







一、前期准备过程
1、代码:https://github.com/VITA-Group/EnlightenGAN
2、conda创建虚拟环境:
conda create -n enlighten python=3.5
3、进入项目文件夹,打开终端
conda activate enlighten
pip install -r requirement.txt
4、创建文件夹mkdir
mkdir model
5、下载VGG pretrained model,放入model文件夹中
二、训练过程
1、创建文件夹…/final_dataset/trainA and …/final_dataset/trainB(即final_dataset文件夹与项目文件夹同级的位置),将图片下载分别放入
2.进行可视化过程
nohup python -m visdom.server -port=8097
可选步骤
1.打开浏览器,输入http://localhost:8097/(可以实时观看图片结果)
如果在另一台电脑上跑,输入地址:地址号:端口号
如:10.162.34.109:8097
2.关于如何停止visdom.server步骤:
(1)ps -aux | grep visdom.server
(2)sudo kill 进程号(PID)
- 可能出现的问题:
(1)
解决:
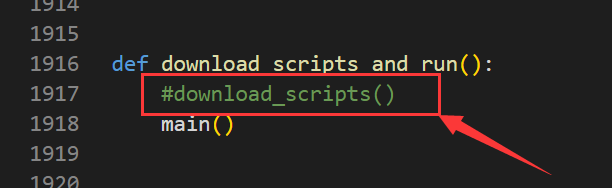
修改server.py文件
找到Anaconda3\envs\pytorch\Lib\site-packages\visdom\server.py文件,在1917行(不一定每个人都在这一行,从后往前找就行),将其注释掉。
(2)
ERROR:tornado.general:Could not open static file ‘/home/xl/.conda/envs/enlighten/lib/python3.5/site-packages/visdom/static/js/react-grid-layout.min.js’
解决:实验室的服务器没有网,需要离线本地下载react-grid-layout.min.js文件放到/home/xl/.conda/envs/enlighten/lib/python3.5/site-packages/visdom/static/js/下
3.另开一个终端,激活虚拟环境enlighten后,输入:
python scripts/script.py --train
- 可能出现的问题:
RuntimeError:cuDNN error: CUDNN_STATUS_EXECUTION_FAILED
解决方法:
(1)在train.py中加入:
import torch
torch.backends.cudnn.enabled = False
(2)将batchsize改小或者减小训练图片的尺寸
我的将batchsize改为了1,把训练图片的尺寸改成了256*256,
并且将base_dataset.py中的transform_list.append(transforms.RandomCrop(opt.finesize))改成了transform_list.append(transforms.RandomCrop(256))
注意:训练挺需要显存的,论文作者说3张1080ti训练3个小时。不然就只能把batchsize调小了
4.运行成功
------------ Options -------------
D_P_times2: False
IN_vgg: False
batchSize: 1
beta1: 0.5
checkpoints_dir: ./checkpoints
config: configs/unit_gta2city_folder.yaml
continue_train: False
dataroot: ../final_dataset
dataset_mode: unaligned
display_freq: 30
display_id: 1
display_port: 8097
display_single_pane_ncols: 0
display_winsize: 256
fcn: 0
fineSize: 320
gpu_ids: [0]
high_times: 400
hybrid_loss: True
identity: 0.0
input_linear: False
input_nc: 3
instance_norm: 0.0
isTrain: True
l1: 10.0
lambda_A: 10.0
lambda_B: 10.0
latent_norm: False
latent_threshold: False
lighten: False
linear: False
linear_add: False
loadSize: 286
low_times: 200
lr: 0.0001
max_dataset_size: inf
model: single
multiply: False
nThreads: 4
n_layers_D: 5
n_layers_patchD: 4
name: enlightening
ndf: 64
new_lr: False
ngf: 64
niter: 100
niter_decay: 100
no_dropout: True
no_flip: False
no_html: False
no_lsgan: False
no_vgg_instance: False
noise: 0
norm: instance
norm_attention: False
output_nc: 3
patchD: True
patchD_3: 5
patchSize: 32
patch_vgg: True
phase: train
pool_size: 50
print_freq: 100
resize_or_crop: crop
save_epoch_freq: 5
save_latest_freq: 5000
self_attention: True
serial_batches: False
skip: 1.0
syn_norm: False
tanh: False
times_residual: True
use_avgpool: 0
use_mse: False
use_norm: 1.0
use_ragan: True
use_wgan: 0.0
vary: 1
vgg: 1.0
vgg_choose: relu5_1
vgg_maxpooling: False
vgg_mean: False
which_direction: AtoB
which_epoch: latest
which_model_netD: no_norm_4
which_model_netG: sid_unet_resize
-------------- End ----------------
train.py:11: YAMLLoadWarning: calling yaml.load() without Loader=... is deprecated, as the default Loader is unsafe. Please read https://msg.pyyaml.org/load for full details.
return yaml.load(stream)
CustomDatasetDataLoader
dataset [UnalignedDataset] was created
#training images = 1016
./model
---------- Networks initialized -------------
DataParallel(
(module): Unet_resize_conv(
(conv1_1): Conv2d(4, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(downsample_1): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), dilation=(1, 1), ceil_mode=False)
(downsample_2): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), dilation=(1, 1), ceil_mode=False)
(downsample_3): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), dilation=(1, 1), ceil_mode=False)
(downsample_4): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), dilation=(1, 1), ceil_mode=False)
(LReLU1_1): LeakyReLU(0.2, inplace)
(bn1_1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True)
(conv1_2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1),  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1100
1100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









