







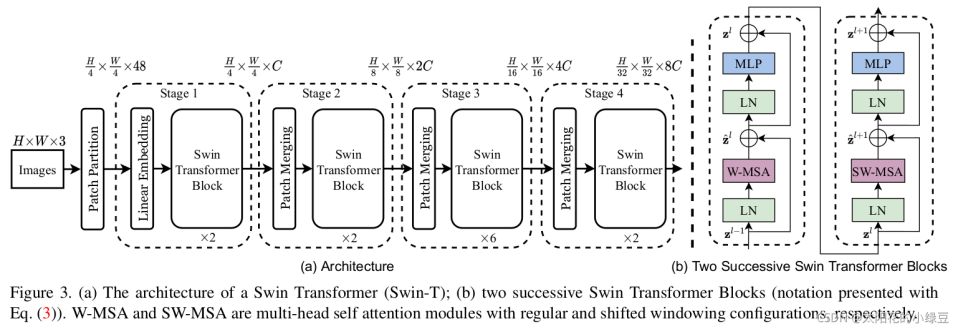
Swin-Transformer得益于其窗口注意力和偏移窗口注意力机制,平衡了感受野和计算效率,逐渐替代Vit成为了很多视觉网络的Backbone。下面将尽可能的清晰地解释其各个模块!
参考文献
nsformer网络结构详解
文章目录
1. SwinTransformer的创新点
从NLP转换为CV,Transformer存在两大难点:
(1)CV的尺度变化大,Transformer感受野有限,无法像CNN一样容纳多个尺度;
(2)CV的图像分辨率高,Transformer计算复杂度高。
基于以上难点,SwinTransformer分别通过以下方法进行改善:
(1)针对transformer感受野有限的难点
Swin Transformer 用 Hierarchical(分层级)的方式解决尺度变化大的难点,针对不同的尺度,每个stage设置了不一样的感受野,随着 stage 逐渐变大,感受野也逐渐变大。
(2)针对计算复杂度高的难点
Swin Transformer 使用分组方式(Windows-MSA)降低计算复杂度,而采用Shifted-windows进行组与组的信息交互。
2. Patch Partition和Linear Embeding
(1)Patch Partition
首先将图片输入到Patch Partition模块中进行分块,即每4x4相邻的像素为一个Patch,然后在channel方向展平(flatten)。假设输入的是RGB三通道图片,那么每个patch就有4x4=16个像素,然后每个像素有R、G、B三个值所以展平后是16x3=48,所以通过Patch Partition后图像shape由 [H, W, 3]变成了 [H/4, W/4, 48]。
(2)Linear Embedding
然后在通过Linear Embeding层对每个像素的channel数据做线性变换,由48变成C,即图像shape再由 [H/4, W/4, 48]变成了 [H/4, W/4, C]。其实在源码中Patch Partition和Linear Embeding就是直接通过一个卷积层实现的,和之前Vision Transformer中讲的 Embedding层结构一模一样。
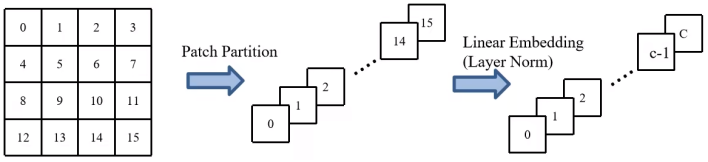
流程如上图所示。
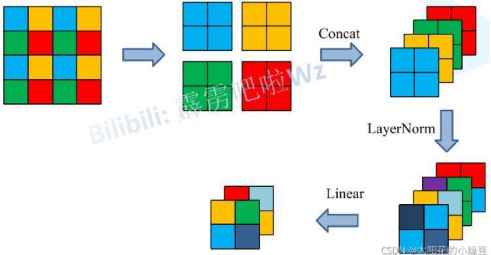
3. PatchMerging
上面有说,在每个Stage中首先要通过一个Patch Merging层进行下采样(Stage1除外)。如下图所示,假设输入Patch Merging的是一个4x4大小的单通道特征图(feature map),Patch Merging会将每个2x2的相邻像素划分为一个patch,然后将每个patch中相同位置(同一颜色)像素给拼在一起就得到了4个feature map。接着将这四个feature map在深度方向进行concat拼接,然后在通过一个LayerNorm层。最后通过一个全连接层在feature map的深度方向做线性变化,将feature map的深度由C变成C/2。通过这个简单的例子可以看出,通过Patch Merging层后,feature map的高和宽会减半,深度会翻倍,如下图所示:
4. W-MSA(窗口多头注意力机制) in TransformerBlocks
引入Windows Multi-head Self-Attention(W-MSA)模块是为了减少计算量。如下图所示,左侧使用的是普通的Multi-head Self-Attention(MSA)模块,对于feature map中的每个像素(或称作token,patch)在Self-Attention计算过程中需要和所有的像素去计算。但在图右侧,在使用Windows Multi-head Self-Attention(W-MSA)模块时,首先将feature map按照MxM(例子中的M=2)大小划分成一个个Windows,然后单独对每个Windows内部进行Self-Attention。

采用W-MSA模块时,只会在每个窗口内进行自注意力计算,所以窗口与窗口之间是无法进行信息传递的。
5. SW-MSA(偏移窗口多头注意力机制)
前面有说,采用W-MSA模块时,只会在每个窗口内进行自注意力计算,所以窗口与窗口之间是无法进行信息传递的。为了解决这个问题,作者引入了Shifted Windows Multi-Head Self-Attention(SW-MSA)模块,即进行偏移的W-MSA。如下图所示,左侧使用的是刚刚讲的W-MSA(假设是第L层),那么根据之前介绍的W-MSA和SW-MSA是成对使用的,那么第L+1层使用的就是SW-MSA(右侧图)。根据左右两幅图对比能够发现窗口(Windows)发生了偏移(可以理解成窗口从左上角分别向右侧和下方各偏移了⌊M /2⌋个像素)。看下偏移后的窗口(右侧图),比如对于第一行第2列的2x4的窗口,它能够使第L层的第一排的两个窗口信息进行交流。再比如,第二行第二列的4x4的窗口,他能够使第L层的四个窗口信息进行交流,其他的同理。那么这就解决了不同窗口之间无法进行信息交流的问题。
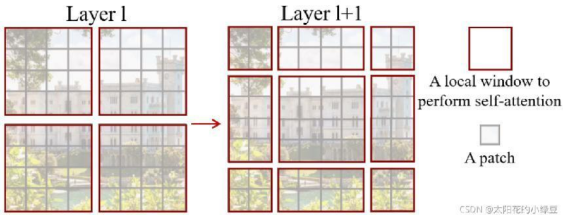
根据上图,可以发现通过将窗口进行偏移后,由原来的4个窗口变成9个窗口了。后面又要对每个窗口内部进行MSA,这样做感觉又变麻烦了。为了解决这个麻烦,作者又提出而了Efficient batch computation for shifted configuration,一种更加高效的计算方法。下面是原论文给的示意图。

然后计算的时候对非原区域的进行mask处理。
6. Relative position bias
在计算Attention时,swin-transformer的公式里新增了一个相对位置偏执B,如下:
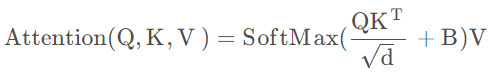
相对位置索引计算:https://blog.csdn.net/weixin_40723264/article/details/127632545
先计算出相对位置索引,feature map的size确定了,索引的位置就是固定的。然后训练一个relative position bias table。所以最终训练的是relative position bias table里的值。

完结,撒花!
















 9253
9253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









