σ 2 ) + l o g e ) = 1 2 l o g ( 2 π e ) + l o g ( σ ) H(Z) = -E(log(f_{Z}(Z))) = -E(-\frac{1}{2}log(2 \pi \sigma^2)-\frac{(Z-\mu)^2}{2 \sigma^2}) \\ = \frac{1}{2}log(2 \pi \sigma^2)+\frac{E((Z-\mu)^2)}{2 \sigma^2} \\ = \frac{1}{2}log(2 \pi \sigma^2) + \frac{\sigma^2}{2 \sigma^2} \\ = \frac{1}{2}(log(2 \pi \sigma^2) +log e) \\ =\frac{1}{2} log(2\pi e) + log(\sigma) H(Z)=−E(log(fZ(Z)))=−E(−21log(2πσ2)−2σ2(Z−μ)2)=21log(2πσ2)+2σ2E((Z−μ)2)=21log(2πσ2)+2σ2σ2=21(log(2πσ2)+loge)=21log(2πe)+log(σ)
6.2.2 多维随机变量的熵
我们再定义一个多维随机变量的熵
假设多维随机变量的联合分布概率密度是f
则多维随机变量的熵表示为
H ( Z 1 , . . , Z n ) = ∫ R n f ( x 1 , . . . x n ) l o g ( f ( x 1 , . . . , x n ) ) d x 1 . . . d x n H(Z_1,..,Z_n) = \int _{R^n} f(x_1,...x_n) log(f(x_1,...,x_n)) dx_1...dx_n H(Z1,..,Zn)=∫Rnf(x1,...xn)log(f(x1,...,xn))dx1...dxn
6.2.3 随机过程的熵
随机过程的熵表示为,也叫做随机过程的熵率
Entropy Rate of Stochastic Processes H ( Z ) = l i m n → ∞ 1 n H ( Z n , . . . , Z 1 ) = l i m n → ∞ H ( Z n ∣ Z n + 1 , . . . , Z 1 ) \text{Entropy Rate of Stochastic Processes} H(Z) = lim_{n \rightarrow \infty} \frac{1}{n} H(Z_n,...,Z_1) \\ = lim_{n \rightarrow \infty} H(Z_n |Z_n+1,...,Z_1) Entropy Rate of Stochastic ProcessesH(Z)=limn→∞n1H(Zn,...,Z1)=limn→∞H(Zn∣Zn+1,...,Z1)
来证明一下
H ( Z n , . . . , Z 1 ) = H ( Z n ∣ Z n − 1 , . . . , Z 1 ) + H ( Z n − 1 , . . . Z 1 ) = H ( Z n ∣ Z n − 1 , . . . , Z 1 ) + . . . + H ( Z 2 ∣ Z 1 ) + H ( Z 1 ) = l i m n → ∞ 1 n H ( Z n , . . . , Z 1 ) H(Z_n,...,Z_1) = H(Z_n|Z_{n-1},...,Z_1) + H(Z_{n-1},...Z_1) \\ =H(Z_n|Z_{n-1},...,Z_1) +...+ H(Z_2 |Z_1) +H(Z_1) \\ = lim_{n \rightarrow \infty} \frac{1}{n} H(Z_n,...,Z_1) H(Zn,...,Z1)=H(Zn∣Zn−1,...,Z1)+H(Zn−1,...Z1)=H(Zn∣Zn−1,...,Z1)+...+H(Z2∣Z1)+H(Z1)=limn→∞n1H(Zn,...,Z1)
这实际上是离散的洛必达法则
l i m r → x 0 f ( x ) g ( x ) = l i m r → x 0 f ′ ( x ) g ′ ( x ) l i m n → ∞ A n B n = l i m r → ∞ A n − A n − 1 B n − B n − 1 lim_{r \rightarrow x_0} \frac{f(x)}{g(x)} = lim_{r \rightarrow x_0} \frac{f'(x)}{g'(x)} \\ lim_{n \rightarrow \infty} \frac{A_n}{B_n} = lim_{r \rightarrow \infty} \frac{A_n - A_{n-1}}{B_n - B_{n-1}} limr→x0g(x)f(x)=limr→x0g′(x)f′(x)limn→∞BnAn=limr→∞Bn−Bn−1An−An−1
也就是
l
i
m
n
→
∞
a
n
=
a
l
i
m
n
→
∞
a
1
+
.
.
.
+
a
n
n
=
a
A
n
=
a
1
+
.
.
+
a
n
A
n
−
1
=
a
1
+
.
.
+
a
n
−
1
B
n
=
n
B
n
−
1
=
n
−
1
lim_{n \rightarrow \infty} a_n = a \\ lim_{n \rightarrow \infty} \frac{a_1 + ... +a_n}{n} = a \\ A_n = a_1 + .. + a_n \\ A_{n-1} = a_1 + .. + a_{n-1} \\ B_n = n \\ B_{n-1} = n-1
limn→∞an=alimn→∞na1+...+an=aAn=a1+..+anAn−1=a1+..+an−1Bn=nBn−1=n−1
如果Z是高斯过程,联合高斯分布的条件分布仍然是高斯分布。
Z ( Gaussian Process ) Z n ∣ Z n − 1 , . . . , Z 1 ∼ N ( μ , σ 2 ) Z(\text{ Gaussian Process}) \quad Z_n |Z_{n-1},...,Z_1 \sim N(\mu,\sigma^2) Z( Gaussian Process)Zn∣Zn−1,...,Z1∼N(μ,σ2)
高斯过程的期望和方差
μ = E ( Z n ∣ Z n − 1 , . . , Z 1 ) = ∑ k = 1 n − 1 c k Z n − k σ 2 = E ( Z n − E ( Z n ∣ Z n − 1 , . . . , Z 1 ) ) 2 \mu = E(Z_n |Z_{n-1},..,Z_1) = \sum_{k=1}^{n-1}c_kZ_{n-k}\\ \sigma^2 = E(Z_n - E(Z_n|Z_{n-1},...,Z_1))^2 μ=E(Zn∣Zn−1,..,Z1)=k=1∑n−1ckZn−kσ2=E(Zn−E(Zn∣Zn−1,...,Z1))2
高斯过程均值的最优估计就是线性的。平均值就是最优逼近
同时,方差得到的就是最小的误差
E ∣ ϵ ( n ) ∣ 2 = σ 2 = E ( Z n − E ( Z n ∣ Z n − 1 , . . . , Z 1 ) ) 2 E|\epsilon(n)|^2 = \sigma^2 = E(Z_n - E(Z_n|Z_{n-1},...,Z_1))^2 E∣ϵ(n)∣2=σ2=E(Zn−E(Zn∣Zn−1,...,Z1))2
与高斯分布的熵相同,高斯过程的熵率就是
H ( Z ) = l i m n → ∞ H ( Z n ∣ Z n + 1 , . . . , Z 1 ) = c + 1 2 l o g σ 2 = c + 1 2 l o g ( E ∣ ϵ ( n ) ∣ 2 ) H(Z) = lim_{n \rightarrow \infty} H(Z_n |Z_n+1,...,Z_1) \\ = c + \frac{1}{2} log \sigma^2 \\ = c+ \frac{1}{2} log(E|\epsilon(n)|^2) H(Z)=limn→∞H(Zn∣Zn+1,...,Z1)=c+21logσ2=c+21log(E∣ϵ(n)∣2)
l i m n → ∞ E ∣ ϵ ( n ) ∣ 2 = l i m n → ∞ ∣ L 00 ( n ) ∣ 2 = ∣ b 0 ∣ 2 = e x p ( 1 2 π ∫ − π π l o g S ( ω ) d ω ) lim_{n \rightarrow \infty}E|\epsilon(n)|^2 = lim_{n \rightarrow \infty}|L_{00}^{(n)}|^2 = |b_0|^2 = exp(\frac{1}{2\pi}\int_{-\pi}^{\pi}log S(\omega)d\omega) limn→∞E∣ϵ(n)∣2=limn→∞∣L00(n)∣2=∣b0∣2=exp(2π1∫−ππlogS(ω)dω)
所以,我们就得到了高斯过程的熵。不过很多非高斯的随机过程也使用这个式子做熵率。
H ( Z ) = 1 4 π ∫ − π π l o g S ( ω ) d ω H(Z) = \frac{1}{4 \pi} \int_{-\pi}^{\pi}log S(\omega)d\omega H(Z)=4π1∫−ππlogS(ω)dω
6.3 最大熵优化
6.3.1 目标函数
有了随机过程熵的表示之后,我们就可以进行最大熵估计了
m a x S ∫ − π π l o g S ( ω ) d ω r k = a k = 1 2 π ∫ − π π S ( ω ) e x p ( j ω k ) d ω k = − ( N − 1 ) , . . . . , ( N − 1 ) L ( S , λ ) = 1 2 π ∫ − π π l o g S ( ω ) d ω − ∑ k = − N + 1 N − 1 λ k ( 1 2 π ∫ − π + π S ( ω ) e x p ( j ω k ) d ω − a k ) max_S \int_{-\pi}^{\pi} log S(\omega) d\omega \\ r_k = a_k=\frac{1}{2\pi}\int_{-\pi}^{\pi}S(\omega)exp(j\omega k )d\omega \quad k = -(N-1),....,(N-1) \\ L(S,\lambda) = \frac{1}{2\pi} \int_{-\pi}^{\pi} log S(\omega) d\omega - \sum_{k=-N+1}^{N-1} \lambda_k (\frac{1}{2 \pi} \int_{-\pi}^{+\pi}S(\omega)exp(j\omega k)d\omega - a_k) maxS∫−ππlogS(ω)dωrk=ak=2π1∫−ππS(ω)exp(jωk)dωk=−(N−1),....,(N−1)L(S,λ)=2π1∫−ππlogS(ω)dω−k=−N+1∑N−1λk(2π1∫−π+πS(ω)exp(jωk)dω−ak)
我们想用拉个朗日数乘法求解,然后我们没有办法求。因为功率谱是个函数,而且这里面是一个函数的函数,我们没有办法得到函数的导数。
因此,这里引入欧拉变分法来求解。
6.3.2 欧拉变分法
我们假设S0是最优的功率谱,并且S可以表示为
S 0 optimal Solution S ( ω ) = S 0 ( ω ) + t G ( ω ) S_0 \text{ optimal Solution} \\ S(\omega) = S_0(\omega) +t G(\omega) S0 optimal SolutionS(ω)=S0(ω)+tG(ω)
因此,熵可以表示为
H ( S ) = ∫ − π π l o g S ( ω ) d ω H ( t ) ~ = H ( S 0 + t G ) ≤ H ( S 0 ) ⇒ H ( t ) ~ ≤ H ( 0 ) ~ H(S) = \int_{-\pi}^{\pi}log S(\omega)d\omega \\ \widetilde{H(t)} = H(S_0 + tG) \leq H(S_0) \\ \Rightarrow \widetilde{H(t)} \leq \widetilde{H(0)} H(S)=∫−ππlogS(ω)dωH(t) =H(S0+tG)≤H(S0)⇒H(t) ≤H(0)
由于t为0的时候得到的是最优功率谱,熵是最大的,因此,我们也得到了一个重要的关系式。
这样我们就把功率谱的函数,变成了t的函数,就可以求导了
H ( t ) ~ = ∫ − π π l o g ( S 0 ( ω ) + t G ( ω ) ) d ω \widetilde{H(t)} = \int_{-\pi}^{\pi}log(S_0(\omega) +t G(\omega) )d\omega H(t) =∫−ππlog(S0(ω)+tG(ω))dω
6.3.3 拉格朗日数乘
现在,我们可以在新函数的基础上重新做拉格朗日数乘了
L ~ ( t , λ ) = H ~ ( t ) − ∑ k = − N + 1 N − 1 λ k ( 1 2 π ∫ − π + π S ( ω ) e x p ( j ω k ) d ω − a k ) = 1 2 π ∫ − π π l o g ( S 0 ( ω ) + t G ( ω ) ) d ω − ∑ k = − N + 1 N − 1 λ k ( 1 2 π ∫ − π + π ( S 0 ( ω ) + t G ( ω ) ) e x p ( j ω k ) d ω − a k ) \widetilde{L}(t,\lambda) =\widetilde H(t) - \sum_{k=-N+1}^{N-1} \lambda_k (\frac{1}{2 \pi} \int_{-\pi}^{+\pi}S(\omega)exp(j\omega k)d\omega - a_k) \\ = \frac{1}{2 \pi} \int_{-\pi}^{\pi}log(S_0(\omega) +t G(\omega) )d\omega - \sum_{k=-N+1}^{N-1} \lambda_k (\frac{1}{2 \pi} \int_{-\pi}^{+\pi}(S_0(\omega) +t G(\omega))exp(j\omega k)d\omega - a_k) L (t,λ)=H (t)−k=−N+1∑N−1λk(2π1∫−π+πS(ω)exp(jωk)dω−ak)=2π1∫−ππlog(S0(ω)+tG(ω))dω−k=−N+1∑N−1λk(2π1∫−π+π(S0(ω)+tG(ω))exp(jωk)dω−ak)
求导,并且t=0处的导数一定为0
d d t L ~ ( t , λ ) = 1 2 π ∫ − π π G ( ω ) S 0 + t G ( ω ) d ω − ∑ k = − N + 1 N − 1 λ k ( 1 2 π ∫ − π + π G ( ω ) e x p ( j ω k ) d ω ) \frac{d}{dt} \widetilde{L}(t,\lambda) = \frac{1}{2 \pi} \int_{-\pi}^{\pi} \frac{G(\omega)}{S_0 + tG(\omega)} d\omega - \sum_{k=-N+1}^{N-1} \lambda_k (\frac{1}{2 \pi}\int_{-\pi}^{+\pi} G(\omega)exp(j\omega k)d\omega ) \\ dtdL (t,λ)=2π1∫−ππS0+tG(ω)G(ω)dω−k=−N+1∑N−1λk(2π1∫−π+πG(ω)exp(jωk)dω)
令t为0
d d t L ~ ( t , λ ) ∣ t = 0 = 1 2 π ∫ − π π G ( ω ) S 0 d ω − ∑ k = − N + 1 N − 1 λ k ( 1 2 π ∫ − π + π G ( ω ) e x p ( j ω k ) d ω ) = 1 2 π ∫ − π π G ( ω ) ( 1 S 0 − ∑ k = − N + 1 N − 1 λ k e x p ( j ω k ) ) d ω = 0 \frac{d}{dt} \widetilde{L}(t,\lambda)|_{t=0} = \frac{1}{2 \pi} \int_{-\pi}^{\pi} \frac{G(\omega)}{S_0 } d\omega - \sum_{k=-N+1}^{N-1} \lambda_k (\frac{1}{2 \pi}\int_{-\pi}^{+\pi} G(\omega)exp(j\omega k)d\omega ) \\ = \frac{1}{2 \pi} \int_{-\pi}^{\pi}G(\omega)(\frac{1}{S_0}-\sum_{k=-N+1}^{N-1} \lambda_k exp(j\omega k) )d\omega = 0 dtdL (t,λ)∣t=0=2π1∫−ππS0G(ω)dω−k=−N+1∑N−1λk(2π1∫−π+πG(ω)exp(jωk)dω)=2π1∫−ππG(ω)(S01−k=−N+1∑N−1λkexp(jωk))dω=0
因为该式子对任意G成立,因此,必定有
1 S 0 − ∑ k = − N + 1 N − 1 λ k e x p ( j ω k ) = 0 \frac{1}{S_0}-\sum_{k=-N+1}^{N-1} \lambda_k exp(j\omega k) = 0 S01−k=−N+1∑N−1λkexp(jωk)=0
即
S 0 ( ω ) = 1 ∑ k = − N + 1 N − 1 λ k e x p ( j ω k ) S_0(\omega) = \frac{1}{\sum_{k=-N+1}^{N-1} \lambda_k exp(j\omega k)} S0(ω)=∑k=−N+1N−1λkexp(jωk)1
因此,我们就得到了基于最大熵进行优化的结果就是AR模型。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









