







目录
7、完整代码和权重下载
为了更详细的了解Yolo的实现原理,通过YOLO的代码形式进行一步一步说明,在阅读代码的过程中,按照下面的目录的步骤去看代码。但在看代码之前建议先去简单的了解YOLO的原理,在了解之后通过下面的内容进一步验证yolo的实现过程,同时也了解了ResNet的实现过程。
YOLO的原理参考通道1
YOLO的原理参考通道2
正文:
1、前期准备
准备好目录结构、数据集和关于YOLOv1的基础认知
1.1 创建目录结构
自己创建项目目录结构,结构目录如下:

network CNN Backbone 存放位置
weights 权重存放的位置
test_images 测试用的图片
utils 辅助功能的代码存放位置models 保存模型位置
data 训练的数据集
1.2 数据集介绍与下载
1.2.1 数据集介绍
首先了解数据集,对数据集了解后方便对数据进行相应处理。数据集详细介绍直通车:https://blog.csdn.net/qq_41946216/article/details/137683750?spm=1001.2014.3001.5501
1.2.1 数据集下载
本次采用数据集: VOC2012数据集。
数据集下载方式一:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
数据集下载方式二:
下载并构建VOC2012数据集,从:https://gitee.com/ppov-nuc/pascal-vocdataset_-for_-yolo.git, 下载get_data文件和generate_csv.py文件到本地,放到创建的目录结构中,修改get_data中下载的内容和相应路径,然后运行批处理文件get_data,在get_dat中会自动执行generate_csv.py,如下图所示。

1.3. 数据集处理
在utils目录下创建工具类 generate_txt_file.py,主要用于数据集的划分和解析 Annotations/xxxxx.xml 文件中的类别和bbox信息,并将信息存入voctrain.txt和voctest.txt文件,如下图所示:


具体代码:
# author: baiCai
# 1. 导包
from xml.etree import ElementTree as ET
import os
import random
# 2. 定义一些基本的参数
# 定义所有的类名
VOC_CLASSES = (
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor')
'''
读取所有 xml 文件,存入列表
'''
# 要读取的xml文件路径,记得自己修改路径
Annotations = '../data/VOC2012/Annotations/'
# 列出所有的xml文件
xml_files = os.listdir(Annotations)
# 打乱数据集
random.shuffle(xml_files)
'''
定义训练集和测试比例
划分Annotations中的训练集和测试集文件列表
'''
# 训练集数量
train_num = int(len(xml_files) * 0.7)
# 训练列表
train_file_list = xml_files[:train_num]
# 测测试列表
test_file_list = xml_files[train_num:]
'''
定义 xml 解析后的信息存储路径和写对象
'''
# 训练集和测试集文件名字
train_set_path = './voctrain.txt'
test_set_path = './voctest.txt'
# 3. 定义解析xml文件的函数
'''
主要解析 xml 获取 类别名字和bbox,如
{'name': 'person','bbox': [174, 101, 349, 351]}
'''
def parse_rec(filename):
# 参数:输入xml文件名
# 创建xml对象
tree = ET.parse(filename)
objects = []
# 迭代读取xml文件中的object节点,即物体信息
for obj in tree.findall('object'):
obj_struct = {}
# difficult属性,即这里不需要那些难判断的对象
difficult = int(obj.find('difficult').text)
if difficult == 1: # 若为1则跳过本次循环
continue
# 开始收集信息
obj_struct['name'] = obj.find('name').text
bbox = obj.find('bndbox')
obj_struct['bbox'] =\
[int(float(bbox.find('xmin').text)),
int(float(bbox.find('ymin').text)),
int(float(bbox.find('xmax').text)),
int(float(bbox.find('ymax').text))]
objects.append(obj_struct)
return objects
# 4. 把信息保存入文件中
def write_txt(file_list,set_path):
# # 生成训练集txt
count = 0
with open(set_path, 'w') as wt:
for xml_file in file_list:
count += 1
# 获取图片名字
image_name = xml_file.split('.')[0] + '.jpg' # 图片文件名
# 对xml_file进行解析
results = parse_rec(Annotations + xml_file)
# 如果返回的对象为空,表示张图片难以检测,因此直接跳过
if len(results) == 0:
print(xml_file)
continue
# 否则,则写入文件中
# 先写入图片名字
wt.write(image_name)
# 接着指定下面写入的格式
for result in results:
class_name = result['name']
bbox = result['bbox']
class_name = VOC_CLASSES.index(class_name) # 名字在类别中是下标位置
wt.write(' ' + str(bbox[0]) +
' ' + str(bbox[1]) +
' ' + str(bbox[2]) +
' ' + str(bbox[3]) +
' ' + str(class_name))
wt.write('\n')
wt.close()
# 5. 运行
if __name__ == '__main__':
write_txt(train_file_list,train_set_path)
write_txt(test_file_list,test_set_path)
1.4. 构建数据加载器
在utils目录下创建工具类 yolo_dataset.py,主要用于数据集的构建,包含初始化、图片增强及归一化等功能。具体代码在下面完整代码中。
1.4.1定义初始化方法
读取xxxx.xml解析后的文件
对每行数据(每个图片信息)的所有中心点信息以【x,y,w,h】和标签分别存入box列表和label列表。
当前图片的边界框和标签信息即box列表和label列表,转换为LongTensor格式添加到对应的boxex列表和labels列表。

1.4.2 定义增强图片方法
增加方法如下列表:
| 增加方法名称 | 定义的函数 |
| 随机翻转图片和边界框 | random_flip(img, boxes) |
| 随机缩放图片和边界框 | randomScale(img, boxes) |
| 随机模糊图片 | randomBlur(img) |
| 随机调整图片亮度 | RandomBrightness(img) |
| 随机调整图片色调 | RandomHue(img) |
| 随机调整图片饱和度 | RandomSaturation(img) |
| 随机移动图片和边界框 | randomShift(img, boxes, labels) |
| 随机裁剪图片和边界框 | randomCrop(img, boxes, labels) |
| 用于从图像中减去均值 | subMean(self, bgr, mean) |
| 将BGR图像转换为RGB图像 | BGR2RGB(self, img) |
| 将BGR图像转换为HSV图像 | BGR2HSV(self, img) |
| 将HSV图像转换为BGR图像 | HSV2BGR(self, img) |
1.4.3 定义编码器
定义编码器主要目的是用于将边界框(归一化后的边界框信息)和标签编码为目标张量。
1.4.4 完整代码
# author: baiCai
# 导入所需的库
import os
import random
import numpy as np
import torch
import torchvision.transforms as T
from torch.utils.data import Dataset
import cv2
# 定义一个Yolo数据加载器类
class Yolo_Dataset(Dataset):
# 初始化默认的图片大小
image_size = 448
def __init__(self, root, list_file, train=True, transforms=None):
''"""
初始化函数
:param root: 图片的根目录
:param list_file: 包含图片路径和标注信息的txt文件
:param train: 是否为训练集,默认为True
:param transforms: 预处理方法,默认为None
"""
# 保存传入的参数
self.root = root
self.train = train
self.transform = transforms
self.fnames = [] # 存储图片文件名
self.boxes = [] # 存储边界框信息
self.labels = [] # 存储标签信息
self.mean = (123, 117, 104) # RGB通道的均值,用于归一化
# 打开并读取txt文件
with open(list_file) as f:
lines = f.readlines() # 读取所有行
# 遍历文件中的每一行
for line in lines:
splited = line.strip().split() # 去除行尾的空格并按空格分割
self.fnames.append(splited[0]) # 添加图片文件名到列表中
# 计算当前行包含的对象数量,每五个数据表示一个对象
num_boxes = (len(splited) - 1) // 5
# 初始化当前图片的边界框和标签列表
box = []
label = []
# 遍历当前行的所有对象
for i in range(num_boxes):
# 读取边界框的坐标信息
x = float(splited[1 + 5 * i])
y = float(splited[2 + 5 * i])
x2 = float(splited[3 + 5 * i])
y2 = float(splited[4 + 5 * i])
# 读取对象的类别标签
c = splited[5 + 5 * i]
# 将边界框坐标添加到列表中,并转换为Tensor格式
box.append([x, y, x2, y2])
# 将标签转换为整数并加1(因为标签通常从1开始计数),然后添加到列表中
label.append(int(c) + 1)
# 将当前图片的边界框和标签信息转换为LongTensor格式添加到对应的列表中
self.boxes.append(torch.Tensor(box))
self.labels.append(torch.LongTensor(label))
# 记录数据集中的样本数量
self.num_samples = len(self.boxes)
def __len__(self):
# 返回数据集中的样本数量
return self.num_samples
# 如果是训练模式,需要进行图像的增强,idx表示每个图像在fnames列表中索引
def __getitem__(self, idx):
# 根据索引获取图片的文件名
fname = self.fnames[idx]
# 拼接完整的图片路径并读取图片
img = cv2.imread(os.path.join(self.root, fname))
# 获取当前图片的边界框和标签信息
boxes = self.boxes[idx].clone()
labels = self.labels[idx].clone()
# 如果是训练模式,需要进行图像的增强
# 需要注意的是,同时处理图像和box
if self.train:
# 随机翻转图片和边界框
img, boxes = self.random_flip(img, boxes)
# 随机缩放图片和边界框
img, boxes = self.randomScale(img, boxes)
# 随机模糊图片
img = self.randomBlur(img)
# 随机调整图片亮度
img = self.RandomBrightness(img)
# 随机调整图片色调
img = self.RandomHue(img)
# 随机调整图片饱和度
img = self.RandomSaturation(img)
# 随机移动图片和边界框
img, boxes, labels = self.randomShift(img, boxes, labels)
# 随机裁剪图片和边界框
img, boxes, labels = self.randomCrop(img, boxes, labels)
# 获取图片的高度、宽度和通道数
h, w, _ = img.shape
# 将边界框坐标除以图片宽高,进行归一化
boxes /= torch.Tensor([w, h, w, h]).expand_as(boxes)
# 由于cv2读取图片为BGR格式,需要转换为RGB格式
img = self.BGR2RGB(img)
# 从图片中减去RGB通道的均值
img = self.subMean(img, self.mean)
# 将图片缩放到指定的大小,这里是448x448
img = cv2.resize(img, (self.image_size, self.image_size))
# 将边界框和标签信息编码为YOLOv1需要的格式,即7x7x30的张量
target = self.encoder(boxes, labels)
# 应用预定义的数据变换
for t in self.transform:
img = t(img)
# 返回处理后的图片和编码后的目标信息
return img, target
# 定义一个encoder方法,用于将边界框和标签编码为目标张量
def encoder(self, boxes, labels):
'''
将边界框和标签编码为7x7x30的目标张量
参数:
boxes (tensor): 形状为[[x1,y1,x2,y2],[]]的边界框张量
labels (tensor): 标签张量
返回:
target (tensor): 形状为7x7x30的目标张量
'''
grid_num = 7 # 定义网格数量
# 创建一个形状为(grid_num, grid_num, 30)的全零张量作为目标张量
target = torch.zeros((grid_num, grid_num, 30))
# 计算每个网格的缩放因子
cell_size = 1. / grid_num
print(cell_size)
print(boxes)
# 计算边界框的宽度、高度和中心点坐标,boxes 是归一化后数据
wh = boxes[:, 2:] - boxes[:, :2]
# 即 xmin ymin ,xmax,ymax 中心点坐标 ((xmax-xmin)/2,(ymax-ymin)/2))
cxcy = (boxes[:, 2:] + boxes[:, :2]) / 2
# 遍历每个边界框的中心点
for i in range(cxcy.size()[0]):
cxcy_sample = cxcy[i] # 获取当前边界框的中心点坐标
# 计算中心点所在的网格索引,并进行向上取整和减一操作
ij = (cxcy_sample / cell_size).ceil() - 1
# 标记目标张量中对应网格的objectness为1
target[int(ij[1]), int(ij[0]), 4] = 1
# 标记目标张量中对应网格的类别为1
target[int(ij[1]), int(ij[0]), 9] = 1
# 标记目标张量中对应网格的标签位置为1
target[int(ij[1]), int(ij[0]), int(labels[i]) + 9] = 1
# 计算中心点在当前网格内的相对坐标
xy = ij * cell_size
# 计算中心点相对于网格左上角的偏移量
delta_xy = (cxcy_sample - xy) / cell_size
# 填充目标张量中对应网格的宽度、高度信息
target[int(ij[1]), int(ij[0]), 2:4] = wh[i]
# 填充目标张量中对应网格的中心点偏移量信息
target[int(ij[1]), int(ij[0]), :2] = delta_xy
# 重复填充宽度、高度信息到目标张量的其他位置
target[int(ij[1]), int(ij[0]), 7:9] = wh[i]
# 重复填充中心点偏移量信息到目标张量的其他位置
target[int(ij[1]), int(ij[0]), 5:7] = delta_xy
# 返回填充好的目标张量
return target
# 以下是各种图像预处理方法的定义
# 将BGR图像转换为RGB图像
def BGR2RGB(self, img):
return cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 将BGR图像转换为HSV图像
def BGR2HSV(self, img):
return cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
# 将HSV图像转换为BGR图像
def HSV2BGR(self, img):
return cv2.cvtColor(img, cv2.COLOR_HSV2BGR)
# 随机调整图像的亮度
def RandomBrightness(self, bgr):
# 以0.5的概率调整图像的亮度
if random.random() < 0.5:
hsv = self.BGR2HSV(bgr) # 将BGR图像转换为HSV图像
h, s, v = cv2.split(hsv) # 分割HSV图像的通道
# 随机选择亮度调整系数
adjust = random.choice([0.5, 1.5])
v = v * adjust # 调整亮度通道的值
# 确保亮度值在0到255之间
v = np.clip(v, 0, 255).astype(hsv.dtype)
# 合并通道得到调整后的HSV图像
hsv = cv2.merge((h, s, v))
# 将调整后的HSV图像转换回BGR图像
bgr = self.HSV2BGR(hsv)
return bgr
# 定义一个随机调整图像饱和度的方法
def RandomSaturation(self, bgr):
# 以0.5的概率决定是否调整图像的饱和度
if random.random() < 0.5:
# 将BGR图像转换为HSV图像
hsv = self.BGR2HSV(bgr)
# 分割HSV图像的通道
h, s, v = cv2.split(hsv)
# 随机选择饱和度调整系数
adjust = random.choice([0.5, 1.5])
# 调整饱和度通道的值
s = s * adjust
# 确保饱和度值在0到255之间
s = np.clip(s, 0, 255).astype(hsv.dtype)
# 合并通道得到调整后的HSV图像
hsv = cv2.merge((h, s, v))
# 将调整后的HSV图像转换回BGR图像
bgr = self.HSV2BGR(hsv)
# 返回调整后的BGR图像
return bgr
# 定义一个随机调整图像色调的方法
# 随机调整图片色调
def RandomHue(self, bgr):
# 以0.5的概率决定是否调整图像的色调
if random.random() < 0.5:
# 将BGR图像转换为HSV图像
hsv = self.BGR2HSV(bgr)
# 分割HSV图像的通道
h, s, v = cv2.split(hsv)
# 随机选择色调调整系数
adjust = random.choice([0.5, 1.5])
# 调整色调通道的值
h = h * adjust
# 确保色调值在0到179之间(因为色调是循环的)
h = h % 180
# 确保色调值的数据类型与hsv图像一致
h = h.astype(hsv.dtype)
# 合并通道得到调整后的HSV图像
hsv = cv2.merge((h, s, v))
# 将调整后的HSV图像转换回BGR图像
bgr = self.HSV2BGR(hsv)
# 返回调整后的BGR图像
return bgr
# 定义一个随机模糊图像的方法
def randomBlur(self, bgr):
# 以0.5的概率决定是否对图像进行模糊处理
if random.random() < 0.5:
# 使用cv2.blur函数对图像进行模糊处理,核大小为(5, 5)
bgr = cv2.blur(bgr, (5, 5))
# 返回模糊处理后的图像或原图像
return bgr
# 定义一个随机平移图像的方法,同时更新边界框和标签的位置
def randomShift(self, bgr, boxes, labels):
# 计算边界框的中心点坐标
center = (boxes[:, 2:] + boxes[:, :2]) / 2
# 以0.5的概率决定是否对图像进行平移
if random.random() < 0.5:
# 获取图像的高度、宽度和通道数
height, width, c = bgr.shape
# 创建一个与原图同样大小的零矩阵,并填充为特定的BGR值(这里可能用于填充平移后的空白区域)
after_shfit_image = np.zeros((height, width, c), dtype=bgr.dtype)
after_shfit_image[:, :, :] = (104, 117, 123) # 填充BGR颜色值
# 生成随机的x和y方向的平移量,限制在图像尺寸的20%以内
shift_x = random.uniform(-width * 0.2, width * 0.2)
shift_y = random.uniform(-height * 0.2, height * 0.2)
# 根据平移量的正负值,对图像进行不同方向的平移
if shift_x >= 0 and shift_y >= 0:
# 当x和y都大于等于0时,从原图的右下角开始平移
after_shfit_image[int(shift_y):, int(shift_x):, :] = bgr[:height - int(shift_y), :width - int(shift_x),
:]
elif shift_x >= 0 and shift_y < 0:
# 当x大于等于0且y小于0时,从原图的右上方开始平移
after_shfit_image[:height + int(shift_y), int(shift_x):, :] = bgr[-int(shift_y):, :width - int(shift_x),
:]
elif shift_x < 0 and shift_y >= 0:
# 当x小于0且y大于等于0时,从原图的左下方开始平移
after_shfit_image[int(shift_y):, :width + int(shift_x), :] = bgr[:height - int(shift_y), -int(shift_x):,
:]
elif shift_x < 0 and shift_y < 0:
# 当x和y都小于0时,从原图的左上方开始平移
after_shfit_image[:height + int(shift_y), :width + int(shift_x), :] = bgr[-int(shift_y):,
-int(shift_x):, :]
# 将平移量转换为Tensor格式,并扩展到与中心点坐标相同的形状
shift_xy = torch.FloatTensor([[int(shift_x), int(shift_y)]]).expand_as(center)
# 更新中心点坐标,加上平移量
center = center + shift_xy
# 创建掩码,确保更新后的中心点坐标在图像尺寸范围内
mask1 = (center[:, 0] > 0) & (center[:, 0] < width)
mask2 = (center[:, 1] > 0) & (center[:, 1] < height)
# 合并两个掩码,得到同时满足两个条件的掩码
mask = (mask1 & mask2).view(-1, 1)
# 根据掩码筛选出更新后仍在图像内的边界框
boxes_in = boxes[mask.expand_as(boxes)].view(-1, 4)
# 如果经过平移后,没有边界框留在图像内,则直接返回原图像、原边界框和原标签
if len(boxes_in) == 0:
return bgr, boxes, labels
# 创建一个Tensor,用于存储平移量,其中x和y的平移量分别对应边界框的左上角和右下角
box_shift = torch.FloatTensor([[int(shift_x), int(shift_y), int(shift_x), int(shift_y)]]).expand_as(
boxes_in)
# 将平移量加到更新后的边界框上,注意这里是对边界框的四个坐标都进行了平移
boxes_in = boxes_in + box_shift
# 根据掩码筛选出更新后仍在图像内的标签
labels_in = labels[mask.view(-1)]
# 返回处理后的图像、更新后的边界框和标签
return after_shfit_image, boxes_in, labels_in
# 如果不需要进行平移,或者平移后逻辑没有进入if条件块,则直接返回原图像、原边界框和原标签
return bgr, boxes, labels
# 定义randomScale方法,用于对图像进行随机尺度变换
def randomScale(self, bgr, boxes):
# 如果随机生成的小于0.5的数,则执行尺度变换
if random.random() < 0.5:
# 生成0.8到1.2之间的随机尺度因子
scale = random.uniform(0.8, 1.2)
# 获取图像的高度、宽度和通道数
height, width, c = bgr.shape
# 使用cv2的resize函数,固定高度不变,按照生成的尺度因子调整宽度
bgr = cv2.resize(bgr, (int(width * scale), height))
# 创建一个Tensor,用于存储尺度因子,扩展为与boxes相同的形状
scale_tensor = torch.FloatTensor([[scale, 1, scale, 1]]).expand_as(boxes)
# 将尺度因子应用到中心点信息boxes上,进行尺度变换
boxes = boxes * scale_tensor
# 返回尺度变换后的图像和边界框
return bgr, boxes
# 如果不进行尺度变换,则返回原图像和边界框
return bgr, boxes
# 定义randomCrop方法,用于对图像进行随机裁剪
# 随机裁剪图片和边界框
def randomCrop(self, bgr, boxes, labels):
# 如果随机生成的小于0.5的数,则执行随机裁剪
if random.random() < 0.5:
# 计算边界框的中心点
center = (boxes[:, 2:] + boxes[:, :2]) / 2
# 获取图像的高度、宽度和通道数
height, width, c = bgr.shape
# 生成随机裁剪的高度和宽度,至少为原图像的60%
h = random.uniform(0.6 * height, height)
w = random.uniform(0.6 * width, width)
# 生成随机裁剪的起始坐标
x = random.uniform(0, width - w)
y = random.uniform(0, height - h)
# 将坐标和裁剪的尺寸转换为整数
x, y, h, w = int(x), int(y), int(h), int(w)
# 将裁剪起始坐标转换为Tensor,并从中心点中减去
center = center - torch.FloatTensor([[x, y]]).expand_as(center)
# 创建掩码,筛选出中心点落在裁剪区域内的边界框
mask1 = (center[:, 0] > 0) & (center[:, 0] < w)
mask2 = (center[:, 1] > 0) & (center[:, 1] < h)
# 将两个掩码合并,并展平为一维Tensor
mask = (mask1 & mask2).view(-1, 1)
# 根据掩码筛选出裁剪区域内的边界框
boxes_in = boxes[mask.expand_as(boxes)].view(-1, 4)
# 如果没有边界框落在裁剪区域内,则返回原图像、原边界框和原标签
if (len(boxes_in) == 0):
return bgr, boxes, labels
# 创建一个Tensor,用于存储裁剪起始坐标,扩展为与boxes_in相同的形状
box_shift = torch.FloatTensor([[x, y, x, y]]).expand_as(boxes_in)
# 将裁剪起始坐标从边界框中减去
boxes_in = boxes_in - box_shift
# 确保裁剪后的边界框坐标在裁剪区域内
boxes_in[:, 0] = boxes_in[:, 0].clamp_(min=0, max=w)
boxes_in[:, 2] = boxes_in[:, 2].clamp_(min=0, max=w)
boxes_in[:, 1] = boxes_in[:, 1].clamp_(min=0, max=h)
boxes_in[:, 3] = boxes_in[:, 3].clamp_(min=0, max=h)
# 根据掩码筛选出裁剪区域内的标签
labels_in = labels[mask.view(-1)]
# 裁剪图像
img_croped = bgr[y:y + h, x:x + w, :]
# 返回裁剪后的图像、裁剪区域内的边界框和标签
return img_croped, boxes_in, labels_in
# 如果不进行裁剪,则返回原图像、原边界框和原标签
return bgr, boxes, labels
# 定义subMean方法,用于从图像中减去均值
def subMean(self, bgr, mean):
# 将均值转换为float32类型的numpy数组
mean = np.array(mean, dtype=np.float32)
# 从图像bgr中减去均值
bgr = bgr - mean
# 返回减去均值后的图像
return bgr
# 定义random_flip方法,用于随机对图像进行水平翻转,并相应地更新边界框
# 随机翻转图片和边界框
def random_flip(self, im, boxes):
# 以0.5的概率决定是否进行翻转
if random.random() < 0.5:
# 对图像进行水平翻转
im_lr = np.fliplr(im).copy()
# 获取图像的高度、宽度
h, w, _ = im.shape
# 更新边界框的左边界为原右边界与图像宽度的差值
xmin = w - boxes[:, 2]
# 更新边界框的右边界为原左边界与图像宽度的差值
xmax = w - boxes[:, 0]
# 将更新后的左右边界赋值回边界框
boxes[:, 0] = xmin
boxes[:, 2] = xmax
# 返回翻转后的图像和更新后的边界框
return im_lr, boxes
# 如果不进行翻转,则返回原图像和原边界框
return im, boxes
# 定义random_bright方法,用于随机调整图像的亮度
def random_bright(self, im, delta=16):
# 生成一个0到1之间的随机数
alpha = random.random()
# 如果该随机数大于0.3
if alpha > 0.3:
# 调整图像的亮度,乘以随机数alpha并加上一个-delta到delta之间的随机整数
im = im * alpha + random.randrange(-delta, delta)
# 将调整亮度后的图像像素值限制在0到255之间,并转换为uint8类型
im = im.clip(min=0, max=255).astype(np.uint8)
# 返回调整亮度后的图像
return im
# 3. 调试代码
def main():
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
file_root = '../data/VOC2012/JPEGImages/' # 记得改为自己的路径
train_dataset = Yolo_Dataset(root=file_root,list_file='voctrain.txt',train=True,transforms = [T.ToTensor()] )
train_loader = DataLoader(train_dataset,batch_size=1,shuffle=False,num_workers=0)
train_iter = iter(train_loader)
for i in range(100):
img,target = next(train_iter)
print(img.shape)
print(target.shape)
break
if __name__ == '__main__':
main()1.5、定义主函数
在utils目录下创建工具类 yolo_dataset.py,中定义主函数进行测试,包含设置和加载一个自定义的Yolo_Dataset数据集,该数据集来源于VOC2012的JPEGImages文件夹。代码中首先导入了必要的模块和类,然后定义了数据集的根目录和预处理操作。接着,创建了一个Yolo_Dataset对象,并通过DataLoader类将其加载为可迭代的数据集。DataLoader的参数包括数据集、批次大小、是否打乱数据以及使用的子进程数量。最后,通过迭代器遍历数据集,获取图像和对应的目标数据,并打印它们的维度信息。
# 3. 调试代码
# 定义一个名为main的函数
def main():
# 从torch.utils.data模块中导入DataLoader类,用于加载数据集
from torch.utils.data import DataLoader
# 导入torchvision.transforms模块,用于图像预处理
import torchvision.transforms as transforms
# 设置文件根目录路径,这里假设是VOC2012数据集的JPEGImages文件夹
file_root = '../data/VOC2012/JPEGImages/' # 记得改为自己的路径
# 创建一个Yolo_Dataset对象,该对象可能是自定义的,用于加载VOC2012数据集
# 参数包括:
# root: 数据集的根目录
# list_file: 包含训练图像文件名的列表文件
# train: 是否为训练模式
# transforms: 图像预处理操作列表,这里只有一个操作,即将图像转换为Tensor
train_dataset = Yolo_Dataset(root=file_root, list_file='voctrain.txt', train=True,
transforms=[transforms.ToTensor()])
# 使用DataLoader类加载训练数据集
# 参数包括:
# dataset: 要加载的数据集
# batch_size: 每个批次的大小
# shuffle: 是否在每个epoch开始时打乱数据
# num_workers: 加载数据使用的子进程数量
train_loader = DataLoader(train_dataset, batch_size=1, shuffle=False, num_workers=0)
# 创建一个迭代器,用于遍历train_loader中的数据
train_iter = iter(train_loader)
# 遍历前100个批次的数据(但由于下面的break语句,实际上只会处理一个批次)
for i in range(100):
# 使用迭代器获取下一个批次的数据,包括图像和目标(可能是标签或边界框)
img, target = next(train_iter)
# 打印图像的shape(维度)
print(img.shape)
# 打印目标的shape(维度)
print(target.shape)
# 跳出循环,因此只处理一个批次的数据
break
if __name__ == '__main__':
main()2构建网络
在YOLO(You Only Look Once)系列的目标检测算法中,Backbone是一个核心组成部分,主要负责提取输入图像的特征。具体来说,Backbone是一种卷积神经网络,它通过多层次的特征提取,从低层次到高层次逐渐提取出图像的不同特征,如边缘、纹理、形状等,最终生成一个高维度的特征向量。这些特征向量在后续的网络层中被用于目标检测和分类等任务。
在YOLOv1中,大部分人都选用的ResNet作为自己的backbone,因为可以方便调用官方的预训练权重。
2.1 ResNet架构介绍
ResNet架构使用残差的模式,即输出值为F(x)+x模式,简单理解就是至少不比上次结果差。不了解可以参考其他人博客.

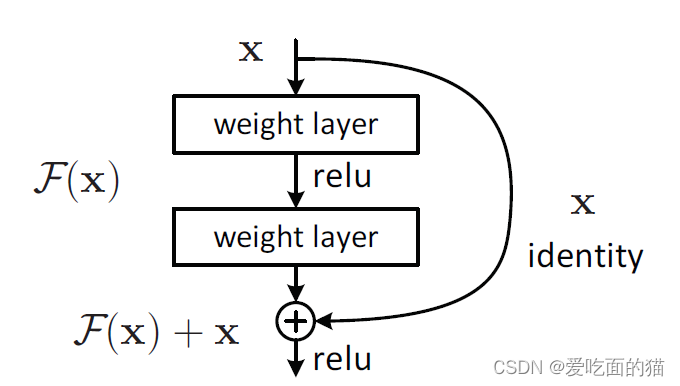
2.2 构建ResNet
在创建的目录结构network中创建Yolo_ResNet.py文件,用于创建 Base_Block、Senior_Block、Output_Block 和 ResNet。
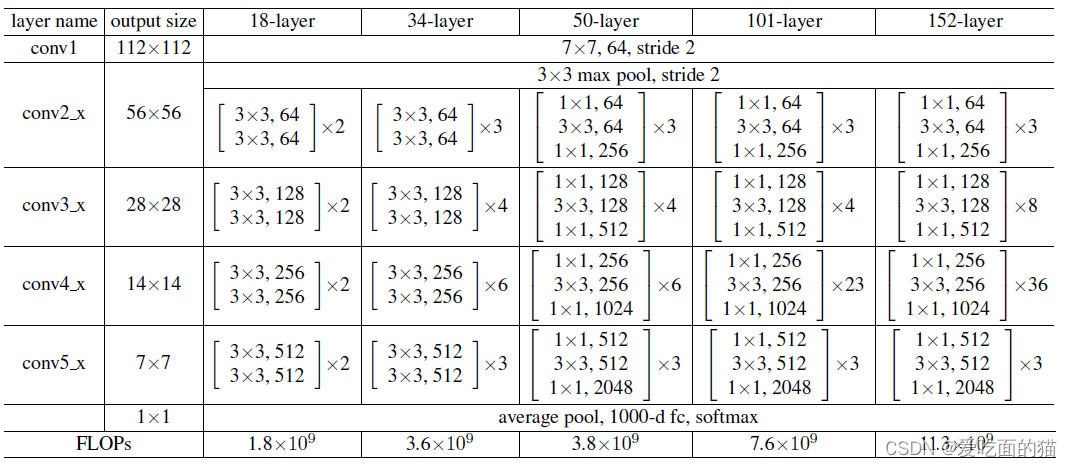
ResNet是一个基于残差块(Block)的卷积神经网络结构。它使用多个层级,每个层级包含多个残差块(Block)。构建残差块时候需要注意的是,ResNet18—ResNet152共有两种类型的Block块,一种不涉及1*1卷积网络,另外一种涉及1*1卷积网络,如下图所示:

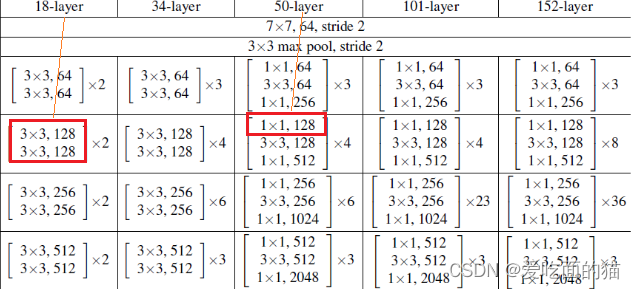
自己实现Block时候也要有涉及1*1卷积网络 和 不涉及1*1卷积网络 两种方式。
2.2.1 构建Base_Block
Base_Block类是一个神经网络的基础块,它定义了一个具有残差连接的结构,这在深度神经网络中(如ResNet)是非常常见的。这个类中不包含 1*1 的卷积,以下是该类中几个函数的主要作用:
__init__ 函数
- 作用:初始化
Base_Block对象。 - 功能:
- 接收输入通道数(
in_planes)、输出通道数(out_planes)、步长(stride)以及下采样函数(downsample)作为参数。 - 定义并初始化两个卷积层(
conv1和conv2)、两个批量归一化层(bn1和bn2)以及ReLU激活函数(relu)。其中,conv1和conv2使用 3x3 的卷积核。 - 保存传入的下采样函数(
downsample)和步长(stride)以便后续使用。
- 接收输入通道数(
forward 函数
- 作用:定义网络块的前向传播过程。
- 功能:
- 接收输入数据
x。 - 保留输入
x作为残差(res),用于后续与卷积处理后的输出相加。 - 将输入
x通过两个卷积层、两个批量归一化层以及ReLU激活函数。 - 如果提供了下采样函数,则对残差
res进行下采样,使其维度与卷积后的输出一致。 - 将卷积处理后的输出与残差
res相加,实现残差连接。 - 对相加后的结果再次应用ReLU激活函数。
- 返回前向传播的结果。
- 接收输入数据
''' # 2. 构建block: 不含有1*1 # 定义一个基础块类,继承自nn.Module,用于构建神经网络的基础结构 ''' class Base_Block(nn.Module): # 用于扩充的变量,表示扩大几倍 # 在某些网络结构中,如ResNet的Bottleneck块,可能需要通过该变量来扩充通道数 expansion = 1 def __init__(self, in_planes, out_planes, stride=1, downsample=None): # 初始化函数,传入输入通道数、输出通道数、步长以及下采样函数 ''' :param in_planes: 输入的通道数 :param planes: 输出的通道数 :param stride: 默认步长 :param downsample: 是否进行下采样 ''' # 调用父类nn.Module的初始化函数 super(Base_Block, self).__init__() # 定义网络结构 + 初始化参数 # 第一个卷积层 self.conv1 = nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False) # 第一个批量归一化层 self.bn1 = nn.BatchNorm2d(out_planes) # ReLU激活函数,inplace=True表示直接改变原始参数值,节省内存 self.relu = nn.ReLU(inplace=True) # 第二个卷积层 self.conv2 = nn.Conv2d(out_planes, out_planes, kernel_size=3, stride=1, padding=1, bias=False) # 第二个批量归一化层 self.bn2 = nn.BatchNorm2d(out_planes) # 下采样函数,用于调整输入x的维度,以便与卷积后的输出维度一致 self.downsample = downsample # 存储步长,以便后续可能用到 self.stride = stride # 定义前向传播函数 def forward(self, x): # 残差,即直接输入x,后续会与卷积处理后的输出相加 res = x # 正常传播 # 通过第一个卷积层 out = self.conv1(x) # 通过第一个批量归一化层 out = self.bn1(out) # 通过ReLU激活函数 out = self.relu(out) # 通过第二个卷积层 out = self.conv2(out) # 通过第二个批量归一化层 out = self.bn2(out) # 判断是否下采样 # 如果需要下采样,则调整残差res的维度 if self.downsample is not None: res = self.downsample(res) # 残差相加 # 将残差res与卷积处理后的输出out相加,实现残差连接 out += res # 再次通过ReLU激活函数 out = self.relu(out) # 返回结果 return out
2.2.2 构建Senior_Block
Senior_Block 类是用于构建更复杂的网络结构。类中包含1*1卷积核3*3卷积,下面是该类中几个函数的主要作用:
__init__ 初始化函数
- 作用:初始化
Senior_Block对象,设置网络层的结构和参数。 - 功能:
- 接收输入通道数(
in_planes)、中间通道数(planes)、步长(stride)以及下采样方法(downsample)作为参数。 - 定义三个卷积层(
conv1、conv2、conv3)和对应的批量归一化层(bn1、bn2、bn3)。其中,conv1和conv3使用 1x1 的卷积核,conv2使用 3x3 的卷积核。 - 定义 ReLU 激活函数(
relu)。 - 保存传入的下采样方法(
downsample)和步长(stride)以便后续使用。
- 接收输入通道数(
forward 前向传播函数
- 作用:定义网络块的前向传播过程,即数据从输入到输出的计算流程。
- 功能:
- 接收输入数据
x。 - 保留输入
x作为残差(res),用于后续与卷积处理后的输出相加。 - 将输入
x通过三个卷积层(conv1、conv2、conv3)和对应的批量归一化层(bn1、bn2、bn3),以及 ReLU 激活函数。 - 如果提供了下采样方法,则对残差
res进行下采样,使其维度与卷积后的输出一致。 - 将卷积处理后的输出与残差
res相加,实现残差连接。 - 对相加后的结果再次应用 ReLU 激活函数。
- 返回前向传播的结果。
- 接收输入数据
''' # 3. 构建Block:含有1*1 # 定义高级块类,继承自nn.Module,用于构建更复杂的网络结构 ''' class Senior_Block(nn.Module): expansion = 4 def __init__(self, in_planes, planes, stride=1, downsample=None): ''' :param in_planes: 输入通道数 :param planes: 中间通道数,最终的输出通道数还需要乘以扩大系数,即expansion :param stride: 步长 :param downsample: 下采样方法 ''' super(Senior_Block, self).__init__() self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False) self.bn1 = nn.BatchNorm2d(planes) self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(planes) self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False) self.bn3 = nn.BatchNorm2d(planes * 4) self.relu = nn.ReLU(inplace=True) self.downsample = downsample self.stride = stride def forward(self, x): # 残差 res = x # 前向传播 out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out = self.relu(out) out = self.conv3(out) out = self.bn3(out) # 是否下采样 if self.downsample is not None: res = self.downsample(x) # 相加 out += res out = self.relu(out) return out
2.2.3 构建Output_Block
Output_Block 类是用于构建神经网络的一部分。下面是该类中几个函数的主要作用:
__init__ 初始化函数
- 作用:初始化
Output_Block对象,设置网络层的结构和参数。 - 功能:
- 接收输入通道数(
in_planes)、中间通道数(planes)、步长(stride)以及块类型(block_type)作为参数。 - 定义三个卷积层(
conv1、conv2、conv3)和对应的批量归一化层(bn1、bn2、bn3)。其中,conv1和conv3使用 1x1 的卷积核,conv2使用 3x3 的卷积核。。 - 根据步长、输入通道数和块类型,判断是否需要进行下采样,并初始化下采样层(
downsample)。
- 接收输入通道数(
forward 前向传播函数
- 作用:定义网络块的前向传播过程,即数据从输入到输出的计算流程。
- 功能:
- 接收输入数据
x。 - 将输入
x通过三个卷积层(conv1、conv2、conv3)和对应的批量归一化层(bn1、bn2、bn3),并在每个卷积层之后应用 ReLU 激活函数。 - 将输入
x通过下采样层(downsample),以便与卷积处理后的输出out的维度相匹配。 - 将卷积处理后的输出
out与下采样后的输入相加,实现残差连接。 - 返回前向传播的结果。
- 接收输入数据
''' # 4. 构建输出层 # 定义输出块类,继承自nn.Module,用于构建更复杂的网络结构 ''' class Output_Block(nn.Module): # 定义扩大系数,该块最终输出的通道数将与中间通道数相同 expansion = 1 def __init__(self, in_planes, planes, stride=1, block_type='A'): # 初始化函数,传入输入通道数、中间通道数、步长以及块类型 ''' :param in_planes: 输入通道数 :param planes: 中间通道数 :param stride: 步长 :param block_type: 块类型,为'A'表示不需要下采样,为'B'则需要 ''' # 调用父类nn.Module的初始化函数 super(Output_Block, self).__init__() # 定义第一个卷积层,用于改变通道数 self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False) # 定义第一个批量归一化层 self.bn1 = nn.BatchNorm2d(planes) # 定义第二个卷积层,使用3x3的卷积核,带有2的空洞率(dilation),可以增大感受野 self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=2, bias=False, dilation=2) # 定义第二个批量归一化层 self.bn2 = nn.BatchNorm2d(planes) # 定义第三个卷积层,用于调整通道数至最终的输出通道数 self.conv3 = nn.Conv2d(planes, self.expansion * planes, kernel_size=1, bias=False) # 定义第三个批量归一化层 self.bn3 = nn.BatchNorm2d(self.expansion * planes) # 初始化下采样层,默认是一个空的序列 self.downsample = nn.Sequential() # 判断是否需要下采样,这里综合了步长、通道数以及块类型 if stride != 1 or in_planes != self.expansion * planes or block_type == 'B': # 如果需要下采样,则设置下采样层 self.downsample = nn.Sequential( # 定义一个卷积层,用于调整输入的通道数和维度 nn.Conv2d(in_planes, self.expansion * planes, kernel_size=1, stride=stride, bias=False), # 定义一个批量归一化层 nn.BatchNorm2d(self.expansion * planes) ) # 定义前向传播函数 def forward(self, x): # 通过第一个卷积层和批量归一化层,并应用ReLU激活函数 out = F.relu(self.bn1(self.conv1(x))) # 通过第二个卷积层和批量归一化层,并再次应用ReLU激活函数 out = F.relu(self.bn2(self.conv2(out))) # 通过第三个卷积层和批量归一化层 out = self.bn3(self.conv3(out)) # 将输入x通过下采样层,以便与out的维度相匹配 # 如果不需要下采样,则下采样层是一个空操作 out += self.downsample(x) # 应用ReLU激活函数 out = F.relu(out) # 返回输出结果 return out
2.2.4 构建ResNet
ResNet类定义了一个基于残差块(block)的卷积神经网络结构。它使用了多个层级(layer1至layer4)和一个输出层(layer5),以及一个平均池化层和一个最终的卷积层。下面是该类中几个函数的主要作用:
__init__ 初始化函数
- 作用:初始化
ResNet对象,设置网络的结构和参数。 - 功能:
- 设置初始通道数
self.inplanes为64。 - 定义初始卷积层
self.conv1,用于从输入图像中提取特征。 - 定义批标准化层
self.bn1和ReLU激活函数self.relu,用于处理conv1的输出。 - 定义最大池化层
self.maxpool,用于进一步减小特征图的尺寸。 - 使用
_make_layer方法创建四个层级(layer1至layer4),每个层级包含多个残差块。 - 使用
_make_out_layer方法创建输出层self.layer5。 - 定义平均池化层
self.avgpool,用于减小特征图的尺寸。 - 定义最终的卷积层
self.conv_end和批标准化层self.bn_end,用于输出层的处理。 - 初始化模型参数,使用正态分布初始化卷积层的权重,并将批标准化层的权重初始化为1,偏置初始化为0。
- 设置初始通道数
_make_layer 方法
- 作用:根据输入的
block类型、输出通道数、block数量和步长,创建并返回一个层级(layer)。 - 功能:
- 循环创建指定数量的
block对象,并将它们添加到一个nn.Sequential容器中。 - 在第一个
block中,根据步长设置是否进行下采样。 - 返回包含多个
block的层级。
- 循环创建指定数量的
_make_out_layer 方法
- 作用:创建输出层。
- 功能:
- 根据输入的通道数,定义输出层的结构。
- 输出层的具体结构在代码中没有给出,但通常会包含卷积层、批标准化层等。
forward 方法
- 作用:定义网络的前向传播过程,即从输入到输出的计算流程。
- 功能:
- 接收输入数据,并通过初始卷积层、批标准化层、ReLU激活函数和最大池化层进行处理。
- 将处理后的数据依次通过四个层级(
layer1至layer4)和输出层(layer5)。 - 通过平均池化层减小特征图的尺寸。
- 通过最终的卷积层和批标准化层进行处理,得到网络的输出。
初始化模型参数部分
- 作用:对模型中的参数进行初始化。
- 功能:
- 遍历模型中的所有模块。
- 对于卷积层,使用正态分布初始化权重,标准差根据卷积核的大小和输出通道数计算得出。
- 对于批标准化层,将权重初始化为1,偏置初始化为0。
''' # 5. 构建ResNet # 定义ResNet类,继承自nn.Module,用于构建更复杂的网络结构 ''' class ResNet(nn.Module): def __init__(self, block, layers): ''' 初始化ResNet网络。 :param block: 基本的Block块对象,如BasicBlock或Bottleneck。 :param layers: 不同层级的block数量,例如ResNet50为[3, 4, 6, 3]。 ''' super(ResNet, self).__init__() # 调用父类nn.Module的初始化方法。 # 初始通道数设置为64 self.inplanes = 64 # 初始卷积层,输入通道为3(RGB图像),输出通道为64,卷积核大小为7x7,步长为2,填充为3,无偏置。 self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False) # 批标准化层,用于conv1的输出 self.bn1 = nn.BatchNorm2d(64) # ReLU激活函数,inplace=True表示直接在原变量上进行操作,节省内存。 self.relu = nn.ReLU(inplace=True) # 最大池化层,池化核大小为3x3,步长为2,填充为1。 self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 根据输入的block和layers创建不同的层级 # 创建四个层级(layer1至layer4),每个层级包含多个残差块 self.layer1 = self._make_layer(block, 64, layers[0]) # 第一层,输出通道为64,block数量由layers[0]决定。 self.layer2 = self._make_layer(block, 128, layers[1], stride=2) # 第二层,输出通道为128,block数量由layers[1]决定,步长为2。 self.layer3 = self._make_layer(block, 256, layers[2], stride=2) # 第三层,输出通道为256,block数量由layers[2]决定,步长为2。 self.layer4 = self._make_layer(block, 512, layers[3], stride=2) # 第四层,输出通道为512,block数量由layers[3]决定,步长为2。 # 创建输出层 self.layer5 = self._make_out_layer(in_channels=2048) # 输出层的输入通道为2048。 # 平均池化层,池化核大小和步长均为2。 self.avgpool = nn.AvgPool2d(2) # 最后的卷积层,将输出通道变为30,卷积核大小为3x3,步长为1,填充为1,无偏置。 self.conv_end = nn.Conv2d(256, 30, kernel_size=3, stride=1, padding=1, bias=False) # 批标准化层,用于conv_end的输出 self.bn_end = nn.BatchNorm2d(30) # 初始化模型参数 for m in self.modules(): # 遍历模型中的所有模块 if isinstance(m, nn.Conv2d): # 如果是卷积层 n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels # 计算权重初始化的标准差 m.weight.data.normal_(0, math.sqrt(2. / n)) # 使用正态分布初始化权重 elif isinstance(m, nn.BatchNorm2d): # 如果是批标准化层 m.weight.data.fill_(1) # 权重初始化为1 m.bias.data.zero_() # 偏置初始化为0 # 根据传入的layer个数和block创建 # 输入层的构建 def _make_layer(self, block, planes, blocks, stride=1): ''' 根据给定的block类型、输出通道数、block数量和步长来创建一系列block组成的层。 :param block: 要使用的block类型,是一个类,如BasicBlock或Bottleneck :param planes: 每个block的输出通道数 :param blocks: 需要搭建的block数量 :param stride: 第一个block的卷积层步长,用于控制是否进行下采样 ''' # 初始化下采样变量,用于第一个block可能需要的下采样操作 downsample = None # 判断是否需要进行下采样 # 如果步长不为1,或者当前层的输入通道数(self.inplanes)与block输出通道数(planes * block.expansion)不匹配,则进行下采样 if stride != 1 or self.inplanes != planes * block.expansion: downsample = nn.Sequential( # 使用1x1的卷积层进行通道数转换和步长调整,使得残差连接可以相加 nn.Conv2d(self.inplanes, planes * block.expansion, kernel_size=1, stride=stride, bias=False), # 批量归一化,稳定训练过程 nn.BatchNorm2d(planes * block.expansion), ) # 初始化层的列表 layers = [] # 添加第一个block,并可能进行下采样 # 第一个block的输入通道数是self.inplanes,输出通道数是planes,步长是stride,可能包含下采样操作 layers.append(block(self.inplanes, planes, stride, downsample)) # 更新当前层的输入通道数为block的输出通道数 self.inplanes = planes * block.expansion # 添加剩余的blocks,它们的输入通道数已经是更新后的self.inplanes,输出通道数保持不变 for i in range(1, blocks): layers.append(block(self.inplanes, planes)) # 将层的列表转换为Sequential模型,便于作为神经网络的一部分进行前向传播 return nn.Sequential(*layers) # *操作符用于将列表中的元素解包为函数参数 # 输出层的构建 def _make_out_layer(self, in_channels): ''' 根据输入通道数构建输出层,包含多个Output_Block。 :param in_channels: 输入通道数 ''' # 初始化层的列表 layers = [] # 添加第一个Output_Block,并指定其输入通道数和输出通道数 # 注意:这里使用了block_type参数来区分不同的Output_Block类型 layers.append(Output_Block(in_planes=in_channels, planes=256, block_type='B')) # 添加两个相同类型的Output_Block,输入通道数和输出通道数都保持不变 layers.append(Output_Block(in_planes=256, planes=256, block_type='A')) layers.append(Output_Block(in_planes=256, planes=256, block_type='A')) # 将层的列表转换为Sequential模型 return nn.Sequential(*layers) # *操作符用于将列表中的元素解包为函数参数 def forward(self, x): # x 为网络的输入,这里的前向传播方法描述了网络如何从输入x获得最终的输出 # 经历共有的卷积和池化层 # 第一个卷积层,对输入x进行卷积操作 x = self.conv1(x) # 批量归一化层,对卷积后的结果进行归一化处理 x = self.bn1(x) # ReLU激活函数,对归一化后的结果进行非线性变换 x = self.relu(x) # 最大池化层,对激活后的结果进行下采样 x = self.maxpool(x) # 经历各个block块 # 第一个block层,对池化后的结果进行进一步的特征提取 x = self.layer1(x) # 第二个block层,继续提取特征 x = self.layer2(x) # 第三个block层 x = self.layer3(x) # 第四个block层 x = self.layer4(x) # 第五个block层,这里需要注意,通常标准的ResNet结构中只有4个layer,这里可能是自定义的扩展 x = self.layer5(x) # 经历最终的输出 # 平均池化层,对最后一个block的输出进行全局平均池化 x = self.avgpool(x) # 卷积层,对池化后的结果进行进一步的卷积变换 x = self.conv_end(x) # 批量归一化层,对卷积后的结果进行归一化处理 x = self.bn_end(x) # Sigmoid激活函数,将特征映射到0-1之间 x = F.sigmoid(x) # 归一化到0-1 # 将输出构建为正确的shape # permute函数用于改变张量的维度顺序,这里将通道维度移动到最后一个位置 # 假设输出shape原本为(-1, C, H, W),经过permute后变为(-1, H, W, C) x = x.permute(0, 2, 3, 1) # (-1,7,7,30) # 返回最终的输出x return x
2.3 定义模型
构建不同的ResNet函数。即不同的ResNet模型。如下:

# 6. 构建不同的ResNet函数 # 预训练下载链接 model_urls = { 'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth', 'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth', 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth', 'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth', 'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth', } # 构建ResNet18 def resnet18(pretrained=False, **kwargs): model = ResNet(Base_Block, [2, 2, 2, 2], **kwargs) # 是否预训练 if pretrained: model.load_state_dict(model_zoo.load_url(model_urls['resnet18'])) return model # 构建ResNet34 def resnet34(pretrained=False, **kwargs): model = ResNet(Base_Block, [3, 4, 6, 3], **kwargs) if pretrained: model.load_state_dict(model_zoo.load_url(model_urls['resnet34'])) return model # 构建ResNet50 def resnet50(pretrained=False, **kwargs): model = ResNet(Senior_Block, [3, 4, 6, 3], **kwargs) if pretrained: model.load_state_dict(model_zoo.load_url(model_urls['resnet50'])) return model # 构建ResNet101 def resnet101(pretrained=False, **kwargs): model = ResNet(Senior_Block, [3, 4, 23, 3], **kwargs) if pretrained: model.load_state_dict(model_zoo.load_url(model_urls['resnet101'])) return model # 构建ResNet152 def resnet152(pretrained=False, **kwargs): model = ResNet(Senior_Block, [3, 8, 36, 3], **kwargs) if pretrained: model.load_state_dict(model_zoo.load_url(model_urls['resnet152'])) return model
2.4 完整代码
Yolo_ResNet卷积神经网络
'' ''' # 1. 导入所需要的包 ''' import torch import math from torch import nn import torch.utils.model_zoo as model_zoo import torch.nn.functional as F ''' # 2. 构建block: 不含有1*1 # 定义一个基础块类,继承自nn.Module,用于构建神经网络的基础结构 ''' class Base_Block(nn.Module): # 用于扩充的变量,表示扩大几倍 # 在某些网络结构中,如ResNet的Bottleneck块,可能需要通过该变量来扩充通道数 expansion = 1 def __init__(self, in_planes, out_planes, stride=1, downsample=None): # 初始化函数,传入输入通道数、输出通道数、步长以及下采样函数 ''' :param in_planes: 输入的通道数 :param planes: 输出的通道数 :param stride: 默认步长 :param downsample: 是否进行下采样 ''' # 调用父类nn.Module的初始化函数 super(Base_Block, self).__init__() # 定义网络结构 + 初始化参数 # 第一个卷积层 self.conv1 = nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False) # 第一个批量归一化层 self.bn1 = nn.BatchNorm2d(out_planes) # ReLU激活函数,inplace=True表示直接改变原始参数值,节省内存 self.relu = nn.ReLU(inplace=True) # 第二个卷积层 self.conv2 = nn.Conv2d(out_planes, out_planes, kernel_size=3, stride=1, padding=1, bias=False) # 第二个批量归一化层 self.bn2 = nn.BatchNorm2d(out_planes) # 下采样函数,用于调整输入x的维度,以便与卷积后的输出维度一致 self.downsample = downsample # 存储步长,以便后续可能用到 self.stride = stride # 定义前向传播函数 def forward(self, x): # 残差,即直接输入x,后续会与卷积处理后的输出相加 res = x # 正常传播 # 通过第一个卷积层 out = self.conv1(x) # 通过第一个批量归一化层 out = self.bn1(out) # 通过ReLU激活函数 out = self.relu(out) # 通过第二个卷积层 out = self.conv2(out) # 通过第二个批量归一化层 out = self.bn2(out) # 判断是否下采样 # 如果需要下采样,则调整残差res的维度 if self.downsample is not None: res = self.downsample(res) # 残差相加 # 将残差res与卷积处理后的输出out相加,实现残差连接 out += res # 再次通过ReLU激活函数 out = self.relu(out) # 返回结果 return out ''' # 3. 构建Block:含有1*1 # 定义高级块类,继承自nn.Module,用于构建更复杂的网络结构 ''' class Senior_Block(nn.Module): expansion = 4 def __init__(self, in_planes, planes, stride=1, downsample=None): ''' :param in_planes: 输入通道数 :param planes: 中间通道数,最终的输出通道数还需要乘以扩大系数,即expansion :param stride: 步长 :param downsample: 下采样方法 ''' super(Senior_Block, self).__init__() self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False) self.bn1 = nn.BatchNorm2d(planes) self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(planes) self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False) self.bn3 = nn.BatchNorm2d(planes * 4) self.relu = nn.ReLU(inplace=True) self.downsample = downsample self.stride = stride def forward(self, x): # 残差 res = x # 前向传播 out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out = self.relu(out) out = self.conv3(out) out = self.bn3(out) # 是否下采样 if self.downsample is not None: res = self.downsample(x) # 相加 out += res out = self.relu(out) return out ''' # 4. 构建输出层 # 定义输出块类,继承自nn.Module,用于构建更复杂的网络结构 ''' class Output_Block(nn.Module): # 定义扩大系数,该块最终输出的通道数将与中间通道数相同 expansion = 1 def __init__(self, in_planes, planes, stride=1, block_type='A'): # 初始化函数,传入输入通道数、中间通道数、步长以及块类型 ''' :param in_planes: 输入通道数 :param planes: 中间通道数 :param stride: 步长 :param block_type: 块类型,为'A'表示不需要下采样,为'B'则需要 ''' # 调用父类nn.Module的初始化函数 super(Output_Block, self).__init__() # 定义第一个卷积层,用于改变通道数 self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False) # 定义第一个批量归一化层 self.bn1 = nn.BatchNorm2d(planes) # 定义第二个卷积层,使用3x3的卷积核,带有2的空洞率(dilation),可以增大感受野 self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=2, bias=False, dilation=2) # 定义第二个批量归一化层 self.bn2 = nn.BatchNorm2d(planes) # 定义第三个卷积层,用于调整通道数至最终的输出通道数 self.conv3 = nn.Conv2d(planes, self.expansion * planes, kernel_size=1, bias=False) # 定义第三个批量归一化层 self.bn3 = nn.BatchNorm2d(self.expansion * planes) # 初始化下采样层,默认是一个空的序列 self.downsample = nn.Sequential() # 判断是否需要下采样,这里综合了步长、通道数以及块类型 if stride != 1 or in_planes != self.expansion * planes or block_type == 'B': # 如果需要下采样,则设置下采样层 self.downsample = nn.Sequential( # 定义一个卷积层,用于调整输入的通道数和维度 nn.Conv2d(in_planes, self.expansion * planes, kernel_size=1, stride=stride, bias=False), # 定义一个批量归一化层 nn.BatchNorm2d(self.expansion * planes) ) # 定义前向传播函数 def forward(self, x): # 通过第一个卷积层和批量归一化层,并应用ReLU激活函数 out = F.relu(self.bn1(self.conv1(x))) # 通过第二个卷积层和批量归一化层,并再次应用ReLU激活函数 out = F.relu(self.bn2(self.conv2(out))) # 通过第三个卷积层和批量归一化层 out = self.bn3(self.conv3(out)) # 将输入x通过下采样层,以便与out的维度相匹配 # 如果不需要下采样,则下采样层是一个空操作 out += self.downsample(x) # 应用ReLU激活函数 out = F.relu(out) # 返回输出结果 return out ''' # 5. 构建ResNet # 定义ResNet类,继承自nn.Module,用于构建更复杂的网络结构 ''' class ResNet(nn.Module): def __init__(self, block, layers): ''' 初始化ResNet网络。 :param block: 基本的Block块对象,如BasicBlock或Bottleneck。 :param layers: 不同层级的block数量,例如ResNet50为[3, 4, 6, 3]。 ''' super(ResNet, self).__init__() # 调用父类nn.Module的初始化方法。 # 初始通道数设置为64 self.inplanes = 64 # 初始卷积层,输入通道为3(RGB图像),输出通道为64,卷积核大小为7x7,步长为2,填充为3,无偏置。 self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False) # 批标准化层,用于conv1的输出 self.bn1 = nn.BatchNorm2d(64) # ReLU激活函数,inplace=True表示直接在原变量上进行操作,节省内存。 self.relu = nn.ReLU(inplace=True) # 最大池化层,池化核大小为3x3,步长为2,填充为1。 self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 根据输入的block和layers创建不同的层级 # 创建四个层级(layer1至layer4),每个层级包含多个残差块 self.layer1 = self._make_layer(block, 64, layers[0]) # 第一层,输出通道为64,block数量由layers[0]决定。 self.layer2 = self._make_layer(block, 128, layers[1], stride=2) # 第二层,输出通道为128,block数量由layers[1]决定,步长为2。 self.layer3 = self._make_layer(block, 256, layers[2], stride=2) # 第三层,输出通道为256,block数量由layers[2]决定,步长为2。 self.layer4 = self._make_layer(block, 512, layers[3], stride=2) # 第四层,输出通道为512,block数量由layers[3]决定,步长为2。 # 创建输出层 self.layer5 = self._make_out_layer(in_channels=2048) # 输出层的输入通道为2048。 # 平均池化层,池化核大小和步长均为2。 self.avgpool = nn.AvgPool2d(2) # 最后的卷积层,将输出通道变为30,卷积核大小为3x3,步长为1,填充为1,无偏置。 self.conv_end = nn.Conv2d(256, 30, kernel_size=3, stride=1, padding=1, bias=False) # 批标准化层,用于conv_end的输出 self.bn_end = nn.BatchNorm2d(30) # 初始化模型参数 for m in self.modules(): # 遍历模型中的所有模块 if isinstance(m, nn.Conv2d): # 如果是卷积层 n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels # 计算权重初始化的标准差 m.weight.data.normal_(0, math.sqrt(2. / n)) # 使用正态分布初始化权重 elif isinstance(m, nn.BatchNorm2d): # 如果是批标准化层 m.weight.data.fill_(1) # 权重初始化为1 m.bias.data.zero_() # 偏置初始化为0 # 根据传入的layer个数和block创建 # 输入层的构建 def _make_layer(self, block, planes, blocks, stride=1): ''' 根据给定的block类型、输出通道数、block数量和步长来创建一系列block组成的层。 :param block: 要使用的block类型,是一个类,如BasicBlock或Bottleneck :param planes: 每个block的输出通道数 :param blocks: 需要搭建的block数量 :param stride: 第一个block的卷积层步长,用于控制是否进行下采样 ''' # 初始化下采样变量,用于第一个block可能需要的下采样操作 downsample = None # 判断是否需要进行下采样 # 如果步长不为1,或者当前层的输入通道数(self.inplanes)与block输出通道数(planes * block.expansion)不匹配,则进行下采样 if stride != 1 or self.inplanes != planes * block.expansion: downsample = nn.Sequential( # 使用1x1的卷积层进行通道数转换和步长调整,使得残差连接可以相加 nn.Conv2d(self.inplanes, planes * block.expansion, kernel_size=1, stride=stride, bias=False), # 批量归一化,稳定训练过程 nn.BatchNorm2d(planes * block.expansion), ) # 初始化层的列表 layers = [] # 添加第一个block,并可能进行下采样 # 第一个block的输入通道数是self.inplanes,输出通道数是planes,步长是stride,可能包含下采样操作 layers.append(block(self.inplanes, planes, stride, downsample)) # 更新当前层的输入通道数为block的输出通道数 self.inplanes = planes * block.expansion # 添加剩余的blocks,它们的输入通道数已经是更新后的self.inplanes,输出通道数保持不变 for i in range(1, blocks): layers.append(block(self.inplanes, planes)) # 将层的列表转换为Sequential模型,便于作为神经网络的一部分进行前向传播 return nn.Sequential(*layers) # *操作符用于将列表中的元素解包为函数参数 # 输出层的构建 def _make_out_layer(self, in_channels): ''' 根据输入通道数构建输出层,包含多个Output_Block。 :param in_channels: 输入通道数 ''' # 初始化层的列表 layers = [] # 添加第一个Output_Block,并指定其输入通道数和输出通道数 # 注意:这里使用了block_type参数来区分不同的Output_Block类型 layers.append(Output_Block(in_planes=in_channels, planes=256, block_type='B')) # 添加两个相同类型的Output_Block,输入通道数和输出通道数都保持不变 layers.append(Output_Block(in_planes=256, planes=256, block_type='A')) layers.append(Output_Block(in_planes=256, planes=256, block_type='A')) # 将层的列表转换为Sequential模型 return nn.Sequential(*layers) # *操作符用于将列表中的元素解包为函数参数 def forward(self, x): # x 为网络的输入,这里的前向传播方法描述了网络如何从输入x获得最终的输出 # 经历共有的卷积和池化层 # 第一个卷积层,对输入x进行卷积操作 x = self.conv1(x) # 批量归一化层,对卷积后的结果进行归一化处理 x = self.bn1(x) # ReLU激活函数,对归一化后的结果进行非线性变换 x = self.relu(x) # 最大池化层,对激活后的结果进行下采样 x = self.maxpool(x) # 经历各个block块 # 第一个block层,对池化后的结果进行进一步的特征提取 x = self.layer1(x) # 第二个block层,继续提取特征 x = self.layer2(x) # 第三个block层 x = self.layer3(x) # 第四个block层 x = self.layer4(x) # 第五个block层,这里需要注意,通常标准的ResNet结构中只有4个layer,这里可能是自定义的扩展 x = self.layer5(x) # 经历最终的输出 # 平均池化层,对最后一个block的输出进行全局平均池化 x = self.avgpool(x) # 卷积层,对池化后的结果进行进一步的卷积变换 x = self.conv_end(x) # 批量归一化层,对卷积后的结果进行归一化处理 x = self.bn_end(x) # Sigmoid激活函数,将特征映射到0-1之间 x = F.sigmoid(x) # 归一化到0-1 # 将输出构建为正确的shape # permute函数用于改变张量的维度顺序,这里将通道维度移动到最后一个位置 # 假设输出shape原本为(-1, C, H, W),经过permute后变为(-1, H, W, C) x = x.permute(0, 2, 3, 1) # (-1,7,7,30) # 返回最终的输出x return x # 6. 构建不同的ResNet函数 # 预训练下载链接 model_urls = { 'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth', 'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth', 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth', 'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth', 'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth', } # 构建ResNet18 def resnet18(pretrained=False, **kwargs): model = ResNet(Base_Block, [2, 2, 2, 2], **kwargs) # 是否预训练 if pretrained: model.load_state_dict(model_zoo.load_url(model_urls['resnet18'])) return model # 构建ResNet34 def resnet34(pretrained=False, **kwargs): model = ResNet(Base_Block, [3, 4, 6, 3], **kwargs) if pretrained: model.load_state_dict(model_zoo.load_url(model_urls['resnet34'])) return model # 构建ResNet50 def resnet50(pretrained=False, **kwargs): model = ResNet(Senior_Block, [3, 4, 6, 3], **kwargs) if pretrained: model.load_state_dict(model_zoo.load_url(model_urls['resnet50'])) return model # 构建ResNet101 def resnet101(pretrained=False, **kwargs): model = ResNet(Senior_Block, [3, 4, 23, 3], **kwargs) if pretrained: model.load_state_dict(model_zoo.load_url(model_urls['resnet101'])) return model # 构建ResNet152 def resnet152(pretrained=False, **kwargs): model = ResNet(Senior_Block, [3, 8, 36, 3], **kwargs) if pretrained: model.load_state_dict(model_zoo.load_url(model_urls['resnet152'])) return model
3、定义损失
在创建的目录结构 network 中创建Yolo_Loss.py文件,用于创建损失。
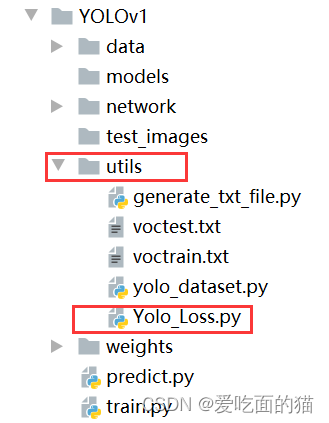
YOLO的损失函数通常包括以下几个部分:
- 定位损失(Localization Loss):即长宽损失和坐标损失,用于衡量模型预测的目标边界框与真实边界框之间的差异。这通常使用均方误差(MSE)或其他类似的回归损失函数来计算。定位损失关注于边界框的中心点坐标(x, y)、宽度(w)和高度(h)的预测精度。
- 置信度损失(Confidence Loss):用于衡量模型预测的目标置信度与真实置信度之间的差异。置信度表示模型对预测目标存在的信心程度。对于每个边界框,模型会预测一个置信度分数,这个分数与真实标签(目标存在与否)进行比较,计算损失。
- 分类损失(Classification Loss):用于衡量模型预测的目标类别与真实类别之间的差异。这通常使用交叉熵损失函数来计算。对于每个目标,模型会预测一个类别概率分布,这个分布与真实标签进行比较,计算损失。
在YOLO的损失函数中,这些部分通常会根据它们的重要性进行加权。例如,由于定位的准确性对于目标检测至关重要,因此定位损失通常会赋予较高的权重。而置信度损失和分类损失的权重则可以根据具体任务进行调整。
此外,YOLO的损失函数还需要考虑如何处理没有目标的背景区域。这通常通过在损失函数中加入一个额外的项来实现,该项用于惩罚模型在背景区域产生高置信度的预测。
总的来说,YOLO的损失函数是一个综合了定位、置信度和分类损失的复合函数,旨在全面地衡量模型在目标检测任务上的性能。通过优化这个损失函数,我们可以训练出更加准确和鲁棒的目标检测模型。

# 1. 导包 import torch import torch.nn as nn import torch.nn.functional as F from torch.autograd import Variable # 2. 损失函数类 class Yolo_Loss(nn.Module): def __init__(self, S=7, B=2, l_coord=5, l_noobj=0.5): ''' :param S: Yolov1论文中的S,即划分的网格,默认为7 :param B: Yolov1论文中的B,即多少个框预测,默认为2 :param l_coord: 损失函数中的超参数,默认为5 :param l_noobj: 同上,默认为0.5 ''' super(Yolo_Loss, self).__init__() # 初始化各个参数 self.S = S self.B = B self.l_coord = l_coord self.l_noobj = l_noobj # 前向传播 def forward(self, pred_tensor, target_tensor): # 获取batchsize大小 ,即每批次数据的个数 N = pred_tensor.size()[0] # target_tensor[:, :, :, 4]是目标张量中用于标记 目标 是否存在的部分(通常第五列是置信度或目标存在标志)。 # 这行代码生成一个布尔掩码,其中值为True的位置表示对应网格中存在目标,值为False则表示不存在。 # 具有目标标签的索引值,此时shape为[batch,7,7] coo_mask = target_tensor[:, :, :, 4] > 0 # 与上一行相反,这行代码生成一个布尔掩码,表示哪些网格中没有目标。 # 不具有目标的标签索引值,此时shape为[batch,7,7] noo_mask = target_tensor[:, :, :, 4] == 0 # unsqueeze(-1)在最后一个维度上增加一个维度,使得coo_mask的形状从[batch, 7, 7]变为[batch, 7, 7, 1]。 # expand_as(target_tensor)将这个新维度扩展至与target_tensor相同的形状,这样便于后续操作。 # 将shape变为[batch,7,7,30] coo_mask = coo_mask.unsqueeze(-1).expand_as(target_tensor) # 同上,对noo_mask也进行相同的操作。 noo_mask = noo_mask.unsqueeze(-1).expand_as(target_tensor) # 使用coo_mask从pred_tensor中索引出存在目标的预测值,然后通过view操作改变形状,使得每个存在目标的预测框成为一个长度为30的向量。 # 获取预测值中包含对象的所有点(共7*7个点),并转为[x,30]的形式,其中x表示有多少点中的框包含有对象 coo_pred = pred_tensor[coo_mask].view(-1, 30) # 对上面获取的值进行处理 # 从coo_pred中取前10个元素(对应预测框的坐标和宽度高度信息),然后改变形状为[2x, 5],其中x表示存在目标的网格数量。 # 1. 转为box形式:box[x1,y1,w1,h1,c1],shape为[2x,5],因为每个单元格/点有两个预测框 box_pred = coo_pred[:, :10].contiguous().view(-1, 5) # 从coo_pred中取后20个元素(对应类别预测信息)。 # 2. 转为class信息,即30中后面的20个值 class_pred = coo_pred[:, 10:] # 对目标张量进行与预测张量相同的操作,获取存在目标的真实值。 # 同理,对真实值进行操作,方便对比计算损失值 coo_target = target_tensor[coo_mask].view(-1, 30) # 从coo_target中取出坐标和宽度高度信息。 box_target = coo_target[:, :10].contiguous().view(-1, 5) # 从coo_target中取出类别信息。 class_target = coo_target[:, 10:] # 同上的操作,获取不包含对象的预测值、真实值 # 使用noo_mask从pred_tensor中索引出不存在目标的预测值,并改变形状。 noo_pred = pred_tensor[noo_mask].view(-1, 30) # 对目标张量执行相同的操作,获取不存在目标的真实值。 noo_target = target_tensor[noo_mask].view(-1, 30) # 注意:上述代码只是将预测值和真实值进行了预处理,以便后续计算损失。实际损失的计算(比如坐标损失、置信度损失和类别损失)在这段代码之后,通常还需要根据YOLO的具体定义来编写。 # 不包含物体grid ceil的置信度损失:即图中的D部分 # 这部分代码计算的是那些不包含目标物体的网格中预测框的置信度损失。 # 1. 自己创建一个索引 # 创建一个与noo_pred形状相同的全零的ByteTensor(布尔掩码),用于标识需要计算的预测框置信度。 noo_pred_mask = torch.cuda.ByteTensor(noo_pred.size()) # 将这个掩码的所有元素初始化为0(即False),意味着初始时所有预测框的置信度都不被考虑。 noo_pred_mask.zero_() # 将全部元素变为Flase的意思 # 2. 将其它位置的索引置为0,唯独两个框的置信度位置变为1 # 将所有网格中第一个预测框的置信度位置(索引为4,因为通常置信度是预测框向量的最后一个元素,且前面有4个坐标值)设置为1。 noo_pred_mask[:, 4] = 1 # 将所有网格中第二个预测框的置信度位置(索引为9,因为每个网格有两个预测框,每个预测框有5个值:4个坐标和1个置信度)设置为1。 noo_pred_mask[:, 9] = 1 # 3. 获取对应的值 # 使用上面创建的掩码从noo_pred中提取出所有预测框的置信度值。 noo_pred_c = noo_pred[noo_pred_mask] # noo pred只需要计算 c 的损失 size[-1,2] # 同样地,使用相同的掩码从noo_target中提取出目标置信度值,用于与预测值比较。 noo_target_c = noo_target[noo_pred_mask] # 4. 计算损失值:均方误差 # 使用均方误差(Mean Squared Error, MSE)计算预测置信度与目标置信度之间的差异,作为不包含物体网格的置信度损失。 nooobj_loss = F.mse_loss(noo_pred_c, noo_target_c, size_average=False) # 计算包含物体的损失值 # 创建几个全为False/0的变量,用于后期存储值 # 创建一个与box_target形状相同的全零的ByteTensor,用于标识负责预测物体的网格中的预测框。 coo_response_mask = torch.cuda.ByteTensor(box_target.size()) # 负责预测框 # 将这个掩码的所有元素初始化为0。 coo_response_mask.zero_() # 创建一个与box_target形状相同的全零的ByteTensor,用于标识不负责预测物体的网格中的预测框。 coo_not_response_mask = torch.cuda.ByteTensor(box_target.size()) # 不负责预测的框的索引(因为一个cell两个预测框,而只有IOU最大的负责索引) # 将这个掩码的所有元素初始化为0。 coo_not_response_mask.zero_() # 创建一个与box_target形状相同的全零的Tensor,用于存放每个预测框与目标框之间的IOU(交并比)值。这个值在后续计算损失时会用到。 box_target_iou = torch.zeros(box_target.size()).cuda() # 具体的IOU值存放处 # 由于一个单元格两个预测框,因此step=2 # 在YOLO系列算法中,每个网格单元通常预测固定数量的预测框。这里假设每个单元有两个预测框,因此迭代步长为2。 # 遍历所有目标框,因为每个目标框与一个单元格关联,且每个单元格有两个预测框。 # 选择具有最佳IOU的预测框。 for i in range(0, box_target.size()[0], 2): # choose the best iou box # 获取预测值中的两个box # 从预测框集合中取出当前单元格的两个预测框。这里box1是一个包含两个预测框的tensor,每个预测框有五个值:[x, y, w, h, c],分别代表中心坐标、宽度、高度和置信度。 box1 = box_pred[i:i + 2] # [x,y,w,h,c] # 创建一个临时变量box1形状相同的tensor,用于存放左上角和右下角角坐标值,因为计算IOU需要 box1_xyxy = Variable(torch.FloatTensor(box1.size())) # 将预测框的中心坐标和宽高转换为左上角和右下角的坐标,并进行归一化处理。self.S通常表示网格的大小,比如7x7的网格。 box1_xyxy[:, :2] = box1[:, :2] / float(self.S) - 0.5 * box1[:, 2:4] # 原本(xc,yc)为7*7 所以要除以7 # 同样地,计算预测框的右下角坐标。 box1_xyxy[:, 2:4] = box1[:, :2] / float(self.S) + 0.5 * box1[:, 2:4] # 用同样的思路对真实值进行处理,不过不同的是真实值一个对象只有一个框 # 从目标框集合中取出与当前单元格关联的目标框,并将其reshape为[-1, 5]的形式。 box2 = box_target[i].view(-1, 5) # 创建一个与目标框形状相同的tensor,用于存放左上角和右下角坐标形式的目标框。 box2_xyxy = Variable(torch.FloatTensor(box2.size())) # 将目标框的中心坐标和宽高转换为左上角和右下角的坐标,并进行归一化处理。 box2_xyxy[:, :2] = box2[:, :2] / float(self.S) - 0.5 * box2[:, 2:4] # 计算目标框的右下角坐标。 box2_xyxy[:, 2:4] = box2[:, :2] / float(self.S) + 0.5 * box2[:, 2:4] # 计算两者的IOU # 调用compute_iou函数计算两个预测框与目标框之间的IOU值。这里box1_xyxy[:, :4]包含两个预测框的坐标,box2_xyxy[:, :4]包含一个目标框的坐标。 iou = self.compute_iou(box1_xyxy[:, :4], box2_xyxy[:, :4]) # 前者shape为[2,4],后者为[1,4] # 获取两者IOU最大的值(max_iou)和对应的索引(max_index),因为一个cell有两个预测框,一般而言取IOU最大的作为预测框 max_iou, max_index = iou.max(0) # 将索引移至GPU上(如果之前不在GPU上的话)。 max_index = max_index.data.cuda() # 将IOU最大的索引设置为1,即表示这个框负责预测 coo_response_mask[i + max_index] = 1 # 将box_target_iou转为PyTorch的Variable,并移到GPU上(如果有的话),以支持自动微分。 box_target_iou = Variable(box_target_iou).cuda() # 获取负责预测框的值、IOU值和真实框的值 # 从box_pred中筛选出负责预测的框(即IOU最大的框),并改变其形状为[-1, 5]。 box_pred_response = box_pred[coo_response_mask].view(-1, 5) # 从box_target_iou中筛选出负责预测的框的IOU值,并改变其形状。 box_target_response_iou = box_target_iou[coo_response_mask].view(-1, 5) # 从box_target中筛选出负责预测的框的真实值,并改变其形状。 box_target_response = box_target[coo_response_mask].view(-1, 5) # 这个对应的是图中的部分C,负责预测框的损失 # 计算负责预测框的置信度损失,使用均方误差损失函数(MSE Loss)。 contain_loss = F.mse_loss(box_pred_response[:, 4], box_target_response_iou[:, 4], size_average=False) # 1. 计算坐标损失,即图中的A和B部分 # 计算负责预测框的坐标损失,包括中心坐标和宽高的损失。注意,宽高损失计算时使用了开方,这通常是为了改善损失函数的性能。 loc_loss = F.mse_loss(box_pred_response[:, :2], box_target_response[:, :2], size_average=False) + F.mse_loss( torch.sqrt(box_pred_response[:, 2:4]), torch.sqrt(box_target_response[:, 2:4]), size_average=False) # 获取不负责预测框的值、真实值 # 从box_pred中筛选出不负责预测的框,并改变其形状。 box_pred_not_response = box_pred[coo_not_response_mask].view(-1, 5) # 从box_target中筛选出不负责预测的框的真实值,并改变其形状。 box_target_not_response = box_target[coo_not_response_mask].view(-1, 5) # 将不负责预测框的置信度真实值设为0,因为这些框不应包含任何对象。 box_target_not_response[:, 4] = 0 # 将真实值置为0 # 2. 计算不负责预测框的损失值,即图中的部分C # 计算不负责预测框的置信度损失。 not_contain_loss = F.mse_loss(box_pred_not_response[:, 4], box_target_not_response[:, 4], size_average=False) # 3. 类别损失,即图中的E部分 # 计算类别损失,使用均方误差损失函数。 class_loss = F.mse_loss(class_pred, class_target, size_average=False) # 返回总损失,它是坐标损失、负责预测框的置信度损失、不负责预测框的置信度损失、类别损失以及一个未显示的`nooobj_loss`的加权和,最后除以N进行归一化。 return (self.l_coord * loc_loss + contain_loss + not_contain_loss + self.l_noobj * nooobj_loss + class_loss) / N # 计算IOU的函数 def compute_iou(self, box1, box2): ''' :param box1: 预测的box,一般为[2,4] :param box2: 真实的box,一般为[1,4] :return: ''' # 获取各box个数 N = box1.size(0) M = box2.size(0) # 计算两者中左上角左边较大的 lt = torch.max( box1[:, :2].unsqueeze(1).expand(N, M, 2), # [N,2] -> [N,1,2] -> [N,M,2] box2[:, :2].unsqueeze(0).expand(N, M, 2), # [M,2] -> [1,M,2] -> [N,M,2] ) # 计算两者右下角左边较小的 rb = torch.min( box1[:, 2:].unsqueeze(1).expand(N, M, 2), # [N,2] -> [N,1,2] -> [N,M,2] box2[:, 2:].unsqueeze(0).expand(N, M, 2), # [M,2] -> [1,M,2] -> [N,M,2] ) # 计算两者相交部分的长、宽 wh = rb - lt # [N,M,2] # 如果长、宽中有小于0的,表示可能没有相交趋于,置为0即可 wh[wh < 0] = 0 # clip at 0 inter = wh[:, :, 0] * wh[:, :, 1] # [N,M] # 计算各个的面积 # box1的面积 area1 = (box1[:, 2] - box1[:, 0]) * (box1[:, 3] - box1[:, 1]) # [N,] # box2的面积 area2 = (box2[:, 2] - box2[:, 0]) * (box2[:, 3] - box2[:, 1]) # [M,] area1 = area1.unsqueeze(1).expand_as(inter) # [N,] -> [N,1] -> [N,M] area2 = area2.unsqueeze(0).expand_as(inter) # [M,] -> [1,M] -> [N,M] # IOu值,交集除以并集,其中并集为两者的面积和减去交集部分 iou = inter / (area1 + area2 - inter) return iou
4、定义训练过程
在创建的目录结构 network 中创建train.py文件,用于进行训练。
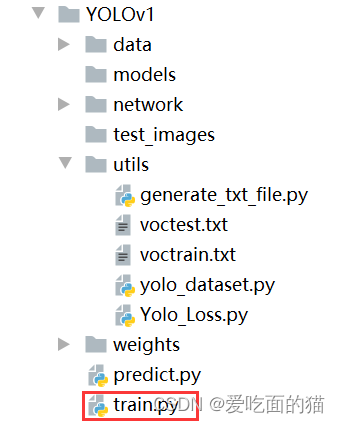
- 导入所需的包
- 定义基本参数
- 创建模型并使用预训练参数
- 损失函数,优化器,并将模型、损失函数放入GPU中
- 加载数据
- 训练:循环50次,第20和第35次调整学习率,每次对数据集中按批次执行训练和验证
# 1. 导入所需的包 import warnings from YOLOv1.network.Yolo_ResNet import resnet50 from YOLOv1.utils.yolo_dataset import Yolo_Dataset from YOLOv1_pytorch.utils.Yolo_Loss import Yolo_Loss warnings.filterwarnings("ignore") from tqdm import tqdm import torch from torch.utils.data import DataLoader import torchvision.transforms as T from torchvision import models # 2. 定义基本参数 device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') batch_size = 2 # 根据自己的电脑设定 epochs = 50 lr = 0.01 file_root = './data/VOC2012/JPEGImages/' # 需要根据的实际路径修改 # 3. 创建模型并使用预训练参数 pytorch_resnet = models.resnet50(pretrained=True) # 官方的resnet50预训练模型 model = resnet50() # 创建自己的resnet50, # 接下来就是让自己的模型去继承官方的权重参数 pytorch_state_dict = pytorch_resnet.state_dict() model_state_dict = model.state_dict() for k in pytorch_state_dict.keys(): # 调试: 看看模型哪些有没有问题 # print(k) # 如果自己的模型和官方的模型key相同,并且不是fc层,则继承过来 if k in model_state_dict.keys() and not k.startswith('fc'): model_state_dict[k] = pytorch_state_dict[k] # 4. 损失函数,优化器,并将模型、损失函数放入GPU中 loss = Yolo_Loss() optimizer = torch.optim.SGD(model.parameters(),lr=lr,momentum=0.9,weight_decay=5e-4) model.to(device) loss.to(device) # 5. 加载数据 train_dataset = Yolo_Dataset(root=file_root, list_file='./utils/voctrain.txt', train=True, transforms = [T.ToTensor()]) train_loader = DataLoader(train_dataset,batch_size=batch_size,shuffle=True,drop_last=True) test_dataset = Yolo_Dataset(root=file_root, list_file='./utils/voctest.txt', train=False, transforms = [T.ToTensor()]) test_loader = DataLoader(test_dataset,batch_size=batch_size,shuffle=True,drop_last=True) # 6. 训练 # 打印一些基本的信息 print('starting train the model') print('the train_dataset has %d images' % len(train_dataset)) print('the batch_size is ',batch_size) # 定义一个最佳损失值 best_test_loss = 0 # 开始训练 for e in range(epochs): model.train() # 调整学习率 if e == 20: print('change the lr') optimizer.param_groups[0]['lr'] /= 10 if e == 35: print('change the lr') optimizer.param_groups[0]['lr'] /= 10 # 进度条显示 tqdm_tarin = tqdm(train_loader) # 定义损失变量 total_loss = 0. for i,(images,target) in enumerate(tqdm_tarin): # 将变量放入设备中 images,target = images.to(device),target.to(device) # 训练--损失等 pred = model(images) loss_value = loss(pred,target) total_loss += loss_value.item() #在开始新的梯度计算之前,调用优化器的zero_grad()方法将模型参数的梯度清零。这是因为在PyTorch中,梯度是累积的,如果不清零,新的梯度会累加到旧的梯度上。 optimizer.zero_grad() #对损失值loss_value调用backward()方法,计算损失相对于模型参数的梯度。这些梯度将被用于接下来的参数更新步骤。 loss_value.backward() #调用优化器的step()方法,根据计算出的梯度更新模型的参数。这一步是模型训练的关键,它使得模型在训练过程中逐渐优化。 optimizer.step() # 打印一下损失值 if (i+1) % 5 == 0: tqdm_tarin.desc = 'train epoch[{}/{}] loss:{:.6f}'.format(e+1,epochs,total_loss/(i+1)) # 启用验证模式 model.eval() validation_loss = 0.0 tqdm_test = tqdm(test_loader) for i, (images, target) in enumerate(tqdm_test): images, target = images.to(device),target.to(device) pred = model(images) loss_value = loss(pred, target) validation_loss += loss_value.item() validation_loss /= len(test_loader) # 显示验证集的损失值 print('In the test step,the average loss is %.6f' % validation_loss) # 如果最佳损失值大于验证集的损失,意味着当前训练很好 # 这一点需要设置好最佳的损失值,不容易设置 # 是否启用看大家心情 # if best_test_loss > validation_loss: # best_test_loss = validation_loss # print('get best test loss %.5f' % best_test_loss) # torch.save(model.state_dict(), './weights/best.pth') # 记得最后保存参数 torch.save(model.state_dict(), './weights/yolo.pth')
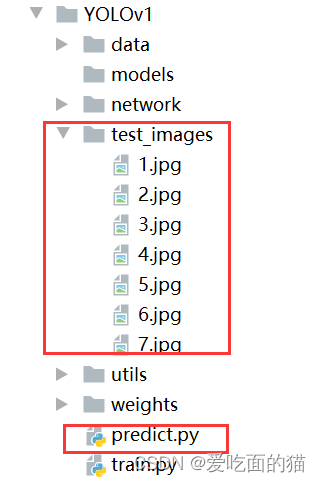
5、定义预测方法
在创建的目录结构 network 中创建predict.py文件,用于进行预测。同时在目录test_images中存入预测的图片(在最下面,自己进行保存,并进行命名为1、2、3、4、5、6)
# author: baiCai # 1. 导包 import os import random import torch from torch.autograd import Variable import torchvision.transforms as transforms import cv2 from matplotlib import pyplot as plt import numpy as np import warnings from YOLOv1_pytorch.network.My_ResNet import resnet50 warnings.filterwarnings('ignore') # 2. 定义一些基本的参数 # 类别索引 VOC_CLASSES = ( 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor') # 画矩形框的时候用到的颜色变量 Color = [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0], [0, 0, 128], [128, 0, 128], [0, 128, 128], [128, 128, 128], [64, 0, 0], [192, 0, 0], [64, 128, 0], [192, 128, 0], [64, 0, 128], [192, 0, 128], [64, 128, 128], [192, 128, 128], [0, 64, 0], [128, 64, 0], [0, 192, 0], [128, 192, 0], [0, 64, 128]] # 3. 解码函数 def decoder(pred): ''' :param pred: batchx7x7x30,但是预测的时候一般一张图片一张的放,因此batch=1 :return: box[[x1,y1,x2,y2]] label[...] ''' # 定义一些基本的参数 grid_num = 7 # 网格划分标准大小 #初始化三个空列表,用于存储解码后的边界框坐标、类别索引和对应的概率值。 boxes=[] cls_indexs=[] probs = [] #计算网格单元的大小(或称为缩放因子),这对于将模型输出的坐标从网格空间转换到图像空间是必要的。 cell_size = 1./grid_num # 缩放因子 # 获取一些值 pred = pred.data # 预测值的数据:1*7*7*30 pred = pred.squeeze(0) # 预测值的数据:7x7x30 contain1 = pred[:,:,4].unsqueeze(2) # 先获取第一个框的置信度,然后升维变为7*7*1 contain2 = pred[:,:,9].unsqueeze(2) # 同上,只是为第二个框 contain = torch.cat((contain1,contain2),2) # 拼接在一起,变为7*7*2 mask1 = contain > 0.1 #大于阈值0.1,设置为True mask2 = (contain==contain.max()) # 找出置信度最大的,设置为True mask = (mask1+mask2).gt(0) # 将mask1+mask2,让其中大于0的设置为True # 开始迭代每个单元格,即7*7个 for i in range(grid_num): for j in range(grid_num): # 迭代两个预测框 for b in range(2): # 如果mask为1,表示这个框是最大的置信度框 if mask[i,j,b] == 1: # 获取坐标值 box = pred[i,j,b*5:b*5+4] # 获取置信度值 contain_prob = torch.FloatTensor([pred[i,j,b*5+4]]) # 将7*7的坐标,归一化 xy = torch.FloatTensor([j,i])*cell_size #cell左上角 up left of cell # box[:2] = box[:2]*cell_size + xy # 将[cx,cy,w,h]转为[x1,xy1,x2,y2] box_xy = torch.FloatTensor(box.size()) # 重新创建一个变量存储值 box_xy[:2] = box[:2] - 0.5*box[2:] # 这个就是中心坐标加减宽度/高度得到左上角/右下角坐标 box_xy[2:] = box[:2] + 0.5*box[2:] # 获取最大的概率和类别索引值 max_prob,cls_index = torch.max(pred[i,j,10:],0) # 如果置信度 * 类别概率 > 0.1,即说明有一定的可信度 # 那么把值加入各个变量列表中 if float((contain_prob*max_prob)[0]) > 0.1: boxes.append(box_xy.view(1,4)) cls_indexs.append(torch.tensor([cls_index.item()])) probs.append(contain_prob*max_prob) # 如果boxes为0,表示没有框,返回0 if len(boxes) ==0: boxes = torch.zeros((1,4)) probs = torch.zeros(1) cls_indexs = torch.zeros(1) # 否则,进行处理,就是简单把原来的列表值[tensor,tensor]转为tensor的形式 # 里面的值不变 else: boxes = torch.cat(boxes,0) #(n,4) probs = torch.cat(probs,0) #(n,) cls_indexs = torch.cat(cls_indexs,0) #(n,) # 后处理——NMS keep = mns(boxes,probs) # 返回值 return boxes[keep],cls_indexs[keep],probs[keep] # 4. NMS处理 def mns(bboxes,scores,threshold=0.5): ''' :param bboxes: bboxes(tensor) [N,4] :param scores: scores(tensor) [N,] :param threshold: 阈值 :return: 返回过滤后的框 ''' # 获取各个框的坐标值 x1 = bboxes[:,0] y1 = bboxes[:,1] x2 = bboxes[:,2] y2 = bboxes[:,3] # 计算面积 areas = (x2-x1) * (y2-y1) # 将置信度按照降序排序,并获取排序后的各个置信度在这个顺序中的索引 _,order = scores.sort(0,descending=True) keep = [] # 判断order中的元素个数是否大于0 while order.numel() > 0: # 如果元素个数只剩下一个了,结束循环 if order.numel() == 1: i = order.item() keep.append(i) break # 获取最大置信度的索引 i = order[0] keep.append(i) # 对后面的元素坐标进行截断处理 xx1 = x1[order[1:]].clamp(min=x1[i]) # min指的是小于它的设置为它的值,大于它的不管 yy1 = y1[order[1:]].clamp(min=y1[i]) xx2 = x2[order[1:]].clamp(max=x2[i]) yy2 = y2[order[1:]].clamp(max=y2[i]) # 此时的xx1,yy1等是排除了目前选中的框的,即假设x1有三个元素,那么xx1只有2个元素 # 获取排序后的长和宽以及面积,如果小于0则设置为0 w = (xx2-xx1).clamp(min=0) h = (yy2-yy1).clamp(min=0) inter = w*h # 准备更新order、 # 计算选中的框和剩下框的IOU值 ovr = inter / (areas[i] + areas[order[1:]] - inter) # 如果 IOU小于设定的阈值,说明需要保存下来继续筛选(NMS原理) ids = (ovr<=threshold).nonzero().squeeze() if ids.numel() == 0: break order = order[ids+1] return torch.LongTensor(keep) # 5. 预测函数 def predict_single(model, image_name, root_path=''): result = [] # 保存结果的变量 # 打开图片 image = cv2.imread(root_path + image_name) h, w, _ = image.shape # resize为模型的输入大小,即448*448 img = cv2.resize(image, (448, 448)) # 由于我们模型那里定义的颜色模式为RGB,因此这里需要转换 mean = (123, 117, 104) # RGB均值 img = img - np.array(mean, dtype=np.float32) # 预处理 transform = transforms.Compose([transforms.ToTensor(), ]) img = transform(img) img = Variable(img[None, :, :, :], volatile=True) img = img.cuda() # 开始预测 pred = model(img) # 1x7x7x30 pred = pred.cpu() # 解码 boxes, cls_indexs, probs = decoder(pred) # 开始迭代每个框 for i, box in enumerate(boxes): # 获取相关坐标,只是需要把原来归一化后的坐标转回去 x1 = int(box[0] * w) x2 = int(box[2] * w) y1 = int(box[1] * h) y2 = int(box[3] * h) # 获取类别索引、概率等值 cls_index = cls_indexs[i] cls_index = int(cls_index) # convert LongTensor to int prob = probs[i] prob = float(prob) # 把这些值集中放入一个变量中返回 result.append([(x1, y1), (x2, y2), VOC_CLASSES[cls_index], image_name, prob]) return result if __name__ == '__main__': # 慢慢的显示 import time # 创建模型,加载参数 model = resnet50() model.load_state_dict(torch.load('./weights/yolo.pth')) model.eval() model.cuda() # 设置图片路径 base_path = './test_images/' # base_path = '../data/VOC2012/JPEGImages/' image_name_list = [base_path+i for i in os.listdir(base_path)] # 打乱顺序 random.shuffle(image_name_list) print('stating predicting....') for image_name in image_name_list: image = cv2.imread(image_name) image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) result = predict_single(model, image_name) # 画矩形框和对应的类别信息 for left_up, right_bottom, class_name, _, prob in result: # 获取颜色 color = Color[VOC_CLASSES.index(class_name)] # 画矩形 cv2.rectangle(image, left_up, right_bottom, color, 2) # 获取类型信息和对应概率,此时为str类型 label = class_name + str(round(prob, 2)) # 把类别和概率信息写上,还要为这个信息加上一个矩形框 text_size, baseline = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.4, 1) p1 = (left_up[0], left_up[1] - text_size[1]) cv2.rectangle(image, (p1[0] - 2 // 2, p1[1] - 2 - baseline), (p1[0] + text_size[0], p1[1] + text_size[1]), color, -1) cv2.putText(image, label, (p1[0], p1[1] + baseline), cv2.FONT_HERSHEY_SIMPLEX, 0.4, (255, 255, 255), 1, 8) # 显示图片 plt.figure() plt.imshow(image) plt.show() time.sleep(2) # 是否保存结果图片 cv2.imwrite('./test_images/result.jpg', image)
6、验证图片






7、完整代码和权重下载
链接:https://pan.baidu.com/s/1nJbfAxTUshCy4giFPoy7sA
提取码:yov1
8、总结
需要改进:
首先,肯定是batch_size的大小,如果有得选,我也想把batch_size改大一点_
其次,是优化器的选择和其参数的设置,本次选用的SGD,参数都是默认设置的,我在想是否改为Adam会好一点
另外,本次学习率从0.01开始,分别在20和35epoch时除以10,感觉初始的学习率有点大了,是否可以减小学习率?
最后,所谓微调,我们继承了ResNet50的权重,但是这个ResNet50是在尺度为224*224下训练的,而我们的目标检测将分辨率改为了448*448,是否需要先进行一定程度的微调才来训练yolov1值得思考。














 1498
1498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









