






FCN Fully Convolutional Networks
论文:Fully Convolutional Networks for Semantic Segmentation
地址:https://openaccess.thecvf.com/content_cvpr_2015/papers/Long_Fully_Convolutional_Networks_2015_CVPR_paper.pdf
特点:用全卷积替代了全连接、反转卷积的操作来恢复信息、高低通道特征融合
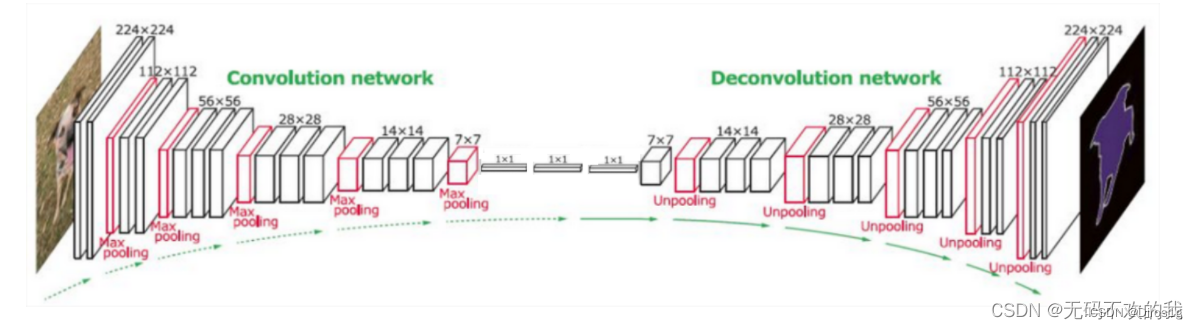
0.网络结构
FCN网络结构主要分为两个部分:全卷积部分和反卷积部分
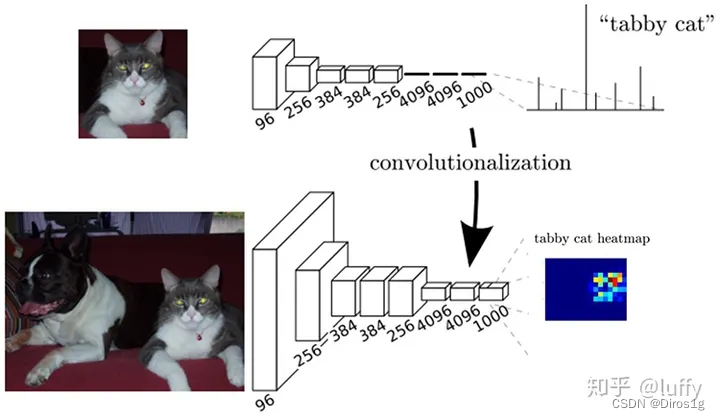
1.全连接
全连接层转化为卷积层
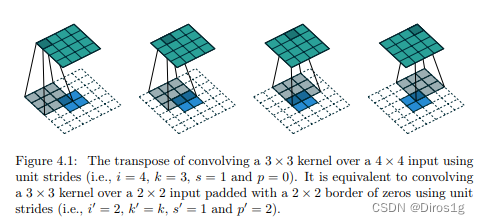
2.Deconvlution上采样
反卷积(Deconvolution),也叫做转置卷积(Transposed Convolution)
作用:反卷积的主要作用是将低维特征图还原为高维特征图,从而实现特征图的上采样或升维。
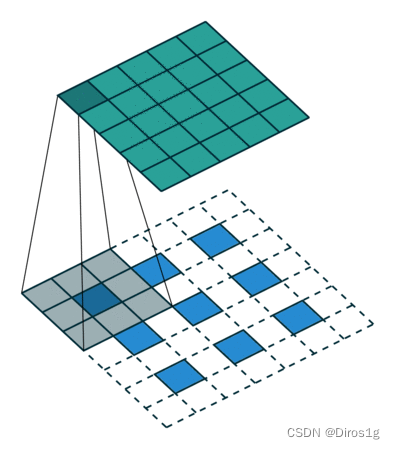
另一种反卷积的方法:内部填充
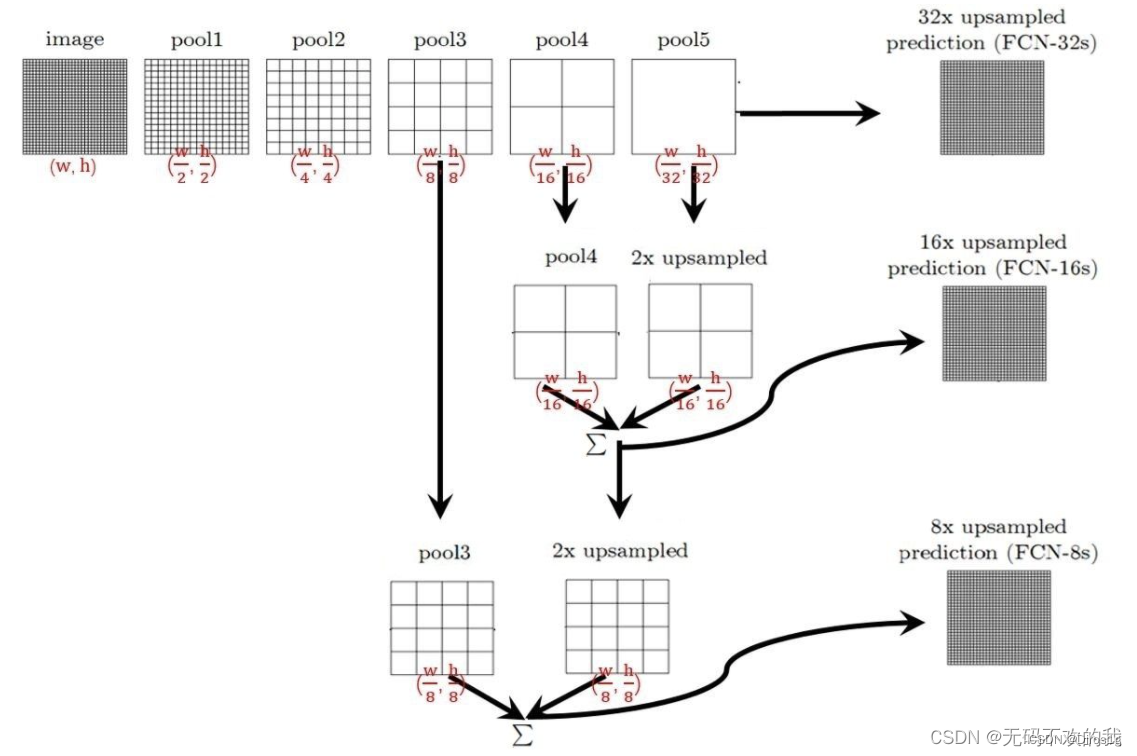
3.Skips高低特征融合
如果只利用反卷积对最后一层的特征图进行上采样得到原图大小的分割,由于最后一层的特征图太小,会损失很多细节。因而提出增加Skips(跳层连接结构)将最后一层的预测(有更富的全局信息)和更浅层(有更多的局部细节)的预测结合起来。
Deeplab系列
这一系列的核心思想就是找到合适的手段代替pooling带来的位置和细节损失,或者补偿损失
参考:https://blog.csdn.net/fanxuelian/article/details/85145558
DeeplabV1
原文:Semantic image segmentation with deep convolutional nets and fully connected CRFs
论文下载地址:https://arxiv.org/abs/1412.7062
参考源码:https://github.com/TheLegendAli/DeepLab-Context
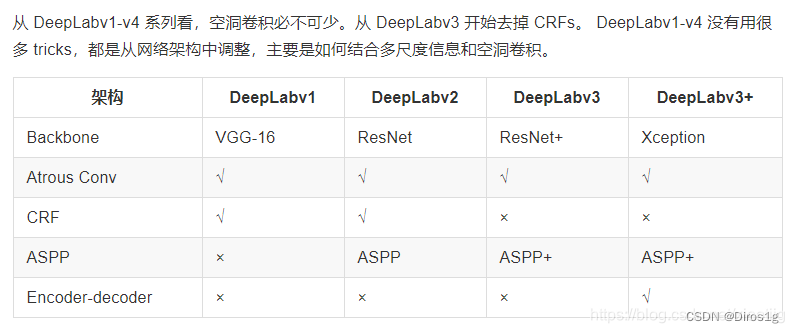
Backbone:VGG16
trick:Atrous convolution空洞卷积、CRF条件随机场、ASPP空洞空间金字塔池化
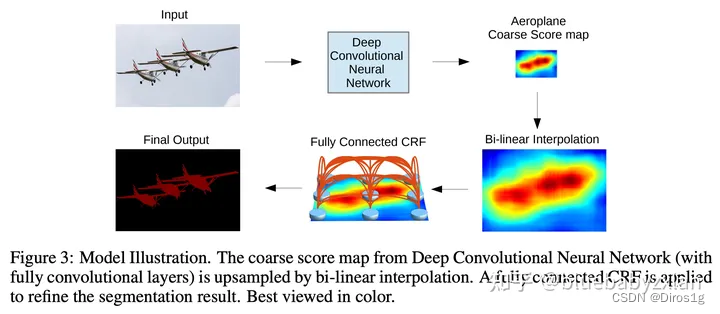
0.网络结构
输入Input -> CNN提取特征 -> 粗糙的分割图(1/8原图大小) -> 双线性插值回原图大小 -> CRF后处理 -> 最终输出Output
1.空洞卷积
使用背景:语义分割是一个end-to-end的问题,需要对每个像素进行精确的分类,对像素的位置很敏感,是个精细活儿。
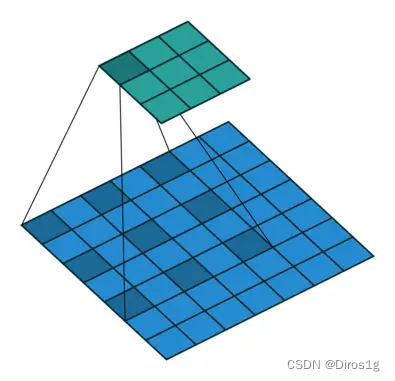
池化层的第一个作用,缩小特征层的尺寸,减少计算量。池化层还有另一个重要作用,快速扩大感受野。但pooling是一个不断丢失位置信息的过程,而语义分割又需要这些信息,矛盾就产生了,于是引入了空洞卷积。
实现方法:空洞卷积通过在卷积核的元素之间插入空洞或空白像素(pixel=0)来实现感受野的扩张。
作用:通过使用空洞卷积,可以在不增加参数数量的情况下增加感受野,从而提高模型对于大范围上下文信息的理解能力。
膨胀率:空洞卷积的一个重要参数是膨胀率(dilation rate),它决定了空洞的大小。通常,膨胀率为1表示普通的卷积操作,膨胀率大于1表示扩大感受野。
2.CRF条件随机场
参考:https://zhuanlan.zhihu.com/p/601952029
2.1随机场
随机场是由若干个位置组成的整体,当给每一个位置中按照某种分布随机赋予一个值之后,其全体就叫做随机场。简单理解,随机场就是一种分布关系,其分布关系只于位置有关。
2.2马尔可夫随机场
马尔科夫随机场是随机场的特例,它假设随机场中某一个位置的赋值仅仅与和它相邻的位置的赋值有关,和与其不相邻的位置的赋值无关。马尔可夫随机场中元素的分布关系不仅和自身位置有关,还和相邻元素属性有关。
2.3条件随机场
CRF是马尔科夫随机场的特例,在极端的约束下,马尔可夫随机场中每个点的值Y可以由该元素的位置关系X推出,并且分布关系可以由P(X|Y)表示,此时就获得了CRF,并且条件概率分布P(Y|X)是条件随机场的表达式。
2.4 DEEPLAB中的CRF
CRFs有两种形式,一种是成对的CRFs(pairwise CRFs),另一种是全连接的CRFs(fully connected CRFs),成对的CRFs只考虑相邻像素之间的关系,而全连接的CRFs考虑所有像素之间的关系。
输入图像经过多层卷积下采样后会导致分辨率大幅下降,这使得像素的位置信息丢失,导致还原图像尺寸的过程pixel的定位有偏失,体现为pixel-wise的最终预测结果不准确,这最主要表现在物体的边缘位置. 而CRF利用不同位置的像素类别信息关系,通过建立概率图的方式,有效缓解了边缘定位不准确的问题.
具体效果如下图所示.
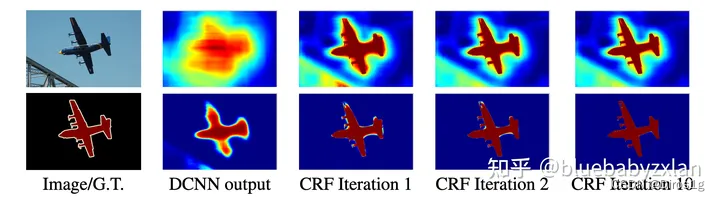
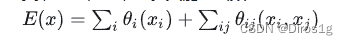
根据公式来看,就是一个全连接的滤波器
DeeplabV2
原文:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
Backbone:ResNet-101 with atrous convolution
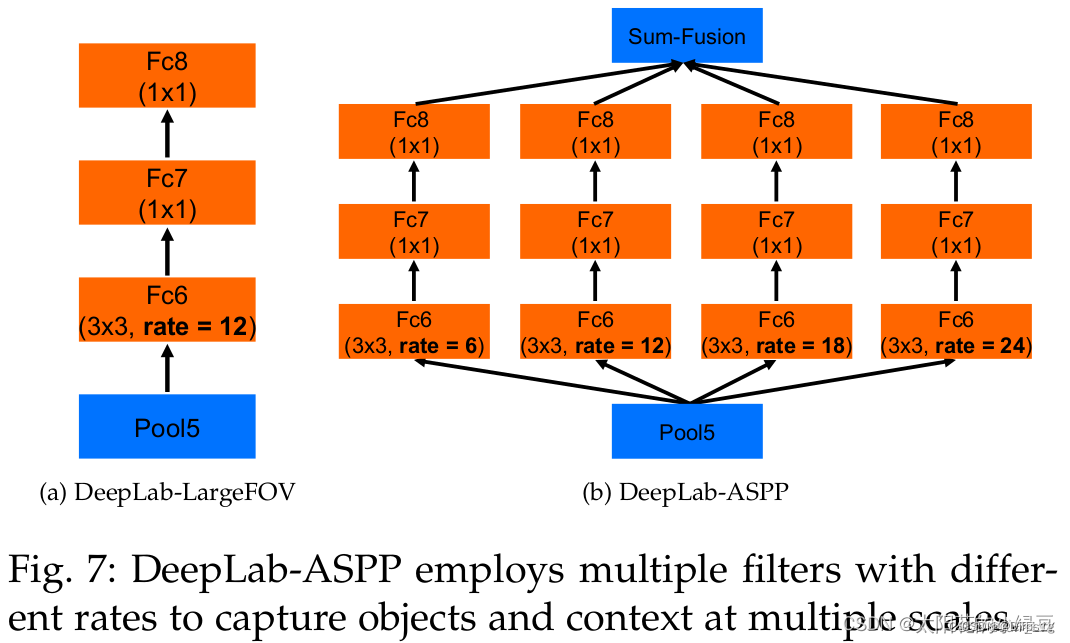
特点:ASPP
0.网络结构
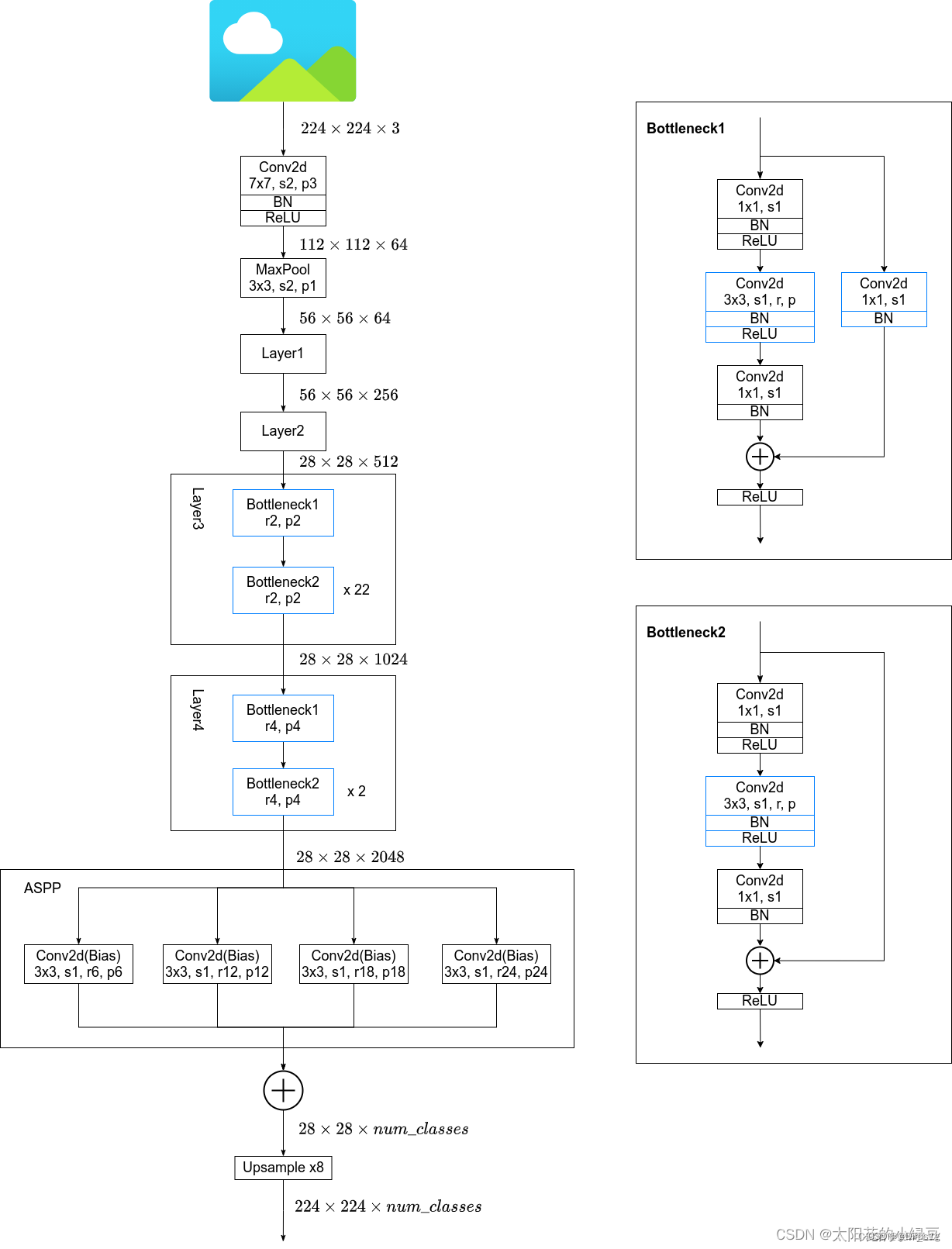
1.ASPP空洞空间金字塔池化
就是在backbone输出的Feature Map上并联四个分支,每个分支的第一层都是使用的膨胀卷积,但不同的分支使用的膨胀系数不同,由于每个分支的感受野不同,从而具有解决目标多尺度的问题
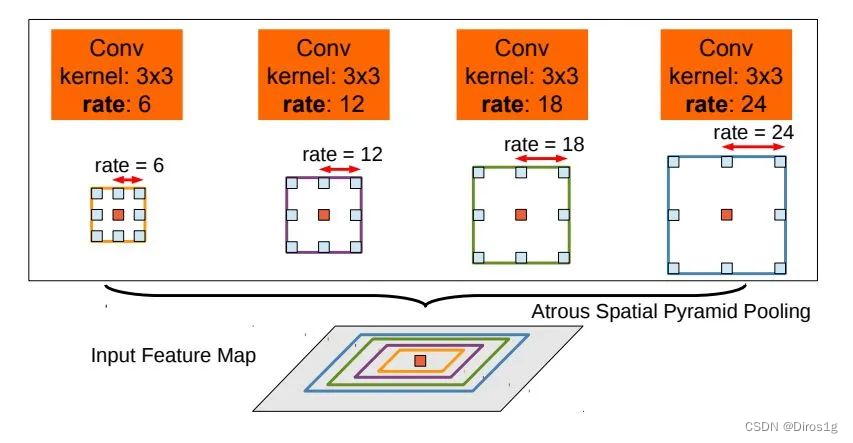
然后将得到的结果 concat 到一起,扩大通道数;最后通过 1 × 1的卷积将通道数降低到预期的数值。相当于以多个比例捕捉图像的上下文。
DeeplabV3
原文:Rethinking Atrous Convolution for Semantic Image Segmentation
Backbone:ResNet-101
特点:在ASPP中使用BN层、cascaded 级联
1.batch normalization
对于ASPP,空洞卷积之后使用batch normalization
DeepLab V3+
原文:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
Backbone:Xception
特点:Encoder-decoder structure














 578
578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









