






文章目录
论文地址: http://openaccess.thecvf.com/content_ICCV_2019/papers/Yang_SCRDet_Towards_More_Robust_Detection_for_Small_Cluttered_and_Rotated_ICCV_2019_paper.pdf
参考:https://zhuanlan.zhihu.com/p/107400817
1. 动机
遥感目标检测有以下三个难点:
- 小目标(small objects)。遥感图像通常包含被复杂周围场景淹没的小物体;
- 密集(cluttered arrangement)。检测对象往往排列密集,如车辆、船舶等;
- 方向任意(arbitrary orientations)。遥感图像中的物体以不同的方向出现。
1.1相关工作
现存通用水平目标检测算法局限:
- Faster-RCNN等通用目标检测算法往往基于水平框进行设计,而遥感图像中目标往往是旋转目标。
- 非极大值抑制(NMS)技术作为后处理技术凸显了这种限制,因为它会抑制任意方向上密集排列的物体检测。
- 水平框的目标检测无法预测方向,而这是遥感提取信息的关键。
现存遥感目标检测算法局限:
- 针对特定的对象类别而设计,如车辆、飞机等
- 缺乏处理小尺寸和高密度。
任意方向目标检测算法局限:
- 大多是应用在文字检测领域,单分类
- 遥感图像中目标更加紧挨
2. SCRDet检测器
整体框架基于Faster RCNN,包含SF-Net、MDA-Net和 IoU-Smooth L1 Loss,整体结构图如下

2.1 SF-Net(finer sampling and feature fusion network)
2.1.1动机
检测小物体存在两个主要障碍:
- 物体特征信息不足
- 锚点样本不足。
原因是由于池化层的使用,小物体在深层中丢失了大部分特征信息。 同时,高层特征图的较大采样步长往往会直接跳过较小的对象,导致采样不足。
文章认为特征融合和有效的采样是较好检测小目标的关键。
对于anchor-based来说,anchor的铺设方式直接影响正样本采样率。经典的anchor铺设方式和特征图的分辨率有关,也就是anchor铺设的步长(C2-C5上的anchor步长分别是4,8,16,32)。随着网络加加深,特征图分辨率下降,anchor的步长扩大,常常会导致小目标的采样丢失,如下图所示:
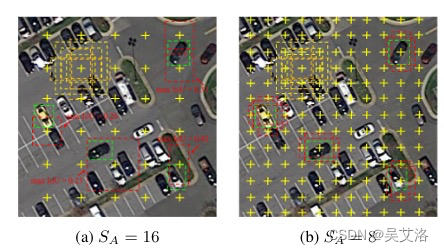
黄色框表示Anchor,绿色框表示GT,红色框表示anchor与GT的最大IoU
文章通过resize的方式选取了一个合适的特征图分辩率,尽可能保证小目标都被采样到,再加上简单的特征融合保证丰富的语义信息和位置信息。(注:文章没有使用C2,遥感目标检测会设置较多的尺度和比例,在C2特征图上的anchor就变得太多了,而且在遥感数据集中最小的目标一般也都在10像素以上,指DOTA1.0)
2.1.2 结构图

SF-Net仅使用Resnet中的C3和C4进行融合,以平衡语义信息和位置信息,同时忽略其他不太相关的特征。
- C4直接上采样至设定的下采样步长(实验表明下采样步长为6效果最好)
- C3上采样至相同大小,然后通过 inception 结构来扩展其感受野并增加语义信息。 inception结构包含多种比率卷积核来捕获物体形状的多样性。
- 最后而这按元素相加得到F3
注:anchor-based方法要充分保证RPN的召回,增加anchor这种做法是暴力的,一个较大的副作用就是检测器变得非常慢,anchor-free可能是个好方法。
2.2 MDA-Net(Multi-Dimensional Attention Network)
2.2.1动机
由于遥感图像背景的复杂性,RPN产生的建议区域可能引入大量噪声信息,如下图所示。
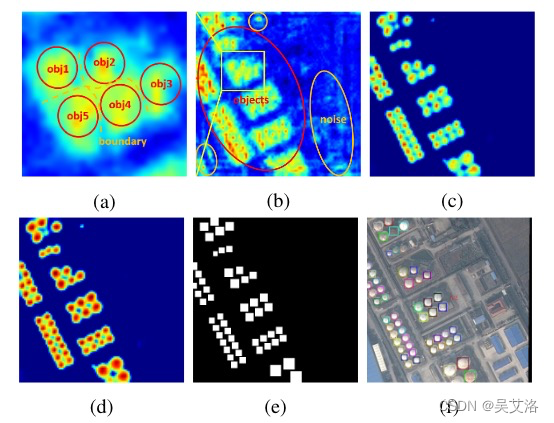
(a)界限模糊 (b)输入Attention模块之前 ©输出Attention模块之后 (d)显著图 (e)二值图 (f)标签
过多的噪音可能会混淆物体信息,物体之间的界限将变得模糊,导致漏检并增加虚警。因此,有必要增强物体特征并削弱非物体特征。
2.2.2网络结构
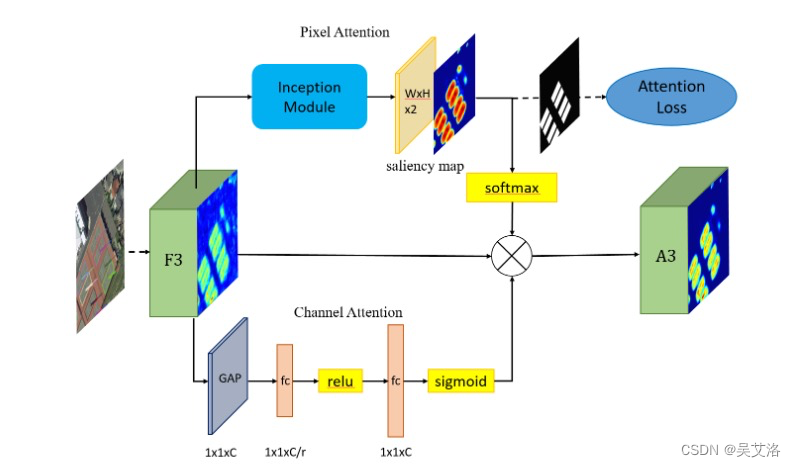
为了更有效地捕捉复杂背景下小物体的特征,文章设计了一种有监督的多维注意力网络(MDA-Net),如下图所示。
-
基于像素的注意网络中,特征图F3通过具有不同大小卷积核进行卷积运算,学习得到双通道的显著图(参见上图d)。这个显著图显示了前景和背景的分数。采取监督学习的方式训练注意力网络,根据groundtruth得到一个二值图作为标签(如上图e所示),然后使用二值图和显着性图的交叉熵损失作为注意力损失。
-
选择显著图中的一个通道与F3相乘,得到新的信息特征图A3(参见上图c)。
-
还使用SENet作为通道注意网络进行辅助,缩减比例值为16。
需要注意的是,Softmax函数之后的显着图的值在[0,1]之间。它可以降低噪声并相对的增强对象信息。由于显著图是连续的,因此不会完全消除背景信息,这有利于保留某些上下文信息并提高鲁棒性。
注:空间注意力加通道注意力的组合,空间注意力在遥感检测非常有用的
2.2 IoU-Smooth L1 Loss
2.2.1 动机
常用的旋转检测框的角度定义下,存在旋转角的的边界问题,产生不必要的损失。
2.2.2 定义
引入 IoU 常数因子 ∣ − l o g ( I o U ) ∣ ∣ L r e g ( v j , , v j ) ∣ \frac{|-log(IoU)|}{|L_{reg}(v_j^,\ ,v_j)|} ∣Lreg(vj, ,vj)∣∣−log(IoU)∣在Smooth L1 Loss中,如下面公式中的回归部分

在边界情况下,新的损失函数近似等于0,消除了损失的突增。新的回归损失可分为两部分,smooth L1回归损失函数取单位向量确定梯度传播的方向,而IoU表示梯度的大小,这样loss函数就变得连续。此外,使用IoU优化回归任务与评估方法的度量标准保持一致,这比坐标回归更直接和有效。
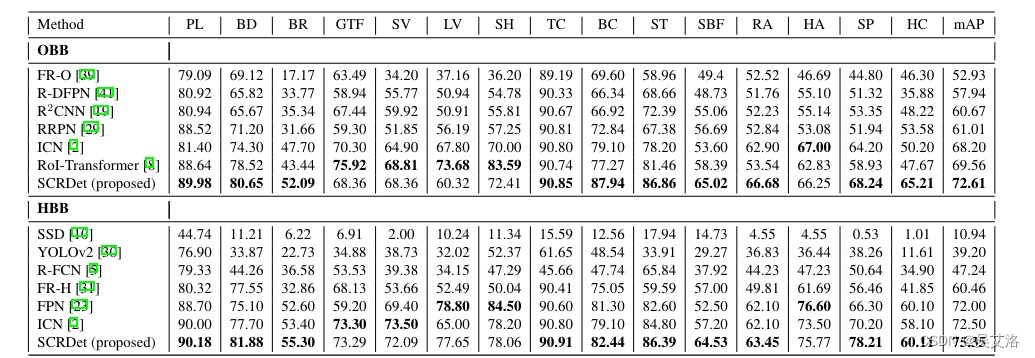
3.实验结果
3.1消融实验
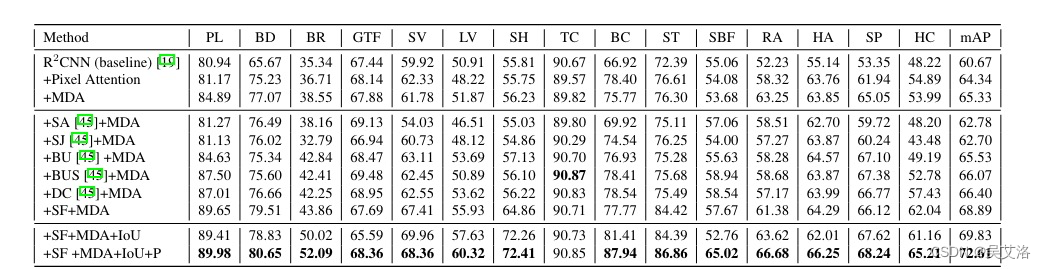
3.1对比实验(DOTA)















 2474
2474











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









