







一、简述
1.1 Network Embedding
基于一个Graph,将节点或者或者边投影到低维向量空间中,再用于后续的机器学习或者数据挖掘任务。

1.2 DeepWalk(Online Learning of Social Representations.)
1. DeepWalk简述:
Network/Graphrandom walk
节点序列
skip-gram
out
2. DeepWalk算法思路:对图从一个节点开始使用random walk来生成类似文本的序列数据,然后将节点id作为一个个「词」,使用skip gram训练得到「词向量」。 这样做其实等价于特殊矩阵分解(Matrix Factorization)。
1.3 node2vec(Scalable Feature Learning for Networks)
1. node2vec在DW的基础上,定义一个bias random walk策略生成序列,采用BFS和DFS两种游走方式,仍用skip gram训练。
Network/Graphbias random walk
节点序列
skip-gram
out
(1)bias random walk
通过不同的p和q参数设置,来达到保留不同信息的目的。当p和q都是1.0的时候,它等价于DeepWalk。
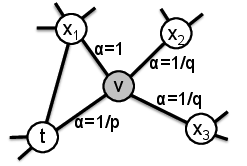
DeepWalk中根据边的权重进行随机游走,而node2vec加了一个权重调整参数α:t是上一个节点,v是最新节点,x是候选下一个节点。d(t,x)是t到候选节点的最小跳数。 从节点t走到v以后,返回t的超参数为p,到其他节点的参数为q。p和q共同控制着重新访问节点(t)、走向前面的节点(x1)、走向更远节点(x2,x3)的概率。
(2)skip-gram
训练一个带有单个隐藏层的简单的神经网络来完成某个任务,但是实际上我们并没有将这个神经网络用于我们训练的任务。相反,目标实际上只是为了学习隐藏层的权重 - 我们会看到这些权重实际上是我们试图学习的“单词向量”。
二、详说skip-gram
参考博客:读懂Word2Vec之Skip-Gram
2.1 假任务
给定一个句子中的特定单词(输入单词),查看附近的单词并随机选择一个单词。网络将告诉我们,我们词汇表中每个单词是我们选择的“邻近单词”(“window size”参数)的概率。
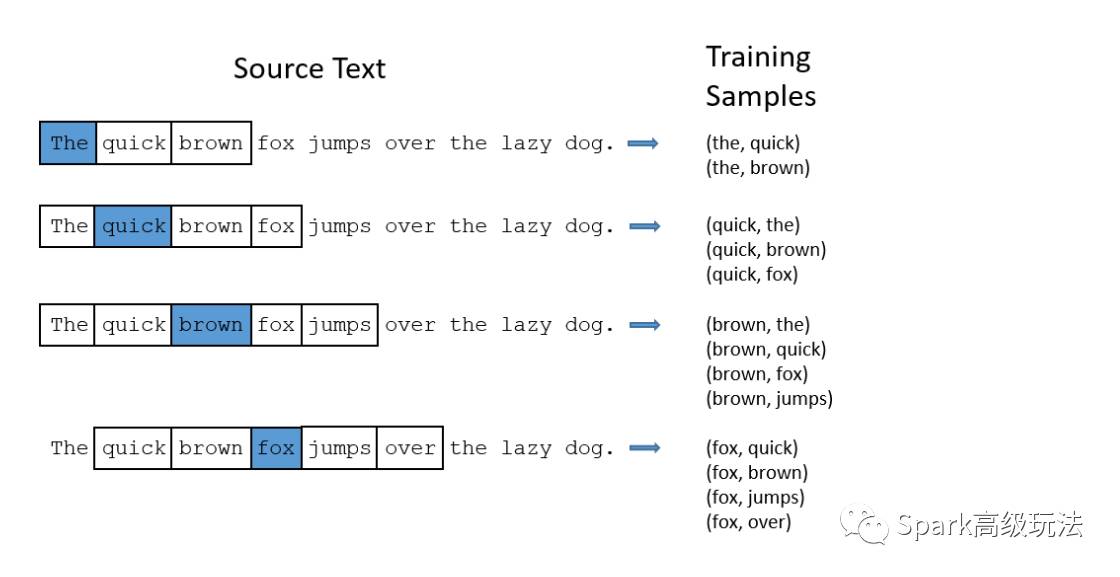
上图采用了一个小的窗口大小为2,标为高亮蓝色的是输入单词。
2.2 模型细节
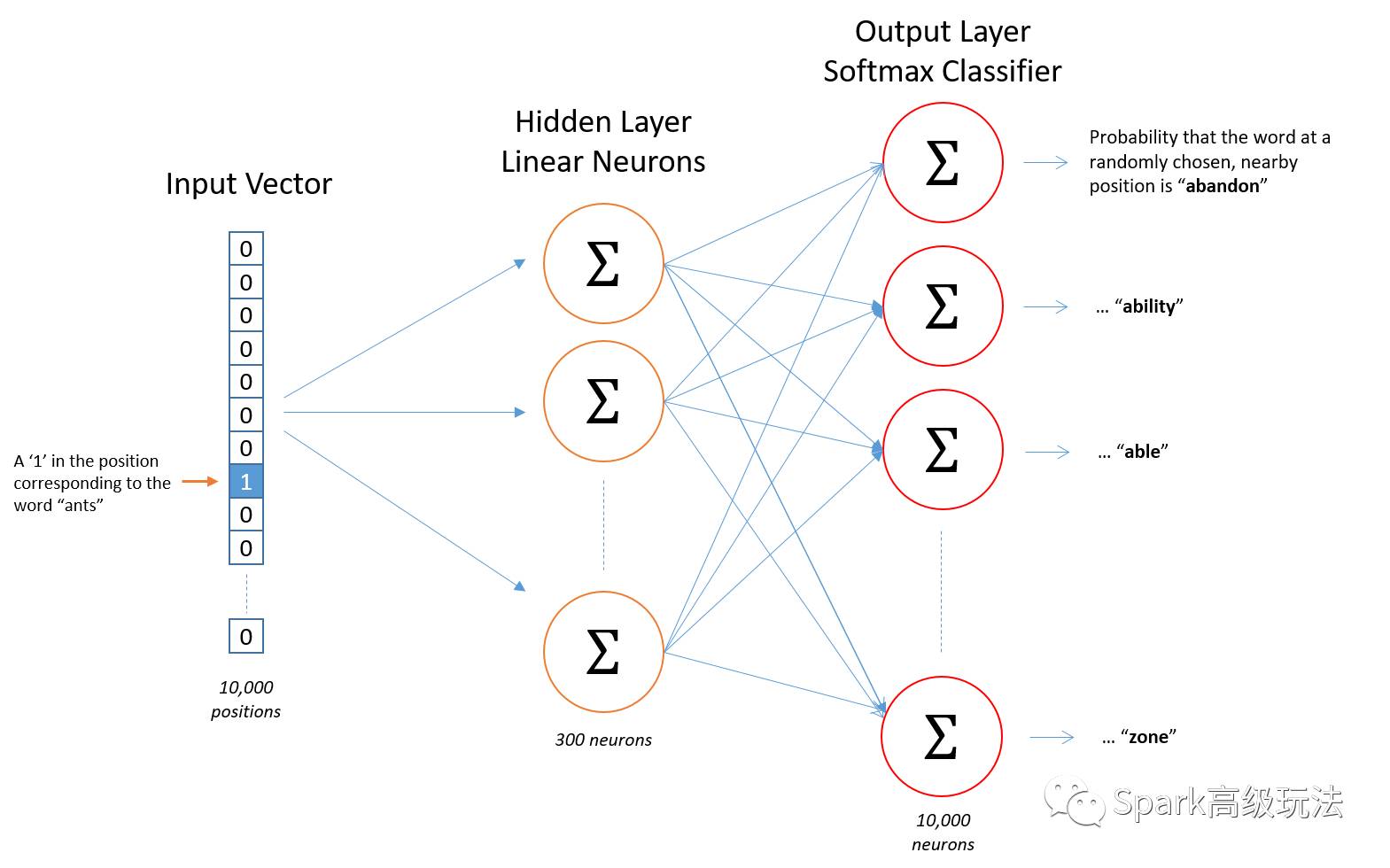
输入层:一个one-hot向量(10000个元素)
隐藏层:没有激活函数
输出层:使用softmax,一个单独的向量(10000元素,一个概率分布--浮点),包含了随机选中词典单词的概率。
2.3 隐藏层
隐藏层:一个10,000行(每一行都针对的是词汇表中的每个单词)和300列(每个隐藏的神经元一个列)的权重矩阵
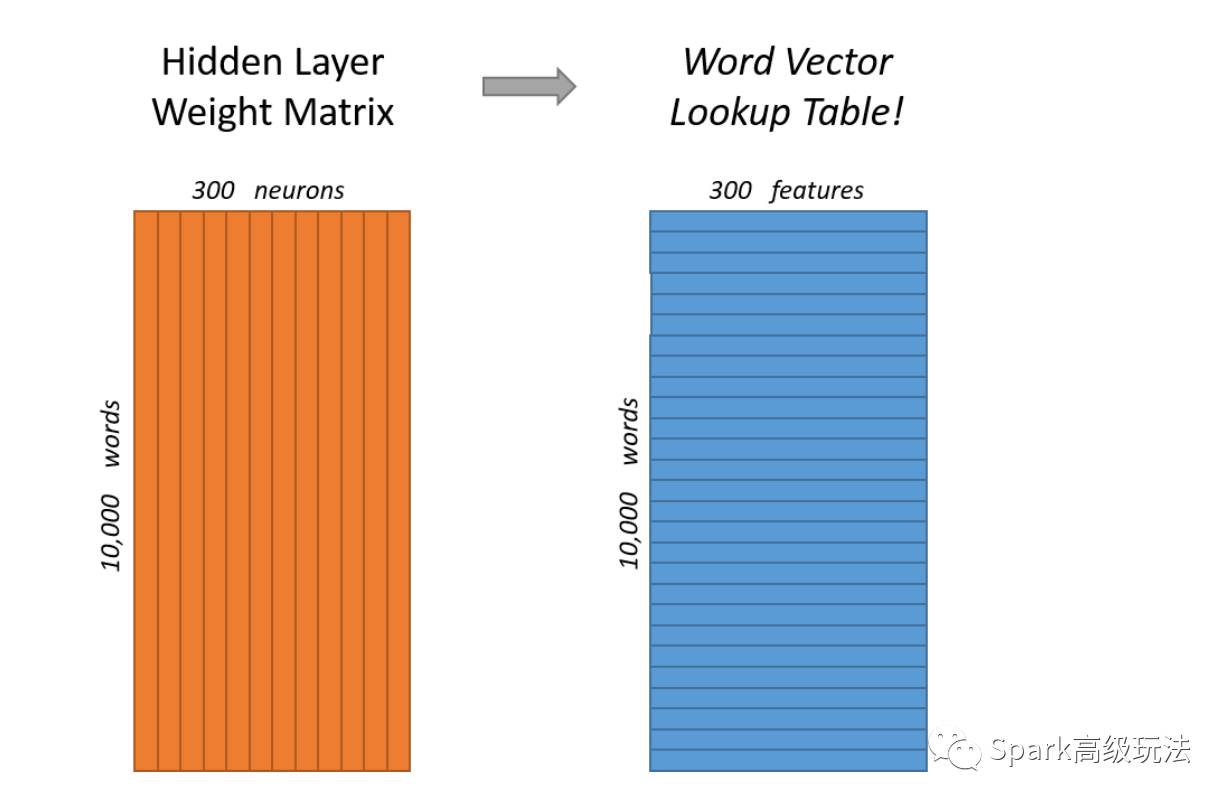
最终目标实际上只是为了学习这个隐藏的层权重矩阵 - 当我们完成时,我们就会抛弃输出层!
隐藏层实际上只是作为一个查找表来操作,隐藏层的输出只是输入单词的“word vector”。
2.4 输出层
输出层:一个softmax分类器。每个输出的神经元(一个在字典中的单词向量)将会产生一个输出值,该值在0-1之间,并且所有的输出值求和之后是1.
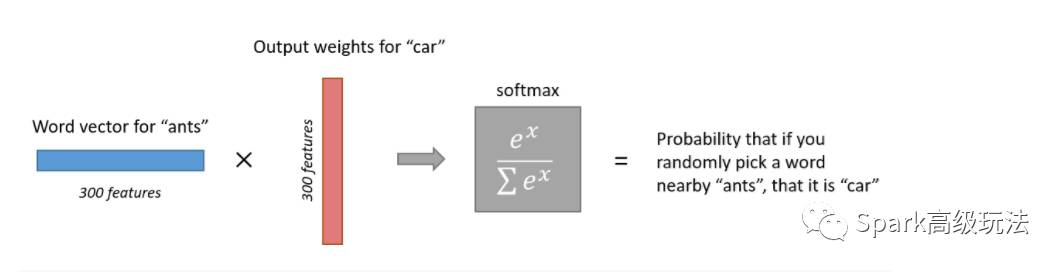
2.5 创新
1,将常见单词对或短语视为单个“单词”
2,对频繁的词进行抽样以减少训练样例的数量
3,使用“负抽样”技术来修改优化目标,使每个训练样本只更新模型权重的一小部分














 5108
5108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









