






1.掩码张量
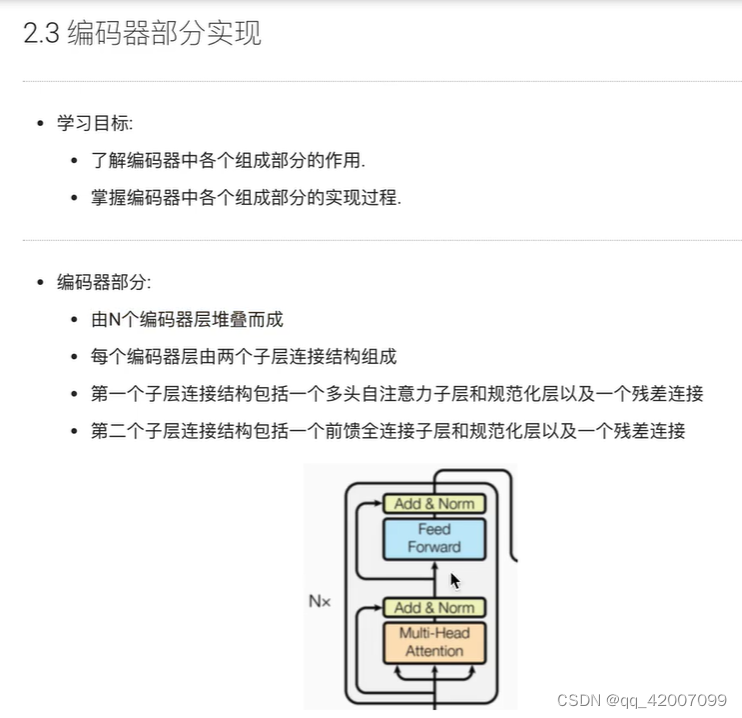

def subsequent_mask(size):
attn_shape = (1,size,size) #代表掩码张量的后两个维度
#先np.one构建一个全1的矩阵,然后利用np.triu()形成上三角
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
return torch.from_numpy(1-subsequent_mask) #使得三角矩阵翻转
size = 5
sm = subsequent_mask(size)
print(sm)
>>>tensor([[[1, 0, 0, 0, 0],
[1, 1, 0, 0, 0],
[1, 1, 1, 0, 0],
[1, 1, 1, 1, 0],
[1, 1, 1, 1, 1]]], dtype=torch.uint8)其中,np.triu(a, k)是取矩阵a的上三角数据,但这个三角的斜线位置由k的值确定。
np.triu([[1,2,3],[4,5,6],[7,8,9],[10,11,12]],k=0)
>>>>array([[1, 2, 3],
[0, 5, 6],
[0, 0, 9],
[0, 0, 0]])
np.triu([[1,2,3],[4,5,6],[7,8,9],[10,11,12]],k=1)
>>>>array([[0, 2, 3],
[0, 0, 6],
[0, 0, 0],
[0, 0, 0]])
np.triu([[1,2,3],[4,5,6],[7,8,9],[10,11,12]],k=-1)
>>>>>array([[ 1, 2, 3],
[ 4, 5, 6],
[ 0, 8, 9],
[ 0, 0, 12]])当np.triu(a, k = 1)时,得到主对角线向上平移一个距离的对角线,也叫右上对角线及其以上的数据。
当np.triu(a, k = -1)时,得到主对角线向下平移一个距离的对角线,也叫左下对角线及其以上的数据,
2.注意力机制
#query, key, value注意力的三个输入
def attention(query, key, value,mask=None, dropout=None):
# 获取query的最后一维的大小,一般情况下就等同于我们的词嵌入维度
d_k = query.size(-1)
#key需要最后两个维度转变(满足矩阵计算规则),再除以缩放系数
# 得到注意力的得分张量scores
scores = torch.matmul(query, key.transpose(-2,-1))/math.sqrt(d_k)
if mask is not None:
# 使用tensor的masked_fill方法,将掩码张量和scores张量每个位置一一比较
# 如果掩码张量处为0 则对应的score张量用-1e9替换
scores = scores.masked_fill(mask==0, -1e9)
p_atten = F.softmax(scores, dim=-1)
if dropout is not None: #是否使用dropout进行随机置零
p_atten = dropout(p_atten) #传入p_atten进行置零
#最后,根据公式将p_attn与value张量相乘获得最终的query注意力输出,同时返回注意力张量
return torch.matmul(p_atten, value.float()), p_atten
query = key = value = pe_result
attn, p_atten = attention(query, key, value)
print('attn',attn)
print(attn.shape)
print('p_atten',p_atten)
print(p_atten.shape)
当query=key=value为自注意力机制。
.mask_fill(x==0,-1e9)表示矩阵x值为0的地方用-1e9填充
x = torch.zeros(4,5)
print(x)
x.masked_fill(x==0, -1e9)
>>>tensor([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])
>>>tensor([[-1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09],
[-1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09],
[-1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09],
[-1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09]])3.多头注意力机制

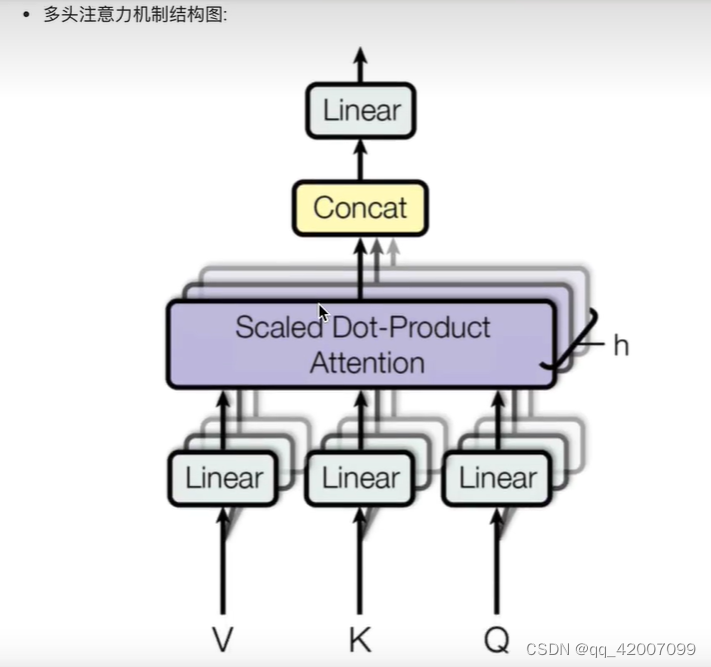
多头注意力机制的作用:
·这种结构设计能让每个注意力机制去优化每个词汇的不同特征部分,从而均衡同一种注意力机制可能产生的偏差,让词义拥有来自更多元的表达。类似于卷积神经网络采样不同的卷积核来提取图片的特征,多头注意力机制同不同的头提取不同的特征。同时可以在多个空间中寻找参数,准确率更高
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads)
self.W_K = nn.Linear(d_model, d_k * n_heads)
self.W_V = nn.Linear(d_model, d_v * n_heads)
self.linear = nn.Linear(n_heads * d_v, d_model)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self,Q,K,V,attn_maks):
residual, batch_szie = Q,Q.size(0) #残差
#映射分头
q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # q_s: [batch_size x n_heads x len_q x d_k]
k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # k_s: [batch_size x n_heads x len_k x d_k]
v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # v_s: [batch_size x n_heads x len_k x d_v]
# 因为是多头,所以mask矩阵要扩充成4维的
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)
#经过一个点击
context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)
#拼接
context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) # context: [batch_size x len_q x n_heads * d_v]
output = self.linear(context)
return self.layer_norm(output + residual), attn # output: [batch_size x len_q x d_model]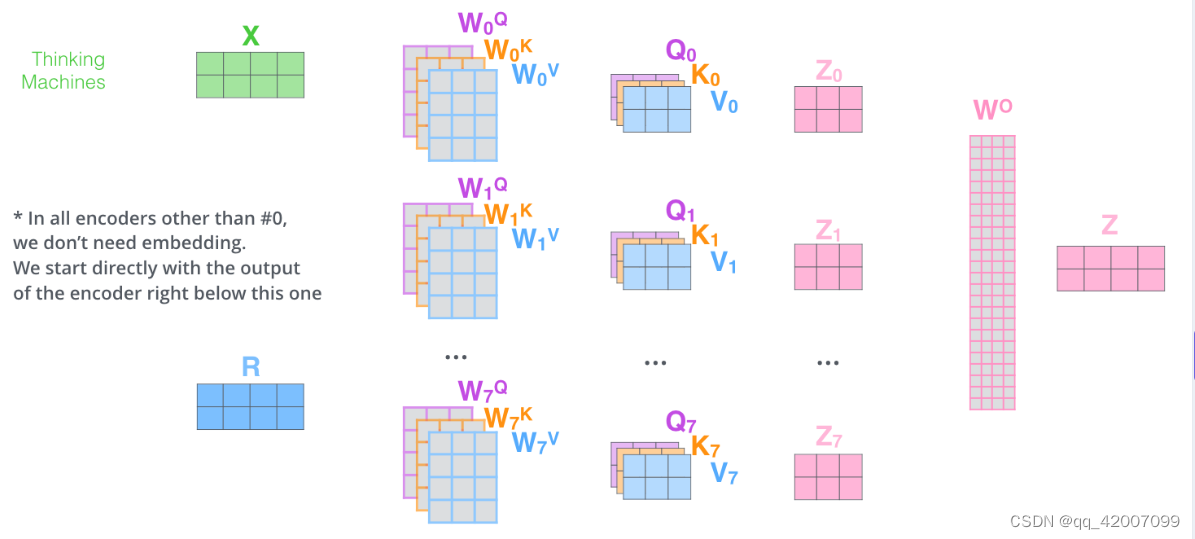
(这里我个人有个不解,为什么多头注意力机制的输入不是经过位置编码的词向量,而是最原始的输入词向量)
接下来,我们对每个部分进行详解。首先,W_Q, W_K, W_V参数矩阵是通过线性变化得到,对于的代码如下:
## 输入进来的QKV是相等的,我们会使用映射linear做一个映射得到参数矩阵Wq, Wk,Wv
self.W_Q = nn.Linear(d_model, d_k * n_heads)
self.W_K = nn.Linear(d_model, d_k * n_heads)
self.W_V = nn.Linear(d_model, d_v * n_heads)
self.linear = nn.Linear(n_heads * d_v, d_model)
self.layer_norm = nn.LayerNorm(d_model)输入为词向量的维度d_model,输出为 d_k * n_heads以及d_v * n_heads。对于Q和K计算注意力的时候需要点积,所以它们的维度需要相同。self.linear层是拼接过后的输出最后还有经过一个线性层;self.layer_norm层是表示在编码器层中,经过多头注意力机制的输出到规范化层。
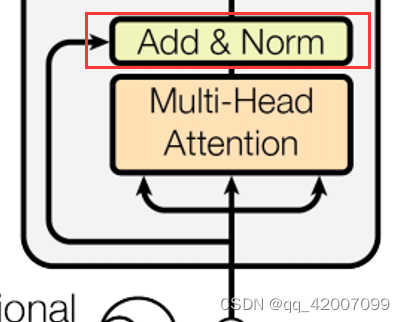
对于前向传播,输入为QKV是相等的,以及掩码张量。首先得到残差residual,
def forward(self, Q, K, V, attn_mask):
residual, batch_size = Q, Q.size(0)
然后计算qkv,输入的qkv都是词向量,维度为[batch_size,sce_len,d_model]。得到qkv的维度是[batch_size , n_heads , len_q , d_k]和[batch_size , n_heads , len_q , d_v]。view()的作用相当于numpy中的reshape,重新定义矩阵的形状。view中一个参数定为-1,代表动态调整这个维度上的元素个数,以保证元素的总数不变。
q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # q_s: [batch_size x n_heads x len_q x d_k]
k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # k_s: [batch_size x n_heads x len_k x d_k]
v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # v_s: [batch_size x n_heads x len_k x d_v] 
得到q_s,k_s,v_s后要进入一个缩放的点积计算相似性得分,
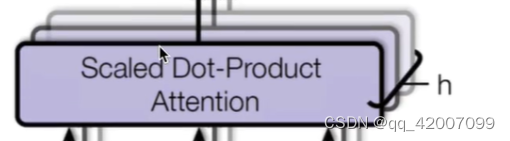
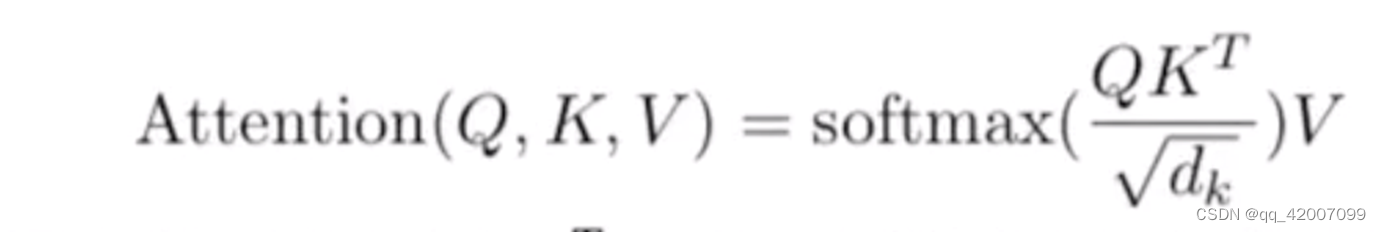
context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)
#其中ScaledDotProductAttention()为:
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
## 输入进来的维度分别是 [batch_size x n_heads x len_q x d_k] K: [batch_size x n_heads x len_k x d_k] V: [batch_size x n_heads x len_k x d_v]
##首先经过matmul函数得到的scores形状是 : [batch_size x n_heads x len_q x len_k]
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
## 然后关键词地方来了,下面这个就是用到了我们之前重点讲的attn_mask,把被mask的地方置为无限小,softmax之后基本就是0,对q的单词不起作用
scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is one.
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V)
return context, attn最后将每个头计算的结果做一个拼接,contiguous()方法语义上是“连续的”,经常与torch.permute()、torch.transpose()、torch.view()方法一起使用,要理解这样使用的缘由。最后得到context的维度是[batch,scr_len,d_model]
context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v)
最后经过一个线性层以及规范化层
output = self.linear(context)
return self.layer_norm(output + residual), attn # output: [batch_size x len_q x d_model]















 610
610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









