









前言
“物以类聚,人以群分”,同类东西常常放在一起,志同道合的人也常常走在一起。knn算法就是这种思想,要想知道一个东西的类别,可以通过它周围的事物来反映。knn算法是一种分类算法,基于实例的学习(instance-based learning)和懒惰学习(lazy learning)。
概述
K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一,是一种懒惰学习方法(基本不学习)。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表
什么是KNN
KNN(K-Nearest Neighbour)又叫K近邻算法
kNN算法的核心思想是
对一个所要分类的点,求出它与空间中所有点的距离然后找出距离它最近的K 个点,分析距离最近的K 个点中的大部分点属于什么类别那么所要分类的这个点也属于这个类别(可以理解为追随大流)。
具体的讲是: 如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
KNN算法工作原理
存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类对应的关系。当我们输入一个没有标签的数据后,将新数据中的每个特征与样本集中数据对应的特征进行比较,提取出样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k((没错,你猜对了,这个开就是KNN的K))个最相似的数据,这就是k近邻算法中k的出处。最后在k个最相似数据中选择出现次数最多的分类作为新数据的分类。
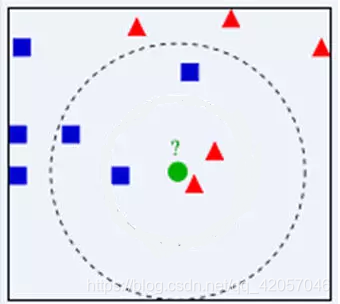
如上图所示,我们现在有一个数据集,数据集中含有11个数据点,其中六个蓝色方块所示的数据代表一类点,五个红色三角形是一类点,我们现在输入一个新的数据点即图中的绿色圆点,我们现在想要求得圆点属于哪一类,首先我们要计算输入数据到样本中每一个数据的距离(一般用欧式距离哈曼或顿距离距算法)在输入中我们会给出一个K(图中k = 5)值,我们将在计算好的距离数据中找出距离输入数据最近的K个样本数据。然后在这K个样本数据中,继续判定输入数据是不同类型的样本数据中的哪一种数据(可以根据数据特征对决策规则进行选取),最后便找出了输入数据所对应的样本数据集中的类型,从图中我们可以看出在K的范围内(圆圈内)蓝色正方形最多,因此,K = 5时,绿色圆点属于蓝色正方向所属的类
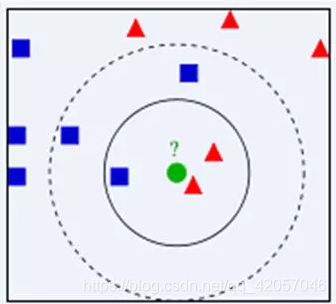
在这里我们在提一下,K的取值对分类的影响,如上图,K = 3是,里输入属于最近的三个点在实现的圆圈内,这是,分类的到的结果,和上面K=5是截然相反
算法步骤
- 计算输入的测试数据与样本数据之间的距离
关于距离的度量方法,常用的有:欧式距离(Euclidean distance),余弦值(cos), 相关度 (correlation), 曼哈顿距离(Manhattan distance)或街区距离(cityblock distance),闵可夫斯基距离(Minkowski distance),切比雪夫距离(Chebyshev distance),汉明距离(Hamming distance)或其他。其中欧氏距离最为常用
- 根据距离远近排序
- 自定义K并选取离测试数据最近的K个点.
- 返回前K个点钟出现频率最高的类别作为该测试数据的类别:多数表决法:
多数表决法类似于投票的过程,也就是在 K 个邻居中选择类别最多的种类作为测试样本的类别。
加权表决法:根据距离的远近,对近邻的投票进行加权,距离越近则权重越大,通过权重计算结果最大值的类为测试样本的类别。
在接下来的学习中我们将补充欧氏距离、曼哈顿距离、决策规则(多数表决法和加权表决法)等将要用到或需要了解的算法和其原理
输入的测试数据和样本数据之间的距离计算

优缺点
优点
1.理论成熟,思想简单,既可以用来做分类又可以做回归
2.可以用于非线性分类
3.训练时间复杂度比支持向量机之类的算法低
3.和朴素贝叶斯之类的算法比,对数据没有假设,准确度高,对异常点不敏感
4.由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属的类别,因此对于类域的交叉或重叠较多的待分类样本集来说,KNN方法较其他方法更为适合
5.该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量比较小的类域采用这种算法比较容易产生误分类情况
缺点
1.计算量大,尤其是特征数非常多的时候
2.样本不平衡的时候,对稀有类别的预测准确率低
3.KD树,球树之类的模型建立需要大量的内存
4.是慵懒散学习方法,基本上不学习,导致预测时速度比起逻辑回归之类的算法慢
5.相比决策树模型,KNN模型的可解释性不强
import numpy as np import operator
from matplotlib import pyplot as plt
#获取数据
def get_data(knn):
#计算 txt 文件的行数
count = len(open(knn).readlines()) #创建矩阵
data = np.zeros(shape = (count,2)) label = np.zeros(shape = (count,1))
label = label.astype(str) i = 0
file = open(knn)
for line in file.readlines():
#strip()消除行首和行尾的空白
#split()以参数为间隔符,提取数据,返回字符串列表
cutline = line.strip().split(',')
data[i,:]= np.array(cutline[0:2],dtype = float) label[i,0] = cutline[2]
i += 1
return data,label.T
#欧氏距离
def Euclidean(dataSet,testdata):
m = np.shape(dataSet)[0]#计算总个数distance = np.zeros(m)
for i in range(m):
distance[i] = np.sqrt( np.sum( np.power( dataSet[i,:] - testdata[0,:] , 2) ) ) return distance
#训练集,测试数据,训练集标签,距离方式,k 值
def Knn(dataSet,dataSet_label,testdata,distance_way,k):
#dist_sort 是 disance 的升序排列的索引列表
dist_sort = distance_way(dataSet, testdata).argsort()
#创建一个{类别:频数}的字典
classcount = {}
#遍历前k 个样本for i in range(k):
label = dataSet_label[0,dist_sort[i]] classcount[label] = classcount.get( label , 0 ) + 1
#classcount_sort 为 classcount 按照 '值' 序列的列表
classcount_sort = sorted(classcount.items(), key = operator.itemgetter(1),reverse = True) #返回频数最高对应的标签
return classcount_sort[0][0]
#主程序
a= get_data('F:\人工智能\数据集\knn1.txt') k=10
dataSet,dataSet_label = a[0],a[1] testdata = np.array([
# [10.0,9.9,10.2,10.1]
# [5.4,3.7,1.5,0.2]
[5.4,3.7]
],dtype = float)
print(" 分 类 结 果 ") lab=Knn(dataSet,dataSet_label,testdata,Euclidean,k) print(lab) #输出分类类型histance=Euclidean(dataSet,testdata) histance.sort()
r=(histance[k+1]+histance[k+2])/2#计算半径'''
#计算每个标签的元素个数
num1 = str(dataSet_label.tolist()).count("Iris-setosa") num2 = str(dataSet_label.tolist()).count("Iris-versicolor") num3 = str(dataSet_label.tolist()).count("Iris-virginica") '''
print("图像展示") #图像展示
def circle(r, a, b): # 为了画出圆,这里采用极坐标的方式对圆进行表示 :x=r*cosθ,y=r*sinθ。 theta = np.arange(0, 2*np.pi, 0.01)#极角
x = a+r * np.cos(theta) y = b+r * np.sin(theta) return x, y
k_circle_x, k_circle_y = circle(r, 5.4,3.7)
plt.figure(figsize=(10, 10)) plt.xlim((4.0,8.0))#x 坐标限制
plt.ylim((2.0,6.0))#y 坐标限制
x_feature = list(map(lambda x: x[0], dataSet)) # 返回每个数据的 x 特征值y_feature = list(map(lambda y: y[1], dataSet)
plt.scatter(x_feature[:50], y_feature[:50], c="b") #标签为 Iris-setosa 的数据plt.scatter(x_feature[50:100], y_feature[50:100], c="g")#标签为 Iris-versicolor 的数据plt.scatter(x_feature[100:], y_feature[100:], c="r")#标签为 Iris-virginica 的数据plt.scatter([5.4], [3.7], c="k", marker="x") # 待测试点的坐标
plt.plot(k_circle_x, k_circle_y)

















 741
741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









