






博主目前是复旦大学信通学院的直博生一年级萌新,刚开始接触论文阅读,如有理解不对的地方请大伙谅解,本文是对题目中的大佬的论文进行1-9页原理部分的解读。
引言
最近在阅读YOLO算法对于SAR图像的舰船目标检测的论文,接触到了旋转目标检测方法,发现其在遥感图像方面具有良好性能,所以对CSL算法的论文进行了解读,以下是许多都是个人的理解所以有不妥的地方大家可以指出让我改正。
摘要
现有的基于回归的旋转检测器的边界问题是由角周期性或角序引起的,并且理想的预测结果可能超出预定义的范围也是其中的主要原因,回归问题在边界处的处理可能由于边界处的不连续性的存在所以会导致处理的性能下降。论文中设计了一种圆形平滑标签技术( Circular Smooth Label,简称CSL)来处理角度的周期性,但是在设计CSL的同时会大大增加代码的参数量以及计算量,所以同时提出了一种密集编码标签(Densely Coded Labels,简称DCL),大大减少了编码的长度,在论文的最后也提出了一种目标头部检测器模型,在对一些特定的需要检测目标航向信息的案例中发挥巨大的作用。
第一部分 介绍(Introduction)
现有的旋转检测器的现状
首先开头部分说明了目标检测(object detection)在许多领域有重要的应用,并且现在也有许多旋转检测器(rotation detection)能够提供准确的方向和尺度信息,在遥感图像和多方向场景文本序列字符识别等领域有重要的应用。
现阶段的一些旋转检测器在根本上是基于回归的检测器,通过旋转检测框或者不规则的四边形检测框来实现目标的旋转检测,例如现有的五参数回归(使用的是旋转检测框)和八参数回归(使用的是规则的四边形检测框)都存在边界的不连续问题,并且这些问题是由于角的周期性(angula periodicity)和角序(angular corner)引起的。在本篇论文中将这一切的根本原因归结于回归方法中的边界问题(boundary problem)中理想的预测超出了预定义的范围,到模型的损失值(loss value)在边界处突然增大,通常无法用常规的预测方式获得准确的预测结果。同时旋转边框检测中角度预测的准确性是非常重要的,轻微的角度偏差也会导致IoU(交并比)的变化,特别是在宽高比较大的情况下表现得更加显著。
本文中设计的旋转检测器
本论文中设计了一种基于分类(classification)的旋转检测器,将角度的预测由传统的回归问题转换为了分类。
设计了CSL来处理角度的周期性以及增加了相邻角之间的公差(tolerance),并且通过下面的一些例子证明了由连续的预测到离散的分类转换之间产生的精度误差可以通过细粒度(fine-granularity)忽略不计,后面接着介绍了四种CSL常用的窗函数并且探讨了不同的窗口半径对检测性能的影响。
设计了两种DCL在保证预测精度的同时大大减少了编码长度,同时为了消除角度色散(angular dispersion)引起的误差(这里我认为是由于在机器计算中由于精度问题机器并不能每次都得到准确的公式中的计算应得到的值,所以会产生相应的误差),提出了一种角度的微调机制。
最后在论文的第四部分往后是一些实验的演示,通过与基于回归的旋转检测器进行比较,可以看出本文中设计的基于分类的旋转检测器性能更加优良。
第二部分 相关工作(Related Work)
水平区域目标检测(Horizontal Region Object Detection)
这一部分介绍了几种常见的一些经典的目标检测,例如RCNN等anchor-based的目标检测方法以及CornerNet、CenterNet和ExtremeNet这些试图预测物体的一些关键点来组成边界框的目标检测方法,但是,这些水平检测器(horizontal detector)没法提供准确的方向和尺度信息,这给航空图像中的目标变化检测和多方向场景文本的顺序字符识别等实际应用带来了问题。
任意方向目标检测( Arbitrary-oriented Object Detection)
航拍图像和场景文本是旋转检测器的主要应用场景。多方向目标检测的最新进展主要是对经典的目标检测方法进行了改进,采用旋转包围框或四边形来表示多方向目标。
由于遥感图像场景的复杂性和大量的小的、杂乱的、旋转的目标,多级旋转检测器以其鲁棒性仍然占据主导地位。其中,ICN、ROI-Transformer、SCRDet、R3Det是目前SOTA检测器。但是究其根本,这些主流的基于回归的方法往往由于预测超出定义范围而存在边界问题。
分割(segmentation)思想是一种解决边界问题的有效方法,但是这种方法并不适用于遥感图像,因为遥感图像中包含大量密集排列的多类别小物体,相比之下,实例分割(instance segmentation)显得更加合适,但是实例分割会导致更多的标记标签工作;由此又存在一种将旋转框(rotated boxes)转换为二进制掩码,但是这种转换会一如许多背景区域最终降低预测框的精度。此外,对于自顶向下的方法(如Mask RCNN),密集场景会限制水平框的检测,因为非最大抑制(NMS)会过度抑制密集的水平重叠边界盒,从而影响后续分割;自下而上的方法,如SOLO和CondInst,将不同的实例分配到不同的通道,因此不适合航空图像,因为航空图像经常显示具有大量密集小物体的大尺度场景。(这一段我认为是在目标识别中,以yolo v5为例,大多采用的特征金字塔结构,利用不同大小的检测框检测不同尺度的信息,而且在检测过程中场景由于存在大量排列紧密的密集目标,在目标检测阶段将各个目标识别并描框后,会因为许多密集物体的框重叠在NMS阶段将许多目标框舍去。)
综上所述,基于角度的旋转检测算法(angle-based rotation detection algorithms)在遥感图像目标检测中占据主导地位,然后利用本文中设计的新的旋转检测器,将角度的预测由回归问题转换为了分类问题,基本消除了边界问题。
方向信息分类(Classification for Orientation Information)
这部分就简单介绍了几种早期的通过分类来获取方向信息的算法。
目标航向检测(Object Heading Detection)
利用DLR 3K数据集进行车辆的头部检测,首先是根据滑动窗口策略以及二值分类策略来对图中的汽车进行识别,然后通过分类对头部进行粗略估计,有16个类(,所以相邻样本组之间的旋转差为22.5°),但是这种方法需要训练多个检测器,同时也不能进行高精度的角度预测。
DRBox和DRBox-v2根据物体的头部定义旋转边界框,通过回归预测的角度可以确定物体头部的方向。然而,这个定义协议的边界框有一个相对较大的角度范围,在[0°,360°]。
第三部分 提出方法(Proposed Approach)
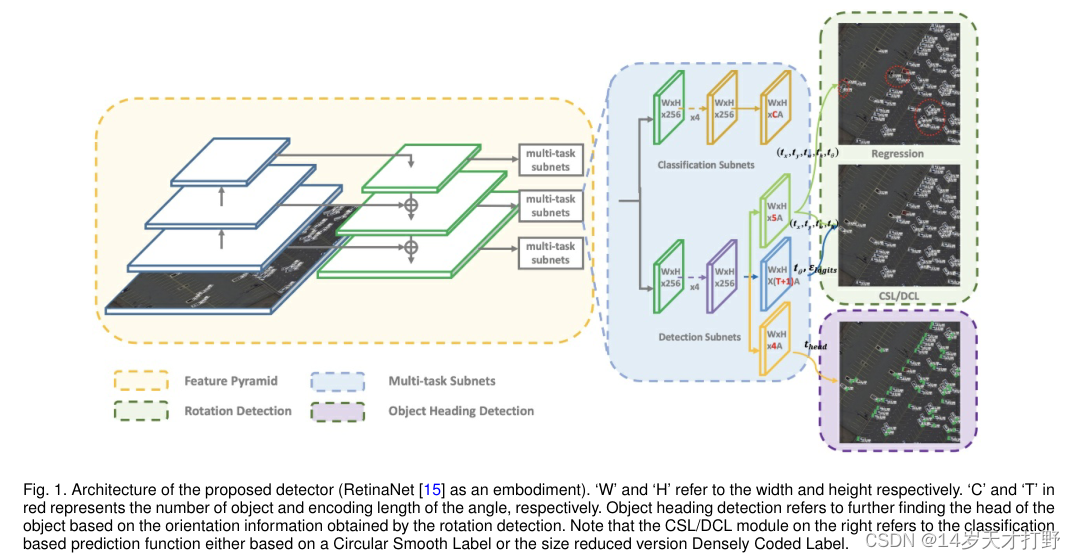
图1是本文作者提出的方法的网络架构,是一种基于RetinaNet网络架构的单阶段旋转检测器(single-stage rotation detector),下图是RetinaNet网络架构图。
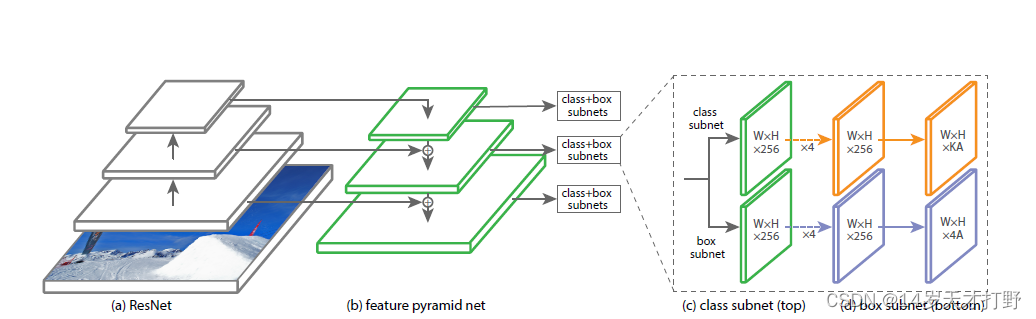
RetinaNet的特征提取网络选择了残差网络ResNet,特征融合这块选择了FPN(特征金字塔网络),以特征金字塔不同的尺寸特征图作为输入,搭建三个用于分类和框回归的子网络。分类网络输出的特征图尺寸为(W,H,KA),其中W、H为特征图宽高,KA为特征图通道,存放A个anchor各自的类别信息(K为类别数)。
图一是一个多任务流水线,包括了分类分支(classification branch),旋转检测分支(rotation branch)和目标航向检测分支(object heading branch)。并且在旋转检测分支(rotation branch)中包含了基于回归的预测和基于CSL的预测用来比较两种方法的性能。从图中可以看出,基于CSL的协议对于学习物体的方向和尺度信息更为准确,基于DCL的协议与CSL保持一致的性能。
在本文中是通过将回归模块替换为分类模块,所以可以适用于大多数的基于回归的算法。
基于回归的旋转检测方法(Regression-based Rotation Detection Method)
参数回归(parametric regression)是当下比较流行的旋转目标检测方法,主要包括基于五参数回归的协议和基于八参数回归的协议。
基于五参数回归一般是在原有的(x,y,h,w)的基础上增加了一个角度参数θ,变为(x, y, h, w,θ)来实现任意方向的边界框检测;基于八参数回归的检测器直接回归对象的四个角(x1, y1, x2, y2, x3, y3, x4, y4),因此预测是一个四边形,具体如图2所示。
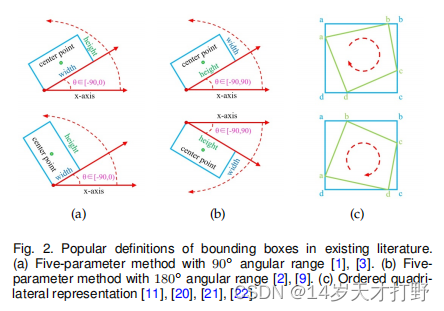
图二(a)中θ表示与x轴的锐角,另一边为width(不论大小),角度的范围为90°。图二(b)中具有180°角度范围,其θ由矩形的长边(height)和x轴决定。图二(c)中采用的是基于八参数的回归,输出为(X1,Y1,X2,Y2,X3,Y3,X4,Y4)四个点的横纵坐标,四边形回归的关键一步是提前对四角点进行排序,在保证预测正确的同时可以避免较大的损失。
回归法的边界问题(Boundary Problem of Regression Method)
这些基于回归的旋转检测本质上都存在不连续边界问题。边界不连续问题通常是由五参数协议下的角周期性或八参数设置中的角序引起的。
边界不连续会使边界处的损失值突然增大。因此,方法必须求助于特殊的,通常是复杂的技巧来缓解这个问题。因此,这些检测方法在边界条件下往往不准确。
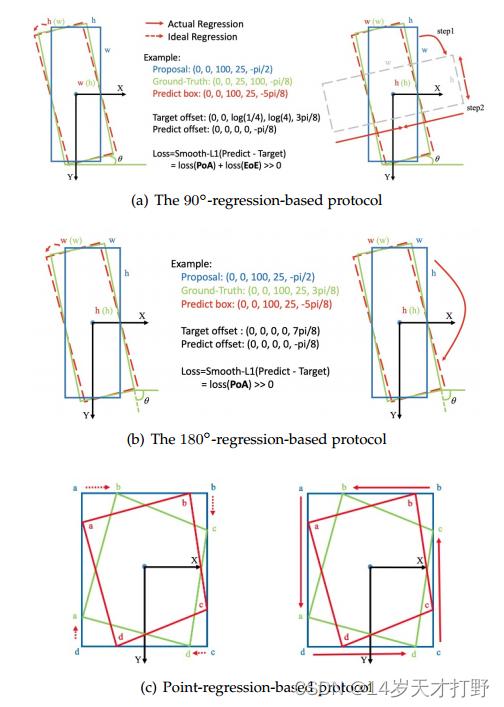
上图描述了三种不同情况下的基于回归协议的边界问题。
图(a)中是基于90°的回归协议(The 90° -regression-based protocol):
在图中篮色框是原本的水平框,此时的width为长边,与x轴的夹角也是-pi/2,理想情况下的由蓝色回归到红色框的形式是逆时针旋转,但是此时由于角的周期性(periodicity of angular)和边的交换性(exchangeability of edges),这种情况的损失会非常大,因为实际中的框(绿色框)的短边是其width,以及与x轴的夹角为-pi/8,而红色框的width是其长边,同时其与x轴的夹角为-5pi/8,根据公式:
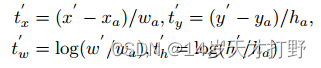
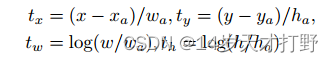
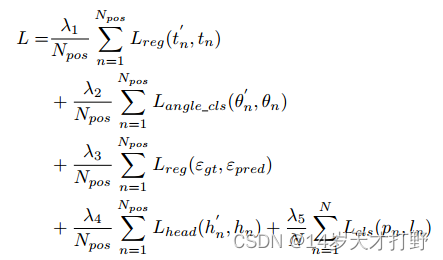
其中x;y;w;h分别表示箱体的中心坐标、宽度、高度和角度。变量x;;
分别为地面真值箱、锚点箱和预测箱(同理y;w;h)。
可以看出算出的损失值(Loss)会比较大。所以得按照图中右边蓝色框先顺时针转到灰色框再到红色框的情况进行回归,但是这增加了回归的难度,并且理想回归方式下的预测框(predict box)和实际框(ground truth)在视觉感知上确实有很高的IoU值,但此时的预测框已经超出了我们定义的范围,如果不进行额外的判断处理,我们无法计算出准确的IoU。
图(b)中是基于180°的回归协议(The 180° -regression-based protocol):
由图中可以看出loss(EoE)变成0,这个方法可以不受到边的交换性(EoE)的影响,但是由于其仍然存在一个垂直的边界,所以仍然会受到PoA的影响,蓝色框到红色框的旋转仍然需要进行一个顺时针的大路径才能完成回归。
图(c)是基于点的回归协议(Point-regression-based protocol):
由于四边形的四个角的点的提前排好序号,八参数回归方法仍然存在边界不连续问题。在图中,理想情况下由蓝色框到绿色框的路径应该为((a->b),(b->c),(c->d),(d->a)),此时消耗的路径最短,但是由于提前的对点标好了序号,实际情况下是((a->a),(b->b),(c->c),(d->d)),这种情况也属于PoA。在图中,由蓝色框到红色框的情况实际路径和理想路径是相同。
在本文中,由于基于回归的旋转检测从根本上存在的边界问题,所以从一个新的角度出发,用分类代替回归来实现更好、更鲁棒的旋转检测器。下面图4中在边界条件下对基于回归和基于分类的旋转检测器进行了视觉比较。

传统的角度分类器(Vanilla Angular Classification)
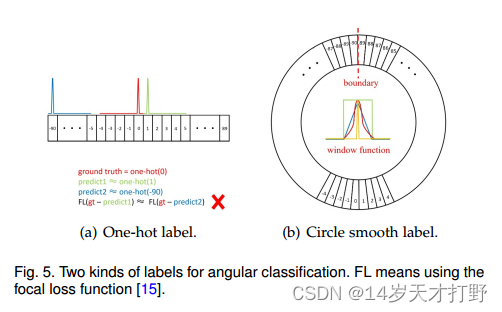
将角度的预测变为一种分类任务,一种方法是将使用对象角度作为其类别标签,类别的数量与角度范围相关。图5(a)显示了一个普通分类问题(One-Hot label)的标签设置。从回归到分类的转换可能会导致一定的准确性损失。以角度范围为180°的五参数方法为例,每个间隔的ω(默认ω = 1 ° )度是一个类别。我们可以计算出最大精度损失Max(loss)Max(loss)和预期精度损失E(loss):(类别的分布服从平均分布)
其中,,
表示角度的范围,
表示角度类别的数量,
则为相邻角度的间隔。
由上述的公式可以看出,当足够小时,此时的旋转检测器误差很小。例如,当一个框的宽高比很小时(1:9),此时即使预测框和实际框相差的角度为0:25°和0:5°(默认预期和最大精度误差),他们之间的IoU只减少0.02和0.05,可以忽略不计。
角度的离散化方程和预测方程如下:(One-Hot Label):
其中,One-Hot代表的是独热编码形式,Round()函数是对非整数进行四舍五入,Argmax()函数是对其中取最大值,Sigmoid()是一种激活函数,logits是当前的预测值。表示角度的十进制标签。
以上的传统的角度分类器对于宽高比很小和单一类别的识别中发挥一定的作用,但是对于宽高比较大并且多类别的识别中,这种高精度的角度预测对于上述的角度分类器难以实现。
角度分类的圆形光滑标签(Circular Smooth Label for Angular Classification)
普通分类方法无法获得旋转检测高精度角度预测的原因有两个:
i)当边界框使用基于90°的协议时,EoE问题仍然存在,如图4(j)所示。此外,90°基于协议有两种不同的边界情况(垂直和水平),而180°基于协议只有垂直边界情况。
ii)传统的角度分类器预测标签与真值标签之间的角度距离无关,因此它不适合角度预测问题的性质。例如图5(a)中,真实值为0°,两个预测值分别是1°和-90°,但是他们的预测损失是相同的,但是理论上预测为1°的损失相比于-90°应该更小。
圆形平滑标签(CSL)技术,通过分类获得更鲁棒的角度预测,而不受边界条件的影响,包括EoE和PoA。需要注意的是,CSL只能解决PoA,而EoE问题可以通过180°角度定义方法来解决。
CSL的表达式如下:
其中g(x)是窗函数。r是窗函数的半径。θ表示当前边界框的角度。理想的窗函数g(x)需要满足以下性质:
1)周期性(Preiodicity):
2)对称性(Symmetry):
3)最大值(Maximum):
4)单调性(Monotonic):,函数从中心点向两侧呈现单调的递减趋势。
图5(b)显示了满足上述四种性质的四个有效窗函数:脉冲函数、矩形函数、三角形函数和高斯函数。并且在角度的边界处标签的值是连续的,不存在由于CSL的周期性而导致的任意精度误差。此外,当窗函数为脉冲函数或窗函数半径很小时,独热标签相当于CSL。(此时的窗函数中只包含了一个标签值时,CSL相当于One-Hot Label)。CSL的角度预测过程:
角分类的密集编码标签(Densely Coded Label for Angular Classification)
基于CSL的检测器使用的是基于稀疏编码标签(Sparsely Coded Label,简称SCL)编码技术,虽然CSL在角度预测方面有很多很好的特性,但是CSL的设计会导致预测层引入过多的参数和计算,导致检测器的效率低下。具体来说,上面描述的One-Hot和CSL都是稀疏角度编码方法,这往往会导致角度编码长度过长:
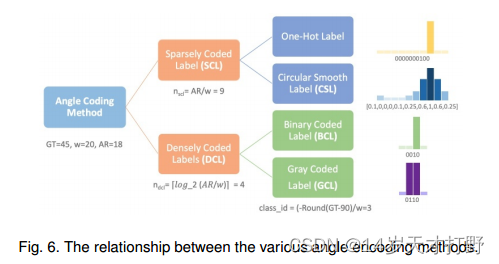
二进制编码标签(Binary Coded Label, BCL)和格雷编码标签(Gray Coded Label, GCL)是两种密集编码标签( Densely Coded Label , DCL)方法。不同角度编码方式之间的关系如图6所示。
DCL的码长为:
论文接下来通过一个具体的实例展示了为什么代码长度对检测模型参数和计算量有如此大的影响,得出了缩短码长是必要的和重要的结论。DCL的编解码过程(以BCL为例):
角度微调 ( Angle Fine-Tuning)
较大的可以在一定程度上缓解预测层参数过多的问题,减少对模型角度分类能力的依赖。但是,此时不能忽略
增大后带来的理论角度误差的增大。为了解决这个问题,文中预测了一个较小的“角度”,以弥补由于角度编码造成的精度误差。
目标航向检测器(Object Heading Detector)
与旋转检测相比,目标头部检测是一项更细粒度的检测任务,其目的是确定目标的头部位置。旋转检测虽然保留了物体的方向信息,但仍然不能仅根据旋转包围框的角度确定物体的准确头部。
实现目标航向检测的一个重要前提是精确的旋转检测器,它需要满足以下两个特点:
•在无边界情况下,检测器能够输出高精度的旋转边界盒。
•在边界情况下,检测器对边界问题不敏感。
因此,梯级多级策略与角度分类技术相结合可以解决上述问题。根据以上分析,我们对整个探测器进行了如下调整:
•由于 anchors的数量对于图像的目标检测发挥着重要的作用,所以在第一阶段的识别中不采用任何的角度分类计数以便得到更多的 anchors,以提供高质量的初始候选框。
•在第一阶段使用回归预测获得精细化anchors后,每个特征点上特征图只保留具有最高置信度的精炼anchors。细化anchors的过滤使得参数A(anchors的数量)在每个细化阶段都等于1,这意味着我们可以使用角度分类技术。
•使用90度角定义方法,如图2(a)所示,将AR减小到最小。同时,为了解决第一阶段的未处理边界问题和细化阶段的EoE问题,我们在每个阶段都使用 IoU-Smooth L1损失函数。
损失函数的设计( Loss Function Design)
任务管道包含了基于回归的预测分支和基于角度分类的预测分支,以便在平等的基础上对两种方法进行性能比较。模型主要输出位置和大小四项:
其中x;y;w;h分别表示箱体的中心坐标、宽度、高度和角度。变量x;;
分别为地面真值箱、锚点箱和预测箱(同理y;w;h)。
对于回归分支的角度预测,我们使用两种形式进行比较:
1)直接回归():
,
2)间接回归():
同时为了确保,进行归一化处理:
,
多任务损失函数的定义如下:
其中和
分别为样本总数和positive样本数,
为预测向量,
为地面真值的目标向量。
和
分别为角度的标记和预测。
和
分别表示理论角度误差和预测角度误差。
和
分别表示地面真值和预测边界盒的头部。
表示对象的标号,
为用sigmoid函数计算出的各类的概率分布。超参数
(k = 1;2;..5)控制权重。分类损耗
、
和
是焦点损耗[或s型交叉熵损耗取决于检测器。回归损失
中使用的平滑L1损失。
总结
以上便是博主对于该论文1-9页基本原理的解读,有些地方我也不太清楚,只能按照自己的理解说出自己的思路,如果理解有误的地方欢迎大家提出督促我改正!















 2312
2312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









