






1.DeepFM
1.1 DeepFM背景
1)相比于wide&deep,用FM替换了原来的wide部分,加强了浅层网络部分特征组合的能力。原来的Wide 部分依旧依赖人工特征工程,不具备自动的特征组合能力,而DeepFM 模型利用FM 进行特征组合。
2)FM是什么?
Factorization Machine因子分解机,为每个特征学习了一个隐权重向量( latent vector )。在特征交叉时,使用两个特征隐向量的内积作为交叉特征的权重。
FFM引入了特征域(field),每个特征对应的不是唯一一个隐向量,而是一组隐向量。在训练过程中,需要学习n个特征在f个域上的k 维隐向量,参数数量共个nfk个。
3)DNN参数爆炸
在神经网络的参数初始化过程中,往往采用随机初始化这种不包含任何先验信息的初始化方法。由于Embedding 层的输入极端稀疏化,导致Embedding 层的收敛速度非常缓慢。再加上Embedding层的参数数量往往占整个神经网络参数数量的大半以上,因此模型的收敛速度往往受限于Embedding 层。
1.2 DeepFM模型梳理
1.2.1整体架构
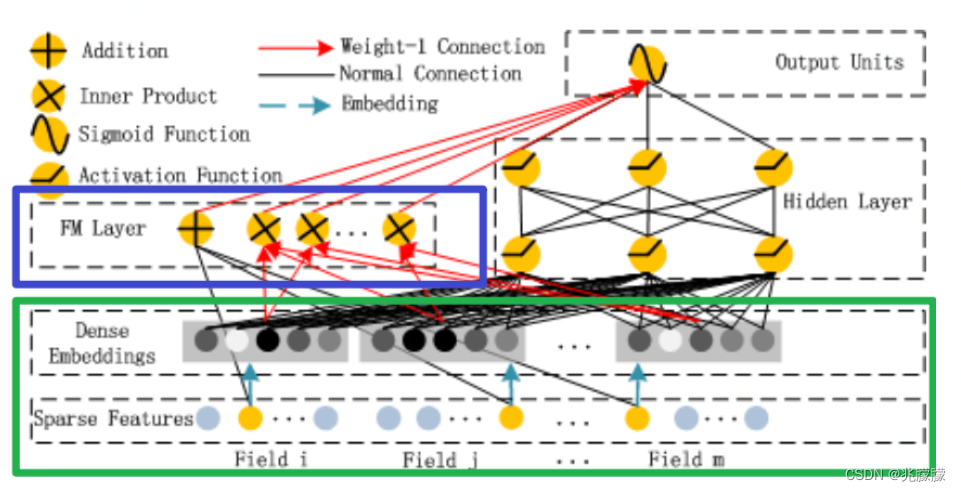
DeepFM主要做法如下:
1.FM Component + Deep Component。FM 提取低阶组合特征,Deep 提取高阶组合特征。但是和 Wide&Deep 不同的是,DeepFM 是端到端的训练,不需要人工特征工程。
2.共享 feature embedding。FM 和 Deep 共享输入和feature embedding不但使得训练更快,而且使得训练更加准确。相比之下,Wide&Deep 中,input vector 非常大,里面包含了大量的人工设计的 pairwise 组合特征,增加了它的计算复杂度。
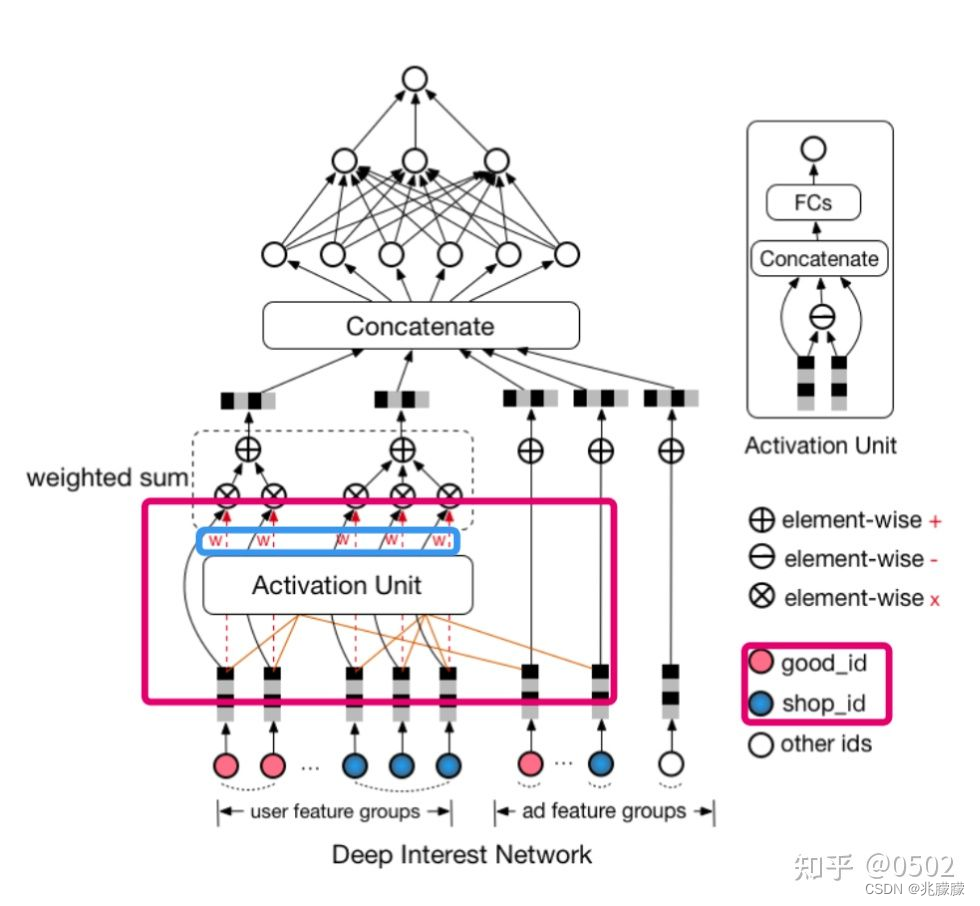
Sparse Feature中黄色和灰色节点代表什么意思:在这个图的Sparse Features中,每个Field代表一个特征的one-hot编码,黄色节点就是值为1,灰色节点就是值为0。Dense Embedding 中灰色的深浅就是这个特征emb之后对应的值的大小。
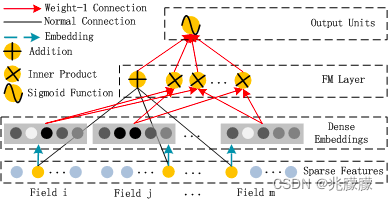
由上面网络结构图可以看到,DeepFM 包括 FM和 DNN两部分,所以模型最终的输出也由这两部分组成:
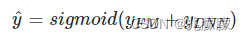
1.2.2FM Component
FM 的输出

【注】由于输入特征one-hot编码,所以embedding vector也就是输入层到Dense Embeddings层的权重。Deep输入层的神经元个数是由embedding vector和field_size共同确定,直观来说就是:神经元的个数为embedding vector*field_size。
FM 模块实现了对于 1 阶和 2 阶组合特征的建模。
1.2.3Deep Component

Deep Component来学习高阶的特征组合,在上图中使用用全连接的方式将Dense Embedding输入到Hidden Layer,这里面Dense Embeddings就是为了解决DNN中的参数爆炸问题,这也是推荐模型中常用的处理方法。
1.3 DeepFM代码实现
from torch_rechub.basic.layers import FM, MLP, LR, EmbeddingLayer
from tqdm import tqdm
import torch
class MyDeepFM(torch.nn.Module):
# Deep和FM为两部分,分别处理不同的特征,因此传入的参数要有两种特征,由此我们得到参数deep_features,fm_features
# 此外神经网络类的模型中,基本组成原件为MLP多层感知机,多层感知机的参数也需要传进来,即为mlp_params
def __init__(self, deep_features, fm_features, mlp_params):
super().__init__()
self.deep_features = deep_features
self.fm_features = fm_features
self.deep_dims = sum([fea.embed_dim for fea in deep_features])
self.fm_dims = sum([fea.embed_dim for fea in fm_features])
# LR建模一阶特征交互
self.linear = LR(self.fm_dims)
# FM建模二阶特征交互
self.fm = FM(reduce_sum=True)
# 对特征做嵌入表征
self.embedding = EmbeddingLayer(deep_features + fm_features)
self.mlp = MLP(self.deep_dims, **mlp_params)
def forward(self, x):
input_deep = self.embedding(x, self.deep_features, squeeze_dim=True)
input_fm = self.embedding(x, self.fm_features, squeeze_dim=False)
y_linear = self.linear(input_fm.flatten(start_dim=1))
y_fm = self.fm(input_fm)
y_deep = self.mlp(input_deep) #[batch_size, 1]
# 最终的预测值为一阶特征交互,二阶特征交互,以及深层模型的组合
y = y_linear + y_fm + y_deep
# 利用sigmoid将预测得分规整到0,1区间内
return torch.sigmoid(y.squeeze(1))
2.DIN
更加关注用户的历史行为序列
2.1 DIN背景
1)之前的Embeding&MLP模型没有利用好用户大量的历史交互行为:对于这种推荐任务一般有着差不多的固定处理套路,就是大量稀疏特征先经过embedding层, 转成低维稠密的,然后进行拼接,最后喂入到多层神经网络中去。这时候根本没有考虑之前用户历史行为商品具体是什么,究竟用户历史行为中的哪个会对当前的点击预测带来积极的作用。 而实际上,对于用户点不点击当前的商品广告,很大程度上是依赖于他的历史行为的。
2)在业务的角度,应该考虑用户的历史行为与当前商品广告的关联性(兴趣):引入注意力机制"local activation unit"。
2.2 DIN模型梳理
输入中有 用户的历史订单商品列表 (浏览)、之类的都行,(每个用户不等长 )
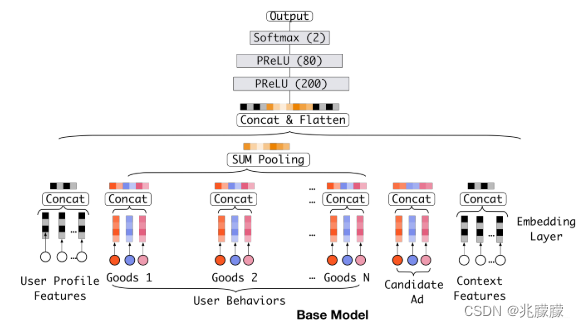
2.2.1 基准模型
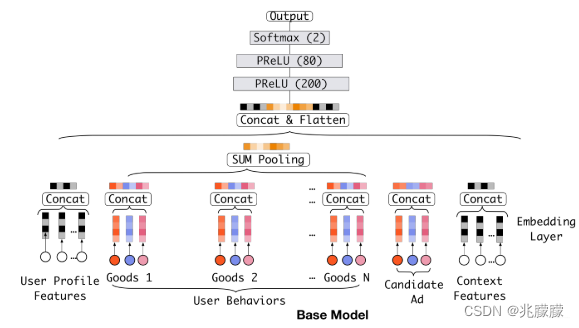
Embedding&MLP基准分为三大模块:Embedding layer,Pooling & Concat layer和MLP
1)Embedding layer:这个层的作用是把高维稀疏的输入转成低维稠密向量, 每个离散特征下面都会对应着一个embedding词典, 维度是D×K, 这里的D表示的是隐向量的维度(64/128), 而K表示的是当前离散特征的nunique。
2)pooling layer and Concat layer: pooling层的作用是将用户的历史行为embedding这个最终变成一个定长的向量。因为每个用户历史购买的商品数是不一样的, 也就是每个用户multi-hot中1的个数不一致,这样经过embedding层,得到的用户历史行为embedding的个数不一样多。
e
i
=
p
o
o
l
i
n
g
(
e
i
1
,
e
i
2
,
.
.
,
e
i
k
)
e_i = pooling(e_{i1},e_{i2},..,e_{ik})
ei=pooling(ei1,ei2,..,eik)
这里的
e
i
j
e_{ij}
eij是用户历史行为的那些embedding。
e
i
e_i
ei就变成了定长的向量。
3)MLP:这个就是普通的全连接,用了学习特征之间的各种交互。
4)Loss: 由于这里是点击率预测任务, 二分类的问题,所以这里的损失函数用的负的log对数似然:

但是,这个模型中1)历史行为和候选商品在进入神经网络之前没有任何交互,2)单纯的综合特征concat,没法再看出到底用户历史行为中的哪个商品与当前商品比较相关,有可能会增加噪声,也丢失了用户的兴趣
因此,DIN通过给定一个候选广告,然后去注意与该广告相关的局部兴趣的表示来模拟此过程。 DIN不会通过使用同一向量来表达所有用户的不同兴趣,而是通过考虑历史行为的相关性来自适应地计算用户兴趣的表示向量(对于给的广告)。 该表示向量随不同广告而变化。
2.2.2 DIN模型结构
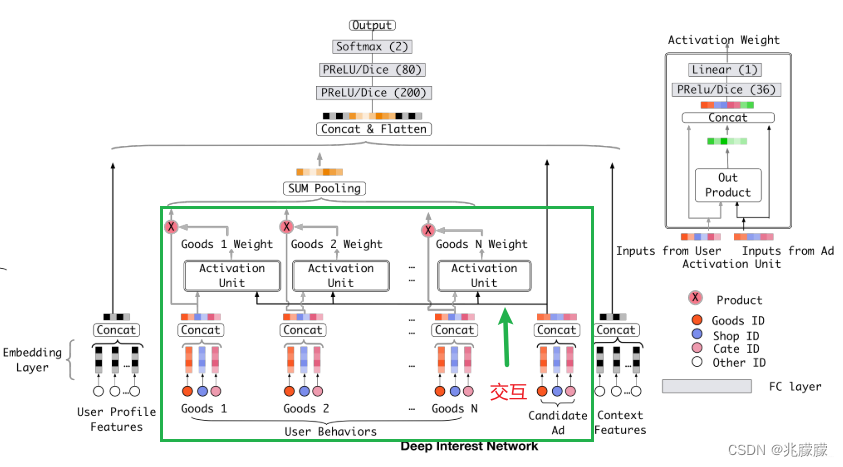
注意力机制的公式
![[公式]](https://img-blog.csdnimg.cn/921890d91e41408d8d94456d164e33ff.png)
其中
V
i
t
e
m
V_{item}
Vitem是候选物的embedding向量,N是用户的N次历史行为(包括购买的商品、浏览的店铺、购买的商品类别),
V
u
i
V_{ui}
Vui 是用户第i次历史行为的embedding向量,
g
(
)
g()
g()是注意力模块函数,
w
u
i
w_{ui}
wui 是用户第i次历史行为对候选物的权重,也叫注意力得分,是通过注意力模块得到的,
f
(
)
f()
f() 是sum pooling,将加权后的embedding向量相加。
【具体的还是通过代码来理解把QAQ】
2.3 DIN代码实现
import torch
import torch.nn as nn
from ...basic.layers import EmbeddingLayer, MLP
class DIN(nn.Module):
"""Deep Interest Network
Args:
features (list): the list of `Feature Class`. training by MLP. It means the user profile features and context features in origin paper, exclude history and target features.
history_features (list): the list of `Feature Class`,training by ActivationUnit. It means the user behaviour sequence features, eg.item id sequence, shop id sequence.
target_features (list): the list of `Feature Class`, training by ActivationUnit. It means the target feature which will execute target-attention with history feature.
mlp_params (dict): the params of the last MLP module, keys include:`{"dims":list, "activation":str, "dropout":float, "output_layer":bool`}
attention_mlp_params (dict): the params of the ActivationUnit module, keys include:`{"dims":list, "activation":str, "dropout":float, "use_softmax":bool`}
"""
def __init__(self, features, history_features, target_features, mlp_params, attention_mlp_params):
super().__init__()
self.features = features
# 用户历史记录特征
self.history_features = history_features
self.target_features = target_features
self.num_history_features = len(history_features)
self.all_dims = sum([fea.embed_dim for fea in features + history_features + target_features])
self.embedding = EmbeddingLayer(features + history_features + target_features)
self.attention_layers = nn.ModuleList(
[ActivationUnit(fea.embed_dim, **attention_mlp_params) for fea in self.history_features])
self.mlp = MLP(self.all_dims, activation="dice", **mlp_params)
def forward(self, x):
embed_x_features = self.embedding(x, self.features) #(batch_size, num_features, emb_dim)
embed_x_history = self.embedding(
x, self.history_features) #(batch_size, num_history_features, seq_length, emb_dim)
embed_x_target = self.embedding(x, self.target_features) #(batch_size, num_target_features候选物品, emb_dim)
attention_pooling = []
for i in range(self.num_history_features):
#使用注意力机制进行转化
attention_seq = self.attention_layers[i](embed_x_history[:, i, :, :], embed_x_target[:, i, :])
attention_pooling.append(attention_seq.unsqueeze(1)) #(batch_size, 1, emb_dim)
#将多个行为序列的attention pooling的embedding进行拼接
attention_pooling = torch.cat(attention_pooling, dim=1) #(batch_size, num_history_features历史记录数据数目, emb_dim)
#输入DNN
mlp_in = torch.cat([
attention_pooling.flatten(start_dim=1),
embed_x_target.flatten(start_dim=1),
embed_x_features.flatten(start_dim=1)
],
dim=1) #(batch_size, N)
y = self.mlp(mlp_in)
return torch.sigmoid(y.squeeze(1))
class ActivationUnit(nn.Module):
"""Activation Unit Layer mentioned in DIN paper, it is a Target Attention method.
Args:
embed_dim (int): the length of embedding vector.
history (tensor):
Shape:
- Input: `(batch_size, seq_length, emb_dim)`
- Output: `(batch_size, emb_dim)`
"""
def __init__(self, emb_dim, dims=None, activation="dice", use_softmax=False):
super(ActivationUnit, self).__init__()
if dims is None:
dims = [36]
self.emb_dim = emb_dim
self.use_softmax = use_softmax
self.attention = MLP(4 * self.emb_dim, dims=dims, activation=activation)
def forward(self, history, target):
seq_length = history.size(1)
target = target.unsqueeze(1).expand(-1, seq_length, -1) #batch_size,seq_length,emb_dim
att_input = torch.cat([target, history, target - history, target * history],
dim=-1) # batch_size,seq_length,4*emb_dim
att_weight = self.attention(att_input.view(-1, 4 * self.emb_dim)) # #(batch_size*seq_length,4*emb_dim)
att_weight = att_weight.view(-1, seq_length) #(batch_size*seq_length, 1) -> (batch_size,seq_length)
if self.use_softmax:
att_weight = att_weight.softmax(dim=-1)
# (batch_size, seq_length, 1) * (batch_size, seq_length, emb_dim)
output = (att_weight.unsqueeze(-1) * history).sum(dim=1) #(batch_size,emb_dim)
return output















 236
236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









