








基于YOLOv8模型的海洋生物目标检测系统(PyTorch+Pyside6+YOLOv8模型)(含源码+模型+可修改)
简介: 基于YOLOv8模型的海洋生物目标检测系统可用于日常生活中检测与定位海洋生物目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测算法训练数据集,使用Pysdie6库来搭建前端页面展示系统。另外本系统支持的功能还包括训练模型的导入、初始化;检测置信分与检测后处理IOU阈值的调节;图像的上传、检测、可视化结果展示与检测结果导出;视频的上传、检测、可视化结果展示与检测结果导出;摄像头的图像输入、检测与可视化结果展示;已检测目标个数与列表、位置信息;前向推理用时等功能。为科研人员、海洋生物观察者或其他相关用户提供了一站式的海洋生物目标识别解决方案,满足从单张图片分析到实时视频监控等多种应用场景的需求。

1. 基本介绍
1、模型训练与导入:
使用 YOLOv8(You Only Look Once version 8)目标检测模型进行深海鱼数据集的训练。YOLOv8 因其高效的速度和准确度而受到青睐。
训练好的模型可以以 ONNX 或 PyTorch(PT)格式导出,方便在不同的平台和框架上部署。
用户可以通过系统界面上传并导入自己的训练模型,实现模型的初始化。
2、图像、视频和摄像头检测:
图像检测:用户可以通过页面上传单张或多张图片,系统使用已训练的模型对图片中的深海鱼进行检测,并将结果可视化展示在页面上。
视频检测:系统支持上传视频文件,对视频帧进行逐帧检测,并将每帧的检测结果进行可视化处理,最终生成一个带有检测框的视频。
摄像头检测:系统可以通过连接摄像头进行实时检测,将摄像头捕获的画面中的深海鱼实时标记并展示在界面上。
3、检测结果的可视化与导出:
检测结果可以通过界面以图像或视频的形式展示给用户,同时提供检测结果图片的下载或视频导出功能。
用户可以根据需要调整置信分和 IOU(Intersection over Union,交并比)阈值,以过滤掉低于某个阈值的检测结果。
4、前向推理用时:
系统会记录每次检测的前向推理时间,即模型处理每张图片或视频帧所需的时间,这对于评估模型性能和优化系统非常重要。
5、界面与交互:
使用 Pyside6(或类似的库如 PyQt5/6、Tkinter 等)来搭建用户友好的图形界面,提供直观的操作体验。
界面设计应包含文件上传、参数设置、结果显示等必要的交互元素。
6、已检测目标列表与位置信息:
系统会维护一个已检测目标的列表,记录每个目标的类别、置信度、位置(如边界框的坐标)等信息。
用户可以通过列表查看和管理已检测到的深海鱼目标。
7、扩展性与灵活性:
系统应设计为可扩展和灵活,支持不同格式模型的导入和多种类型输入数据的检测。
提供 API 接口,方便与其他系统或平台进行集成。
2.安装环境及运行
(1)下载完整文件到自己电脑上,然后使用cmd打开到文件目录
(2)利用Conda创建环境(Anacodna),conda create -n yolo8 python=3.8 ;使用
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple安装依赖包;
(3)安装Pyside6库
pip install pyside6==6.3 -i https://pypi.tuna.tsinghua.edu.cn/simple3.YOLOV8算法原理
YOLOv8 是 ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本,目前支持图像分类、物体检测和实例分割任务,鉴于Yolov5的良好表现,Yolov8在还没有开源时就收到了用户的广泛关注YOLOv8是一种先进的深度学习模型,专为实现高效准确的目标检测而设计。其核心思想是将目标检测任务视为一个回归问题,通过单一的前向传播过程直接预测出图像中物体的类别和位置。
3.1 数据集介绍
使用的海洋生物数据集手动标注了海胆、海参、扇贝和海星这四个类别(海胆:echinus,海参:holothurian,扇贝:scallop,海星:starfish),数据集总计6575张图片。该数据集中类别都有大量的旋转和不同的光照条件,有助于训练出更加鲁棒的检测模型。本文实验的海洋生物检测识别数据集包含训练集5260张图片,验证集1315张图片,选取部分数据部分样本数据集如下图所示。此外,为了增强模型的泛化能力和鲁棒性,我们还使用了数据增强技术,包括随机旋转、缩放、裁剪和颜色变换等,以扩充数据集并减少过拟合风险。
|
|
|
|---|---|
|
|
|




3.2 YOLOV8算法原理
yolov8的整体架构如下:
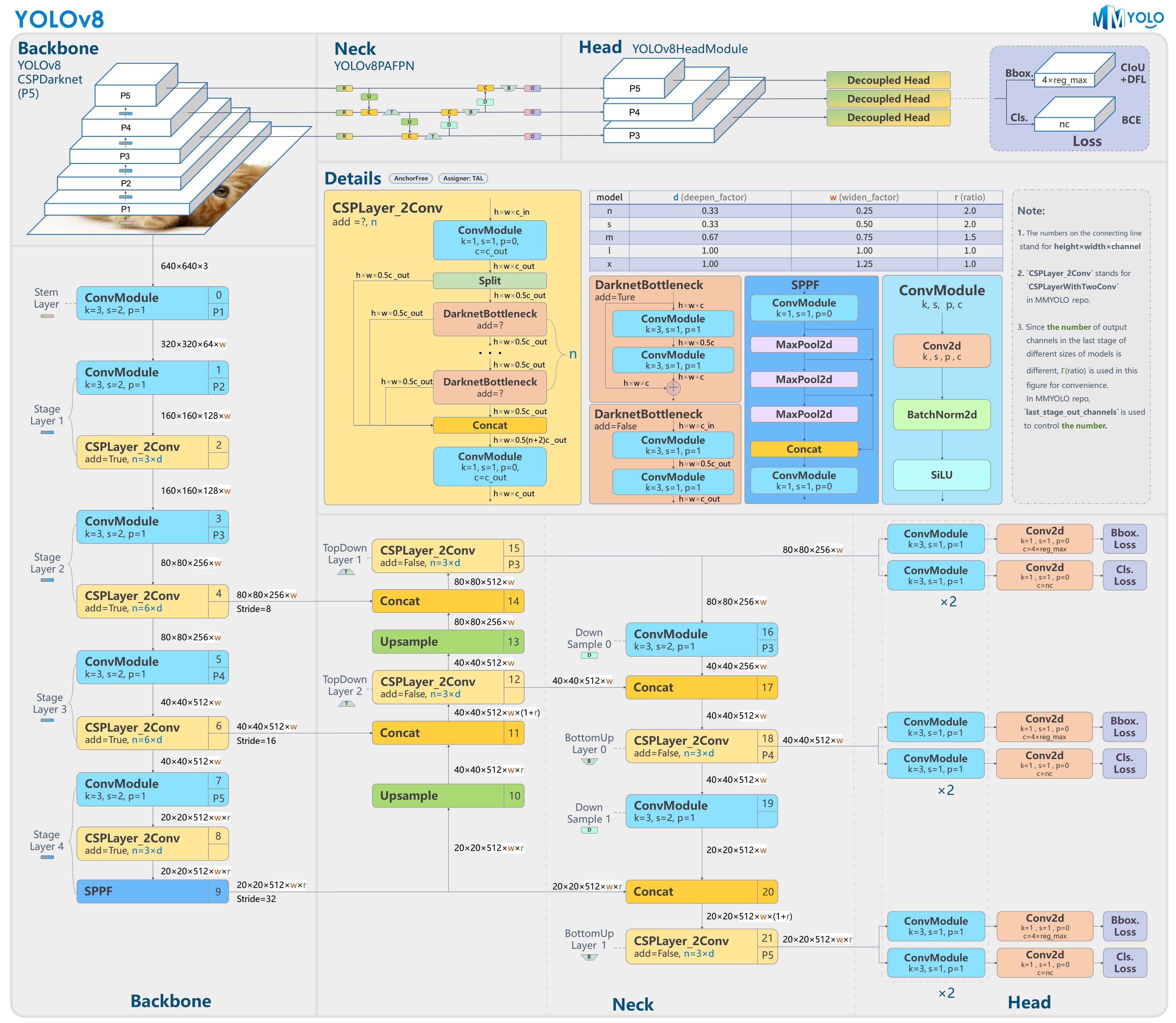
YOLOv8继承了YOLO系列算法的设计,优化并改进了网络结构,使其在速度和准确率之间达到更好的平衡。它采用了一个深度卷积神经网络作为其基础架构,通常以类似于Darknet-53的网络作为骨干,这种网络深度和宽度的平衡设计使得模型能够捕捉到丰富的特征信息,同时保持了较快的处理速度。
YOLOV8主要优点有如下:
- 用户友好的API
- 可以同时实现分类、检测、分割和姿态估计任务
- 速度更快、准确率更高
- 全新的结构
- 新的损失函数
- Anchor free
主要改动:
Backbone: 第一层卷积由原本的 6×6 卷积改为 3×3 卷积;参考 YOLOv7 ELAN 设计思想将 C3 模块换成了 C2f 模块,并配合调整了模块的深度。
Neck: 移除了 1×1 卷积的降通道层;同时也将原本的 C3 模块换成了 C2f 模块。
Head: 这部分改动较大,换成了解耦头结构,将分类任务和回归任务解耦;同时也将 Anchor-Based 换成了 Anchor-Free 。
Loss:使用 BCE Loss 作为分类损失;使用 DFL Loss + CIOU Loss 作为回归损失。
样本匹配策略: 采用了 Task-Aligned Assigner 样本分配策略。
训练策略: 新增加了最后 10 轮关闭 Mosaic 数据增强操作,该操作可以有效的提升精度
YOLOv8的网络结构通常包括几个关键部分:首先是输入预处理,它将输入图像统一调整至固定的尺寸(例如416x416像素),以保证网络输入的一致性。随后,图像通过多层卷积网络,这一过程中会使用到多种类型的卷积层,包括标准的卷积层、残差连接以及BottleNeck层。这些层次的设计旨在提取图像中的特征,为后续的目标检测任务奠定基础。
在特征提取过程中,YOLOv8通过使用批量归一化(Batch Normalization, BN)和CBL(Convolution, Batch normalization, Leaky ReLU)模块来加速训练过程并提高模型的稳定性。BN层可以减少内部协变量偏移,提高模型训练过程的稳定性和泛化能力。CBL模块则是YOLOv8网络中重复使用的基本构建块,通过这种模块化的设计,YOLOv8能够以较小的计算成本提取深层次的特征信息。
YOLOv8的另一个显著特点是它的预测方式。它将图像分割为一个个网格,并在每个网格中预测多个边界框及其对应的置信度和类别概率。这种设计使得YOLOv8能够在图像中的多个位置同时预测多个目标,大幅提高了检测的效率。为了减少重复检测和提高检测准确性,YOLOv8还采用了非极大值抑制(Non-maximum Suppression, NMS)的技术,通过此技术可以筛选出最佳的边界框,并抑制那些重叠较多且置信度较低的边界框。
总之,YOLOv8通过其创新的网络结构和预测机制,为实时目标检测任务提供了一种既快速又准确的解决方案。它的设计理念和技术细节共同确保了在保持高速处理的同时,也能够准确地识别出图像中的各种目标。这一系列的技术进步使得YOLOv8在目标检测领域中占据了领先地位,并被广泛应用于各种实际场景中。
3.3 代码简介
在训练阶段,我们使用了预训练模型作为初始模型进行训练,然后通过多次迭代优化网络参数,以达到更好的检测性能。在训练过程中,我们采用了学习率衰减和数据增强等技术,以增强模型的泛化能力和鲁棒性。一个简单的单卡模型训练命令如下。
Device is determined automatically. If a GPU is available then it will be used, otherwise training will start on CPU.
# Build a new model from YAML and start training from scratch
yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640
# Start training from a pretrained *.pt model
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
# Build a new model from YAML, transfer pretrained weights to it and start training
yolo detect train data=coco128.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640
To train with 2 GPUs, CUDA devices 0 and 1 use the following commands. Expand to additional GPUs as required.
# Start training from a pretrained *.pt model using GPUs 0 and 1
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640 device=0,1
训练时可指定更多的参数,如下:
| Argument | Default | Description |
|---|---|---|
| model | None | 模型或者模型配置文件 |
| data | None | 数据集配置文件 |
| epochs | 100 | 训练的轮次 |
| patience | 100 | 准确率为提升停止的轮次 |
| batch | 16 | 训练的批次大小 |
| imgsz | 640 | 图像的尺寸 |
| save | True | 是否需要保存训练的结果与模型 |
| device | None | 训练设备 |
| workers | 8 | 多线程数据集加载 |
| project | None | 项目名称 |
| exist_ok | False | 是否覆盖现有试验 |
| pretrained | True | 是否使用预训练模型 |
| optimizer | 'auto' | 优化器选择 |
| verbose | False | 是否详细输出 |
| seed | 0 | 种子数 |
| deterministic | True | 是否启动确定性模式 |
| rect | False | 单类别模型训练 |
| cos_lr | False | 是否使用余弦学习率调度器 |
| resume | False | 是否从最近的训练断掉权重继续训练 |
| amp | True | 是否开启混合精度训练 |
本文中我们将深入探讨如何通过Python脚本使用YOLOv8算法与PySide6库来构建一个多目标检测和跟踪的图形用户界面(GUI)应用。这段代码展示了从图像读取、模型加载、预测执行到结果展示整个流程的实现。
首先,我们引入了必要的Python模块,包括random、sys、time以及图像处理和GUI设计相关的库。通过这些库,我们可以处理图像数据、创建窗口界面,并接受用户输入。代码首先设置QF_Config以关闭冗余输出,保持GUI输出的整洁。
# 界面入口
import sys
import os
import logging
# 禁止标准输出
sys.stdout = open(os.devnull, 'w')
logging.disable(logging.CRITICAL) # 禁用所有级别的日志
from PySide6.QtGui import QIcon
from PySide6.QtWidgets import QApplication
from utils import glo
from yoloshow import *
我们定义了一个MainWindow类,它继承自QMainWindow,用于创建主窗口。在窗口中,我们添加了一个标签(QLabel),它将用来展示目标检测后的图像。
# 多套一个类 为了实现MouseLabel方法
class MyWindow(YOLOshow):
# 定义关闭信号
closed = Signal()
def __init__(self):
super(MyWindow, self).__init__()
self.center()
# --- 拖动窗口 改变窗口大小 --- #
event.ignore()
else:
self.setWindowOpacity(1.0)
self.closed.emit()
在代码的核心部分,我们首先记录了预测开始的时间,调用模型的predict函数进行预测,并记录结束时间,以计算整个推理过程所需时间。使用postprocess函数对检测结果进行后处理,然后遍历每个检测到的对象信息,包括类别名称、边界框、置信度和类别ID。这些信息将用来在图像上绘制代表检测对象的矩形框,并显示类别和置信度。最后,我们在GUI的标签上显示处理后的图像,并启动Qt应用程序的主循环。通过这样的实现,用户可以直观地看到每个检测对象,以及模型预测的准确性和效率。

3.4 模型训练
在文中,使用YOLOv8模型进行目标检测模型训练。YOLOv8作为一种高效目标检测算法,能够快速准确地在图像中识别出不同的物体。这段代码概述了如何设置训练环境、如何读取数据集、以及如何执行模型训练的整个过程。我们将详细介绍代码的每个关键步骤,并解释每段代码的作用。
首先,代码导入了os库用于操作系统相关的功能,如文件路径的处理;torch库是PyTorch的核心,提供了深度学习模型训练所需的各种工具和函数;yaml库用于解析和处理YAML文件,这在读取数据集配置时尤为重要。接着,从ultralytics导入了YOLO类,这是Ultralytics提供的一个方便用户加载和训练YOLO模型的类。代码段设置了设备变量,首先确保了脚本能够正确识别运行环境,即自动选择使用GPU或CPU。这对于训练效率至关重要,因为GPU可以大大加速深度学习模型的训练过程。
import math
import os
import subprocess
import time
import warnings
from copy import deepcopy
from datetime import datetime, timedelta
from pathlib import Path
from ultralytics import SAM, YOLO
...
# Device
if self.device.type in ("cpu", "mps"):
self.args.workers = 0 # faster CPU training as time dominated by inference, not dataloading
接着,我们读取并处理了数据集的YAML配置文件。这个文件包含了关于训练数据的详细信息,如文件路径、类别标签等。通过调整配置文件,我们确保了数据的正确加载,这对于模型训练至关重要。
def yaml_load(file="data.yaml", append_filename=False):
assert Path(file).suffix in (".yaml", ".yml"), f"Attempting to load non-YAML file {file} with yaml_load()"
with open(file, errors="ignore", encoding="utf-8") as f:
s = f.read() # string
# Remove special characters
if not s.isprintable():
s = re.sub(r"[^\x09\x0A\x0D\x20-\x7E\x85\xA0-\uD7FF\uE000-\uFFFD\U00010000-\U0010ffff]+", "", s)
# Add YAML filename to dict and return
data = yaml.safe_load(s) or {} # always return a dict (yaml.safe_load() may return None for empty files)
if append_filename:
data["yaml_file"] = str(file)
return data
我们实例化了YOLO模型,并加载了预训练权重,这样可以利用在其他数据集上获得的知识,加速我们当前任务的学习进程。使用YOLO类的train方法,我们开始了模型的训练过程。在这里,我们指定了各种训练参数,包括数据集路径、设备、工作进程数、图像大小、训练周期和批次大小,还有一个特定的训练任务名称,以便于区分和管理训练过程。
model = YOLO(abs_path('./weights/yolov8n.pt'), task='detect') # 加载预训练的YOLOv8模型
results2 = model.train( # 开始训练模型
data=data_path, # 指定训练数据的配置文件路径
device=device, # 自动选择进行训练
workers=workers, # 指定使用2个工作进程加载数据
imgsz=640, # 指定输入图像的大小为640x640
epochs=120, # 指定训练100个epoch
batch=batch, # 指定每个批次的大小为8
name='train_v8_' + data_name # 指定训练任务的名称
)
# Preprocess 预处理
with self.dt[0]:
im = self.preprocess(im0s)
# Inference 推断
with self.dt[1]:
preds = self.inference(im)
# Postprocess 后处理
with self.dt[2]:
self.results = self.postprocess(preds, im, im0s)
训练深度学习模型YOLOv8,理解和分析训练过程中的各种指标至关重要。损失函数的变化趋势、精度(precision)、召回率(recall)以及平均精度均值(mAP)等指标是评估模型性能的关键。深入分析图中所示的训练指标,以揭示模型训练过程中的细微变化和潜在的信息。
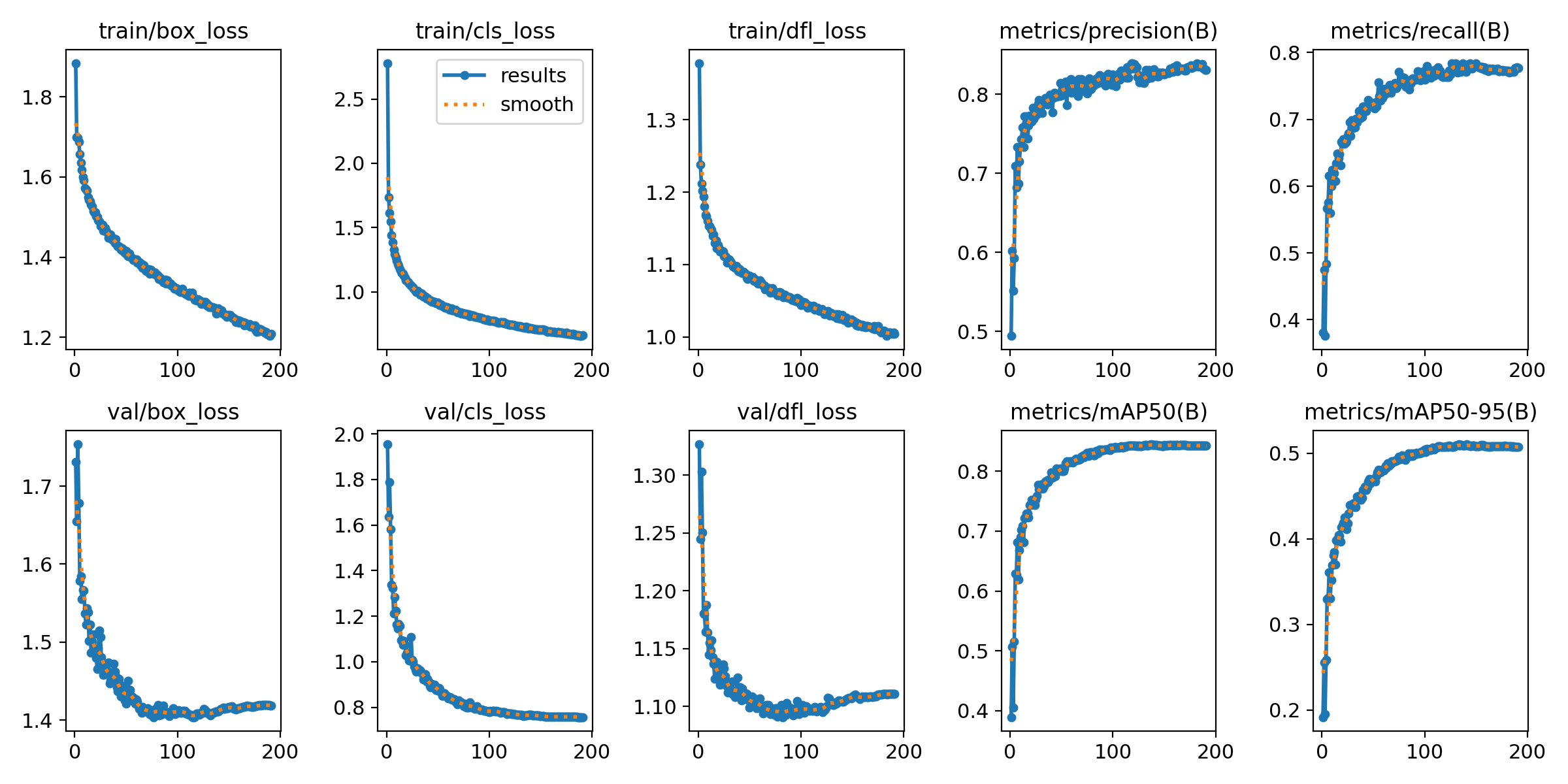
从图中可以看到,训练集的box_loss、cls_loss、和df1_loss都随着迭代次数增加呈现下降趋势,这表明模型在训练过程中对目标的定位(box_loss)、分类(cls_loss)和检测(df1_loss)能力在逐步提升。这些损失函数的下降意味着模型在识别和定位目标方面的误差在减少。特别是在训练初期,损失下降得非常迅速,这通常是因为模型从随机初始化的权重快速地学习到了有关数据的基本特征。随着训练的深入,损失下降速度减缓,这是因为模型开始拟合更为复杂的模式,而这需要更多的训练迭代来实现。
在验证集上,box_loss和df1_loss的下降趋势与训练集相似,但cls_loss在下降到一定程度后趋于平稳,这可能暗示在分类任务上,模型对于训练数据的学习已经接近饱和,或者数据中的分类任务本身存在一定难度,模型难以进一步从中学习到更多的区分性特征。
精度和召回率两个指标为我们提供了模型性能的另一个视角。精度指标告诉我们,模型识别出的目标中有多少是正确的,而召回率则告诉我们,所有正确的目标中有多少被模型识别出来。图中的precision和recall曲线都呈上升趋势,这表明模型随着训练逐步增强了识别目标的能力,并能够从更多样的样本中检测出正确的目标。
至于mAP指标,它是衡量目标检测模型在多个类别和不同阈值下性能的综合指标。mAP和mAP50-95的上升趋势表明,模型的整体检测性能在提升,对不同大小的目标都有较好的检测效果。mAP50和mAP50-95两个指标,前者仅计算IoU大于0.5的预测框,而后者则包含了IoU从0.5到0.95的所有情况,这两个指标的提高说明模型在不同程度的重叠区域内都展现出了良好的性能。
在深度学习的目标检测领域,F1分数是衡量模型性能的重要指标之一。它是精确率和召回率的调和平均值,能够全面反映模型对正类别的识别能力。深入分析我们基于YOLOv8模型训练后的F1分数曲线,这些曲线为我们提供了模型各个类别的性能表现以及整体性能的综合视图。

F1分数与置信度阈值之间的关系图为我们提供了每个类别在不同置信度阈值下的性能变化。从曲线图中我们可以观察到,随着置信度阈值的增加,各个类别的F1分数先是上升后下降,呈现出一个类似于山峰的形状。这种曲线表明,在某个阈值点之前,随着置信度阈值的增加,模型越来越能准确地识别出真正的目标,减少了误检,因此精确率上升。但是,当阈值设置得过高时,模型变得过于保守,很多实际的目标会被漏检,导致召回率下降。
曲线图中还标注了所有类别综合的最佳F1分数0.58,对应的置信度阈值为0.357。这表明,在此置信度阈值下,模型达到了平衡精确率和召回率之间的最优状态。对于实际应用来说,这个阈值点提供了一个参考,我们可以根据具体任务的需求来调整阈值,以获得最佳的检测效果。
不同颜色的曲线代表了不同的类别,我们可以看到,不同类别的模型性能差异显著。比如,“person”类别的F1分数曲线相对较高,表明模型在识别人这一类别上表现较好。而像“train”这样的曲线比较低,可能意味着在检测该类别时模型的性能有待提高。这可能与训练数据的分布、类别本身的复杂性以及模型的学习能力有关。
在深度学习模型的优化过程中,我们通常需要密切观察这些性能曲线,并结合实际应用中的需求来微调我们的模型。例如,如果我们的应用场景对误检的容忍度较低,则可能需要选择一个较高的置信度阈值。相反,如果我们更重视避免漏检,那么一个较低的阈值可能更为适合。
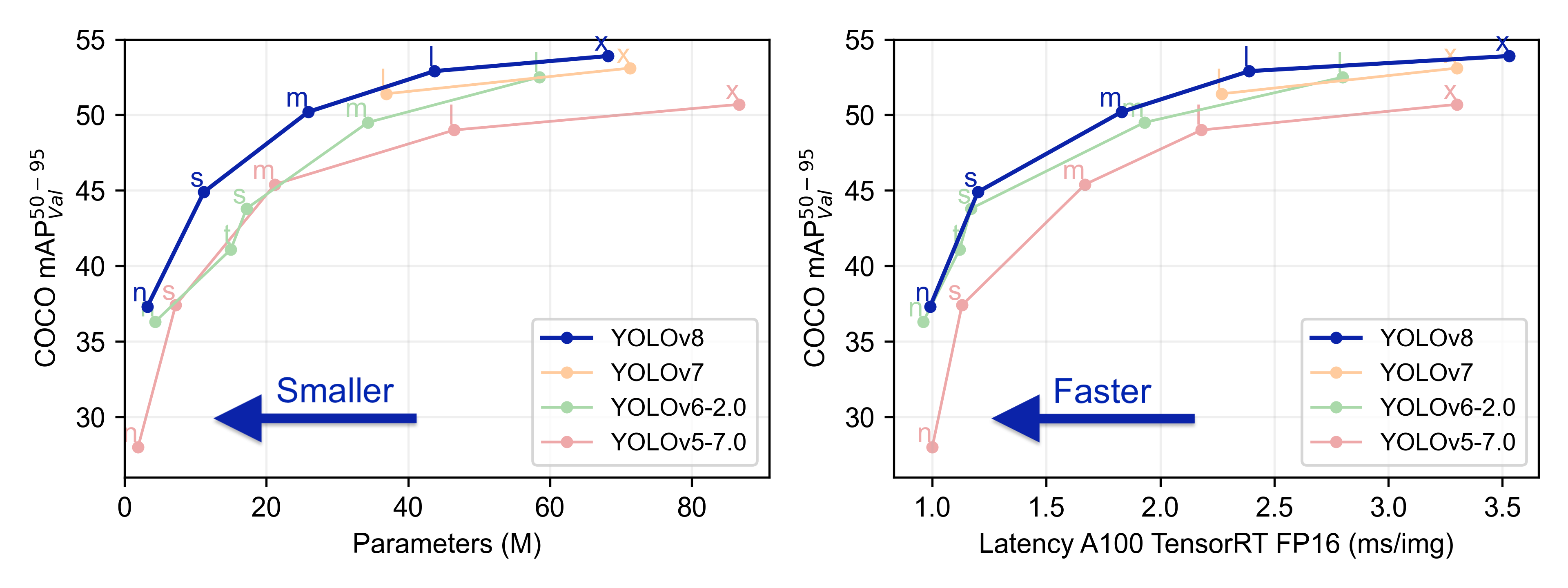
在原作者文章中比较YOLOv5、YOLOv6、YOLOv7和YOLOv8几种模型在多目标目标检测任务上的性能
3.5 代码实现
利用YOLOv8和PySide6库构建一个高效的海洋生物检测系统;这各系统能准确检测到海洋生物,区分出种类。
(1)引入必要的库
首先,我们需要导入一系列模块,这些模块包括用于图像处理的OpenCV库、用于构建图形用户界面的PySide6库、以及其他必要的Python模块。通过这些模块的配合工作,我们能够处理视频数据,并在一个友好的用户界面中展示结果。
# yolov8检测线程处
import os.path
import time
import cv2
import numpy as np
import torch
from PySide6.QtCore import QThread, Signal
from pathlib import Path
from yolocode.yolov8.data import load_inference_source
from yolocode.yolov8.data.augment import classify_transforms, LetterBox
from yolocode.yolov8.data.utils import IMG_FORMATS, VID_FORMATS
from yolocode.yolov8.engine.predictor import STREAM_WARNING
from yolocode.yolov8.engine.results import Results
from models.common import AutoBackend
from yolocode.yolov8.utils import callbacks, ops, LOGGER, colorstr, MACOS, WINDOWS
from collections import defaultdict
# from yolocode.yolov5.utils.general import increment_path
from yolocode.yolov8.utils.checks import check_imgsz
from yolocode.yolov8.utils.torch_utils import select_device
(2)设置主窗口
系统中,MainWindow类负责创建主窗口,并在其中显示视频图像。
class MyWindow(YOLOshow):
# 定义关闭信号
closed = Signal()
def __init__(self):
super(MyWindow, self).__init__()
self.center()
# --- 拖动窗口 改变窗口大小 --- #
self.left_grip = CustomGrip(self, Qt.LeftEdge, True)
self.right_grip = CustomGrip(self, Qt.RightEdge, True)
self.top_grip = CustomGrip(self, Qt.TopEdge, True)
self.bottom_grip = CustomGrip(self, Qt.BottomEdge, True)
self.animation_window = None
(3)主程序部分
# 界面入口
import sys
import os
import logging
# 禁止标准输出
sys.stdout = open(os.devnull, 'w')
logging.disable(logging.CRITICAL) # 禁用所有级别的日志
from PySide6.QtGui import QIcon
from PySide6.QtWidgets import QApplication
from utils import glo
from yoloshow import *
if __name__ == '__main__':
app = QApplication([]) # 创建应用程序实例
app.setWindowIcon(QIcon('images/marine.ico')) # 设置应用程序图标
# 为整个应用程序设置样式表,去除所有QFrame的边框
app.setStyleSheet("QFrame { border: none; }")
# 启动界面入口
yoloshow = MyWindow()
glo._init()
glo.set_value('yoloshow', yoloshow)
Glo_yolo = glo.get_value('yoloshow')
Glo_yolo.show()
app.exec()
整个系统的设计旨在创建一个用户友好、反应迅速的界面,允许实时监控视频中目标的动态变化。它结合了深度学习的强大能力与用户友好的界面设计,使得多目标检测技术更加易于访问和使用。
4.系统实现
在构建交互式海洋生物多目标检测系统设计中,我们的核心目标是开发一个既直观又易于操作的用户界面,它能够实时显示多目标检测的结果。为了达到这一目标,采取了模块化的设计思路,整合界面、媒体处理和深度学习模型,实现了一个既高效又灵活的系统。
4.1 设计思路
在这一系统中,我们设计了MainWindow类作为架构的核心。这个类不仅是用户交互的主体,还起到了将处理逻辑和界面逻辑紧密联系起来的桥梁作用。通过精心设计的界面,用户能够轻松地管理和观察到从视频流中检测和跟踪的对象。此外,通过实时更新的视觉元素,比如标签和图像框,用户可以直观地看到模型的检测结果。
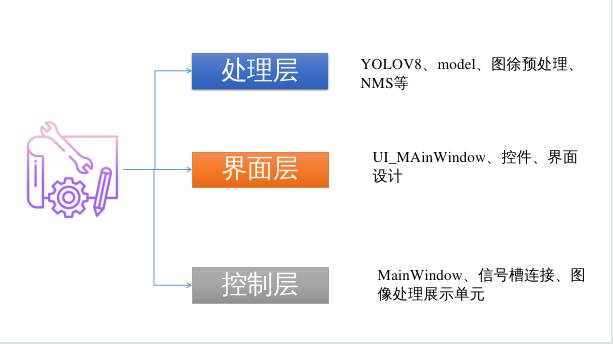
MainWindow类的设计巧妙地融合了处理层、界面层和控制层,使得整个系统既有良好的用户体验,又保持了强大的功能性:
-
处理层是系统的智能核心,利用先进的YOLOv8模型,它负责处理输入的视频流,并进行对象检测与跟踪。这层不仅需要高效地执行深度学习模型的推理,还要对检测到的对象信息进行实时更新和管理。
-
界面层是与用户直接交互的前端,通过PySide6构建的GUI元素,提供了一个清晰、响应迅速的界面。用户可以通过这个界面实时查看检测结果,以及各种统计信息和系统状态。
-
控制层承担着指挥和协调的角色,它通过连接处理层的逻辑和界面层的表现,将用户的操作转化为系统的响应。例如,用户的一次点击操作可能会触发一个槽函数,该函数会告诉模型开始处理下一帧视频或停止当前任务。
在此架构下,各层之间通过信号和槽机制进行高效通信。当处理层完成一帧的检测时,会发出一个信号,界面层的相应部件会捕捉这个信号,并更新显示的内容,如图像框中的对象位置和标签。这种机制使得我们的系统能够流畅地在用户操作和复杂的后端处理之间过渡,确保用户获得连贯和实时的体验。
通过这样的设计,我们不仅使得系统易于使用和扩展,而且还确保了它能够高效地处理复杂的多目标检测任务,并在动态环境下提供稳定的性能。这种架构设计使得我们的系统不仅适用于研究和学术领域,也能够满足工业级应用的需要。
下载链接
若您想获得博文中涉及的实现完整全部资源文件(包括测试图片、视频,py, UI文件,训练数据集、训练代码、界面代码等),这里已打包见可参考博客与视频,进行私信;已将所有涉及的文件同时打包到里面,点击即可运行,完整项目文件截图如下:
完整资源中包含数据集及训练代码,环境配置与界面中文字、图片、logo等的修改方法请见视频,项目完整文件下载请见演示与介绍视频的简介处给出: 基于YOLOv8模型的海洋生物目标检测系统(PyTorch+Pyside6+YOLOv8模型)(含源码+模型+可修改)_哔哩哔哩_bilibili
5.结束
本文详细介绍了一个基于YOLOv8模型的海洋生物多目标检测系统。系统以模块化的方式设计,充分采用了合理的架构设计,带来良好的可维护性和可扩展性。其用户界面友好,能够提供实时的多目标检测计数与跟踪和识别结果展示,同时支持用户账户管理,以便于保存和管理检测结果和设置。
该系统支持摄像头、视频、图像和批量文件等多种输入源,能够满足用户在不同场景下的需求。在后面可以添加更多预训练模型,增加检测和识别的种类;优化用户界面,增强个性化设置;并积极聆听用户反馈,以期不断改进系统,以更好地满足用户的需求。
非常感谢大家的支持!支出需要改进的地方,以便后续更改,共同追求更完美、更严谨的知识分享!















 935
935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









