









当前的物体检测算法为了保证召回率,对于同一个真实物体往往会有多个的候选框输出。由于多余的候选框会影响检测精度,因此需要利用NMS过滤掉重叠的候选框,得到最佳的预测输出。当前有如下几种较为常见的NMS方法,

1.基本NMS
非极大值抑制, 顾名思义就是抑制不是极大值的边框,这里的抑制通常是直接去掉冗余的边框。

这个过程涉及以下两个量化指标:
1.预测得分:NMS假设一个边框的预测得分越高,这个框就要被优先考虑,其他与其重叠超过一定程度的边框要被舍弃,非极大值即是指得分的非极大值。
2.IoU:在评价两个边框的重合程度时,NMS使用了IoU这个指 标。如果两个边框的IoU超过一定阈值时,得分低的边框会被舍弃。 阈值通常会取0.5或者0.7。
NMS存在一个非常简约的实现方法,算法输入包含了所有预测 框的得分、左上点坐标、右下点坐标一共5个预测量,以及一个设定 的IoU阈值。具体流程如下:
-
按照得分,对所有边框进行降序排列,记录下排列的索引 order,并新建一个列表keep,作为最终筛选后的边框索引结果。
-
将排序后的第一个边框置为当前边框,并将其保留到keep 中,再求当前边框与剩余所有框的IoU。
-
在order中,仅仅保留IoU小于设定阈值的索引,重复第 2步,直到order中仅仅剩余一个边框,则将其保留到keep中,退出循环,NMS结束。
def nms(self, bboxes, scores, thresh=0.5):
x1 = bboxes[:, 0]
y1 = bboxes[:, 1]
x2 = bboxes[:, 2]
y2 = bboxes[:, 3]
# 计算每个box的面积
areas = (x2 - x1 + 1)*(y2 - y1 + 1)
# 对得分进行降序排列, order为降序排列的索引
_, order = scores.sort(0, descending=True)
# keep保留了nms留下了的bbox
keep =[]
while order.numel() > 0:
if order.numel() == 1: # 保留框只有一个
i = order.item()
keep.append(i)
break
else:
i = order[0].item() # 保留scores最大的那个框
keep.append(i)
xx1 = x1[order[1:]].clamp(min=x1[i])
yy1 = y1[order[1:]].clamp(min=y1[i])
xx2 = x2[order[1:]].clamp(min=x2[i])
yy2 = y2[order[1:]].clamp(min=y2[i])
# 求取每一个框与当前框重合部分的面积
inter = (xx2 - xx1).clamp(min = 0)*(yy2 -yy1).clamp(min=0)
# 计算每一个框和当前框的IOU
iou = inter / (areas[i] + areas[order[1:]] - inter)
# 保留IOU小于阈值的边框索引
idx = (iou <= threshold).nonzero().squeeze()
if idx.numel() == 0:
break
order = order[idx + 1]
return torch.LongTensor(keep)
NMS方法虽然简单有效,但在更高的物体检测需求下,也存在如下缺陷:
- 最大的问题就是将得分较低的边框强制性地去掉,如果物体出 现较为密集时,本身属于两个物体的边框,其中得分较低的也有可能被抑制掉,从而降低了模型的召回率。
- 阈值难以确定。过高的阈值容易出现大量误检,而过低的阈值 则容易降低模型的召回率,这个超参很难确定。
- 将得分作为衡量指标。NMS简单地将得分作为一个边框的置信度,但在一些情况下,得分高的边框不一定位置更准,因此这个衡量指标也有待考量。
- 速度:NMS的实现存在较多的循环步骤,GPU的并行化实现不 是特别容易,尤其是预测框较多时,耗时较多。
2.Soft NMS
NMS方法虽有效过滤了重复框,但也容易将本属于两个物体框中得分低的框抑制掉,从而降低了召回率。造成这种现象的原因在于NMS的计算公式:
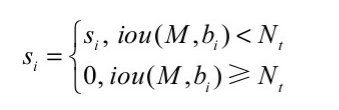
公式中Si代表了每个边框的得分,M为当前得分最高的框,bi为剩余框的某一个,Nt为设定的阈值,可以看到当IoU大于Nt时,该边框的得分直接置0,相当于被舍弃掉了,从而有可能造成边框的漏检。
Soft NMS对于IoU大于阈值的边框,没有 将其得分直接置0,而是降低该边框的得分,
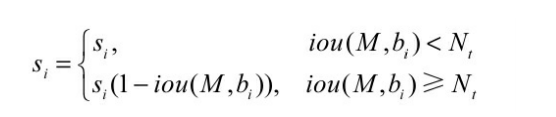
从公式中可以看出,利用边框的得分与IoU来确定新的边框得 分,如果当前边框与边框M的IoU超过设定阈值Nt时,边框的得分呈线性的衰减。
但是,该式并不是一个连续的函数,当一个边框与M的重 叠IoU超过阈值Nt时,其得分会发生跳变,这种跳变会对检测结果产 生较大的波动,因此还需要寻找一个更为稳定、连续的得分重置函 数,最终Soft NMS给出了如下所示的重置函数。
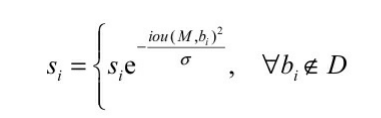
经过多种实验证明,Soft NMS在不影响前向速度的前提下,能够有效提升物体检测的精度。
3.Softer NMS
NMS与Soft NMS算法都使用了预测分类置信度作为衡量指标, 即假定分类置信度越高的边框,其位置也更为精准。但很多情况下并非如此,例如下面两种情形:
- 对于一个真实物体,所有的预测边框都不准,那么这时应该选择哪一个?还是综合所有边框得到更为精准的一个结果?
- 具有高分类置信度的边框其位置并不是最精准的。
因此,位置的置信度与分类置信度并不是强相关的关系,直接使用分类置信度作为NMS的衡量指标并非是最佳选择。基于此现象, Softer NMS进一步改进了NMS的方法,新增加了一个定位置信度的预测,使得高分类置信度的边框位置变得更加准确,从而有效提升了 检测的性能。
首先,为了更加全面地描述边框预测,Softer NMS方法对预测边框与真实物体做了两个分布假设:
1.真实物体的分布是狄拉克delta分布,即标准方差为0的高斯分布的极限。
2.预测边框的分布满足高斯分布。
基于这两个假设,Softer NMS提出了一种基于KL(Kullback- Leibler)散度的边框回归损失函数KL loss。KL散度是用来衡量两个概率分布的非对称性衡量,KL散度越接近于0,则两个概率分布越相似。
具体到边框上,KL Loss是最小化预测边框的高斯分布与真实物体的狄克拉分布之间的KL散度。即预测边框分布越接近于真实物体分布,损失越小
为了描述边框的预测分布,除了预测位置之外,还需要预测边框的标准差,因此Softer NMS提出了如图所示的预测结构。

图中上半部为原始的FastRCNN方法的预测,下半部的网络为SofterNMS提出的方法。可以看到,SofterNMS在原FastRCNN预测的基础上,增加了一个标准差预测分支,从而形成边框的高斯分布,与边框的预测一起可以求得KL损失,由于公式较为复杂,这里就不再展开描述了。
边框的标准差可以被看做边框的位置置信度,因此Softer NMS利 用该标准差也改善了NMS过程。具体过程大体与NMS相同,只不过利用标准差改善了高得分边框的位置坐标,从而使其更为精准。
总体上,Softer NMS通过提出的KL Loss与加权平均的NMS策略,在多个数据集上有效提升了检测边框的位置精度。
4.IoU-Net
在当前的物体检测算法中,物体检测的分类与定位通常被两个分支预测。对于候选框的类别,模型给出了一个类别预测,可以作为分类置信度,然而对于定位而言,回归模块通常只预测了一个边框的转换系数,而缺失了定位的置信度,即框的位置准不准,并没有一个预测结果。
定位置信度的缺失也导致了在前面的NMS方法中,只能将分类的预测值作为边框排序的依据,然而在某些场景下,分类预测值高的边框不一定拥有与真实框最接近的位置,因此这种标准不平衡可能会导致更为准确的边框被抑制掉。 基于此,旷视提出了IoU-Net,增加了一个预测候选框与真实物体之间的IoU分支,并基于此改善了NMS过程,进一步提升了检测器的性能。
IoU-Net的整体结构如图所示,基础架构与原始的Faster RCNN类似,使用了FPN方法作为基础特征提取模块,然后经过RoI 的Pooling得到固定大小的特征图,利用全连接网络完成最后的多任务预测。

总体上,IoU-Net提出了一个IoU的预测分支,解决了NMS过程 中分类置信度与定位置信度之间的不一致,可以与当前的物体检测框 架一起端到端地训练,在几乎不影响前向速度的前提下,有效提升了物体检测的精度。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









