









扩散模型系列:
(1)扩散模型(一)——DDPM推导笔记-大白话推导
(2)扩散模型(二)——DDIM学习笔记-大白话推导
各位佬看文章之前,可以先去看看这个视频,并给这位up主点赞投币,这位佬讲解的太好了:大白话AI
1.前置知识的学习
1.1 正态分布特性
(1)正态分布的概率密度函数
f
(
x
)
=
1
2
π
σ
e
−
(
x
−
μ
)
2
2
σ
2
,
记为
N
(
μ
,
σ
2
)
f(x) = {1 \over \sqrt{2 \pi } \sigma} e^{-{{(x-\mu)^2} \over {2 \sigma^2}}} ,记为N(\mu, \sigma^2)
f(x)=2πσ1e−2σ2(x−μ)2,记为N(μ,σ2)
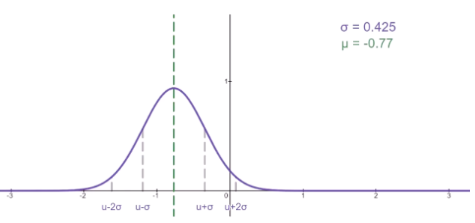
当 μ = 0 , σ 2 = 1 \mu = 0, \sigma^2=1 μ=0,σ2=1时,则记为标准正态分布,记为 N ( 0 , 1 ) N(0, 1) N(0,1), 又称为高斯分布。
(2)正态分布的基本性质
N
(
μ
1
,
σ
1
2
)
+
N
(
μ
2
,
σ
2
2
)
=
N
(
μ
1
+
μ
2
,
σ
1
2
+
σ
2
2
)
a
∗
N
(
μ
,
σ
)
=
N
(
a
∗
μ
,
(
a
∗
σ
)
2
)
N(\mu_1, \sigma_1^2) + N(\mu_2, \sigma_2^2) = N(\mu_1+\mu2, \sigma_1^2+\sigma_2^2) \\ a*N(\mu, \sigma) = N(a*\mu, (a*\sigma)^2)
N(μ1,σ12)+N(μ2,σ22)=N(μ1+μ2,σ12+σ22)a∗N(μ,σ)=N(a∗μ,(a∗σ)2)
1.2 贝叶斯定理
A
,
B
A, B
A,B是两个随机事件,
P
(
A
)
P(A)
P(A)表示
事件
A
事件A
事件A发生的概率,
P
(
B
∣
A
)
P(B|A)
P(B∣A)表示A事件发生的情况下B事件发生的概率,则贝叶斯定理如下:
P
(
A
∣
B
)
=
P
(
B
∣
A
)
∗
P
(
A
)
P
(
B
)
P(A|B) = {{P(B|A) * P(A)} \over P(B)}
P(A∣B)=P(B)P(B∣A)∗P(A)
2. 前向过程(加噪)

如图所示,前向过程则是一个加载过程,在每个时间步,都从正态分布中随机采样一个和图片等大的噪声(也可以理解为噪声图片),则加噪过程:
x
1
=
β
1
∗
ϵ
1
+
1
−
β
1
∗
x
0
x_1 = \sqrt{\beta_1} * \epsilon_1 + \sqrt{1-\beta_1} * x_0
x1=β1∗ϵ1+1−β1∗x0
其中
x
0
x_0
x0表示原始图片,
ϵ
1
\epsilon_1
ϵ1 表示随机噪声,
β
1
\beta_1
β1表示扩散速度,
T
T
T表示扩散的次数,则可以一次推导:
x
1
=
β
1
∗
ϵ
1
+
1
−
β
1
∗
x
0
x
2
=
β
2
∗
ϵ
2
+
1
−
β
2
∗
x
1
x
3
=
β
3
∗
ϵ
3
+
1
−
β
3
∗
x
2
⋅
⋅
⋅
⋅
⋅
⋅
x
T
=
β
T
∗
ϵ
T
+
1
−
β
T
∗
x
T
−
1
前后关系就可以记为:
x
t
=
β
t
∗
ϵ
t
+
1
−
β
t
∗
x
t
−
1
x_1 = \sqrt{\beta_1} * \epsilon_1 + \sqrt{1-\beta_1} * x_0 \\ x_2 = \sqrt{\beta_2} * \epsilon_2 + \sqrt{1-\beta_2} * x_1 \\ x_3 = \sqrt{\beta_3} * \epsilon_3 + \sqrt{1-\beta_3} * x_2 \\ ······ \\ x_T = \sqrt{\beta_T} * \epsilon_T + \sqrt{1-\beta_T} * x_{T-1} \\ 前后关系就可以记为: \\ x_t = \sqrt{\beta_t} * \epsilon_t + \sqrt{1-\beta_t} * x_{t-1} \\
x1=β1∗ϵ1+1−β1∗x0x2=β2∗ϵ2+1−β2∗x1x3=β3∗ϵ3+1−β3∗x2⋅⋅⋅⋅⋅⋅xT=βT∗ϵT+1−βT∗xT−1前后关系就可以记为:xt=βt∗ϵt+1−βt∗xt−1
β
0
\beta_0
β0接近0,
β
T
\beta_T
βT接近1,原因是越到最后扩散速度越快, 而且是自己事先就要定义好的常数,为简化后续运算,令
α
t
=
1
−
β
t
\alpha_t = 1 - \beta_t
αt=1−βt, 则有:
x
t
=
1
−
α
t
∗
ϵ
t
+
α
t
∗
x
t
−
1
x_t = \sqrt{1- \alpha_t} * \epsilon_t + \sqrt{\alpha_t} * x_{t-1}
xt=1−αt∗ϵt+αt∗xt−1
思考:如何能更快的得到
x
T
x_T
xT?因为如果加噪1000步,岂不是要计算1000次上述的运算!好的,下面介绍怎样依赖正态分布的可加性来简化运算,从而推导出
x
0
x_0
x0到
x
t
x_t
xt的关系:
由:
x
t
=
1
−
α
t
∗
ϵ
t
+
α
t
∗
x
t
−
1
x
t
−
1
=
1
−
α
t
−
1
∗
ϵ
t
−
1
+
α
t
−
1
∗
x
t
−
2
把
x
t
−
1
代入到
x
t
中可以推导出:
x
t
=
1
−
α
t
∗
ϵ
t
+
α
t
∗
(
1
−
α
t
−
1
∗
ϵ
t
−
1
+
α
t
−
1
∗
x
t
−
2
)
=
a
t
(
1
−
a
t
−
1
)
∗
ϵ
t
−
1
+
1
−
a
t
∗
ϵ
t
+
a
t
a
t
−
1
∗
x
t
−
2
其中:
ϵ
t
−
1
和
ϵ
t
是两个随机噪声,且两者是两个独立的随机变量。
打个比喻:我们有一个骰子掷两次分别得到
ϵ
t
−
1
和
ϵ
t
,完全可以等效
于我们有两个骰子掷一次。即:一个骰子掷两次的概率分布等同于两个骰子掷一次的概率分布,所以
,
如果我们知道两个骰子掷一次的概率分布,然后进行一次采样即可。
由: \\ x_t = \sqrt{1- \alpha_t} * \epsilon_t + \sqrt{\alpha_t} * x_{t-1} \\ x_{t-1} = \sqrt{1- \alpha_{t-1}} * \epsilon_{t-1} + \sqrt{\alpha_{t-1}} * x_{t-2} \\ 把x_{t-1}代入到x_t中可以推导出: \\ x_t = \sqrt{1- \alpha_t} * \epsilon_t + \sqrt{\alpha_t} * (\sqrt{1- \alpha_{t-1}} * \epsilon_{t-1} + \sqrt{\alpha_{t-1}} * x_{t-2}) \\ = \sqrt{a_t(1-a_{t-1})} * \epsilon_{t-1} + \sqrt{1-a_t} * \epsilon_t + \sqrt{a_t a_{t-1}} * x_{t-2} \\ 其中:\epsilon_{t-1} 和 \epsilon_{t} 是两个随机噪声,且两者是两个独立的随机变量。\\ 打个比喻:我们有一个骰子掷两次分别得到\epsilon_{t-1} 和 \epsilon_{t},完全可以等效\\ 于我们有两个骰子掷一次。即:一个骰子掷两次的概率分布等同于两个骰子掷一次的概率分布,所以,\\ 如果我们知道两个骰子掷一次的概率分布,然后进行一次采样即可。 \\
由:xt=1−αt∗ϵt+αt∗xt−1xt−1=1−αt−1∗ϵt−1+αt−1∗xt−2把xt−1代入到xt中可以推导出:xt=1−αt∗ϵt+αt∗(1−αt−1∗ϵt−1+αt−1∗xt−2)=at(1−at−1)∗ϵt−1+1−at∗ϵt+atat−1∗xt−2其中:ϵt−1和ϵt是两个随机噪声,且两者是两个独立的随机变量。打个比喻:我们有一个骰子掷两次分别得到ϵt−1和ϵt,完全可以等效于我们有两个骰子掷一次。即:一个骰子掷两次的概率分布等同于两个骰子掷一次的概率分布,所以,如果我们知道两个骰子掷一次的概率分布,然后进行一次采样即可。
由正态分布的基本性质可知: ϵ t 和 ϵ t − 1 服从 N ( 0 , 1 ) , 即: ϵ t ∼ N ( 0 , 1 ) , ϵ t − 1 ∼ N ( 0 , 1 ) 可以推导出: 1 − a t ∗ ϵ t ∼ N ( 0 , 1 − α t ) a t ( 1 − a t − 1 ) ∗ ϵ t − 1 ∼ N ( 0 , a t − a t ∗ a t − 1 ) ) 由正态分布的基本性质可知:\\ \epsilon_t和\epsilon_{t-1}服从N(0, 1),即:\epsilon_t \sim N(0,1), \epsilon_{t-1} \sim N(0,1) \\ 可以推导出: \sqrt{1-a_t} * \epsilon_t \sim N(0, 1- \alpha_t) \\ \sqrt{a_t(1-a_{t-1})} * \epsilon_{t-1} \sim N(0, a_t-a_t*a_{t-1})) 由正态分布的基本性质可知:ϵt和ϵt−1服从N(0,1),即:ϵt∼N(0,1),ϵt−1∼N(0,1)可以推导出:1−at∗ϵt∼N(0,1−αt)at(1−at−1)∗ϵt−1∼N(0,at−at∗at−1))
从而推导出: a t ( 1 − a t − 1 ) ∗ ϵ t − 1 + 1 − a t ∗ ϵ t ∼ N ( 0 , 1 − a t ∗ a t − 1 ) 从而推导出: \\ \sqrt{a_t(1-a_{t-1})} * \epsilon_{t-1} + \sqrt{1-a_t} * \epsilon_t \sim N(0, 1-a_t*a_{t-1}) 从而推导出:at(1−at−1)∗ϵt−1+1−at∗ϵt∼N(0,1−at∗at−1)
进而推导出: x t = 1 − a t ∗ a t − 1 ∗ ϵ + a t ∗ a t − 1 ∗ x t − 2 , 其中: ϵ ∼ N ( 0 , 1 − a t ∗ a t − 1 ) 进而推导出:\\ x_t = \sqrt{1-a_t*a_{t-1}} * \epsilon + \sqrt{a_t*a_{t-1}}*x_{t-2}, 其中:\epsilon \sim N(0, 1-a_t*a_{t-1}) 进而推导出:xt=1−at∗at−1∗ϵ+at∗at−1∗xt−2,其中:ϵ∼N(0,1−at∗at−1)
这里就可到了 x t 和 x t − 2 之间的关系,然后依靠上面的方法就可以一次推导出 x t 到 x 0 的关系 ( 数学归纳法证明 ) ,具体如下: x t = 1 − a t a t − 1 a t − 2 . . . a 1 ∗ ϵ + a t a t − 1 a t − 2 . . . a 1 ∗ x 0 其中, ϵ ∼ N ( 0 , 1 − a t a t − 1 a t − 2 . . . a 1 ) 这里就可到了x_t和x_{t-2}之间的关系,然后依靠上面的方法就可以一次推导出x_t到x_0的关系(数学归纳法证明),具体如下: \\ x_t = \sqrt{1 - a_ta_{t-1}a_{t-2}...a_1} * \epsilon + \sqrt{a_ta_{t-1}a_{t-2}...a_1} * x_0 \\ 其中,\epsilon \sim N(0, 1 - a_ta_{t-1}a_{t-2}...a_1) 这里就可到了xt和xt−2之间的关系,然后依靠上面的方法就可以一次推导出xt到x0的关系(数学归纳法证明),具体如下:xt=1−atat−1at−2...a1∗ϵ+atat−1at−2...a1∗x0其中,ϵ∼N(0,1−atat−1at−2...a1)
为了方便表示 , 记: a ˉ t = a t a t − 1 a t − 2 . . . a 1 则: x t = 1 − a ˉ t ∗ ϵ + a ˉ t x 0 为了方便表示,记: \bar{a}_t = a_ta_{t-1}a_{t-2}...a_1 \\ 则: x_t = \sqrt{1 - \bar{a}_t} * \epsilon + \sqrt{\bar{a}_t} x_0 为了方便表示,记:aˉt=atat−1at−2...a1则:xt=1−aˉt∗ϵ+aˉtx0
至此,前向过程就记录完成了,我们得到 x 0 到 x t x_0到x_t x0到xt的关系,并且可以只通过一次采样就能得到。
3. 反向过程(去噪)
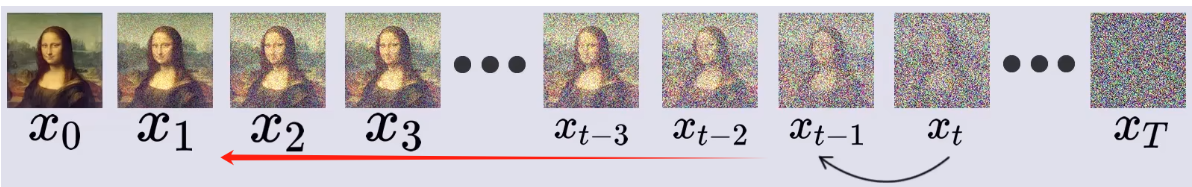
去噪过程就是从
x
T
x_T
xT一步步反推回
x
0
x_0
x0。
3.1 反向原理推导
由贝叶斯定理:
P
(
A
∣
B
)
=
P
(
B
∣
A
)
∗
P
(
A
)
P
(
B
)
P(A|B) = {{P(B|A) * P(A)} \over P(B)}
P(A∣B)=P(B)P(B∣A)∗P(A)
我们可以令:
由于
x
t
到
x
t
−
1
是一个随机过程,则令:
P
(
x
t
−
1
∣
x
t
)
:
表示在给定
x
t
的情况下,
x
t
−
1
的概率。
套用贝叶斯定理得:
P
(
x
t
−
1
∣
x
t
)
=
P
(
x
t
∣
x
t
−
1
)
∗
P
(
x
t
−
1
)
P
(
x
t
)
其中,
P
(
x
t
)
和
P
(
x
t
−
1
)
分别表示
x
t
和
t
t
−
1
的概率
,
也就是从
x
0
原图得到它们的概率。
由于x_t到x_{t-1}是一个随机过程,则令: \\ P(x_{t-1}|x_t): 表示在给定x_t的情况下,x_{t-1}的概率。 \\ 套用贝叶斯定理得: \\ P(x_{t-1} | x_t) = { P(x_t | x_{t-1}) * P(x_{t-1}) \over P(x_t)} \\ 其中,P(x_t)和P(x_{t-1})分别表示x_t和t_{t-1}的概率,也就是从x_0原图得到它们的概率。
由于xt到xt−1是一个随机过程,则令:P(xt−1∣xt):表示在给定xt的情况下,xt−1的概率。套用贝叶斯定理得:P(xt−1∣xt)=P(xt)P(xt∣xt−1)∗P(xt−1)其中,P(xt)和P(xt−1)分别表示xt和tt−1的概率,也就是从x0原图得到它们的概率。
所以,可以在每个式子后面添加一个先验
x
0
,
即:
P
(
x
t
−
1
∣
x
t
,
x
0
)
=
P
(
x
t
∣
x
t
−
1
,
x
0
)
∗
P
(
x
t
−
1
∣
x
0
)
P
(
x
t
∣
x
0
)
所以,可以在每个式子后面添加一个先验x0,即: \\ P(x_{t-1} | x_t,x_0) = { P(x_t | x_{t-1},x_0) * P(x_{t-1} | x_0) \over P(x_t | x_0)} \\
所以,可以在每个式子后面添加一个先验x0,即:P(xt−1∣xt,x0)=P(xt∣x0)P(xt∣xt−1,x0)∗P(xt−1∣x0)
有:
P
(
x
t
∣
x
t
−
1
,
x
0
)
给定
x
t
−
1
到
x
t
的概率。
前向过程中可知:
x
t
=
1
−
α
t
∗
ϵ
t
+
α
t
∗
x
t
−
1
x
t
=
1
−
a
ˉ
t
∗
ϵ
+
a
ˉ
t
x
0
ϵ
t
和
ϵ
分别服从
N
(
0
,
1
)
从而推导出:
x
t
∼
N
(
a
t
x
t
−
1
,
1
−
a
t
)
或:
x
t
∼
N
(
a
ˉ
t
x
0
,
1
−
a
ˉ
t
)
以及:
x
t
−
1
∼
N
(
a
ˉ
t
−
1
x
0
,
1
−
a
ˉ
t
−
1
)
有: \\ P(x_t|x_{t-1}, x_0) 给定x_{t-1}到x_t的概率。 \\ 前向过程中可知: \\ x_t = \sqrt{1- \alpha_t} * \epsilon_t + \sqrt{\alpha_t} * x_{t-1} \\ x_t = \sqrt{1 - \bar{a}_t} * \epsilon + \sqrt{\bar{a}_t} x_0 \\ \epsilon_t和\epsilon分别服从N(0, 1) \\ 从而推导出: \\ x_t \sim N(\sqrt{a_t} x_{t-1}, 1-a_t) \\ 或: \\ x_t \sim N(\sqrt{\bar{a}_t} x_0, 1-\bar{a}_t) \\ 以及: \\ x_{t-1} \sim N(\sqrt{\bar{a}_{t-1}} x_0, 1-\bar{a}_{t-1}) \\
有:P(xt∣xt−1,x0)给定xt−1到xt的概率。前向过程中可知:xt=1−αt∗ϵt+αt∗xt−1xt=1−aˉt∗ϵ+aˉtx0ϵt和ϵ分别服从N(0,1)从而推导出:xt∼N(atxt−1,1−at)或:xt∼N(aˉtx0,1−aˉt)以及:xt−1∼N(aˉt−1x0,1−aˉt−1)
然后就可以把他们分别写成概率密度形式:

然后将概率密度函数带入到贝叶斯定理中,就可以得到:

化简成高斯分布得:
P ( x t − 1 ∣ x t , x 0 ) P(x_{t-1}|x_t, x_0) P(xt−1∣xt,x0) =

由此推导出:
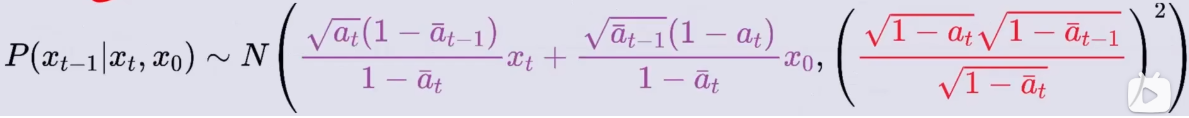
我们的目的是通过
x
t
求出
x
t
−
1
,
然后由
x
t
−
1
推导出
x
t
−
2
⋅
⋅
⋅
直到求出
x
0
,
但现在的式子中出现了
x
0
,
怎么办?
没关系,我们之前由
x
t
和
x
0
的关系:
x
t
=
1
−
a
ˉ
t
∗
ϵ
+
a
ˉ
t
x
0
我们的目的是通过x_t求出x_{t-1},然后由x_{t-1}推导出x_{t-2}···直到求出x_0,\\ 但现在的式子中出现了x_0,怎么办? \\ 没关系,我们之前由x_t和x_0的关系: \\ x_t = \sqrt{1 - \bar{a}_t} * \epsilon + \sqrt{\bar{a}_t} x_0 \\
我们的目的是通过xt求出xt−1,然后由xt−1推导出xt−2⋅⋅⋅直到求出x0,但现在的式子中出现了x0,怎么办?没关系,我们之前由xt和x0的关系:xt=1−aˉt∗ϵ+aˉtx0
变换可以得到:

将它带入到
P
(
x
t
−
1
∣
x
t
,
x
0
)
P(x_{t-1}|x_t, x_0)
P(xt−1∣xt,x0)的概率密度函数中可得:
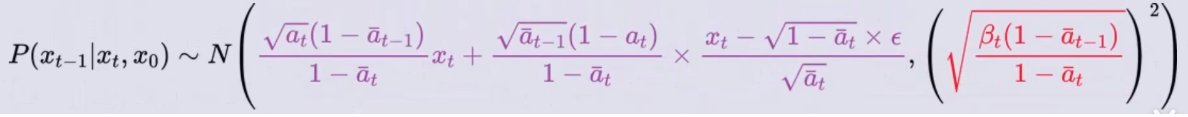
它表示的是:对于任意
x
t
x_t
xt的图像都可以用
x
0
x_0
x0加载而来;而只要知道了从
x
0
x_0
x0到
x
t
x_t
xt加入的噪声
ϵ
\epsilon
ϵ,就能得到它前一时刻
x
t
−
1
x_{t-1}
xt−1的概率分布,即:
P
(
x
t
−
1
∣
x
t
,
x
0
)
P(x_{t-1}|x_t, x_0)
P(xt−1∣xt,x0) 。
其中,可以通过数学变换将
P
(
x
t
−
1
∣
x
t
,
x
0
)
P(x_{t-1}|x_t, x_0)
P(xt−1∣xt,x0)中的均值部分(即
μ
\mu
μ)变换成如下形式,更利于代码实现:

这样
P
(
x
t
−
1
∣
x
t
,
x
0
)
P(x_{t-1}|x_t, x_0)
P(xt−1∣xt,x0)服从概率分布如下:
P
(
x
t
−
1
∣
x
t
,
x
0
)
∼
N
(
1
a
t
(
x
t
−
1
−
a
t
1
−
a
ˉ
t
ϵ
)
,
(
β
t
(
1
−
a
ˉ
t
−
1
)
1
−
a
ˉ
t
)
2
)
P(x_{t-1}|x_t, x_0) \sim N({1 \over \sqrt{a_t}} (x_t - {{1-a_t} \over \sqrt{1-\bar{a}_t}} \epsilon), (\sqrt{{\beta_t (1-\bar{a}_{t-1}) \over {1- \bar{a}_t}}})^2)
P(xt−1∣xt,x0)∼N(at1(xt−1−aˉt1−atϵ),(1−aˉtβt(1−aˉt−1))2)
这里我们就需要使用神经网络,输入
x
t
x_t
xt时刻的图像,预测此图像相对于某个
x
0
x_0
x0原图加入的噪声
ϵ
\epsilon
ϵ。
如图所示,也就是说:
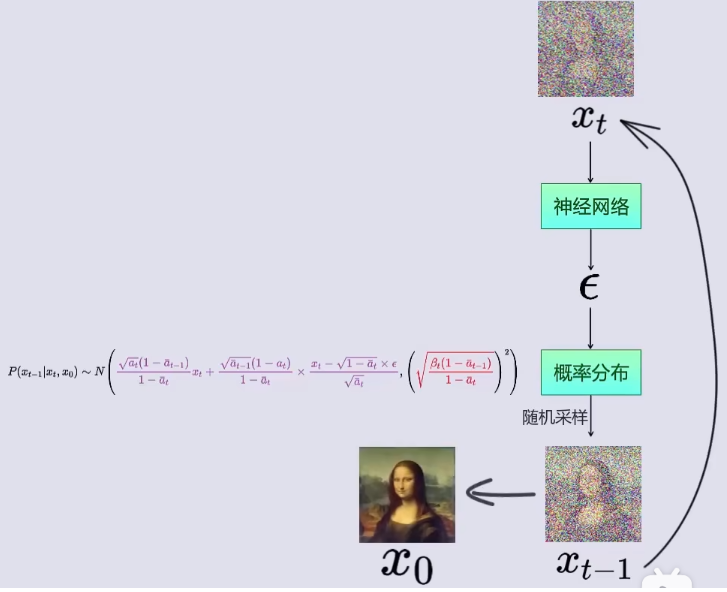
Step1: 在神经网络中,输入
x
t
x_t
xt时刻图像,训练得到此图像相对于某个
x
0
x_0
x0原图加入的噪声
ϵ
\epsilon
ϵ。
Step2: 将噪声 ϵ \epsilon ϵ带入到 x t − 1 x_{t-1} xt−1的概率密度函数 P ( x t − 1 ∣ x t , x 0 ) P(x_{t-1}|x_t, x_0) P(xt−1∣xt,x0)中;
Step3: 从 x t − 1 x_{t-1} xt−1的概率密度函数 P ( x t − 1 ∣ x t , x 0 ) P(x_{t-1}|x_t, x_0) P(xt−1∣xt,x0)中随机采样,得到 x t − 1 x_{t-1} xt−1(即t-1时刻对应的图像);
Step4: 将 x t − 1 x_{t-1} xt−1作为神经网络的输入,带入到Step1中,循环Step1 ~ Step3,直到得到 x 0 x_0 x0
DDPM中的神经网络选用的UNet.
3.2 疑难点注解
(1)在反向传播的过程中,训练的 ϵ \epsilon ϵ是个固定的值,还是根据 t t t的变化而变化的值?
是个固定的值!
理由:在推导反向传播时,为了去掉
x
0
x_0
x0而引入了
x
t
与
x
0
x_t与x_0
xt与x0的关系,
x
t
=
1
−
a
ˉ
t
∗
ϵ
+
a
ˉ
t
x
0
其中,
ϵ
∼
N
(
0
,
1
−
a
t
a
t
−
1
a
t
−
2
.
.
.
a
1
)
x_t = \sqrt{1 - \bar{a}_t} * \epsilon + \sqrt{\bar{a}_t} x_0 \\ 其中,\epsilon \sim N(0, 1 - a_ta_{t-1}a_{t-2}...a_1)
xt=1−aˉt∗ϵ+aˉtx0其中,ϵ∼N(0,1−atat−1at−2...a1)

而 x t = 1 − a ˉ t ∗ ϵ + a ˉ t x 0 x_t = \sqrt{1 - \bar{a}_t} * \epsilon + \sqrt{\bar{a}_t} x_0 xt=1−aˉt∗ϵ+aˉtx0中的 ϵ \epsilon ϵ在前向传播中已经确定好了,所以神经网络训练的 ϵ \epsilon ϵ就是要去接近它。因为在训练过程中的损失函数就是使用的MES_Loss使两个 ϵ \epsilon ϵ尽可能一致。
(2)很多代码中 x t = 1 − a ˉ t ∗ ϵ + a ˉ t x 0 x_t = \sqrt{1 - \bar{a}_t} * \epsilon + \sqrt{\bar{a}_t} x_0 xt=1−aˉt∗ϵ+aˉtx0的 ϵ \epsilon ϵ并不是从 ϵ ∼ N ( 0 , 1 − a t a t − 1 a t − 2 . . . a 1 ) \epsilon \sim N(0, 1 - a_ta_{t-1}a_{t-2}...a_1) ϵ∼N(0,1−atat−1at−2...a1)采样的,而是直接从 N ( 0 , 1 ) N(0,1) N(0,1)中采样的,这是为什么?
理由:因为 a t a t − 1 a t − 2 . . . a 1 a_ta_{t-1}a_{t-2}...a_1 atat−1at−2...a1非常趋近于0, 所以 1 − a t a t − 1 a t − 2 . . . a 1 1-a_ta_{t-1}a_{t-2}...a_1 1−atat−1at−2...a1非常趋近于1。故直接从 N ( 0 , 1 ) N(0,1) N(0,1)中采样。
(3)训练过程中的Step3: 从 x t − 1 x_{t-1} xt−1的概率密度函数 P ( x t − 1 ∣ x t , x 0 ) P(x_{t-1}|x_t, x_0) P(xt−1∣xt,x0)中随机采样,得到 x t − 1 x_{t-1} xt−1(即t-1时刻对应的图像),其中的采样是怎么完成的?
千万不要被什么"采样"、"概率分布"等字眼吓到,其实非常简单!从代码的角度解释就是:
1)我们已知:
P
(
x
t
−
1
∣
x
t
,
x
0
)
∼
N
(
1
a
t
(
x
t
−
1
−
a
t
1
−
a
ˉ
t
ϵ
)
,
(
β
t
(
1
−
a
ˉ
t
−
1
)
1
−
a
ˉ
t
)
2
)
P(x_{t-1}|x_t, x_0) \sim N({1 \over \sqrt{a_t}} (x_t - {{1-a_t} \over \sqrt{1-\bar{a}_t}} \epsilon), (\sqrt{{\beta_t (1-\bar{a}_{t-1}) \over {1- \bar{a}_t}}})^2)
P(xt−1∣xt,x0)∼N(at1(xt−1−aˉt1−atϵ),(1−aˉtβt(1−aˉt−1))2)
其中我们输入的是
x
t
x_t
xt, 而式子中的
ϵ
\epsilon
ϵ是神经网络需要预测的,其中的
a
t
、
a
ˉ
t
、
β
t
a_t、 \bar{a}_t、 \beta_t
at、aˉt、βt都是事先定义好的。
2)从概率分布中采样
我们现在有了 x t , ϵ x_t, \epsilon xt,ϵ和概率分布,怎样得到 x t − 1 x_{t-1} xt−1呢?很简单:
Step1: 从 N ( 0 , 1 ) N(0,1) N(0,1)中随机采样一个噪声,代码如下:
noise = torch.randn_like(x_t) # randn_like(x_t)表示从标准正态分布中采样一个和x_t同维度的noise
Step2: 获取概率中的方差var
v
a
r
=
β
t
(
1
−
a
ˉ
t
−
1
)
1
−
a
ˉ
t
var = { \beta_t (1-\bar{a}_{t-1}) \over {1- \bar{a}_t} }
var=1−aˉtβt(1−aˉt−1)
里面的参数都是已知的。
Step3: 获取概率分布中的均值mean
1
a
t
(
x
t
−
1
−
a
t
1
−
a
ˉ
t
ϵ
)
{1 \over \sqrt{a_t}} (x_t - {{1-a_t} \over \sqrt{1-\bar{a}_t}} \epsilon)
at1(xt−1−aˉt1−atϵ)
里面的
x
t
x_t
xt是输入,
ϵ
\epsilon
ϵ是神经网络预测的,其他的都是已知的。
Step4: 从概率分布中采样
很简单的,就是
x
t
−
1
=
x_{t-1}=
xt−1=mean + noise * sqrt(var)即可,这样就表示从:
P
(
x
t
−
1
∣
x
t
,
x
0
)
∼
N
(
1
a
t
(
x
t
−
1
−
a
t
1
−
a
ˉ
t
ϵ
)
,
(
β
t
(
1
−
a
ˉ
t
−
1
)
1
−
a
ˉ
t
)
2
)
P(x_{t-1}|x_t, x_0) \sim N({1 \over \sqrt{a_t}} (x_t - {{1-a_t} \over \sqrt{1-\bar{a}_t}} \epsilon), (\sqrt{{\beta_t (1-\bar{a}_{t-1}) \over {1- \bar{a}_t}}})^2)
P(xt−1∣xt,x0)∼N(at1(xt−1−aˉt1−atϵ),(1−aˉtβt(1−aˉt−1))2)
进行采样,即得到了
x
t
−
1
x_{t-1}
xt−1, 然后把
x
t
−
1
x_{t-1}
xt−1带入到神经网络,重新预测
ϵ
\epsilon
ϵ,重复上述步骤,就可以得到
x
t
−
2
x_{t-2}
xt−2,一直持续,就可以得到
x
0
x_0
x0。
(4)前向加噪是不是只需要一步即可,而反向去噪则需要T步?
对!
理由:前向加噪过程本来是需要T步的,但通过正态分布的性质,让我们一次采样就可以得到和T次采样一样的效果,所以只需要一次即可!
而反向传播中,则需要T步,即:若T=1000,则需要进行1000次预测。因为反向传播依赖马尔科夫链,需要已知 x t x_{t} xt才能得到 x t − 1 x_{t-1} xt−1,只能这样一次次推导才能得出 x 0 x_0 x0。这也是DDPM很大的一个缺点,推理太慢!后面才有DDIM的改进。
至此,本文结束!
















 2750
2750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









