







本文未经许可,禁止转载,如需转载请联系笔者
0. 前言
本章之前的内容介绍的多是规模比较小的强化学习问题,生活中有许多实际问题要复杂得多,有些是属于 状态数量 巨大甚至是连续的,有些 行为数量 较大或者是连续的。这些问题要是使用前几章介绍的基本算法效率会很低,甚至会无法得到较好的解决。本章就聚焦于求解那些 状态数量多或者是连续状态 的强化学习问题。
当状态数量和行为数量多时,如果仍然用字典式的存储,即:一个状态动作对(S,A)对应一个Q值,那么这个存储量将会非常大,特别是状态数量或行为数量是连续的时候,这个存储量理论上是无穷大。前面几章讲的都是查表式(table lookup)算法。
那么这个时候,我们要转换思路,不能用离散的字典式存储,对于连续问题,就要用连续的方式,即存储一个Q函数。输入一个状态动作对,输出函数计算的Q值。
因此,我们可以用一个函数来近似状态价值函数 V V V,或者行为(动作)价值函数 Q Q Q,我们只需要存储函数的关键系数即可,这样大大降低了存储量。对于近似函数,可以分为 线性函数 和 非线性函数 ,对于线性函数,存储函数自变量前的系数即可;对于非线性函数,通常采用神经网络的方式进行近似,那么只需要存储神经网络的连接权系数即可。
采用神经网络作为近似就是著名的 深度Q学习网络(Deep Q-Network, DQN) 。本章除了会讲述DQN算法外,还会讲述DDQN (Double Deep Q-Network, DQN)。
1. 价值近似的意义
正如引言所述,对于状态连续或动作连续的强化学习问题,必须要用近似函数来存储他们的状态价值 V V V或者行为价值 Q Q Q,否则存储量爆炸。
如果能建立一个 函数 v ^ \hat{v} v^,这个函数 由参数 w w w描述,它可以直接接受表示状态特征的连续变量 s s s作为输入,通过计算得到一个状态的价值,通过 调整参数 w w w 的取值,使得其 符合基于某一策略 π \pi π的最终状态价值,那么 这个函数就是 状态价值 v π ( s ) v_{\pi}(s) vπ(s)的近似表示。
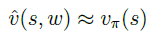
可以看到,不同的
w
w
w会对应不同的策略
π
\pi
π下的状态价值函数。用图像表示即为:
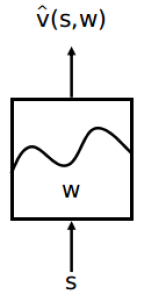
类似的,如果由参数 w w w构成的函数 q ^ \hat{q} q^同时接受状态变量 s s s和行为变量 a a a,计算输出一个行为价值,通过调整参数 w w w的取值,使得其符合基于某一策略 π \pi π的最终行为价值,那么这个函数就是 行为价值 q π ( s , a ) q_{\pi}(s,a) qπ(s,a)的近似表示。
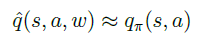
可以看到,不同的
w
w
w会对应不同的策略
π
\pi
π下的行为价值函数。用图像表示即为:
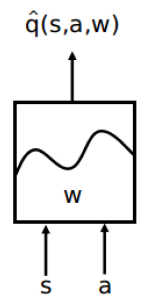
对于行为价值函数,还有一种近似表示方式,就是输入状态变量
s
s
s,它能够输出所有行为变量
a
a
a对应的行为价值。同样通过调整参数
w
w
w的取值,使得其符合基于某一策略
π
\pi
π的最终行为价值。用图像表示即为:
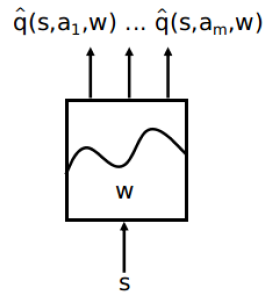
显然这第三种表示方式,仅限于行为变量是离散可穷举的。
2. 目标函数与梯度下降
首先我们来回顾一下上一章《不基于模型的控制》中Sarsa算法的更新行为价值函数
Q
Q
Q的方式:
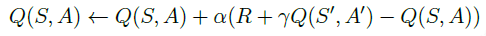
在on-policy TD算法中,与Sarsa不同的算法,比如Sarsa(n),Sarsa(
λ
\lambda
λ),以及off-policy TD算法,他们的Q函数更新差别只体现在上式中的目标值
R
+
γ
Q
(
S
′
,
A
′
)
R+\gamma Q(S' ,A')
R+γQ(S′,A′)的选取上。试想一下,如果价值函数最终收敛不再更新,那意味着对任何状态或状态行为对,其目标值与价值相同。对于 预测问题,收敛得到的Q就是基于某策略的 最终行为价值函数; 对于 控制问题,收敛得到的价值函数同时也对应着 最优策略。
现在把上式中的所有
Q
(
S
,
A
)
Q(S,A)
Q(S,A)用
Q
^
(
S
,
A
,
w
)
\hat{Q}(S,A, w)
Q^(S,A,w)代替,就变成了 基于近似价值函数的价值更新方法︰
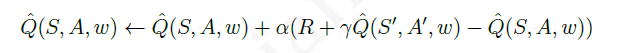
假设现在我们已经找到了参数使得价值函数收敛不再更新,那么意味着下式成立:
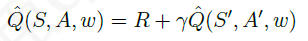
即:
α
\alpha
α乘的那一项为0。同时意味着找到了 基于某策略的最终价值函数 或者是 控制问题中的最优价值函数。
事实上,很难找到完美的参数 w w w使得上式完全成立。同时由于算法是基于采样数据的,即使上式对于采样得到的状态转换成立,也很难对所有可能的状态转换成立。为了衡量在采样产生的 M M M个状态转换上近似价值函数的收敛情况,可以定义目标函数 J ( w ) J(w) J(w)为:
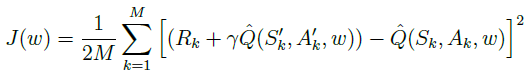
公式(6.1)中 M M M为采样得到的状态转换的总数。近似价值函数 Q ( S , A , w ) Q(S,A, w) Q(S,A,w)收敛意味着 J ( w ) J(w) J(w)逐渐减小。 J ( w ) J(w) J(w)的定义使得它不可能是负数同时存在一个极小值0。目标函数 J J J也称为代价函数(cost function),只要代价函数减小为0,那么我们就可以认为此时的参数 w w w就近乎完美了(但实际上很难收敛到0)。
以上是 以TD学习、行为价值为例设计的目标函数。
对于 MC学习,使用收获代替目标价值,此时近似状态价值函数
V
^
\hat{V}
V^和近似行为价值函数
Q
^
\hat{Q}
Q^的好坏,同样可以用代价函数来表示,即:
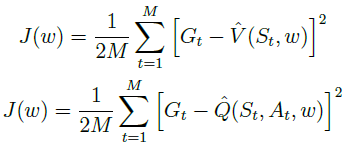
对于 TD(0)和反向认识 TD(
λ
\lambda
λ)学习 来说,使用TD目标代替目标价值,写出代价函数:
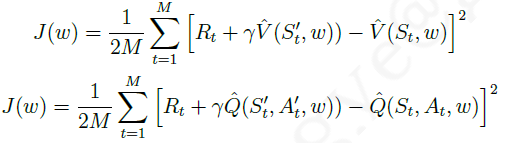
对于 前向认识TD(
λ
\lambda
λ)学习 来说,使用
G
λ
G^{\lambda}
Gλ或
q
λ
q^{\lambda}
qλ代替目标价值:
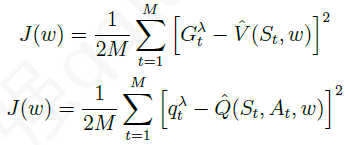
如果 事先存在 对于预测问题最终基于某一策略 最终价值函数
V
π
(
S
)
V_{\pi}(S)
Vπ(S)或
Q
π
(
S
,
A
)
Q_{\pi}(S,A)
Qπ(S,A),或者 存在 对于控制问题的 最优价值函数
V
∗
(
S
)
V_*(S)
V∗(S)或
Q
∗
(
S
,
A
)
Q_*(S,A)
Q∗(S,A),那么可以使用这些价值来代替上式中的目标价值,这里集中 使用
V
t
a
r
g
e
t
V_{target}
Vtarget或
Q
t
a
r
g
e
t
Q_{target}
Qtarget 来代表 目标价值,使用 期望 代替 平均值 的方式,那么目标价值的表述公式为:
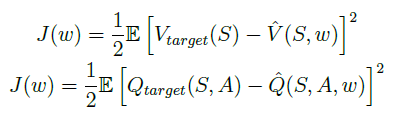
事实上,这些目标价值正是我们要求解的。在实际求解近似价值函数参数
w
w
w的过程中,我们使用基于近似价值函数的目标价值来代替。下文还将继续就这一点做出解释。
而如何让代价函数 J ( w ) J(w) J(w)收敛到0,这就需要用到梯度下降法,这对于神经网络而言,直接使用pytorch的loss.backward()即可,这里不在详细讲述梯度下降法的原理了。
参数
w
w
w的梯度下降法更新方式为:
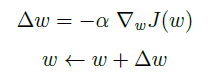
3. 常用近似函数
3.1 线性近似
线性价值函数使用一些列特征的线性组合来近似价值函数:
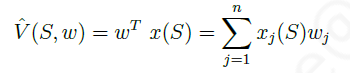
上式中的 x ( S ) x(S) x(S)和 w w w均为列向量, x j ( S ) x_j(S) xj(S)表示状态 S S S的第 j j j个特征分量值, w j w_j wj表示该特征分量值的权重,也就是要求解的参数。
如果已知目标状态,则线性函数
V
^
(
S
,
w
)
\hat{V}(S,w)
V^(S,w)近似价值函数,其对应的目标函数
J
(
w
)
J(w)
J(w)为︰
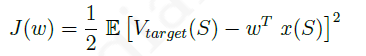
相应的梯度
∇
w
J
(
w
)
\nabla_{w} J(w)
∇wJ(w)为:
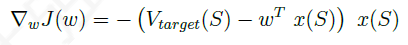
参数的更新量
Δ
w
\Delta w
Δw为:
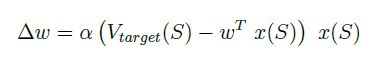
上式中,使用不同的学习方法时,
V
t
a
r
g
e
t
(
S
)
V_{target}(S)
Vtarget(S)由不同的目标价值代替。
事实上,查表式的价值函数是线性近似价值函数的一个特例。比如对于查表式的状态价值函数,我们去找这个状态对应的价值,而线性近似函数只需要改变状态向量的值,然后与权重做向量点乘即可:

3.2 神经网络
关于神经网络的知识点,这里不进行讲述,因为不是强化学习的重点,读者可以自行查阅全连接网络和卷积神经网络等经典神经网络的资料。
4. DQN算法和DDQN算法
DQN算法就是,近似价值函数使用神经网络来表示,换句话说就是用神经网络来做价值评估,仍然用
ϵ
\epsilon
ϵ贪婪策略来做策略迭代,优化策略。
DQN算法伪代码如下:

该算法流程图中使用 θ \theta θ和 θ − \theta^- θ−代表 神经网络的参数。相比前一章的各种学习算法,该算法中的状态 s s s都由特征 ϕ ( s ) \phi (s) ϕ(s)来表示。为了表述得简便,在除算法之外的公式中,本章将仍直接使用 s s s来代替 ϕ ( s ) \phi (s) ϕ(s)。
在每一产生一个行为 A A A并与环境实际交互后,个体都会进行一次学习并更新一次参数(做一次更新需要用到“记忆库”中一大批的experience,因此做更新之前一定要保证experience够多,比如一次取10个experience,那么要保证“记忆库”中至少有10个experience)。更新参数时使用的目标价值由下式产生︰
Q target ( s t , a t ) = R t + γ max a t ′ Q ^ ( s t ′ , a t ′ ; θ − ) Q_{\text {target }}\left(s_{t}, a_{t}\right)=R_{t}+\gamma \max_{a'_t} \hat{Q}\left(s_{t}^{\prime}, a_{t}^{\prime} ; \theta^{-}\right) Qtarget (st,at)=Rt+γat′maxQ^(st′,at′;θ−)
上式中的 θ − \theta^- θ−是 Q ^ \hat{Q} Q^网络(又称为target Q网络,即伪代码中的target action-value function)的参数。可以看到,在进行行为 a t a_t at的选择时,用的是参数为 θ \theta θ的 Q Q Q网络,在进行状态行为对 ( s t , a t ) (s_t,a_t) (st,at)的行为价值更新时,用的是参数为 θ − \theta^- θ−的 Q ^ \hat{Q} Q^网络,并且取网络的最大值输出值加上即时奖励 r j r_j rj作为 y j y_j yj,然后用 y j y_j yj作为 Q Q Q网络的“实际输出”,与 Q Q Q网络的预测输出 Q ( ϕ j , a j ; θ ) Q(\phi_j,a_j;\theta) Q(ϕj,aj;θ)进行比较,从而 完成 Q Q Q网络的参数训练。等 Q Q Q网络训练了C轮后,才将 Q Q Q网络的参数复制给 Q ^ \hat{Q} Q^网络。(为什么要过一会才更新 Q ^ \hat{Q} Q^网络?因为这是为了保证行为价值(action-value)的稳定,从而使 Q Q Q网络的训练稳定)
DQN算法在深度强化学习领域取得了不俗的成绩,不过其 并不能保证一直收敛,研究表明这种估计目标价值的算法过于乐观的 高估了 一些情况下的行为价值,导致算法会将次优行为价值一致认为最优行为价值,最终不能收敛至最佳价值函数。
一种使用 双价值网络的DDQN(double deep Q-network) 被认为较好地解决了这个问题。
而DDQN算法绝大多数流程与DQN算法一样,只是在更新目标价值时使用下式:
Q target ( s t , a t ) = R t + γ Q ^ ( s t ′ , max a ′ Q ( s t ′ , a ′ ; θ ) ; θ − ) Q_{\text {target }}\left(s_{t}, a_{t}\right)=R_{t}+\gamma \hat{Q}\left(s_{t}^{\prime}, \max _{a^{\prime}} Q\left(s_{t}^{\prime}, a^{\prime} ; \theta\right) ; \theta^{-}\right) Qtarget (st,at)=Rt+γQ^(st′,a′maxQ(st′,a′;θ);θ−)
该式表明,DDQN在生成 ( s t , a t ) (s_t,a_t) (st,at)的target action-value时,不是直接从 Q ^ \hat{Q} Q^中取下一状态 s t ′ s'_t st′中target action-value最大的那一项,而是先从 Q Q Q网络中找到下一状态 s t ′ s'_t st′时action-value最大的那个行为 a ′ a' a′,然后代入 Q ^ \hat{Q} Q^中计算target action-value值。接着就和DQN一致了,更新 Q Q Q网络的参数,更新C轮后,才将 Q Q Q网络的参数复制给 Q ^ \hat{Q} Q^网络。
实验表明这样的更改比 DQN算法更加稳定,更容易收敛值最优价值函数和最优策略。在编程实践环节,我们将实现 DQN和 DDQN。
在使用神经网络等深度学习技术来进行价值函数近似时,有可能会碰到无法得到预期结果的情况。造成这种现象的原因很多,其中包括基于TD学习的算法使用引导(bootstrapping)数据,非线性近似随机梯度下降落入局部最优值等,也和 ϵ \epsilon ϵ-贪婪策略的 ϵ \epsilon ϵ的设置有关。此外深度神经网络本身也有许多训练技巧,包括学习率的设置、网络架构的设置等。这些设置参数有别于近似价值函数本身的参数,一般称为超参数(super parameters)。如何设置和调优超参数目前仍没有一套成熟的理论来指导,得到一套完美的网络参数有时需要多次的实践的并对训练结果进行有效的观察分析。
5. 编程实践
本章的编程实践是《基于PyTorch实现DQN求解PuckWorld问题》,同时实现了DQN算法和DDQN算法,详见叶强github强化学习主页。
参考文献:
- David Silver强化学习视频.
- 叶强《强化学习入门——从原理到实践》
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









