







 GPT 是把 Transformer 的解码器提出来,在没有标注的大数据下完成一个语言模型,作为预训练模型,然后在子任务上做微调获得不同任务的分类器。这个逻辑和我们的计算机视觉的套路是一样的。这个模型叫 GPT-1。GPT-2 收集了更大的数据集,生成了更大的模型这就算 GPT-2,证明了当数据库越大,模型越大,能力就有可能越强,但是需求投入多少钱可以得到预期效果,大家都不确定,所以 GTP-2 没有在市场上获得特别强的反响。GPT 团队认为自己的算法没有问题,思路没有问题,逻辑没有问题,唯一有问题
GPT 是把 Transformer 的解码器提出来,在没有标注的大数据下完成一个语言模型,作为预训练模型,然后在子任务上做微调获得不同任务的分类器。这个逻辑和我们的计算机视觉的套路是一样的。这个模型叫 GPT-1。GPT-2 收集了更大的数据集,生成了更大的模型这就算 GPT-2,证明了当数据库越大,模型越大,能力就有可能越强,但是需求投入多少钱可以得到预期效果,大家都不确定,所以 GTP-2 没有在市场上获得特别强的反响。GPT 团队认为自己的算法没有问题,思路没有问题,逻辑没有问题,唯一有问题
GPT 是把 Transformer 的解码器提出来,在没有标注的大数据下完成一个语言模型,作为预训练模型,然后在子任务上做微调获得不同任务的分类器。这个逻辑和我们的计算机视觉的套路是一样的。这个模型叫 GPT-1。
GPT-2 收集了更大的数据集,生成了更大的模型这就算 GPT-2,证明了当数据库越大,模型越大,能力就有可能越强,但是需求投入多少钱可以得到预期效果,大家都不确定,所以 GTP-2 没有在市场上获得特别强的反响。
GPT 团队认为自己的算法没有问题,思路没有问题,逻辑没有问题,唯一有问题的就是没有菠菜罐头,所以 GPT 团队找了金主买了菠菜罐头,终于大力水手升级为暴力水手,从大力出奇迹转变为暴力出奇迹,惊艳的 GPT-3 终于诞生了,那么这么暴力升级有多恐怖呢?GPT-3 数据和模型都比 GTP-2 大了100倍!
GPT
GPT全称是 Generative Pre-trained Transformer,名字非常直白,就是生成式预训练转换器。GPT 想解决的问题:在 NLP 领域有很多任务,虽然有了互联网,我们已经可以方便的采集大量的样本,但是相对于有标注的样本,更多存在的是无标注样本,那么我们怎么来使用这些无标注的样本。
GPT 团队的解决方案是在没有标注的样本上训练出一个预训练的语言模型,然后在有标注的特定的子任务上训练一个微调分类器模型。具体来说就是先让模型在大规模无标注数据上针对通用任务进行训练,使模型具备理解语言的基础能力,然后将预训练好的模型在特定的有标注数据上针对下游任务进行微调,使模型能够适应不同的下游任务。
但是 NLP 并不是 AI 中一个新的领域,在之前其实已经有了很多出色的 NLP 模型,那 GPT 的创新在哪里呢?之前的 NLP 模型是和任务绑定的,比如分词,词向量,句子相似度,每一个任务都有自己的模型,所以每一个新任务都需要一个新模型。GPT 的方式是生成一个大模型,然后通过输入的形式就可以获得不同的任务结果。这个是非常创新的思路。
当然了,统一的想法是好的,谁不想要一个这样的统一模型呢?但明显会遇到几个挑战:
-
损失函数怎么选择,因为在原先的方式中,不同的任务具有不同的损失函数,能不能找到一个损失函数可以为所有任务提供有效服务呢?
-
NLP 子任务的各自表现形式不同,怎么设计一个表示方式,有没有一种统一的表示可以让所有子任务接受。
-
在没有标注的文本上训练一个大的语言模型,然后在子任务上进行微调,GPT 称为半监督方式。有大量的无标注的数据和有标注的数据,这些数据具有相似性,那我怎么用我已经标注的数据来有效的使用那些无标注的数据。后来这个方式又叫自监督模型了。
下面是 GPT 提出的解决方案:
-
无监督预(自监督)训练:在没有标注的数据上做预训练。假设我们有一段文本,里面每一个词都是有序的,GPT 使用了 Transformer 的解码器来预测第一个词出现的概率。预测的方式就是通过前面的词的序列来预测接下来词出现的概率,是不是觉得和我们的联想输入法特别相似,所以前面的词越长,预测出后面词出现的概率精度就越高,这点应该是非常容易理解的。同时我们也可以想象出,这个计算是非常恐怖的。我总觉得 GPT 团队大概很想通过这样的预测模式来预算股票走势。
-
微调:微调就是输入一段文本,同时给这一段文本设计一个标注,这是一个比较标准的分类手段。GPT 的创新是对这段微调文本同时使用了对下一个词的预测和对完整文本的标签预测。
-
NLP 的子任务表示形式:NLP 的子任务有很多种,传统 NLP 的任务模型和输入都是对应的,就是一个模型对应一个任务,GPT 要做一个统一模型,就必须定义一个 NLP 子任务的表示形式。
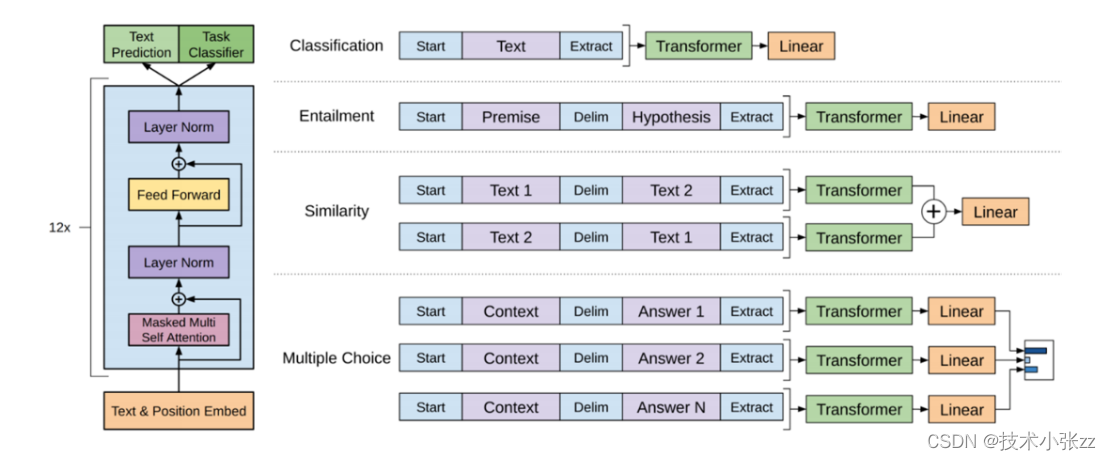
下面的图非常重要,在我看来比论文中各种眼花缭乱的公式重要的多。
-
分类输入表示:将需要分类的文本在前后加上开始和结束标记,然后放入 Transformer,然后模型对特放进线性层进行微调。
-
推理输入表示:推理表达是对两段文本给出支持,反对和中立三分类的问题。比如前提为:一个人今年32岁,假设是他未成年,这段的标签就是反对。也能出现前提是:他喜欢吃狗肉。假设是:他不是爱狗人士。如果是我做标签的话,我可能会给出中立的标签。所以微调其实是存在标签设计者者的偏向的。
-
相似输入表示:两段文本的表达方式不一样,但他们的含义是相似的。由于模型是单向的,但相似度与顺序无关。所以需要将两个句子顺序颠倒后两次输入的结果相加来做最后的推测。
-
多选题输入表示:给出一个问题和一组答案,预测对这个问题是不是能给出正确答案。
除了无标注文本和自监督学习外,GPT 还有一个创新,这个创新是贯穿了整个 GTP-1-2-3,也是 GPT 和 BERT 的一大区别:GPT 模型既使用了前馈神经网络,又使用
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 44
44











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











