







因为实验需求接触到了Yolov3这个开源的图像识别开源库,这里稍微总结一下。
Yolov3既有速度又有精度,还非常灵活,而且还是完全开源的,简直是工业界良心。当然我这里只是介绍如何配置和使用,想看详细解析可以去参考大佬们的博客,我之前有看过的是(https://blog.csdn.net/leviopku/article/details/82660381)。
一、Yolov3(GPU)配置
请注意,这里的配置只适合安装了NIVDA显卡的计算机。
1. VS2015以及CUDA、cuDnn的安装
这一部分的安装在我关于配置Tensorflow的博客中有详细介绍(https://blog.csdn.net/qq_41967481/article/details/108431516),这里就不做赘述了。
2. 安装openCV
由链接openCV下载,注意请下载3.4.0,至于为什么不使用更高版本的请自行查看yolov3的作者已经在GitHub上的说明,笔者亲测3.4.0是可用的。(如果嫌官网速度感人的话,下载链接我会放在文章末尾)

下载后安装至任意盘符目录(自己能找到就行),之后配置环境变量:
Path:E:\cuda\opencv\build\include
E:\cuda\opencv\build\x64\vc14\lib
然后把 E:\cuda\opencv\build\x64\vc14\bin 路径下的三个dll文件拷贝到C:\Windows\System32下。

3. 下载Yolov3
Github项目地址:https://github.com/AlexeyAB/darknet 下载并解压(项目中解压至D盘根目录下:D:\yolov3\darknet-master)
在D:\yolov3\darknet-master\build\darknet 目录下打开darknet.sln,修改平台为X64,状态为release:

在属性中更改平台工具集为:Visual Studio 2015(v140)

VC++目录中添加包含目录和库目录:


在链接器- 输入 中添加依赖项:

将E:\cuda\opencv\build\x64\vc14\bin目录中的dll文件拷贝至 D:\yolov3\darknet-master\build\darknet\x64 中,生成darknet.exe,完成yolov3(GPU)配置。

4. 测试Yolov3
首先下载预训练权重yolov3.weights,地址:https : //pjreddie.com/media/files/yolov3.weights

将权重文件放置到 ..\darknet-master\build\darknet\x64 下,在上述目录中找到 darknet_yolo_v3.cmd 并打开,运行后出现下图说明yolov3已配置。

二、安装labelImg
如果你不需要标注自己的训练集,那可以不用理会这一步。
安装labelImg建议是在Anaconda环境下配置,如果不了解Anaconda怎么配置请查看(https://blog.csdn.net/qq_41967481/article/details/108431516)。
下载labelImg,地址:https://github.com/tzutalin/labelImg
打开Anaconda Prompt,键入:
conda install pyqt=5
安装成功后继续在Prompt中cd到安装labelImg的目录,输入:
pyrcc5 -o resources.py resources.qrc这一步如果没有输出则说明安装成功了,下面就可以打开软件了。
python labelImg.py
该程序的界面的大概介绍:


三、训练集准备
将你需要进行标注的图片样本作为一个训练集,存放于一个文件夹中(图片格式最好是使用jpg)。标注存放的文件夹也提取创建好。
![]()
设置需要标注的类别,在../ labelImg/data目录下找到predefined_classes.txt,将其修改为所需的类名,多个类别则每个类别占据一行。

设置图片路径:点击Open Dir,选择obj文件夹。

修改标注结果存放路径:选择Change Save Dir,修改为txt文件夹。

修改标注格式:点击PascalVOC,使其变为yolo。

标注:按下w,拖动鼠标即可框选出所需的目标,完成框选后选择对应的类名

四、权重训练
1.数据准备
将前述标注结果(txt文件夹内)复制黏贴至图片文件夹中(obj文件夹),注意只需要标注文件,有可能会出现名为classname的文件,请在黏贴时排除此文件,得到图片文件如下: 讲图片文件夹放入如下路径下(D:\yolov3\darknet-master\build\darknet\x64\data)

2.图片路径准备
在data目录(即图片文件夹所在目录)下创建文本文件(文档中命名为train.txt),在该文件中存储图片相对于darknet.exe的路径。

3.CFG文件准备
在..\darknet-master\build\darknet\x64\cfg目录下找到yolov3.cfg文件(对于显存小于4GB的机器请选择yolov3-tiny.cfg文件),将所述文件复制,黏贴至..\darknet-master\build\darknet\x64目录下并改名(文档中改名为yolo-obj.cfg,yolov3-tiny.cfg对应yolov3-tiny-obj.cfg)。
使用文本编辑器打开改名后的文件
注释testing部分参数
![]()
取消training部分参数,注意training本身需要注释
![]()
修改batch=64 subdivisions=8(上图以修改)
修改max_batches数目,设定在类别数目*2000至类别数目*4000之间(例如只有1类则设定在2000-4000之间)

修改steps,分别为max_batches*0.8和max_batches*0.9

修改classes=类别数,filters=(类别数+5)*3 (1类时classes=1,filters=18)
建议使用查找功能,查找文件中的classes,使得每一处修改为下图样式

4.修改name文件和data文件
在..\darknet-master\build\darknet\x64\data目录下创建obj.names文件以及obj.data文件
obj.names文件中存放类名,每一类占据一行

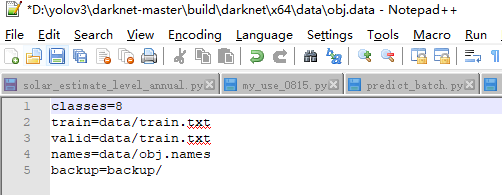
obj.data中存放关键路径,按所给设置修改,自上而下分别是类别数目、训练集路径、测试集路径、类别名路径、结果存放路径
5.下载预计卷积权重文件
yolov3对应版本地址:https : //pjreddie.com/media/files/darknet53.conv.74
yolov3-tiny对应版本地址:https ://pjreddie.com/media/files/yolov3-tiny.weights
将下载后的文件放入..\darknet-master\build\darknet\x64目录下
其中,tiny版本在放入后需要在当前目录中运行cmd,键入:
darknet.exe partial cfg/yolov3-tiny.cfg yolov3-tiny.weights yolov3-tiny.conv.15 15即可得到对应的预卷积权重
6.权重训练
在..\darknet-master\build\darknet\x64目录下运行cmd
Yolov3版本键入:
darknet.exe detector train data/obj.data yolo-obj.cfg darknet53.conv.74Tiny版本键入:
darknet.exe detector train data/obj.data yolov3-tiny-obj.cfg yolov3-tiny.conv.15此时出现一个绘图窗口,其中绘制loss的收敛情况,每1000次在backup中保存当前的权重文件

7.显存不够问题
若出现显存不够的问题,可尝试增加cfg配置文件中的subdivisions值(8的倍数),若多次修改后仍然报错或显存容量小于4GB,请使用tiny版本。


训练得出的结果一般是在D:\yolov3\darknet-master\build\darknet\x64\results路径下:

五、检测
检测是利用置信度筛查的方法提取样本识别结果并加以显示:
@author: 明矾
"""
import numpy as np
import cv2 as cv
#image类
class image:
def __init__(self,imagePath):
# 加载图片、转为blob格式
self.cvimg=cv.imread(imagePath)
self.blobImg=cv.dnn.blobFromImage(self.cvimg, 1.0/255.0, (416, 416), None, True, False)
(self.height,self.width)=self.cvimg.shape[:2]
self.result={'class':[],'confidence':[]}
def distinguish(self,net):
net.setInput(self.blobImg) # 调用setInput函数将图片送入输入层
# 获取网络输出层信息(所有输出层的名字),设定并前向传播
outInfo = net.getUnconnectedOutLayersNames()#yolo在每个scale都有输出,outInfo是每个scale的名字信息,供net.forward使用
layerOutputs = net.forward(outInfo)# 得到各个输出层的、各个检测框等信息,是二维结构
# 过滤layerOutputs
# layerOutputs的第1维的元素内容: [center_x, center_y, width, height, objectness, N-class score data]
# 过滤后的结果放入:
boxes = [] # 所有边界框(各层结果放一起)
confidences = [] # 所有置信度
classIDs = [] # 所有分类ID
# # 1)过滤掉置信度低的框框
for out in layerOutputs: # 各个输出层
for detection in out: # 各个框框
# 拿到置信度
scores = detection[5:] # 各个类别的置信度
classID = np.argmax(scores) # 最高置信度的id即为分类id
confidence = scores[classID] # 拿到置信度
# 根据置信度筛查
if confidence > CONFIDENCE:
box = detection[0:4] * np.array([self.width, self.height, self.width, self.height]) # 将边界框放会图片尺寸
(centerX, centerY, width, height) = box.astype("int")
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
classIDs.append(classID)
# # 2)应用非最大值抑制(non-maxima suppression,nms)进一步筛掉
idxs = cv.dnn.NMSBoxes(boxes, confidences, CONFIDENCE, THRESHOLD) # boxes中,保留的box的索引index存入idxs
# 应用检测结果
np.random.seed(42)
# 框框显示颜色,每一类有不同的颜色,每种颜色都是由RGB三个值组成的,所以size为(len(labels), 3)
COLORS = np.random.randint(0, 255, size=(len(labels), 3), dtype="uint8")
if len(idxs) > 0:
for i in idxs.flatten(): # indxs是二维的,第0维是输出层,所以这里把它展平成1维
(x, y) = (boxes[i][0], boxes[i][1])
(w, h) = (boxes[i][2], boxes[i][3])
color = [int(c) for c in COLORS[classIDs[i]]]
cv.rectangle(self.cvimg, (x, y), (x+w, y+h), color, 2) # 线条粗细为2px
text = "{}: {:.4f}".format(labels[classIDs[i]], confidences[i])
cv.putText(self.cvimg, text, (x, y-5), cv.FONT_HERSHEY_SIMPLEX, 0.5, color, 2) # cv.FONT_HERSHEY_SIMPLEX字体风格、0.5字体大小、粗细2px
self.result['class'].append(labels[classIDs[i]])
self.result['confidence'].append(confidences[i])
def haveClass(self):
if len(self.result['class'])>0:
return True
else:
return False
def saveImg(self,savePath):
cv.imwrite(savePath,self.cvimg)
def show(self):
cv.imshow('detected image',self.cvimg)
cv.waitKey(0)
weightsPath = 'yolo-obj_final.weights' # 权重文件
configPath = 'yolo-obj-test.cfg' # 配置文件
labelsPath = 'obj.names' # label名称
CONFIDENCE = 0 # 过滤弱检测的最小概率
THRESHOLD = 0.4 # 非最大值抑制阈值
# 加载网络、配置权重
net = cv.dnn.readNetFromDarknet(configPath, weightsPath) # 利用配置和权重
# 得到labels列表
with open(labelsPath, 'rt') as f:
labels = f.read().rstrip('\n').split('\n')
# 示例
img=image('3.jpg')
img.distinguish(net)
if img.haveClass():
img.show()
img.saveImg('result-3.jpg')
检测结果:


六、下载链接
openCV 3.4.0 :链接:https://pan.baidu.com/s/16vVfJBzQ47B7B0T1X-csTQ 提取码:gzmp
Yolov3 : 链接:https://pan.baidu.com/s/1g3kEvF3ON4LMBocEUc5dqQ 提取码:ltsh
Yolov3预训练权重: 链接:https://pan.baidu.com/s/1Zp8GA8vwTkn4V19g9CsmKQ 提取码:6cd0
Yolov3预卷积权重:链接:https://pan.baidu.com/s/1ACY4hONFvOsyfyINN0UnEg 提取码:esoj
Yolov3预卷积权重 Tiny:链接:https://pan.baidu.com/s/1JZ4y0yTDzv8kxyM0AMnmiw 提取码:ep5y
有问题可以邮件我 :yangy9803@163.com















 2866
2866











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









