






文章目录
论文地址: https://arxiv.org/abs/2003.05597v2
代码地址: https://github.com/open-mmlab/mmrotate
参考: https://zhuanlan.zhihu.com/p/111493759
1. 动机
1.1边界问题
目前流行的基于回归方式的角度预测方法或多或少都有边界问题,主要原因是理想的预测结果超出所定义的范围,导致产生一个较大的损失值。CSL通过将角度的回归问题转换成了一个分类问题,限制预测结果的范围来消除这一问题。
1.2现有分类编码局限性
简单的独热编码分类手段来处理存在几个问题:
- 表示方法需要采用五参数的形式,而且角度是要180角度范围的(长边定义法),不然依然回存在边的交换性问题(EoE)
- 目前的分类损失无法衡量预测结果和标签之间的角度距离,如图,如果 g t gt gt是0度,预测1度和-90度损失值是一样的。
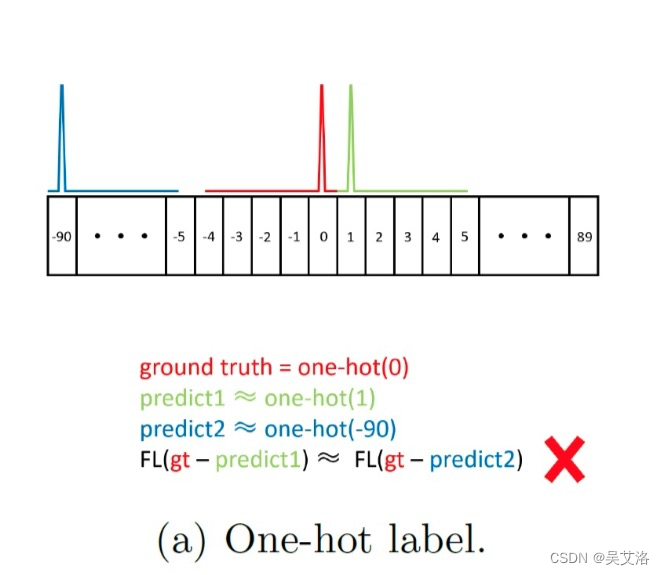
2.CSL(Circular Smooth Label, CSL)
2.1.误差分析
回归问题转换成分类问题是一个连续到离散的问题,在这个转换的过程中会有精度的损失,比如在一度一类的情况下( w w w=1 ),无法预测出0.5度这种结果。
因此,需要先计算一下精度最大损失和平均损失(服从均匀分布),以确定这种损失对最后的结果影响大不大。
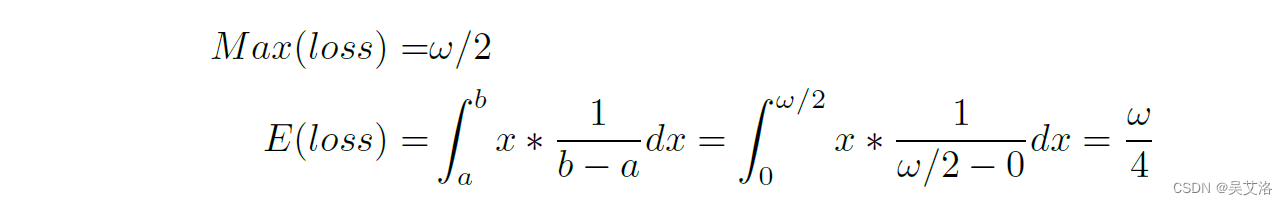
以一度一类的为例( w w w=1 ),精度最大和期望的损失分别是0.5和0.25。假如,有两个相同的长宽比1:9的同中心的矩形,角度相差0.5和0.25,则他们之间的IoU只下降了0.05和0.02。
2.2CSL编码
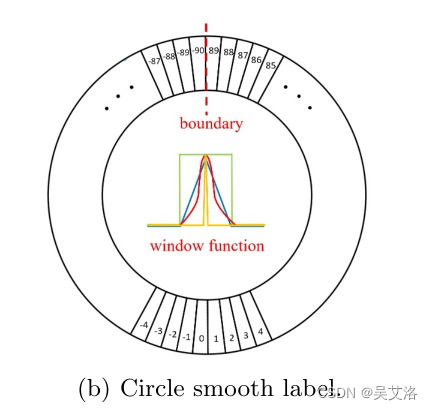
针对独热编码的局限性,CSL编码通过设置窗口函数,来衡量预测值和GT之间的角度距离,即在一定范围内,越靠近真实值的预测值的损失值越小,并且引入周期性解决角度周期性问题,使得89和-90两个角度变成近邻。
CSL表达式:
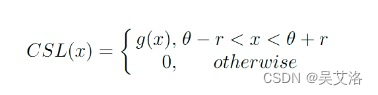
窗口函数性质:
- 周期性
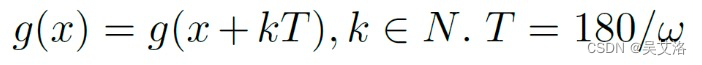
- 对称性
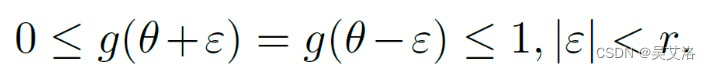
- 最大值
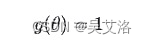
- 单调性
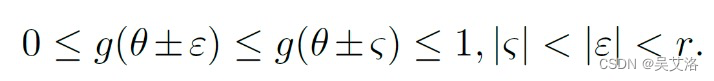
注意:当窗口函数窗口半径很小时,CSL等价于One-hot label。
3.3检测模型:
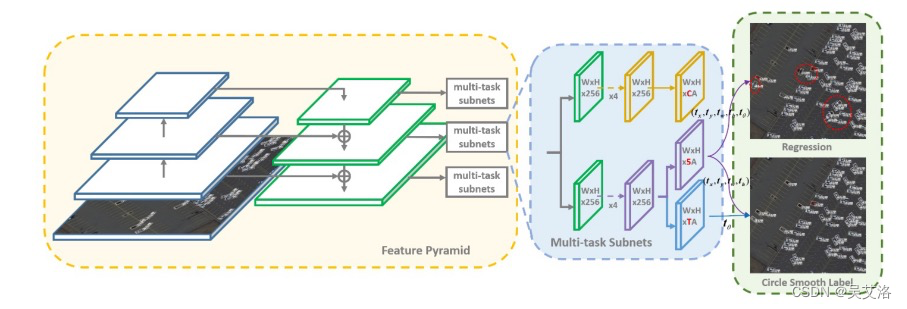
以RetinaNet为Baseline,将角度作为180分类分支。
- 回归框编码 (DeltaXYWHTRBBoxCoder)
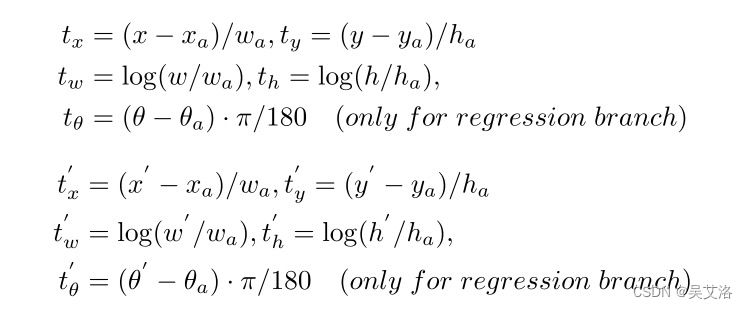
- 多任务损失函数
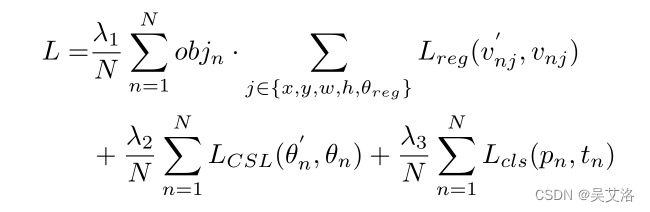
其中N表示anchor的数量, o b j n obj_{n} objn是一个二进制值( o b j n = 1 obj_{n}=1 objn=1表示前景, o b j n = 0 obj_{n}=0 objn=0表示背景,背景不回归)。 v ∗ j ‘ v^`_{*j} v∗j‘表示预测的偏移向量, v ∗ j v_{*j} v∗j 是 GT的目标向量。 θ n θ_n θn, θ n ‘ θ_n^‘ θn‘分别表示角度的标签和预测。 t n t_n tn表示对象的标签, P n P_n Pn是通过Sigmoid函数计算的各个类别的概率分布。 超参数 λ1、λ2、λ3 控制权衡,默认设置为 {1, 0.5, 1}。 分类损失 L c l s L_{cls} Lcls 和$ L_{CSL}$ 是Focal Loss或 sigmoid CE Loss,取决于检测器。 回归损失 L r e g L_{reg} Lreg 是Smooth L1 Loss。
注:角度有两个损失,回归以及分类损失都有。
3.实验结果
3.1.窗口函数
- 由于EoE问题的存在, 90-CSL-baesd方法总体不如 180-CSL-baesd方法;
- 基于高斯窗口函数的方法效果最好,而基于脉冲窗口函数(One-hot label)的效果最差,几乎预测不出角度值;
3.2.窗口半径
- 窗口半径的大小要适中,过小则会变成One-hot label形式,无法学到角度信息,过大则角度预测偏差会加大;
- 单阶段检测器比双阶段检测器对于窗口半径更加敏感,推测的原因是双阶段方法是基于instance-level的特征提取方法(RoI Pooling或RoI Align),这些方法提取到的特征会明显好于单阶段image-level的提取方式,使得双阶段检测方法可以区分更加小角度差的角度类别。
4.局限性
角度类别太多,会导致RetinaNet的head部分过于厚














 3908
3908











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









