






1,
KNN 是应用于监督式学习的一个简单的分类算法。目的是查找特征空间中最匹配的测试数据。
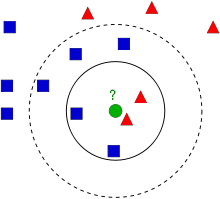
这幅图中有两大家族,蓝色方框与红色三角。我们把家族叫做类,在小镇地图上呈现的是他们的房间,叫做特征空间。(可以想象特征空间就是受保护数据的空间,比如2d坐标空间中,所有的数据都有两个特征,x和y坐标。你可以表示该数据2 d坐标空间,对吧?在想象一下,如果有三个特征,你需要3 d空间,现在考虑N特性,您需要N维空间,对吧?这个n维空间是其特征空间,在我们的图像,你可以认为这是一个2 d两个特性。)
现在新成员进入城镇,创建一个新的家,图示中的绿色圆圈。它要被加入蓝色或红色家族中,这个处理过程叫分类。该怎么办?可以使用KNN来处理这事情。
一种方法就是检查他最近的邻居,是红色三角,这叫邻近采样(Nearest Neighbour),因为分类仅依赖于邻近采样。
但是有一个问题。最近的邻居是红色三角但是有更多的蓝色方框靠近它,蓝色方框比红三角在这个地方有更强势力。所以检查最近的并不够,检查K个邻近来取代,谁占多数,绿色家伙就归入那个家族。在我们的图像中,令k=3,既3个邻近房间,就有2红1蓝(有两个蓝色是等距离的,但是k=3,所以只取之中之一),这样我们还是要把他加入红色家族中。但是当k=7时,有5个蓝2红。太好了,这时就要加入到蓝色家族中,所有的变化取决于k的取值。那么k==4时,2蓝2红。这是平局。所以k要取奇数值。这个;邻近采样的分类取决k个邻近数据。
ANN 考虑的是K个邻近,而我们提供平等的数据也同样重要。对吧?这关乎正义,在这个例子中,我们应该取k=4,我们说这是平局,但是仔细看看,2红与2蓝更靠近,更适合添加到红色家族。那么我们如何用算术来表述?我们按照和新来的家伙的距离给每个家庭一个权重,离得近权重高,离得远权重就低。统计每个家庭的权重,新来的就归权重高的家族。我们叫着为修正KNN。
看到这,有几个重点:
1,需药小镇所有家庭的信息,我们需要计算新来的和每个家庭的距离从而知道最近的家庭。如果有很多家庭和家族,那么需要大量的内存,花费很长时间取计算。
2,任何训练或准备的时间几乎是零
opencv 中的KNN
这里,我们标记红色家族为class-0,蓝色为class-1,创建25个家庭后者25个训练数据,标记他们要么是class-0要么是class-1,这个可以用numpy的随机迭代来实现。
import cv2
import numpy as np
import matplotlib.pyplot as plt
# Feature set containing (x,y) values of 25 known/training data
trainData = np.random.randint(0,100,(25,2)).astype(np.float32)
# Labels each one either Red or Blue with numbers 0 and 1
responses = np.random.randint(0,2,(25,1)).astype(np.float32)
# Take Red families and plot them
red = trainData[responses.ravel()==0]
plt.scatter(red[:,0],red[:,1],80,'r','^')
# Take Blue families and plot them
blue = trainData[responses.ravel()==1]
plt.scatter(blue[:,0],blue[:,1],80,'b','s')
plt.show()你可以得到类似第一张图的数据,每次都可以取得不一样的数据
然后启动KNN 算法,传递traindata和respone。
接着添加一个新家伙,用KNN把他分给家族。
在开始KNN之前,要了解测试的数据。我们的测试数据需要浮点数组,大小是testdata * number of features ,然后找到新来的最近的邻居。我们可以指定多少邻居。
将返回:
1,按照上面的KNN理论,分配给新家伙的标签。如果在KNN中,k就是指定的邻居个数。
2,KNN的所有标签
3,每个邻近点的距离
新来的家伙标记为绿色
newcomer = np.random.randint(0,100,(1,2)).astype(np.float32)
plt.scatter(newcomer[:,0],newcomer[:,1],80,'g','o')
knn = cv2.KNearest()
knn.train(trainData,responses)
ret, results, neighbours ,dist = knn.find_nearest(newcomer, 3)
print "result: ", results,"\n"
print "neighbours: ", neighbours,"\n"
print "distance: ", dist
plt.show()结果是:
result: [[ 1.]]
neighbours: [[ 1. 1. 1.]]
distance: [[ 53. 58. 61.]]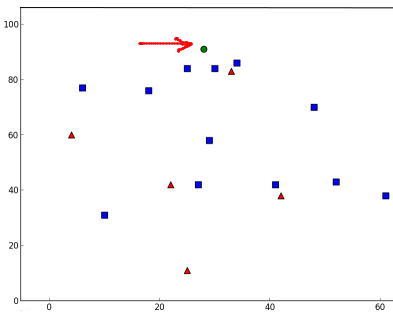
如果是大量的数据,相应的得到的结果也是数组
# 10 new comers
newcomers = np.random.randint(0,100,(10,2)).astype(np.float32)
ret, results,neighbours,dist = knn.find_nearest(newcomer, 3)
# The results also will contain 10 labels.















 268
268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









