






摘要
去噪扩散模型代表了计算机视觉领域的一个新兴主题,在生成建模领域展示了显着的成果。扩散模型是一种基于两个阶段的深度生成模型,即前向扩散阶段和反向扩散阶段。在前向扩散阶段,通过添加高斯噪声在几个步骤中逐渐扰动输入数据。在反向阶段,模型的任务是通过学习逐步反向扩散过程来恢复原始输入数据。扩散模型因其生成样本的质量和多样性而受到广泛赞赏,尽管其计算负担已知,即由于采样过程中涉及大量步骤而导致速度较低。
Abstract
Denoising diffusion models represent an emerging topic in computer vision, showing remarkable results in the field of generative modeling. The diffusion model is a deep generative model based on two stages, namely the forward diffusion stage and the backward diffusion stage. In the forward diffusion stage, the input data is gradually perturbed in several steps by adding Gaussian noise. In the inverse phase, the task of the model is to recover the original input data by learning a stepwise backward diffusion process. Diffusion models are widely appreciated for the quality and diversity of the samples they generate, despite the known computational burden of low speed due to the large number of steps involved in the sampling process.
1. 通用框架

扩散模型是一类概率生成模型,它学习逆转一个逐渐降低训练数据结构的过程。因此,训练过程包括两个阶段:正向扩散过程和反向去噪过程。前一阶段由多个步骤组成,在这些步骤中,低水平的噪声被添加到每个输入图像中,其中噪声的规模在每一步变化。训练数据逐渐被破坏,直到产生纯高斯噪声。后一阶段是通过逆转正向扩散过程来表示的。同样的迭代过程被使用,但是是反向的:噪声被顺序地去除,因此,原始图像被重新创建。因此,在推理时,图像是由随机白噪声开始逐步重建生成的。每一处的噪声都减少了时间步长是通过神经网络估计的,通常基于 U-Net 架构,允许保留维度。在接下来的三个部分中,我们提出了三种扩散模型的表达方式,即去噪扩散概率模型,噪声条件下的分数网络,以及基于随机微分方程的方法,该方法在前两种方法的基础上得到了推广。对于每一个公式,我们描述了向数据添加噪声的过程,学习反向这个过程的方法,以及在推理时如何生成新的样本。在图 中,所有三种公式都作为一个通用框架加以说明。我们将在最后一小节讨论与其他深层生成模型的联系。
2.去噪扩散概率模型(ddpm)
2.1 DDPM概述
扩散过程的表述,即输入图像 x 0 x_0 x0 ,经过时间 T个步骤,逐渐向其添加高斯噪声,我们将其称为前向过程。值得注意的是,这与神经网络的前向传递无关。但是前向过程对于我们的神经网络生成(应用t<T 添加噪声步骤后的图像)目标是必要的。之后,通过反转噪声过程来恢复原始数据,训练神经网络。通过能够对逆向过程建模,我们可以生成新数据。这就是所谓的反向扩散过程,或者通俗地说,就是生成模型的采样过程。更具体些,对于一个步的扩散模型,每一步的索引为t。在前向过程中,我们从一个真实图像 x 0 x_0 x0开始,在每一步我们随机生成一些高斯噪声,然后将生成的噪声逐步加入到输入图像中,当T足够大时,我们得到的加噪后的图像便接近一个高斯噪声图像,例如DDPM中 T=1000。在后向过程中,我们从噪声图像 x T x_T xT开始(训练时是真实图像加噪的结果,采样时是随机噪声),通过一个神经网络学习 x t − 1 x_{t-1} xt−1到 x t x_t xt 添加的噪声,然后通过逐渐去噪的方式得到最后要生成的图像。
2.2 扩散模型 Diffusion
扩散模型的训练可以分为两部分:
- 正向扩散→在图像中添加噪声。
- 反向扩散过程→去除图像中的噪声
正向扩散过程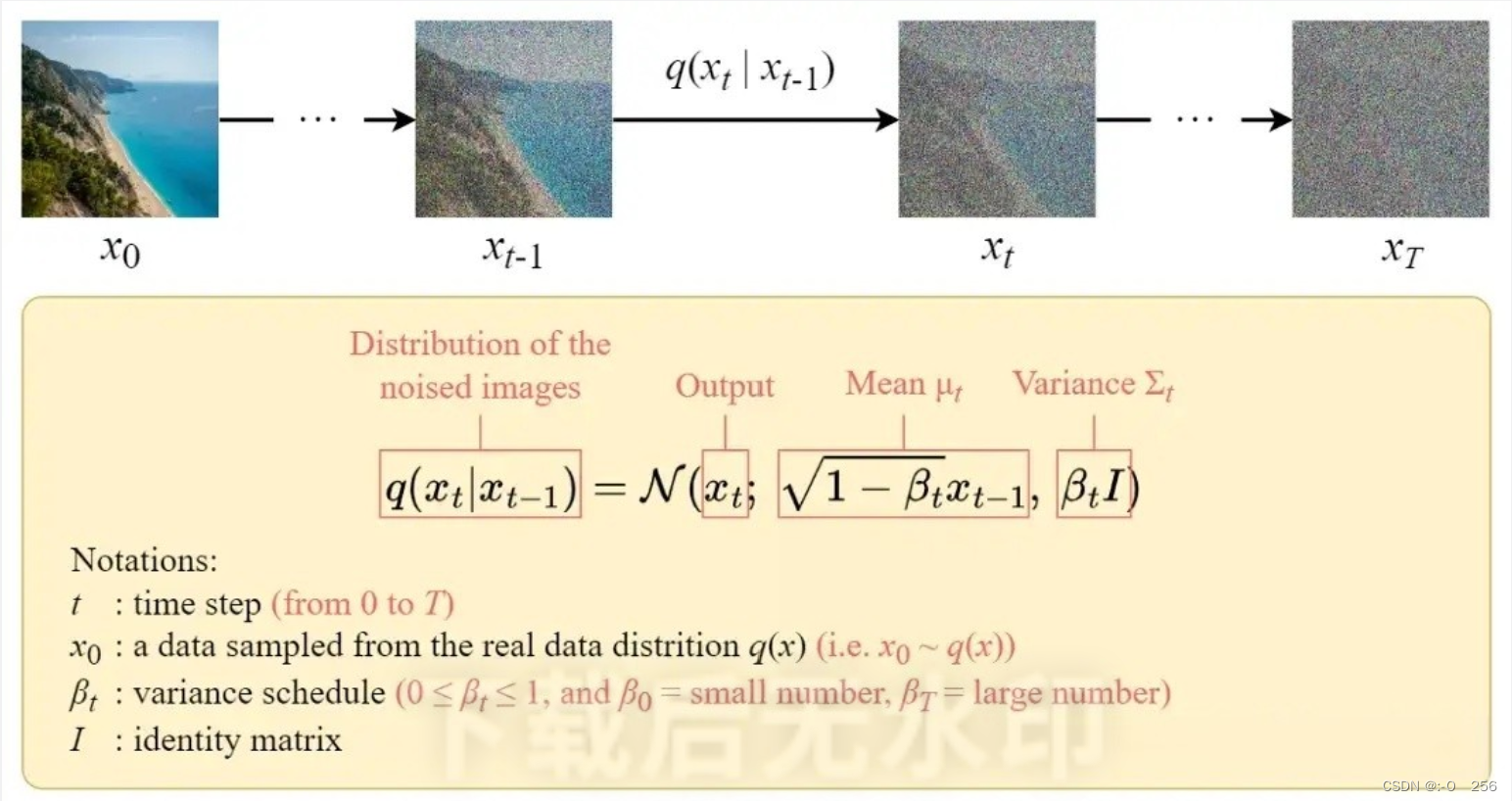
封闭公式
封闭形式的抽样公式可以通过重新参数化技巧得到。
手写推到:

现在我们可以使用这个公式在任何时间步骤直接对xₜ进行采样,这使得向前的过程更快。
反向扩散过程

与正向过程不同,不能使用
q
(
x
t
−
1
∣
x
t
)
q(x_{t-1}|x_t)
q(xt−1∣xt)来反转噪声,因为它是难以处理的(无法计算)。所以我们需要训练神经网络
p
θ
(
x
t
−
1
∣
x
t
)
来近似
q
(
x
t
−
1
∣
x
t
)
p_θ(x_{t-1}|x_t)来近似q(x_{t-1}|x_t)
pθ(xt−1∣xt)来近似q(xt−1∣xt)。近似
p
θ
(
x
t
−
1
∣
x
t
)
p_θ(xₜ₋₁|xₜ)
pθ(xt−1∣xt)服从正态分布,其均值和方差设置如下:
μ
θ
(
x
t
,
t
)
:
=
μ
θ
(
x
t
,
x
0
)
~
\mu_\theta(x_t,t) := \tilde{\mu_\theta(x_t,x_0)}
μθ(xt,t):=μθ(xt,x0)~
∑
θ
(
x
t
,
t
)
:
=
β
t
I
\sum\theta(x_t,t) := \beta _t I
∑θ(xt,t):=βtI
损失函数
损失定义为负对数似然

这个设置与VAE中的设置非常相似。我们可以优化变分的下界,而不是优化损失函数本身。
通过优化一个可计算的下界,我们可以间接优化不可处理的损失函数。

通过展开,我们发现它可以用以下三项表示:
- 1、L_T:常数项 由于 q 没有可学习的参数,p 只是一个高斯噪声概率,因此这一项在训练期间将是一个常数,因此可以忽略。
- 2、Lₜ₋₁:逐步去噪项 这一项是比较目标去噪步骤 q 和近似去噪步骤 pθ。通过以 x₀ 为条件,q(xₜ₋₁|xₜ, x₀) 变得易于处理。

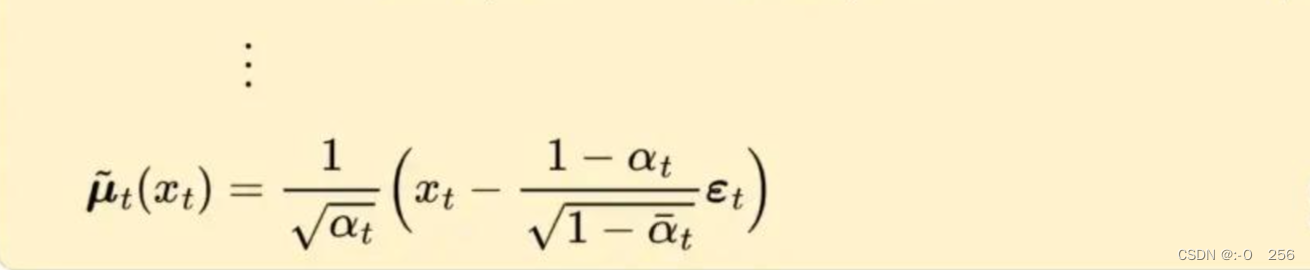
经过一系列推导,上图为q(xₜ₋₁|xₜ,x₀)的平均值μ′ₜ。为了近似目标去噪步骤q,我们只需要使用神经网络近似其均值。所以我们将近似均值 μ θ μ_θ μθ设置为与目标均值 μ̃ₜ 相同的形式(使用可学习的神经网络 εθ):

目标均值和近似值之间的比较可以使用均方误差(MSE)进行:
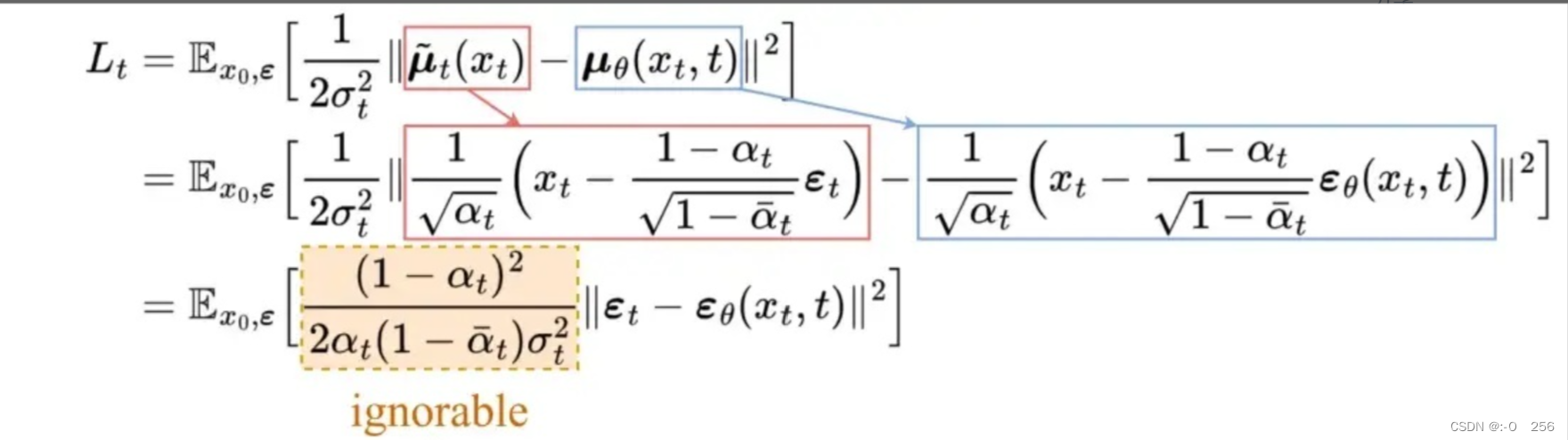
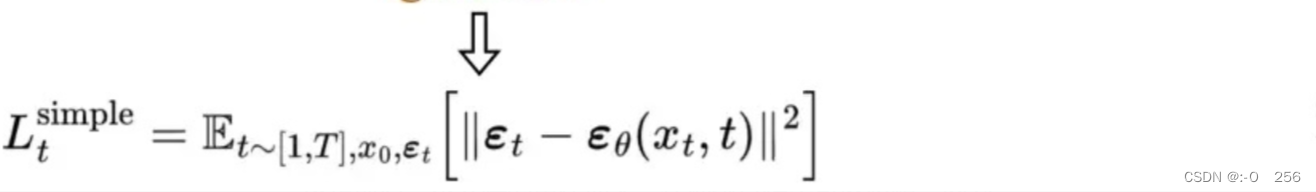
经过实验,通过忽略加权项并简单地将目标噪声和预测噪声与 MSE 进行比较,可以获得更好的结果。所以为了逼近所需的去噪步骤 q,我们只需要使用神经网络 εθ 来逼近噪声 εₜ。
-3、L₀:重构项
这是最后一步去噪的重建损失,在训练过程中可以忽略,因为:
可以使用 Lₜ₋₁ 中的相同神经网络对其进行近似。
忽略它会使样本质量更好,并更易于实施。
所以最终简化的训练目标如下:
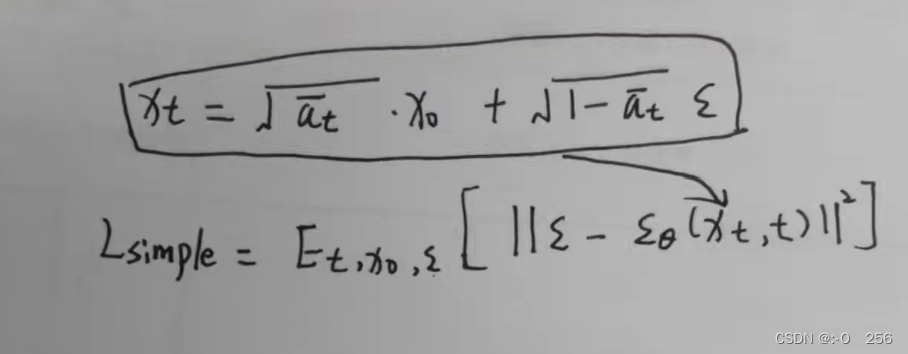
2.2 DDPM原理
前进过程。 DDPM 使用高斯噪声慢慢破坏训练数据。令 p(x0) 为数据密度,其中索引 0 表示数据未损坏(原始)。给定一个未损坏的训练样本 x0 ∼ p(x0),噪声版本
x
1
,
x
2
.
.
.
,
x
T
x_1,x_2 ...,x_T
x1,x2...,xT根据以下公式获得马尔可夫过程:
p
(
x
t
,
x
t
−
1
)
=
N
(
x
t
;
1
−
β
t
⋅
x
t
−
1
,
β
t
⋅
I
)
,
∀
t
∈
{
1
,
2
,
3
,
.
.
.
,
T
}
——
(
1
)
p(x_{t},x_{t-1})=N(x_{t};\sqrt{1-\beta _{t}}\cdot x_{t-1},\beta _{t}\cdot I),\forall t\in\left \{ 1,2,3,...,T \right \}——(1)
p(xt,xt−1)=N(xt;1−βt⋅xt−1,βt⋅I),∀t∈{1,2,3,...,T}——(1)
其中 T 是扩散步骤的数量,β1,…,βT ∈ [0, 1) 是表示跨扩散步骤的方差表的超参数,I 是与输入图像 x0 具有相同维度的单位矩阵,N(x; μ, σ) 表示生成 x 的均值 μ 和协方差 σ 的正态分布。该递归公式的一个重要特性是,当 t 从均匀分布中抽取时,它还允许对
x
t
x_t
xt 进行直接采样,即 ∀t ∼U ({1,…,T}):
p
(
x
t
,
x
0
)
=
N
(
x
t
;
1
−
β
^
t
⋅
x
0
,
β
^
t
⋅
I
)
——
(
2
)
p(x_{t},x_{0})=N(x_{t};\sqrt{1-\hat \beta _{t}}\cdot x_0,\hat\beta _{t}\cdot I)——(2)
p(xt,x0)=N(xt;1−β^t⋅x0,β^t⋅I)——(2)
其中
β
^
t
=
∏
i
=
1
t
α
i
且
α
t
=
1
−
β
t
\hatβ_{t}=\prod_{i=1}^{t}αi 且 α_t =1− β_t
β^t=∏i=1tαi且αt=1−βt。本质上,表明,如果我们有原始图像
x
0
x_0
x0 并修复方差表
β
t
β_t
βt,我们可以通过单个步骤对任何噪声版本
x
t
x_t
xt 进行采样。
p
(
x
t
∣
x
0
)
p(x_t|x_0)
p(xt∣x0) 的采样是通过重新参数化技巧来执行的。一般来说,为了标准化正态分布
x
∼
N
(
μ
,
σ
2
⋅
I
)
x ∼N(μ, σ^2 · I)
x∼N(μ,σ2⋅I) 的样本 x,我们减去平均值 μ 并除以标准差 σ,
z
=
x
−
μ
σ
z =\frac{x-\mu }{\sigma }
z=σx−μ 得到标准正态分布的样本 z ~ N(0,I)。重新参数化技巧执行此操作的逆操作,从 z 开始,通过将 z 乘以标准差 σ 并加上平均值 μ 来生成样本 x,即
x
=
z
⋅
σ
+
μ
x=z\cdot \sigma +\mu
x=z⋅σ+μ。如果我们将此过程转化为我们的情况,则
x
t
从
p
(
x
t
∣
x
0
)
x_t 从 p(x_t|x_0)
xt从p(xt∣x0)中采样,因为
μ
=
1
−
β
^
t
⋅
x
0
,
σ
=
β
^
t
⋅
I
\mu = \sqrt{1-\hat\beta _t}\cdot x_0,\sigma =\sqrt{\hat\beta _t}\cdot I
μ=1−β^t⋅x0,σ=β^t⋅I,如下所示:
x
t
=
β
^
t
⋅
x
0
+
1
−
β
^
t
⋅
z
0
——
(
3
)
x_t=\sqrt{\hat\beta_t}\cdot x_0+\sqrt{1-\hat\beta_t}\cdot z_0——(3)
xt=β^t⋅x0+1−β^t⋅z0——(3)
其中
z
t
∼
N
(
0
,
I
)
。
β
t
z_t∼N(0, I)。 β_t
zt∼N(0,I)。βt 的性质。如果选择方差表
(
β
t
)
t
=
1
T
使得
β
T
→
0
(β_t)_{t=1}^{T} 使得 β_T → 0
(βt)t=1T使得βT→0,则根据 (2),
x
T
x_T
xT 的分布应该很好地近似为标准高斯分布
π
(
x
T
)
=
N
(
0
,
I
)
π(x_T)= N(0,I)
π(xT)=N(0,I)。此外,如果每个
(
β
t
)
t
=
1
T
<
<
1
(β_t)_{t=1}^{T}<<1
(βt)t=1T<<1,则反向步骤
p
(
x
t
−
1
∣
x
t
)
p(x_{t-1}|x_t)
p(xt−1∣xt)具有与正向过程
p
(
x
t
∣
x
t
−
1
)
p(x_t|x_{t-1})
p(xt∣xt−1)相同的函数形式。直观上,当
x
t
x_t
xt 以非常小的步长创建时,最后一个陈述是正确的,因为
x
t
−
1
x_{t−1}
xt−1 更有可能来自靠近观察
x
t
x_t
xt 的区域,这允许我们使用高斯分布对该区域进行建模。为了符合上述性质。 选择
(
β
t
)
t
=
1
T
为
β
1
=
1
0
−
4
和
β
T
=
2
⋅
1
0
−
2
(β_t)_{t=1}^{T}为 β_1 =10^{−4} 和 β_T =2 · 10_{−2}
(βt)t=1T为β1=10−4和βT=2⋅10−2之间线性递增的常数,其中 T = 1000。
逆向过程。通过利用上述属性,如果我们从样本
x
T
x_T
xT ∼N(0, I) 开始并遵循相反的步骤
p
(
x
t
−
1
∣
x
t
)
=
N
(
x
t
−
1
;
μ
(
x
t
,
t
)
,
Σ
(
x
t
,
t
)
)
p(x_{t−1}|x_t)= N(x_{t−1}; μ(x_t,t), Σ(x_t,t))
p(xt−1∣xt)=N(xt−1;μ(xt,t),Σ(xt,t))。为了近似这些步骤,我们可以训练一个神经网络
p
θ
(
x
t
−
1
∣
x
t
)
=
N
(
x
t
−
1
;
μ
θ
(
x
t
,
t
)
,
Σ
θ
(
x
t
,
t
)
)
p_θ(x_{t−1}|x_t)= N(x_{t−1}; μ_θ(x_t,t), Σ_θ(x_t,t))
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t)),该网络接收噪声图像 xt 和时间步长 t ,并学习预测平均值
μ
θ
(
x
t
,
t
)
和协方差
Σ
θ
(
x
t
,
t
)
μ_θ(x_t,t) 和协方差 Σ_θ(x_t,t)
μθ(xt,t)和协方差Σθ(xt,t)。
在理想的情况下,我们会用一个最大似然目标来训练神经网络,使模型
p
θ
(
x
0
)
p_θ(x_0)
pθ(x0)分配给每个训练示例
x
0
x_0
x0的概率尽可能大。然而,
p
θ
(
x
0
)
p_θ(x_0)
pθ(x0)是棘手的,因为我们必须将所有可能的反向轨迹边缘化,才能计算它。解决这个问题的方法是最小化负对数似然的一个变分下界,公式如下:
ι
v
l
b
=
−
log
p
θ
(
x
0
∣
x
1
)
+
K
L
(
p
(
x
T
∣
x
0
)
∣
∣
π
(
x
T
)
)
+
∑
t
>
1
K
L
(
p
(
x
t
−
1
∣
x
t
,
x
0
)
∣
∣
p
θ
(
x
t
−
1
∣
x
t
)
)
——
(
4
)
\iota_{vlb} =-\log p_\theta (x_0|x_1)+KL(p(x_T|x_0)||\pi (x_T))+\sum_{t>1}KL(p(x_{t-1}|x_t,x_0)||p_\theta(x_{t-1}|x_t))——(4)
ιvlb=−logpθ(x0∣x1)+KL(p(xT∣x0)∣∣π(xT))+t>1∑KL(p(xt−1∣xt,x0)∣∣pθ(xt−1∣xt))——(4)
式中KL表示两个概率分布之间的Kullback-Leibler散度。分析每个分量,我们可以看到,第二项可以被删除,因为它不依赖于θ。最后一项表明,神经网络的训练是这样的,在每个时间步t,
p
θ
(
x
t
−
1
∣
x
t
)
p_θ(x_{t−1}|x_t)
pθ(xt−1∣xt)在原始图像条件下尽可能接近正演过程的真后验。可以证明后验
p
(
x
t
−
1
∣
x
t
,
x
0
)
p(x_{t−1}|x_t,x_0)
p(xt−1∣xt,x0)是一个高斯分布,意味着KL散度的闭型表达式。
将协方差
Σ
θ
(
x
t
,
t
)
Σ_θ(x_t,t)
Σθ(xt,t)固定为一个常数值,并将平均μθ(xt,t)重写为噪声的函数,如下所示:
μ
θ
=
1
α
t
⋅
(
x
t
−
1
−
α
t
1
−
β
^
t
)
⋅
z
θ
(
x
t
,
t
)
——
(
5
)
\mu _\theta =\frac{1}{\sqrt{\alpha _t}}\cdot\left ( x_t-\frac{1-\alpha_t}{\sqrt{1-\hat \beta _t}} \right )\cdot z_\theta(x_t,t)——(5)
μθ=αt1⋅
xt−1−β^t1−αt
⋅zθ(xt,t)——(5)
这些简化解开了目标Lvlb的一个新公式,它度量了在正向过程的随机时间步长t下,模型的真实噪声zt与噪声估计zθ(xt,t)之间的距离:
ι
s
i
m
p
l
e
=
E
t
∼
[
1
,
T
]
E
x
0
∼
p
(
x
0
)
E
z
0
∼
N
(
0
,
1
)
∥
z
t
−
z
θ
(
x
t
,
t
)
∥
2
——
(
6
)
\iota_{simple} = E_{t\sim [1,T]} E_{x_0\sim p(x_0)}E_{z_0\sim N(0,1)} \left \| z_t-z_\theta(x_t,t)\right \|^2——(6)
ιsimple=Et∼[1,T]Ex0∼p(x0)Ez0∼N(0,1)∥zt−zθ(xt,t)∥2——(6)
其中E为期望值,
z
θ
(
x
t
,
t
)
z_θ(x_t,t)
zθ(xt,t)为预测
x
t
x_t
xt噪声的网络。我们强调
x
t
x_t
xt是通过(3)采样的,其中我们使用训练集中的随机图像
x
0
x_0
x0。生成过程仍然由
p
θ
(
x
t
−
1
∣
x
t
)
p_θ(x_{t−1}|x_t)
pθ(xt−1∣xt)定义,但神经网络并不直接预测均值和协方差。相反,训练它从图像中预测噪声,均值根据(5)确定,协方差固定为一个常数。算法1形式化了整个生成过程。
总结
这周学习了扩散模型的基本知识和数学原理,下周将继续学习扩散模型所用的U-Net模型算法。















 355
355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









