










[自动驾驶算法][从0开始轨迹预测] [文献阅读笔记] [MTR]:Motion Transformer with Global Intention Localization and Local Movement Refinement
1. 概述
这篇论文是2022年Waymo Open Motion Dataset(WOD)冠军方案:https://github.com/sshaoshuai/MTR
1.1 模型解决问题的方向
- 当前一系列的轨迹预测方案注重于场景的建模与交互,即编码器架构,涌现出一系列经典的模型和与方案(如VectorNet、PointNet编码方式、LaneGCN等),但是对于特征的解码研究较为单一,要么是直接对编码器输出的特征,基于回归的方法进行多模态解码,要么采用基于密集采样点的方法(如DenseTNT,Home(密度图)),基于目标进行多模态解码;前者模型收敛速度慢,且解码出的多模态轨迹来自于同一特征;而后一种方案高度依赖采样终点的数量,并且性能较差(采样点密集,后处理NMS较重)
- 文章通过优化解码器结构入手,借鉴DAB-DETR的架构,通过使用 intention anchor(终点模式) 初始化learnable query,迭代多次优化预测结果。
- 当前轨迹预测方案,对场景建模的结果进行编码,这不能很好的建模agent之间在未来时刻的交互。
1.2 主要结论和贡献
- (1)提出了一种的运动解码器网络,具有运动查询对的新概念,采用两种类型的查询对运动预测进行建模,将全局意图定位和局部运动细化进行联合优化。 它不仅可以通过特定于模式的运动查询对来稳定训练,还可以通过迭代收集细粒度的轨迹特征来实现自适应运动细化。
- (2)提出了一个辅助密集的未来预测任务,以实现感兴趣的智能体和其他智能体之间的未来交互。
2. 模型
2.1 模型架构
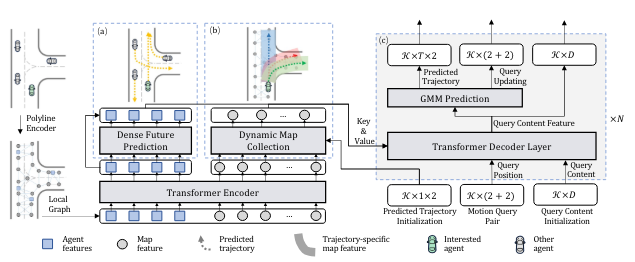
MTR模型的整体架构如图所示,(a) 表示稠密未来预测模块,它预测每个智能体的单个轨迹(例如,在上面的 (a) 中绘制为黄色虚线)。 (b) 表示动态地图收集模块,它沿着每个预测轨迹收集地图元素(例如,在(b)的上述部分中沿着每个轨迹绘制为阴影区域)以提供特定于轨迹的地图元素运动解码器网络的功能。 ©表示运动解码器网络,其中𝒦是运动查询对的数量,𝑇是未来帧的数量,𝐷是隐藏特征维度𝑁 是 Transformer 解码器层数。 预测轨迹、运动查询对和查询内容特征是最后一个解码器层的输出,并将作为下一个解码器层的输入。 对于第一解码器层,运动查询对的两个分量都被初始化为预定义意图点,预测轨迹被替换为初始地图收集的意图点,并且查询内容特征被初始化为零。
2.2 模型输入
模型将环境信息(周围agent、车道线)组织成VectorNet中的折线形式,对于要预测的障碍物,以该障碍物为中心,将场景归一化到预测障碍物的坐标系内。
使用PointNet的折线编码器建模输入特征(PointNet是一种类似于VectorNet的特征提取编码器)。
障碍物折线特征: A i n ∈ R N a × t × C a A_{in}\in \mathbb{R}^{N_a\times t \times C_a} Ain∈RNa×t×Ca,其中, N a N_a Na为周围障碍物的数量, t t t为障碍物历史帧的长度, C a C_a Ca为历史帧数的障碍物状态信息(例如,位置、航向角和速度),并且我们在缺少帧的位置处填充零,以获取少于 t t t 帧的轨迹。
地图道路这线特征: M i n ∈ R N m × n × C m M_{in}\in \mathbb{R}^{N_m\times n \times C_m} Min∈RNm×n×Cm,其中, N m N_m Nm为周围车道线折线的数量, n n n为每条折线的点数, C m C_m Cm为每个折线点的状态信息(例如,位置、道路类型等),并且我们在缺少帧的位置处填充零,以获取少于 m m m 帧的折线特征。
PointNet特征编码:
A
p
=
ψ
(
M
L
P
(
A
i
n
)
)
,
M
p
=
ψ
(
M
L
P
(
M
i
n
)
)
A_p=\psi(\mathbf{MLP}(A_{in})), M_p=\psi(\mathbf{MLP}(M_{in}))
Ap=ψ(MLP(Ain)),Mp=ψ(MLP(Min))
其中, ψ ( . ) \psi(.) ψ(.)为最大池化操作,输出特征维度 A p ∈ R N a × D A_{p}\in \mathbb{R}^{N_a\times D} Ap∈RNa×D, M p ∈ R N m × D M_{p}\in \mathbb{R}^{N_m\times D} Mp∈RNm×D
2.4 局部场景编码器(Local Transformer Encoder)
对于场景的编码,与SceneFormer不同:对周围场景特征做self-attention,作者通过限制周围参与建模的场景特征的方式(局部注意力)来保持局部场景特征的注意力,提高注意力机制的提取效率并减少内存的使用(QCNet & SEPT同样的思路,不再建模全局连通图转而建模局部连通图)。
具体来说,第𝑗个Transformer编码器层的注意力模块可以表示为:
G
j
=
M
H
A
(
q
u
e
r
y
=
G
j
−
1
+
P
E
G
j
−
1
,
k
e
y
=
κ
(
G
j
−
1
)
+
P
E
κ
(
G
j
−
1
)
,
v
a
l
u
e
=
κ
(
G
j
−
1
)
)
G^j=\mathsf{MHA}(query=G^{j-1}+\mathsf{PE_{G^{j-1}}}, key=\kappa{(G^{j-1})}+\mathsf{PE_{\kappa (G^{j-1})}},value=\kappa{(G^{j-1})})
Gj=MHA(query=Gj−1+PEGj−1,key=κ(Gj−1)+PEκ(Gj−1),value=κ(Gj−1))
其中,
M
H
A
(
.
)
\mathsf{MHA(.)}
MHA(.)是多头注意力层,
G
0
=
[
A
p
,
M
p
]
∈
R
(
N
a
+
N
m
,
D
)
G^0= [A_p,M_p]\in\mathbb{R}^{(N_a+N_m,D)}
G0=[Ap,Mp]∈R(Na+Nm,D),为聚合的agent和车道线的场景特征,
κ
(
.
)
\kappa (.)
κ(.)为k-最近邻算法,为每个query折线找到k个最近的折线特征,PE为正弦位置编码,使用每个agent当前帧的位置和道路折线特征的中点。
局部场景编码器输出 G p a s t ∈ R ( N a + N m ) × D G^{past}\in \mathbb{R} ^{(N_a + N_m) \times D} Gpast∈R(Na+Nm)×D,对应于agent历史特征 A p a s t ∈ R N a × D A_{past}\in \mathbb{R}^{N_a \times D} Apast∈RNa×D 和地图特征 M ∈ R N m × D M \in \mathbb{R}^{N_m \times D} M∈RNm×D
2.5 预测轨迹的初步解码(单模态)Dense Future Trajectory Decoder
通过局部场景编码器,将周围环境的特征进行了编码,此时每个agent的特征包含了丰富的上下文信息,文章对特征先行进行单模解码,输出每个障碍物的单模态轨迹。对未来的轨迹进行交互建模。
类似于QCNetX的思路,区别在于QCNetX通过query的形式进行隐式的交互,本文作者采用的显式解码后,重新编码交互。
该部分作者通过一个简单的MLP回归头解码:
S
1
:
T
=
M
L
P
(
A
p
a
s
t
)
S_{1:T}=\mathbf{MLP}(A_{past})
S1:T=MLP(Apast)
其中
S
∈
R
N
a
×
T
×
4
S\in\mathbb{R}^{N_a \times T \times4}
S∈RNa×T×4,预测T个时间步内的位置和速度,使用PointNet的特征编码器编码预测的轨迹,输出
A
f
u
t
u
r
e
∈
R
N
a
×
D
A_{future}\in\mathbb{R}^{N_a \times D}
Afuture∈RNa×D,将编码后的预测特征与编码器的编码特征concat后过三层Linear编码:
A
=
M
L
P
(
[
A
p
a
s
t
,
A
f
u
t
u
r
e
]
)
A=\mathbf{MLP}([A_{past},A_{future}])
A=MLP([Apast,Afuture])。
2.6 Motion Query Pair Transformer Decoder
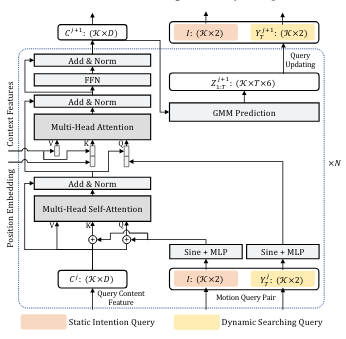
与SceneFormer、QCNet、SEPT使用随机初始化的trajectory query去解码轨迹不同,作者设计了两种query PE形式:使用全局意图初始化的静态query PE和经过预测轨迹终点更新后的动态query PE,共同组成了trajectory query PE,文章中叫做Motion Query Pair。
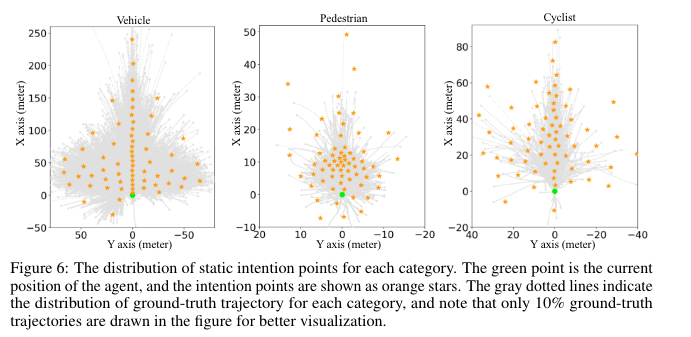
静态意图 PE: 通过限制不同模式的终点,来缩小预测任务的状态空间。
类似于MultiPath中对数据集进行轨迹模式聚类,生成anchor的形式,与之不同点是文章只使用了gt轨迹终点进行K-MEANS聚类,聚类类别为64,即使用64种类别的模式
K
\mathfrak{K}
K 代表意图点的个数
I
∈
R
K
×
2
I∈ℝ^{\mathfrak{K}×2}
I∈RK×2,在ground-truth(GT)轨迹的端点上采用k-means聚类算法,其中每个意图点代表一个考虑两个运动方向的隐式运动模式和速度。 将每个静态意图查询建模为意图点的可学习位置嵌入,如下所示:
Q
I
=
M
L
P
(
P
E
(
I
)
)
Q_I=\mathbf{MLP({PE}}(I))
QI=MLP(PE(I))
其中
P
E
(
⋅
)
\mathbf{PE(⋅)}
PE(⋅) 是正弦位置编码,
Q
I
∈
R
K
×
D
Q_I\inℝ^{\mathfrak{K} \times D}
QI∈RK×D。 每个静态意图query负责预测特定运动模式的轨迹,这稳定了训练过程并有助于预测多模态轨迹,因为每种运动模式都有自己的可学习嵌入。 由于它们的可学习和自适应特性,文章中使用了 64 个query,实现意图定位,而不是像DenseTNT使用密集的候选终点。
动态更新意图 PE: 文中又称为局部运动细化query,通过静态意图位置进行动态query的初始化,并通过预测轨迹的终点迭代更新,完成轨迹的refine。
说到预测轨迹的refine,文章SmartRefine,详细介绍了各种refine的方法,并提出了一种基于局部注意力的refine模块;
QCNet中使用的refine方法是对于traj propose模块输出的预测轨迹,使用GRU编码,提取时序特征,作为propose的trajectory query,并使用和propose模块相同的解码器进行Refine,输出的是propose trajectory的diff,该种方法输出的最终轨迹并不是连续平滑的轨迹!
具体来说,给定第
j
j
j 层解码器中预测的未来轨迹为
Y
1
:
T
j
=
Y
i
j
∈
R
K
×
2
∣
i
=
1
,
⋯
,
T
Y^j_{1:T}={Y_i^j∈ℝ^{\mathfrak{K}×2}∣i=1,⋯,T}
Y1:Tj=Yij∈RK×2∣i=1,⋯,T,使用轨迹终点
Y
T
j
Y_T^j
YTj 将第
(
j
+
1
)
(j+1)
(j+1)解码器层的动态搜索查询更新为:
Q
s
j
+
1
=
M
L
P
(
P
E
(
Y
T
j
)
)
Q_s^{j+1}=\mathbf{MLP(PE}(Y_T^j))
Qsj+1=MLP(PE(YTj))
动态地图特征收集模块:通过crop预测轨迹周围最近的L条车道线,来限制进入decoder的车道特征(不进行全局的cross-attention)。
2.6.1 Decoder
- 首先,静态意图PE作为位置嵌入,用于区分各个意图query之间的模式:
C s a i = M H S A ( Q = C j − 1 + Q I , K = C j − 1 + Q I , V = C j − 1 ) C_{sa}^i=\mathbf{MHSA}(Q=C^{j-1}+Q_I, K=C^{j-1}+Q_I, V=C^{j-1}) Csai=MHSA(Q=Cj−1+QI,K=Cj−1+QI,V=Cj−1)
其中 C j − 1 ∈ R K × D C^{j−1}∈ℝ^{\mathfrak{K}×D} Cj−1∈RK×D 是来自 ( j − 1 ) (j−1) (j−1) 解码器层的trajectory query的输出, 0 ^0 0 初始化为零, C s a j ∈ R K × D C_{sa}^j∈ℝ^{\mathfrak{K}×D} Csaj∈RK×D 是更新的query内容。
-
接下来,利用动态搜索PE作为交叉注意的查询位置嵌入,从编码器的输出中寻找特定于轨迹的特征。 受 DAB-DETR 的启发,将查询和键的内容特征和位置嵌入连接起来,以解耦它们对注意力权重的贡献。 分别采用两个交叉注意模块来聚合来自代理特征 𝐴 和地图特征 𝑀 的特征,如下所示:
C A j = M H C A ( Q = [ C s a j , Q S j ] , K = [ A , P E A ] , V = A ) C M j = M H C A ( Q = [ C s a j , Q S j ] , K = [ α ( M ) , P E α ( M ) ] , V = α ( M ) ) C j = M L P ( [ C A j , C M j ] ) C_A^j=\mathbf{MHCA}(Q=[C_{sa}^j,Q_S^j],K=[A,PE_A],V=A) \\ C_M^j=\mathbf{MHCA}(Q=[C_{sa}^j,Q_S^j],K=[\alpha(M),PE_{\alpha(M)}],V=\alpha(M)) \\ C^j = \mathbf{MLP}([C_A^j,C_M^j]) CAj=MHCA(Q=[Csaj,QSj],K=[A,PEA],V=A)CMj=MHCA(Q=[Csaj,QSj],K=[α(M),PEα(M)],V=α(M))Cj=MLP([CAj,CMj])
其中, α ( M ) \alpha(M) α(M)为动态地图收集模块的输出。 C j ∈ R K × D C^j∈ℝ^{\mathfrak{K}×D} Cj∈RK×D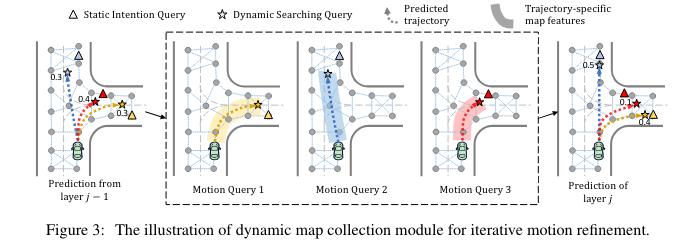
2.7 模型输出
使用高斯混合模型进行多模态运动预测。 对于每个解码器层,我们将MLP预测头附加到
C
j
C^j
Cj 生成未来的轨迹。由于智能体的行为是高度多模态的,在每个时间步用高斯混合模型(GMM,双变量高斯分布)表示预测轨迹的分布。对于每个未来时间步
i
∈
1
,
⋯
,
T
i∈{1,⋯,T}
i∈1,⋯,T,预测每个高斯分量的概率
p
p
p和参数
(
μ
x
,
μ
y
,
σ
x
,
σ
y
,
ρ
)
(\mu_x,\mu_y,\sigma_x,\sigma_y,\rho)
(μx,μy,σx,σy,ρ):
Z
1
:
T
j
=
M
L
P
(
C
j
)
,
Z_{1:T}^j=\mathbf{MLP}(C^j),
Z1:Tj=MLP(Cj),
其中
Z
i
j
∈
R
K
×
6
Z_i^j∈ℝ^{\mathfrak{K}×6}
Zij∈RK×6 包括概率分布
p
1
:
K
p_{1:\mathfrak{K}}
p1:K 以及高斯分量
N
1
:
K
(
(
μ
x
,
μ
y
,
σ
x
,
σ
y
,
ρ
)
\mathfrak{N}_{1:\mathfrak{K}}((\mu_x,\mu_y,\sigma_x,\sigma_y,\rho)
N1:K((μx,μy,σx,σy,ρ)。 代理在时间步
i
i
i 位置的预测分布可以表示为:
P
i
j
(
o
)
=
∑
k
=
1
K
p
k
⋅
N
k
(
o
x
−
μ
x
,
σ
x
;
o
y
−
μ
y
,
σ
y
;
ρ
)
P_i^j(o)=\sum_{k=1}^{\mathfrak{K}} p_k⋅\mathfrak{N}_k(o_x-\mu_x, \sigma_x; o_y-\mu_y, \sigma_y; \rho)
Pij(o)=k=1∑Kpk⋅Nk(ox−μx,σx;oy−μy,σy;ρ)
其中
P
i
j
(
o
)
P_i^j(o)
Pij(o)是智能体在空间位置
o
∈
R
2
o∈ℝ^2
o∈R2出现的概率。 通过简单地提取高斯分量的预测中心生成预测轨迹
Y
1
:
T
j
Y_{1:T}^j
Y1:Tj。
2.8 损失函数
损失函数包括两部分组成:
-
L1损失,优化密集未来预测与GT的损失函数
-
高斯回归损失,对上述公式取负对数似然。
优化最低的MinFDE的模式
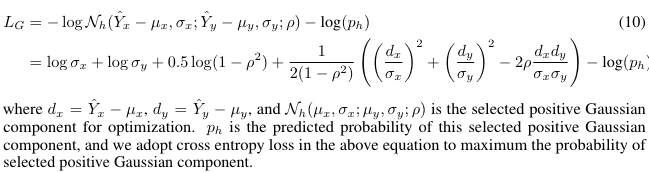
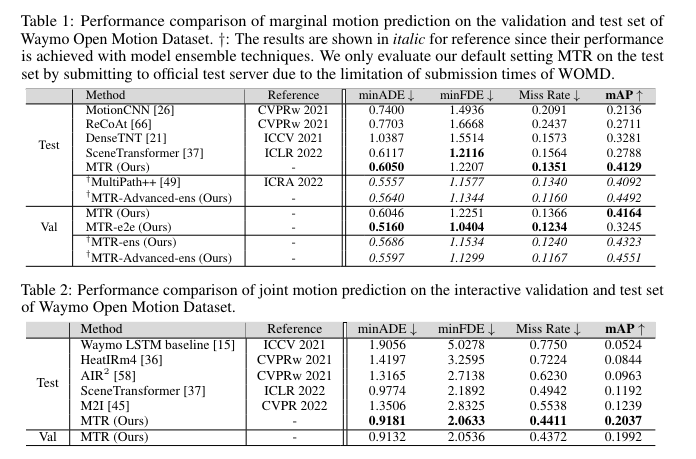
3. 实验
作者在Waymo联合预测和边缘预测两项任务中分别进行了实验。
对于局部场景编码器,堆叠了6个transformer编码器层,对于解码器,使用6个Transformer层,论文使用64个intention,最后输出使用NMS,筛选6条预测轨迹,距离阈值为2.5m。
其中为了消除NMS后处理逻辑,作者同样提出了一个6 intention的query的方案。
文章同时也进行了详尽的消融实验,定性和定量分析,毕竟是1st的方案,实验这块还是非常详尽的。
4. 思考和比较
-
MTR算是比较初期的工作,受Sceneformer和DAB-DETR结构和思路的影响,提出的动静意图query位置编码的方法,还是挺有创新点的,基于数据驱动的方法,动态学习agent的不同运动模式,算是TNT、DenseTNT在DETR基础上的改进版。
-
作者提出的未来密集轨迹预测辅助任务,可以显式的建模未来特征的交互,并使用L1 Loss去监督这项辅助任务。
QCNet是隐式的建模agent未来不同障碍物不同模式之间的交互,
-
对于场景的编码和使用,文章在两个阶段都使用了局部注意力机制的模式,从计算效率、内存使用、建模有效性的方向来考虑,使用局部连通图的建模方式替代全局连通图。
-
对了联合预测的建模,场景建模方面需要考虑旋转和平移不变性(如何归一化:QCNet?ForecaseMAE?),解码方面是否还需要每条意图的轨迹单独出概率???如何处理交互模式之间轨迹对的选择,尤其是在场景内障碍物的数量增多的情况下。合理的轨迹组合还是非常重要的。
-
对于intention anchor的建模,是否需要划分场景以及障碍物类型,比如直行场景和路口场景,前者倾向于直行的意图或者却有多种选择;再比如VRU和机动车,速度和运动模式的不同,导致其有不同的终点。















 639
639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









