







机器学习系列问题(一):MLE和MAP
前言
MLE(Maximum Likelihood Estimation):最大似然估计
MAP( Maximum A Posteriori):最大后验估计
机器学习的本质问题都是目标函数的优化,而MLE和MAP都是产生目标函数的思想。
首先的一个问题,概率与统计一样吗?答案是否定的。概率问题是已知模型参数,推导数据的问题。统计问题是已知数据推导模型参数的问题。很明显,MLE和MAP都是统计问题。
一、条件概率公式和贝叶斯公式
我们先回忆一下条件概率公式和贝叶斯公式
条件概率公式:
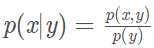
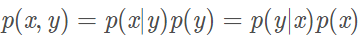
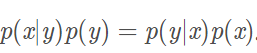
贝叶斯公式:
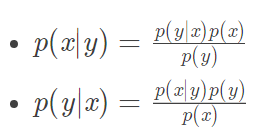
二、MLE和MAP
假设x为数据,y为模型参数
MLE:最大似然估计,就是对似然概率建模,使似然概率P(x|y)最大化,其中x已知,表示对于不同的模型参数,出现x样本点的概率是多少。
MAP:最大后验概率估计,就是对条件概率P(x,y)进行建模,条件概率最大化。
P(x,y)=P(x|y)P(y)
不仅要求似然概率大,同时要求先验概率P(y)最大
你也可以向下面这样理解:
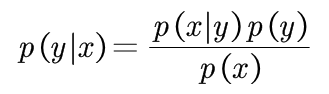
P(x)已知且为定值,一般都设为1;所以有:
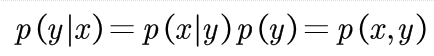
先验概率:P(y)
后验概率:P(y|x)
似然概率:P(x|y)
MAP使条件概率最大化就是使后验概率最大化。
那么到这里,我们根据名字就能辨别他们。
总结如下:
MLE(最大似然估计):就是使似然概率最大化。
MAP(最大后验估计):就是使后验概率最大化。MAP比MLE多考虑了先验概率的影响,或者说MLE认为先验概率P(y)=1
写的不好,如果有问题请及时指出,我会及时纠正。如果您认可我的文章,希望你能关注我的微信公众号,我会不定期更新工作中学到的东西和一些技术比较前沿的东西。


















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











