






作者 | 一根呆毛 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/654070149
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【轨迹预测】技术交流群
本文只做学术分享,如有侵权,联系删文
本文包含MTR和MTR++两个model。
原文链接:https://arxiv.org/pdf/2306.17770.pdf (MTR和MTR++都写在里面了)
https://arxiv.org/pdf/2209.10033.pdf?trk=public_post_comment-text (只有MTR)
Abstract
轨迹预测的难点在于多种物体复杂多样的行为,以及复杂的环境信息的使用。此论文提出了Motion TRansformer (MTR). 这个transformer使用encoder和decoder结构,用intention作为query来获取轨迹。intention对应着不同mode的轨迹。结构中包含两部分:
global intention localization: 获取agent的intention
local movement refinement: 修正出精准的预测轨迹
同时此论文还提出了MTR++的结构,来实现同时预测多个agent的多mode轨迹。这个过程中自然是处理了不同agent间不同intention的交互。在性能上也有提升。
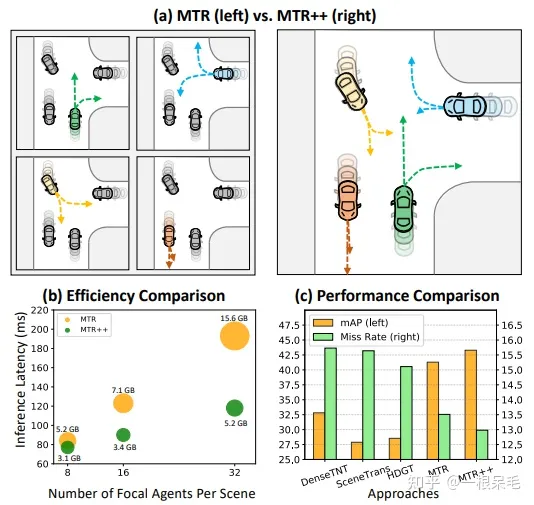
Introduction
传统方法使用MLP来直接回归多条轨迹,这样的话会导致预测结果倾向于学习发生频率最高的几个mode,而对于发生频率稀少的mode学习不充分。于是有论文提出了goal based的方案:给一把goal,然后预测通向每个goal的概率,再进行轨迹的预测(每个goal都是独立学习,及时发生频率低也确保能学习到)。这个做法很依赖goal的密度,而密度一高,算力又吃不消。因此提出了MTR的框架来处理多mode的预测。
MTR中使用了可学习的intention query。每个intention可以最后被解码成轨迹。intention query也使得可以同时优化abstract中的两个目标。
为了确保mode不塌缩(即学出来的mode都是同一个),预先在空间中生成了有限个分散的intention点。这些点也降低了最后轨迹的不确定性。也不用生成非常多的点,因为每个query负责的是一块区域。每个query也会做classification来获取概率来粗筛。最后再是iterative地去修正轨迹中的点。
本文侧重MTR++,会考虑多个agent联合预测。提出了symmetric scene context model,在每个agent附近的范围内会用self attention的方式来处理agent自身坐标系下的附近地图。在轨迹预测端,采用了交互的intention query来模拟交互。
此文有四个贡献:
提出了MTR框架,实现了使用intention query的方式来处理多mode的预测。
提出了MTR++来同时预测多个agent。这里包含了两部分:对于不同agent都有一个共用的场景理解model,对agent未来轨迹间的交互使用intention query来处理。
3.4. 都是打榜成功。
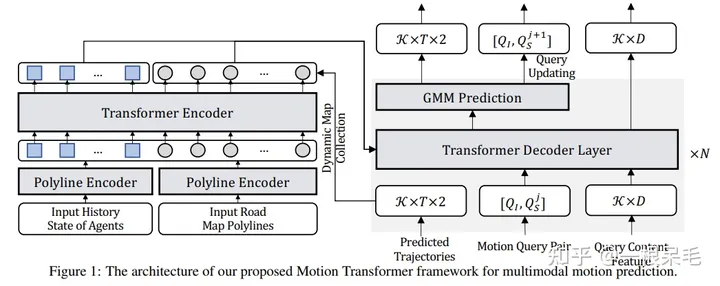
MTR
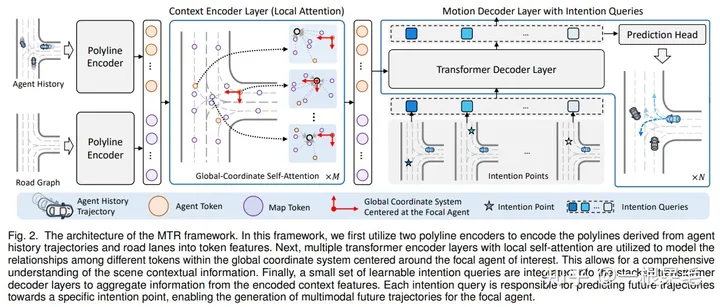
场景理解
采用transformer作为encoder。
Input Representation with Single Focal Agent:采用vector的形式编码地图和历史轨迹。所有node要转到agent的坐标系后再处理的。
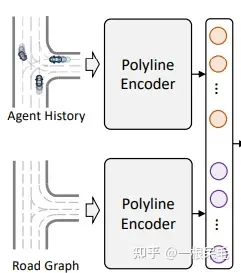

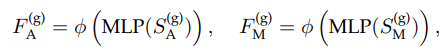

Scene Context Encoding with Local Transformer Encoder:上一步提取了每个node的特征,然后还需要把不同node的特征给融合起来。
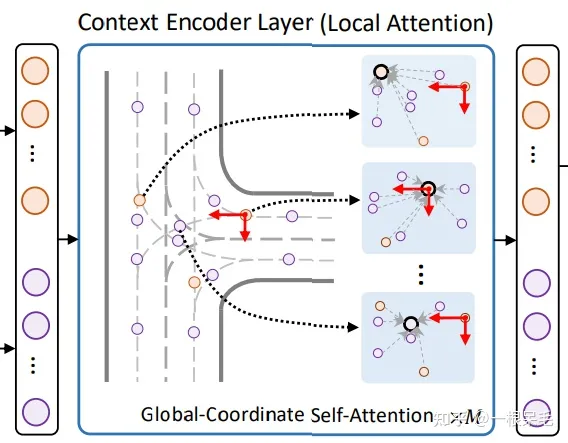
对上一步所有node采用了多头自注意力机制,每一个node都会concat上位置信息的positional encoding。因为我们没有必要考虑离这个node太远的node,所以提前计算出每个node附近的k个node: . 然后就是用Q去K里找对与附近node间的weight。然后去V那里做加权。整个过程就是标准的Transformer基础block,只不过对于KV的选取采用了附近的node来节省算力。
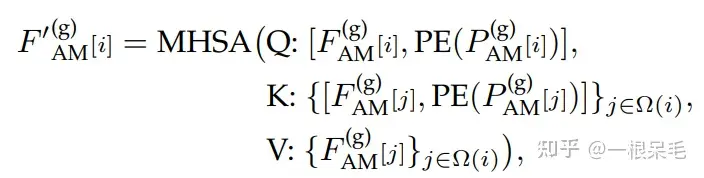
用transformer的另一个好处是,即使地图很大,对于每一个局部来说,都会再次提取每个node的特征给Q,K,V,这里对于所有node来说都是共享权重的,相比直接Dense融合,参数量会更少。
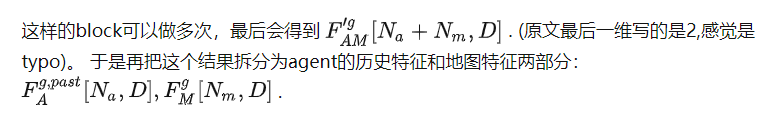 .
.
Dense Future Prediction for All Agent(是个辅助任务):处理agent间的交互,此论文不止考虑了历史轨迹的交互(前面融合的时候其实已经算进去了),还会侧重未来轨迹mode间的交互。
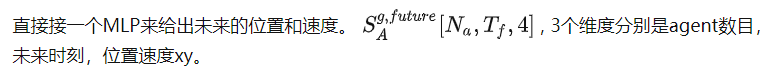
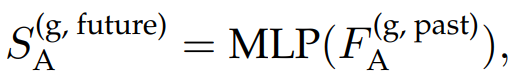

这个做法算是一个辅助任务,通过未来轨迹重新放到agent feature里来监督最后的预测结果,能提升model别的部分的性能。最后infer的时候自然不会使用这部分代码。
解码未来轨迹
利用intention query,使用transformer来解码。query的话是代表着不同的intention,以此来实现多mode的预测。使用了多个transformer block来一步步优化轨迹。
Learnable Intention Query:为了获得更精准的intention,采用了可学习的intention query。对agent的gt最后一个点进行统计,然后用k-means的做法来实现获取k个有较大区别的end point。每一个end point对应着一个intention,也即对应着最后的完整轨迹。
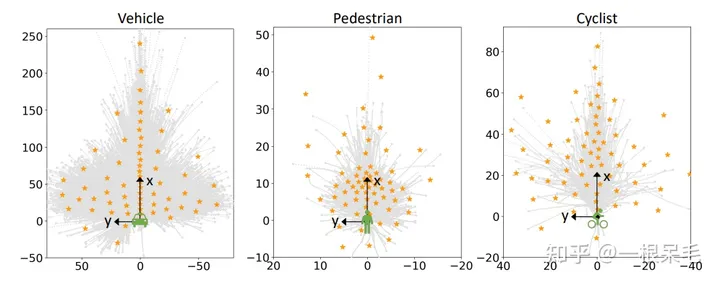

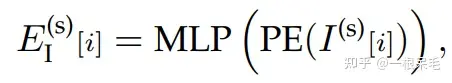
这样显式地获取intention query的方式使得intention的学习更简单稳定,可以快速学到结果且不容易mode塌缩。而且不需要非常多的query,因为k means起到了nms的作用,只挑出了区分度大且很有价值的end point。
Scene Context Aggregation with Intention Query:获得query后,就可以进行transformer了。首先先在同一agent的不同intention间做self-attention来交换mode间的信息,即每一个intention作为query去所有K个intention里找权重再加权。
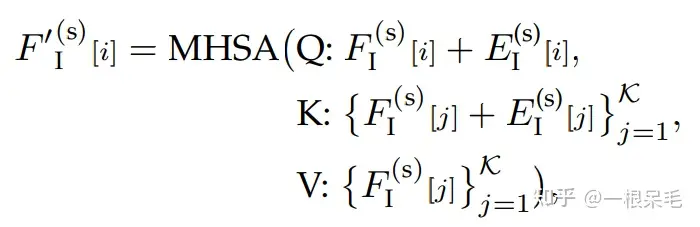

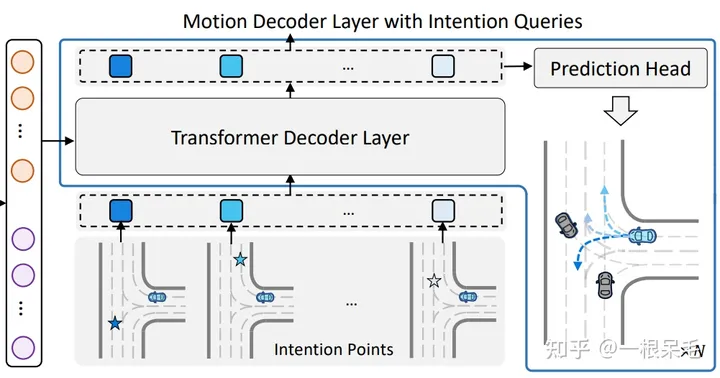

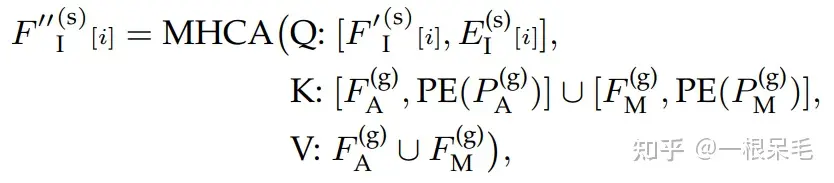
对于每个intention,周围的信息都是选取intention的附近的node。
Global Intention Localization:计算每个intention的概率。所有mode的特征经过一个MLP,获得k个概率,里面应该还会有softmax来确保总概率加起来为1。
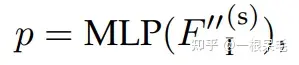

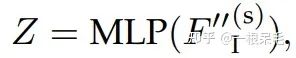
这样获得了新坐标,最后一个点是最后的坐标。把它concat到 上,就可以作为下一轮的query,再做transformer,再次refine轨迹。
这一层transformer获得的整条获得的轨迹则可以放入下一层的KV。
GMM获得多mode预测

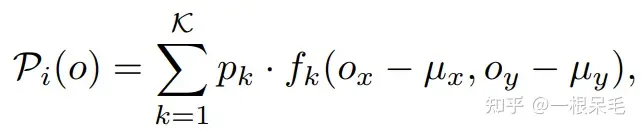
f是每个高斯分布的概率密度函数。o代表具体的一个xy坐标,那就可以查这个坐标的所有高斯概率密度函数里的值,再加权求和就是o处的真实概率密度。实际预测的时候,直接拿每个高斯分布的mean来当对应时刻的点的坐标就行了。(GMM概念上是混合了的高斯分布,但实际使用时就是多个单高斯分别算一下,并没有真正意义上混起来,对于靠近的高斯和远离的高斯其实没有做区分)
Training Loss:GMM部分的loss采用距离gt最近的mode的mean来计算,计算了gt在对应mode的高斯函数里的概率分布值,这个值越大说明gt离高斯的mean越近。gt对应的概率自然希望越高越好,所以也加上了概率的-log。
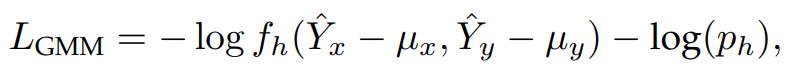
在前面还有提到一个辅助任务,那部分的loss也加上,最后获得了loss函数。
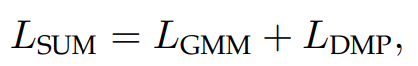
MTR++
在MTR中,需要对不同agent选择不同的周围node进行坐标系转换,不够高效。而像scene transformer的做法则是围绕ego car进行地图特征提取,这样就会导致远处信息没法很好提取。
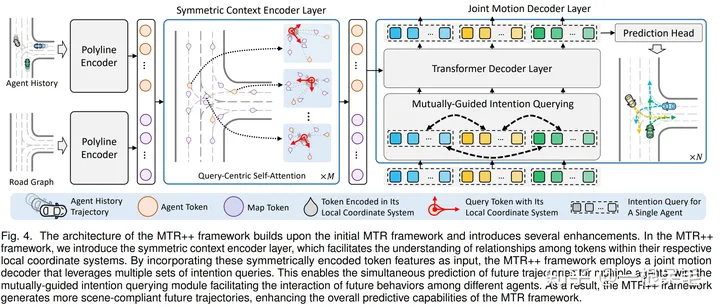
对称编码场景信息
常见做法是找出agent为中心的场景来分别处理。这里是一起编码。
Input Representation with Polyline-Centric Encoding:仍然采用向量的形式来表示输入地图和历史轨迹,但是不会把所有node都转到agent自己的坐标系,而是采用polyline为中心的做法。
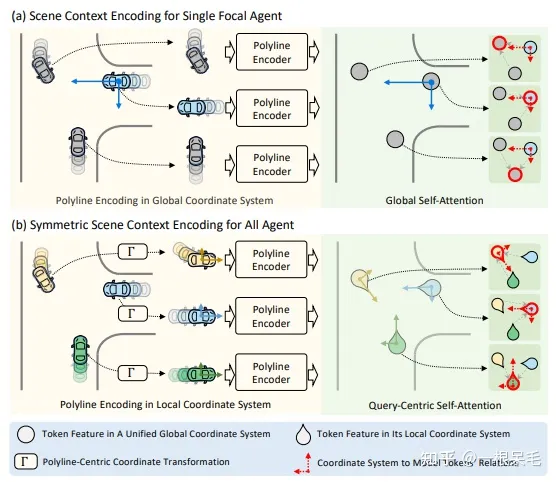
对于agent,采用当前位置为中心,朝向为方向。对于地图元素,采用整个polyline的几何中心和其切线方向。因此先对它们的state进行平移旋转。之后再和之前一样处理:MLP后maxpooling处理。这样类似pointnet的做法获取了node的整体特征。
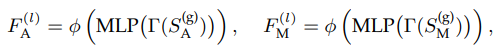


Symmetric Scene Context Modeling with Query-Centric Self-Attention:如果目标是i的token,对于别的token j,还是需要处理他们的坐标信息,但只需要处理每个node中一个点的坐标和朝向就行。下式就是旋转平移到i的坐标系里。
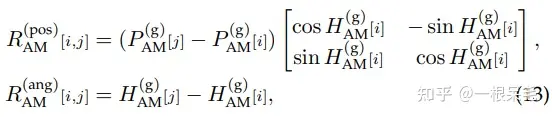
pos和ang的R作为成新的R用来替换MTR里的P,注意力机制的做法一致。
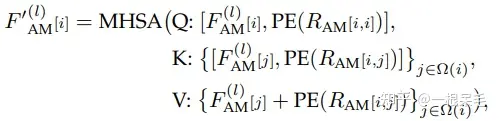
计算量和MTR中差不多,但对于多个agent一起预测很友好,因为有很大部分是共享的。
联合运动解码
场景编码实现了同时操作,因此对于不同agent间多mode轨迹交互也可以实现同时处理。
Mutually-Guided Intention Querying of Multiple Agents:提出了 mutually-guided intention querying 模块,来处理不同intention间的交互选择。难点在于对于每个agent来说,intention是围绕他们自己的坐标系,没法直接融合。因此使用了场景编码中query-centric类似的做法:
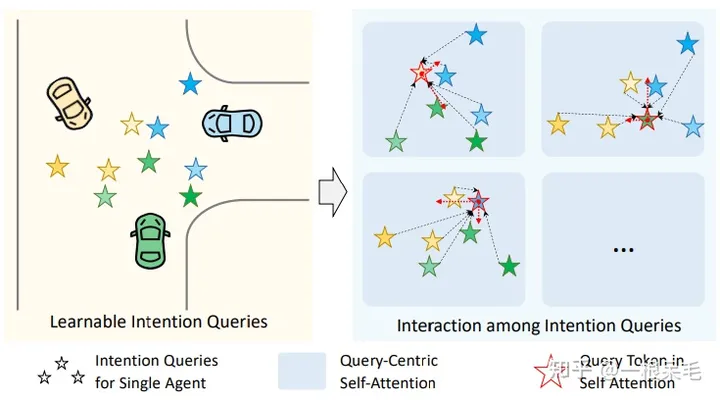


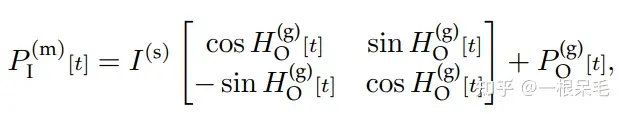

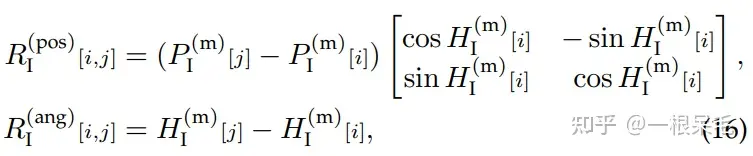
最后就可以进行query-centric self-attention了。这里的F和MTR里一样,一开始初始化为0,随着多个模块获得新的F,E和R分别是mode本身的特征和相对位置关系。F的作用类似于对于mode特征的offset学习。在KV中,j的选取范围为i这个intention的坐标点最近的若干个intention。
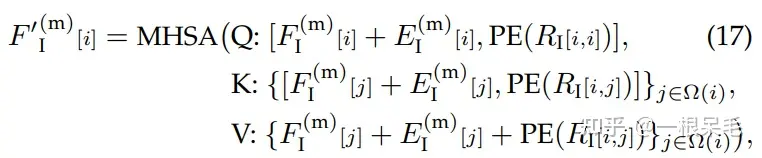

① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!


















 414
414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









