









赛事地址(持续更新):
https://challenge.xfyun.cn/topic/info?type=telecom-customer&ch=ds22-dw-zs01
1. 赛题介绍
随着市场饱和度的上升,电信运营商的竞争也越来越激烈,电信运营商亟待解决减少用户流失,延长用户生命周期的问题。对于客户流失率而言,每增加5%,利润就可能随之降低25%-85%。因此,如何减少电信用户流失的分析与预测至关重要。
鉴于此,运营商会经常设有客户服务部门,该部门的职能主要是做好客户流失分析,赢回高概率流失的客户,降低客户流失率。某电信机构的客户存在大量流失情况,导致该机构的用户量急速下降。面对如此头疼的问题,该机构将部分客户数据开放,诚邀大家帮助他们建立流失预测模型来预测可能流失的客户。
2. 赛题任务
给定某电信机构实际业务中的相关客户信息,包含69个与客户相关的字段,其中“是否流失”字段表明客户会否会在观察日期后的两个月内流失。任务目标是通过训练集训练模型,来预测客户是否会流失,以此为依据开展工作,提高用户留存。
3.赛题数据
赛题数据由训练集和测试集组成,总数据量超过25w,包含69个特征字段。为了保证比赛的公平性,将会从中抽取15万条作为训练集,3万条作为测试集,同时会对部分字段信息进行脱敏。
- 特征字段
客户ID、地理区域、是否双频、是否翻新机、当前手机价格、手机网络功能、婚姻状况、家庭成人人数、信息库匹配、预计收入、信用卡指示器、当前设备使用天数、在职总月数、家庭中唯一订阅者的数量、家庭活跃用户数、… 、过去六个月的平均每月使用分钟数、过去六个月的平均每月通话次数、过去六个月的平均月费用、是否流失
4.评分标准
赛题使用AUC作为评估指标,即:
from sklearn import metrics
auc = metrics.roc_auc_score(data['default_score_true'], data['default_score_pred'])
5.赛题baseline
防迷糊,提供整体程序框图:
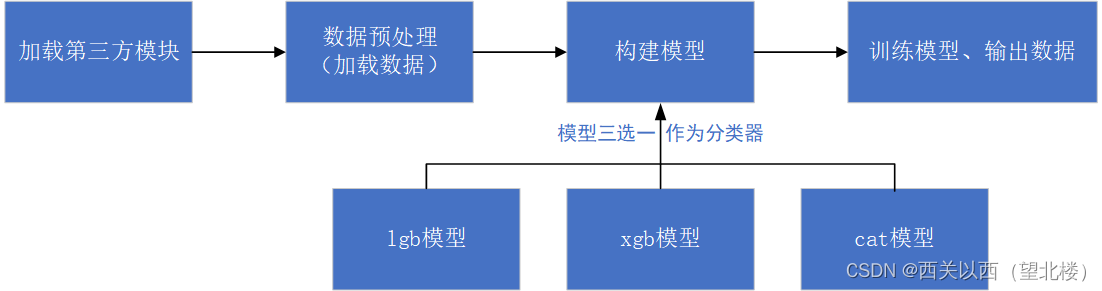
5.1 导入模块
将pandas等模块导入,用于后续对数据的读取、处理,模型的训练、验证,对模型的性能进行评估,以及对测试数据的预测并输出预测结果。
import pandas as pd
import os
import gc
import lightgbm as lgb
import xgboost as xgb
from catboost import CatBoostRegressor
from sklearn.linear_model import SGDRegressor, LinearRegression, Ridge
from sklearn.preprocessing import MinMaxScaler
from gensim.models import Word2Vec
import math
import numpy as np
from tqdm import tqdm
from sklearn.model_selection import StratifiedKFold, KFold
from sklearn.metrics import accuracy_score, f1_score, roc_auc_score, log_loss
import matplotlib.pyplot as plt
import time
import warnings
warnings.filterwarnings('ignore')
5.2 数据预处理
# 从csv文件中读取数据
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
'''
pd.concat(objs, axis=0, ignore_index=False)
# axis: 需要合并链接的轴,0是行,1是列
# objs: series,dataframe或者是panel构成的序列lsit
# ignore_index:如果两个表的index都没有实际含义,使用ignore_index参数,置true,合并的两个表就会根据列字段对齐,然后合并。最后再重新整理一个新的index。
'''
data = pd.concat([train, test], axis=0, ignore_index=True)
len(data)
运行结果展示:

5.3 训练数据/测试数据准备
# 导出特征列名称
features = [f for f in data.columns if f not in ['是否流失','客户ID']]
# 重置索引后,drop参数默认为False,想要删除原先的索引列要置为True.
# 此处训练数据集中 是否流失 是应当不为空(有标签的),而测试集是无标签的,因此此处对数据集进行拆分,分为训练集和测试集并对其索引进行重置。
train = data[data['是否流失'].notnull()].reset_index(drop=True)
test = data[data['是否流失'].isnull()].reset_index(drop=True)
# 分别对测试集、训练集提取特征数据
x_train = train[features]
x_test = test[features]
# 提取训练集是否流失(标签)
y_train = train['是否流失']
5.4 构建模型
'''
搭建训练模型
'''
# clf:为模型库函数,
# train_x:训练数据集特征数据
# train_y:训练数据集标签
# test_x:测试集特征数据
# clf_name:选择不同的模型,对应不同的模型名称
def cv_model(clf, train_x, train_y, test_x, clf_name):
folds = 5 # 代表交叉验证中的折数
seed = 2022 # 随机种子
# 交叉验证函数,这里是5折随机交叉验证
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
# 声明变量 train、test用于存储预测结果
train = np.zeros(train_x.shape[0])
test = np.zeros(test_x.shape[0])
# 声明列表 cv_scores 用于存储每折交验证后结果得分
cv_scores = []
# 此处循环是遍历每折交叉验证
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
print('************************************ {} ************************************'.format(str(i+1)))
# 提取对应的训练集特征数据、验证集特征数据及其对应标签
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]
'''
***************************此处开始是根据模型名称开始判断选择相应模型************************************
'''
if clf_name == "xgb":
# 由于模型需要加载特定数据格式、类型,因此在此处完成数据格式、类型转换
train_matrix = clf.DMatrix(trn_x , label=trn_y)
valid_matrix = clf.DMatrix(val_x , label=val_y)
test_matrix = clf.DMatrix(test_x)
params = {'booster': 'gbtree',
'objective': 'binary:logistic',
'eval_metric': 'auc',
'gamma': 1,
'min_child_weight': 1.5,
'max_depth': 5,
'lambda': 10,
'subsample': 0.7,
'colsample_bytree': 0.7,
'colsample_bylevel': 0.7,
'eta': 0.2,
'tree_method': 'exact',
'seed': 2020,
'nthread': 36,
"silent": True,
}
watchlist = [(train_matrix, 'train'),(valid_matrix, 'eval')]
'''
params: 这是一个字典,里面包含着训练中的参数关键字和对应的值,形式是params = {‘booster’:’gbtree’,’eta’:0.1}
params中参数解释:
objective: 目标函数的选择要根据问题确定,如果是回归问题 ,一般是 reg:linear , reg:logistic , count:poisson 如果是分类问题,一般是binary:logistic ,rank:pairwise
booster:表示应用的弱学习器的类型, 推荐用默认参数可选的有gbtree, dart, gblinear
a: gblinear是线性模型,表现很差,接近一个LASSO
b: dart是树模型的一种,思想是每次训练新树的时候,随机从前m轮的树中扔掉一些,来避免过拟合
gbtree即是论文中主要讨论的树模型,推荐使用
eval_metric:根据objective而定
a: 模型性能度量方法,主要根据objective而定,也可以自定义一些,下面列举一些常见的
b: rmse : root mean square error 也就是平方误差和开根号
c: mae : mean absolute error 误差的绝对值再求平均
d: auc : area under curve roc曲线下面积
e: aucpr: area under the pr curve pr曲线下面积
gamma:叶子节点分裂时所需要的最小的损失减少量,这个值越大,叶子节点越难分裂,所以算法就越保守
min_child_weight:
a: 最小的叶子节点权重
b: 在普通的GBM中,叶子节点样本没有权重的概念,其实就是等权重的,也就相当于叶子节点样本个数
c: 越小越没有限制,容易过拟合,太高容易欠拟合
max_depth:
a: 树的最大深度
b: 这个值对结果的影响算是比较大的了,值越大,树的深度越深,模型的复杂度就越高,就越容易过拟合
c: 注意如果这个值被设置的较大,会吃掉大量的内存
d: 一般来说比价合适的取值区间为[3, 10]
lambda: 损失函数中的L2正则化项的系数,类似RidgeRegression,减轻过拟合
sub_sample:
a: 样本抽样比例
b: 在每次训练的随机选取sub_sample比例的样本来作为训练样本
colsample_by*:
a: 这里实际上有3个参数,借助了随机森林的特征抽样的思想,3个参数可以同时使用
b: colsample_bytree 更常用,每棵树的特征抽样比例
c: colsample_bylevel 每一层深度的树特征抽样比例
d: colsample_bynode 每一个节点的特征抽样比例
eta: 就是常说的学习速率,控制每一次学习的权重缩减,给后来的模型提供更多的学习空间
tree_method:xgboost中使用的树约束算法。xgboost的分布式训练支持 hist 和 approx。
a: auto:使用启发式选择最快的方法。中小数据集:精确的贪心算法;大数据集:近似算法
b: exact:精确的贪心算法
c: approx:近似的贪心算法,使用分位数图和梯度直方图
d: hist:快速直方图优化近似贪心算法,它使用了一些性能改进,比如垃圾缓存
e: gpu_exact: exact 算法的GPU实现
f: gpu_hist:hist 算法的GPU实现
nthread:
a: 训练过程中的并行线程数
b: 如果用的是sklearn的api,那么使用n_jobs来代替
seed: 随机数种子
silent: 不推荐使用,推荐使用verbosity参数来代替,功能更强大
train_matrix: 训练的数据
num_boost_round: 这是指提升迭代的个数
evals: 这是一个列表,用于对训练过程中进行评估列表中的元素。形式是evals = [(dtrain,’train’),(dval,’val’)]或者是evals = [(dtrain,’train’)],对于第一种情况,它使得我们可以在训练过程中观察验证集的效果。
verbose_eval: (可以输入布尔型或数值型),也要求evals 里至少有 一个元素。如果为True ,则对evals中元素的评估结果会输出在结果中;如果输入数字,假设为5,则每隔5个迭代输出一次。
early_stopping_rounds:早期停止次数 ,假设为100,验证集的误差迭代到一定程度在100次内不能再继续降低,就停止迭代。这要求evals 里至少有 一个元素,如果有多个,按最后一个去执行。返回的是最后的迭代次数(不是最好的)。如果early_stopping_rounds 存在,则模型会生成三个属性,bst.best_score,bst.best_iteration,和bst.best_ntree_limit。
'''
# 训练模型
model = clf.train(params, train_matrix, num_boost_round=50000, evals=watchlist, verbose_eval=3000, early_stopping_rounds=200)
# 利用训练好的模型对验证集数据进行预测,验证模型效果
val_pred = model.predict(valid_matrix, ntree_limit=model.best_ntree_limit)
# 利用训练好的模型对测试集数据进行预测
test_pred = model.predict(test_matrix , ntree_limit=model.best_ntree_limit)
if clf_name == "lgb":
# 由于模型需要加载特定数据格式、类型,因此在此处完成数据格式、类型转换
train_matrix = clf.Dataset(trn_x, label=trn_y)
valid_matrix = clf.Dataset(val_x, label=val_y)
# params为模型中指定参数,可参照上方关于xgb模型参数解释自行查询,此处暂时不详细解释
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'min_child_weight': 5,
'num_leaves': 2 ** 5,
'lambda_l2': 10,
'feature_fraction': 0.7,
'bagging_fraction': 0.7,
'bagging_freq': 10,
'learning_rate': 0.2,
'seed': 2022,
'n_jobs':-1
}
# 训练模型,参数部分同上,暂时不做解释。
model = clf.train(params, train_matrix, 50000, valid_sets=[train_matrix, valid_matrix],
categorical_feature=[], verbose_eval=3000, early_stopping_rounds=200)
# 利用训练好的模型对验证集数据进行预测,验证模型效果
val_pred = model.predict(val_x, num_iteration=model.best_iteration)
# 利用训练好的模型对测试集数据进行预测
test_pred = model.predict(test_x, num_iteration=model.best_iteration)
# 输出平均增益排名前20的特征及其收益
# gain: 该特征在它所有分裂使用中带来的平均增益
print(list(sorted(zip(features, model.feature_importance("gain")), key=lambda x: x[1], reverse=True))[:20])
if clf_name == "cat":
# params为模型中指定参数,可参照上方关于xgb模型参数解释自行查询,此处暂时不详细解释
params = {'learning_rate': 0.2, 'depth': 5, 'l2_leaf_reg': 10, 'bootstrap_type': 'Bernoulli',
'od_type': 'Iter', 'od_wait': 50, 'random_seed': 11, 'allow_writing_files': False}
# 训练模型,参数部分同上,暂时不做解释。
model = clf(iterations=20000, **params)
model.fit(trn_x, trn_y, eval_set=(val_x, val_y),
cat_features=[], use_best_model=True, verbose=3000)
# 利用训练好的模型对验证集数据进行预测,验证模型效果
val_pred = model.predict(val_x)
# 利用训练好的模型对测试集数据进行预测
test_pred = model.predict(test_x)
train[valid_index] = val_pred
test += test_pred / kf.n_splits
cv_scores.append(roc_auc_score(val_y, val_pred))
print(cv_scores)
# 输出K折交叉验证结果
print("%s_scotrainre_list:" % clf_name, cv_scores)
# 输出K折交叉验证结果的均值
print("%s_score_mean:" % clf_name, np.mean(cv_scores))
# 输出K折交叉验证结果标准差
print("%s_score_std:" % clf_name, np.std(cv_scores))
return train, test
# 定义lgb模型,进行调用
def lgb_model(x_train, y_train, x_test):
lgb_train, lgb_test = cv_model(lgb, x_train, y_train, x_test, "lgb")
return lgb_train, lgb_test
# 定义xgb模型,进行调用
def xgb_model(x_train, y_train, x_test):
xgb_train, xgb_test = cv_model(xgb, x_train, y_train, x_test, "xgb")
return xgb_train, xgb_test
# 定义cat模型,进行调用
def cat_model(x_train, y_train, x_test):
cat_train, cat_test = cv_model(CatBoostRegressor, x_train, y_train, x_test, "cat")
return cat_train, cat_test
lgb_train, lgb_test = lgb_model(x_train, y_train, x_test)
5.5 提交结果
test['是否流失'] = lgb_test
# 保存测试集预测结果至test_sub.csv文件中
test[['客户ID','是否流失']].to_csv('test_sub.csv', index=False)
心得: baseline仅供赛事参考,整体完成baseline的理解真的心累。通过完成对baseline提供程序的注解,我个人对数据处理的相关流程有了更加清晰的认识。个人理解还有很多可以改进的地方,比如模型的参数调整,选择合适的特征、分类模型。个人关于AUC的理解仍然需要补充,在接下来的时间将针对此部分内容进行补课。
注: 此博客内容版权归博主与Datawhale、科大讯飞相关赛事承办方所有,如需转载请联系!
QQ:1755826272















 391
391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









