







一、NLP中的encoder和decoder
本质:多个编码器和解码器(编码器结构相同,参数不同)(原文用了6个)
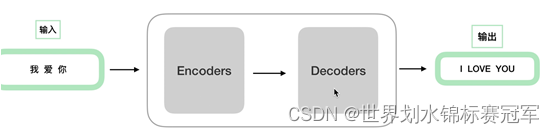
为什么要先编码后解码?
NLP处理的是Sequence2Sequence任务,主要是泛指一些Sequence到Sequence的映射问题。
通常的做法是将输入的源Sequence编码到一个中间的context当中,这个context是一个特定长度的编码(可以理解为一个向量),然后再通过这个context还原成一个输出的目标Sequence。
编码之后不必每次训练都预处理一次数据,可以直接解码读取数据
二、模型框架
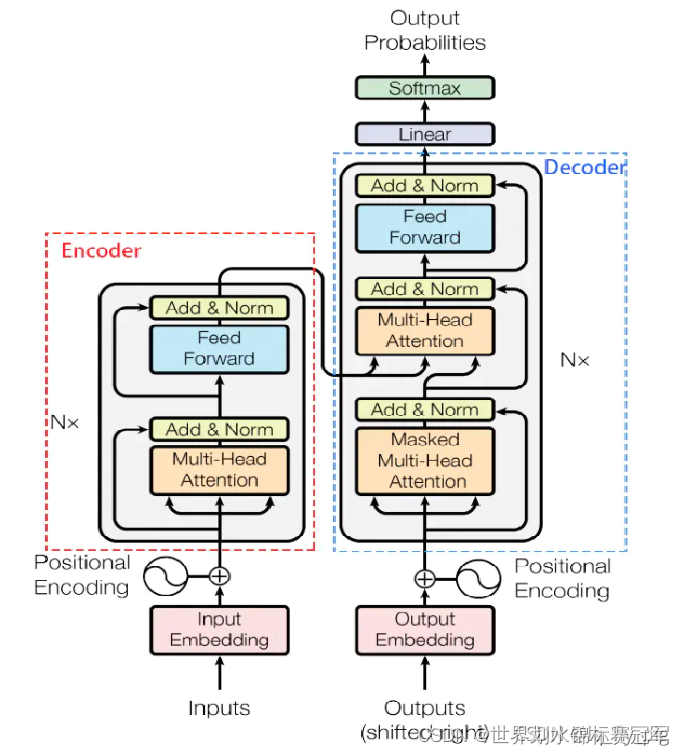
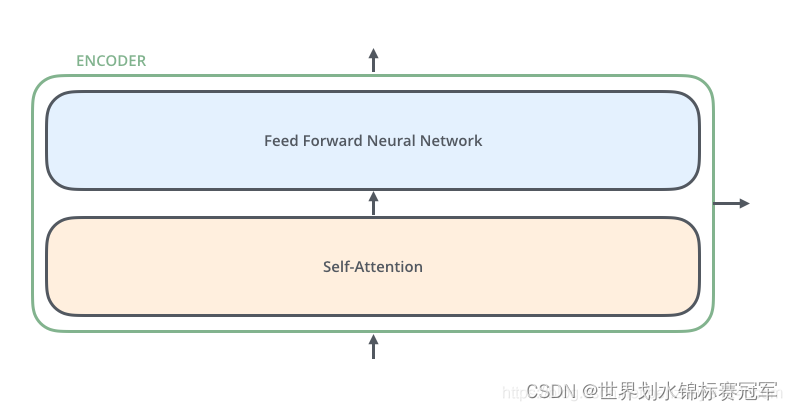
编码器
每个编码器都是由两个子层组成,但是每个编码器的权重不相同
- Self-Attention 层(自注意力层)
作用:让编码器在对特定词进行编码时使用输入句子中的其他词的信息(可以理解为:当我们翻译一个词时,不仅只关注当前的词,而且还会关注其他词的信息) - Position-wise Feed Forward Network(前馈网络,缩写为 FFN)
解码器
比编码器多了注意力层
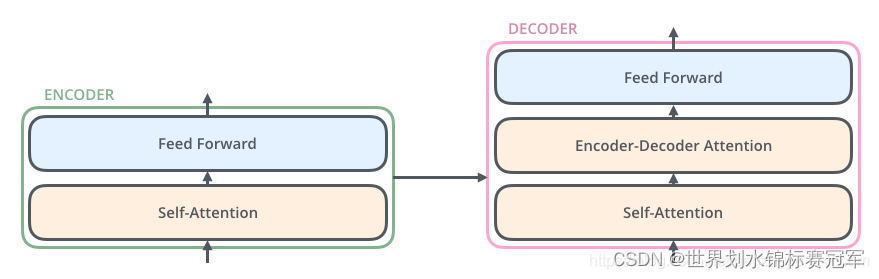
- Self-Attention 层(自注意力层)
- Encoder-Decoder Attention层(注意力层)
- Position-wise Feed Forward Network(前馈网络,缩写为 FFN)
三、数据的表现流动载体—张量/向量
三、自注意力层(Self-Attention)
3.1 为什么要有自注意力机制
举个翻译的例子:
The animal didn’t cross the street because it was too tired
句子中的 it 指的是什么?是指 animal 还是 street ?对人来说,这是一个简单的问题,但是算法来说却不那么简单。
当模型在处理 it 时,Self-Attention 机制使其能够将 it 和 animal 关联起来。
当模型处理每个词(输入序列中的每个位置)时,Self-Attention 机制使得模型不仅能够关注当前位置的词,而且能够关注句子中其他位置的词,从而可以更好地编码这个词。

当我们在编码器 #5(堆栈中的顶部编码器)中对单词”it“进行编码时,有一部分注意力集中在”The animal“上,并将它们的部分信息融入到”it“的编码中。
3.2 Self-Attention 机制
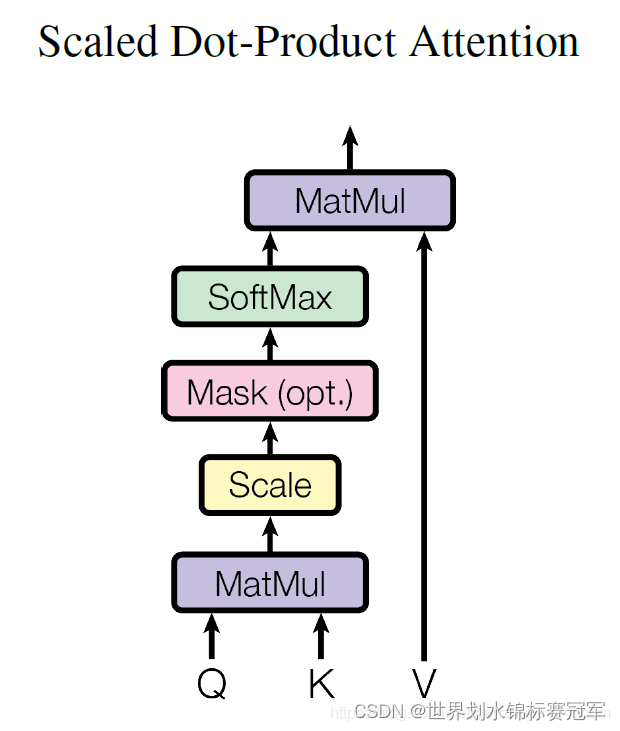
对于 Self Attention 来讲,Q(Query查询),K(Key键)和 V(Value值)三个矩阵均来自同一输入,并按照以下步骤计算:
- 首先计算 Q 和 K 之间的点积,为了防止其结果过大,会除以为 d k \sqrt{d_{k}} dk ,其中 d k d_{k} dk是Key 向量的维度。
- 然后利用 Softmax 操作将其结果归一化为概率分布,再乘以矩阵 V 就得到权重求和的表示
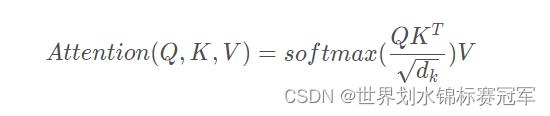
3.3 具体的计算实例
第一步:对编码器的每个输入向量(在本例中,即每个词的词向量)创建三个向量:Query 向量、Key 向量和 Value 向量。
它们是通过词向量X1和X2分别和 3 个矩阵相乘得到的,这 3 个矩阵通过训练获得。分别是 W Q W^{Q} WQ, W
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1048
1048











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









