







- actor:策略
- critic:评估价值
Actor-Critic 是囊括一系列算法的整体架构,目前很多高效的前沿算法都属于 Actor-Critic 算法,本章接下来将会介绍一种最简单的 Actor-Critic 算法。需要明确的是,Actor-Critic 算法本质上是基于策略的算法,因为这一系列算法的目标都是优化一个带参数的策略,只是会额外学习价值函数,从而帮助策略函数更好地学习。
1 核心
- 在 REINFORCE 算法中,目标函数的梯度中有一项轨迹回报(trajectory return),用于指导策略(policy, π(s | a) )的更新。REINFOCE 算法用蒙特卡洛方法来估计q(s, a)。
- 其实就是用回报作为策略的加权值,所以这里可以推广出一个一般形式,只要一个值能作为aciton的好坏的判断,就可以做为权重。
- 所以critic学的就是一个权重,输出是一个值。
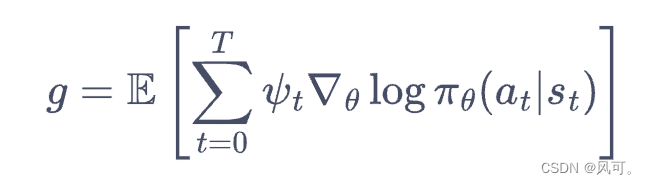
-
- 权重可以有以下这些:
- 权重可以有以下这些:

actor-critic优势:
- 事实上,用q值或者v值本质上也是用奖励来进行指导,但是用神经网络进行估计的方法可以减小方差、提高鲁棒性。除此之外,REINFORCE 算法基于蒙特卡洛采样,只能在序列结束后进行更新,这同时也要求任务具有有限的步数,而 Actor-Critic 算法则可以在每一步之后都进行更新,并且不对任务的步数做限制。
2 Actor-Critic

我们将 Actor-Critic 分为两个部分:Actor(策略网络)和 Critic(价值网络)。
- Actor 要做的是与环境交互,并在 Critic 价值函数的指导下用策略梯度学习一个更好的策略。
- Critic 要做的是通过 Actor 与环境交互收集的数据学习一个价值函数,这个价值函数会用于判断在当前状态什么动作是好的,什么动作不是好的,进而帮助 Actor 进行策略更新。

2.1 code
说的再多,不如看看代码。Actor-Critic 算法
网络
class PolicyNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super(PolicyNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
return F.softmax(self.fc2(x), dim=1)
class ValueNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim):
super(ValueNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, 1) ## 输出是1个值
def forward(self, x):
x = F.relu(self.fc1(x))
return self.fc2(x)class ActorCritic:
def __init__(self, state_dim, hidden_dim, action_dim, actor_lr, critic_lr,
gamma, device):
# 策略网络
self.actor = PolicyNet(state_dim, hidden_dim, action_dim).to(device)
self.critic = ValueNet(state_dim, hidden_dim).to(device) # 价值网络
# 策略网络优化器
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(),
lr=actor_lr)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(),
lr=critic_lr) # 价值网络优化器
self.gamma = gamma
self.device = device
def take_action(self, state):
state = torch.tensor([state], dtype=torch.float).to(self.device)
probs = self.actor(state)
action_dist = torch.distributions.Categorical(probs)
action = action_dist.sample()
return action.item()
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'],
dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(
self.device)
rewards = torch.tensor(transition_dict['rewards'],
dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
# 时序差分目标
td_target = rewards + self.gamma * self.critic(next_states) * (1 - dones)
td_delta = td_target - self.critic(states) # 时序差分误差
log_probs = torch.log(self.actor(states).gather(1, actions))
actor_loss = torch.mean(-log_probs * td_delta.detach())
# 均方误差损失函数
critic_loss = torch.mean(
F.mse_loss(self.critic(states), td_target.detach()))
self.actor_optimizer.zero_grad()
self.critic_optimizer.zero_grad()
actor_loss.backward() # 计算策略网络的梯度
critic_loss.backward() # 计算价值网络的梯度
self.actor_optimizer.step() # 更新策略网络的参数
self.critic_optimizer.step() # 更新价值网络的参数













 686
686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









