









文章目录
0. 背景:why optuna
-
小模型+参数量少+单卡跑不需要服务器,尝试了一下ray tune不是很适合。。而且很难用。。
-
再三尝试后,决定使用
optuna,选择的原因:- 我这个是小模型,希望调参工具不要太复杂,最好能具有良好的可视化功能
- 和ray tune一样,使用起来都只需要“几行代码”的包装,但是一定要比ray tune操心更少的参数就可以完成任务,或许大模型/分布式更适合ray tune?
- 官方文档新手友好,demo很多(optuna任何一个demo都非常言简意赅)
- 我这里调参以grid search 为主,但是也想尝试一下非grid search的东西
-
我本来是调参的。。结果却调了很多调参的工具老半天,所以分享一些零碎的经验和踩过的坑,查看本文之前最好已经对optuna(或者其他调参工具)的使用方式有一个基本的了解喔,
不要太指望这个写的很碎的教程能帮你从0起步…
0.1 插播一个简单的grid search
- 有一个知乎上的非常简单的grid search的代码,也贴一下,但是这个太简单了,也满足不了我的需求,找不到网址了。代码和荣誉属于这位朋友
# trainable params
parameters = dict(
lr=[.01,.001],
batch_size = [100,1000],
shuffle = [True,False]
)
#创建可传递给product函数的可迭代列表
param_values = [v for v in parameters.values()]
#把各个列表进行组合,得到一系列组合的参数
#*号是告诉乘积函数把列表中每个值作为参数,而不是把列表本身当做参数来对待
for lr,batch_size,shuffle in product(*param_values):
comment = f'batch_size={batch_size}lr={lr}shuffle={shuffle}'
#这里写你调陈的主程序即可
print(comment)
0.2 参考
1. Optuna
1.1 a basic demo与部分参数释义
optimize函数与suggest_float的一个demo
import optuna
def objective(trial):
x = trial.suggest_float("x", 0, 10)
return x**2
study = optuna.create_study()
study.optimize(objective, n_trials=3,show_progress_bar=True)
-
optimize参数:objective: objecticve函数,就是包装一下training的过程,具体参考其他文档n_trials: objecticve函数执行的次数,每次执行都会抽取一个x,抽取规则是suggest_floatshow_progress_bar:多输出一点tuning的进展信息,默认是False,其实设置为True也不会有什么有价值的信息,就像tqdm一样会告诉你现在进行到第几个,还剩几个。
-
suggest_float函数 -
官方文档,值得参考:
-
含义:从0和10中抽取一个float数返回给x,当然如果想返回一个int,使用
suggest_int
1.2 random的问题
- 因为我有一个小小的诉求是,不要每次都重新抽取新的training data组成data loader,我希望 “固定住”training data"的split方式 ,然后观察一些参数的影响。重点在于:
- 已知
optimize会执行objective函数n_trials次,按照官方的写法,是不是每次执行都会重新抽取执行各种random程序:- 经过实验,是的
- 如何设计使得固定住training data?
- 我的方法是:重写
objectivefunction,写成Objectiveclass,因此objective = Objective(params) - 重写之后,一个是可以传递任意的参数给
objective函数(不然只能传一个trial),二是self.attr的值是不会变的
- 我的方法是:重写
- 已知
1.3 Objective方法类
- 参考官方文档
- 当重写之后,可以给objective函数传入自己需要的参数,并且
self.attr的值是不会变的,刚好解决了我需要的一切问题 - 根据官方重写的demo:
import optuna
import numpy as np
class Objective:
def __init__(self, min_x, max_x):
# Hold this implementation specific arguments as the fields of the class.
self.min_x = min_x
self.max_x = max_x
# 注意这里的值不会变喔
self.test_randn = np.random.randn(7)
# 这个trial是必须的(也是唯一的?)
def __call__(self, trial):
# Calculate an objective value by using the extra arguments.
x = trial.suggest_float("x", self.min_x, self.max_x)
print(self.test_randn)
return (x - 2) ** 2
# Execute an optimization by using an `Objective` instance.
# 调用100次Objective function,self.test_randn是不会变的
study = optuna.create_study()
study.optimize(Objective(-100, 100), n_trials=100)
- 我的
Objectiveclass 大概这样:
class Objective:
# 传递dataset以及opt,后者是一个dict,存放了各种不需要tune的参数
def __init__(self, dataset, opt):
# Hold this implementation specific arguments as the fields of the class.
self.dataset = dataset
self.opt = opt
# Hold the data split!!
self.shuffled_indices = save_data_idx(dataset,opt)
def __call__(self, trial):
# Calculate an objective value by using the extra arguments.
# 需要tune的参数
config = {
'learning_rate': trial.suggest_categorical('learning_rate', [5e-2, 1e-2, 5e-3]),
'lr_for_pi': trial.suggest_categorical('lr_for_pi', [1e-2, 5e-2, 1e-3])
}
print("idx check: ",self.shuffled_indices[0:5])
# 每次split出来的data都是一致的
train_loader, val_loader, test_loader = get_data_loader(self.dataset, self.shuffled_indices, self.opt)
model = MLP(self.opt.N_gaussians).to(device)
performance = trainer(train_loader, val_loader, model, config, self.opt, device)
return performance
2. Optuna与grid search
- 为了做到网格搜索
grid search,做了一些必要的修改,其实感觉还是有点笨重 - 修改1: 假设我们这里需要调2个参数,请把他们都设置成
trial.suggest_categorical,而不是什么int或者float,后面的list存放你想尝试的几个数据,比如[5e-2, 1e-2, 5e-3]就是我想尝试的3个数据
config = {
'learning_rate': trial.suggest_categorical('learning_rate', [5e-2, 1e-2, 5e-3]),
'lr_for_pi': trial.suggest_categorical('lr_for_pi', [1e-2, 5e-2, 1e-3])
}
- 修改2: 在实例化一个
study时,加上参数sampler,并且选取GridSampler
# 里面所有的组合被cover之后会自动stop
sampler = optuna.samplers.GridSampler(search_space={
'learning_rate': [5e-2, 1e-2, 5e-3], # 注意这里和config里保持一致
'lr_for_pi': [1e-2, 5e-2, 1e-3] # 注意这里和config里保持一致
})
study = optuna.create_study(study_name=study_name,direction='minimize',storage=storage_name,load_if_exists=True,sampler=sampler,pruner=pruner)
study.optimize(Objective(dataset), n_trials=100,show_progress_bar=True)
- 注意
sampler里面的搜索空间search_space和上面的config保持一致 GridSampler的官方文档非常值得一读:
- 上述修改的作用:
- 即便
n_trials==100,只要搜索完了搜索空间search_space里的全部组合,就会自动停止,比如这里只需要搜索9个参数组合,那么执行9次之后就会自动停止 - 当
config不是suggest_categorical,也可以进行网格搜索,那么依然会等cover全部组合之后自动停止,因此这个时候的试探次可能不止9次
- 即便
3. optuna的sampler
- 正如上面提到的gridsampler,还有其他的sampler方法,官网列出了一个大表介绍了各个方法的优劣,尤其是还贴心的列出来了“复杂度”和建议的
n_trials值,后者还是非常有参考价值的 - 下面介绍笔者用过的两种
3.1 RandomSampler
- 进行独立的随机抽样,所以两次抽样抽到相同的参数值不是没可能的
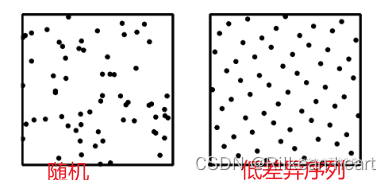
3.2 QMCSampler方法
- 如果想要达到随机的效果(比如learning rate等的测试),但是又不想获得太多的随机性,可以考虑这种方法:准蒙特卡洛Quasi Monte Carlo(QMC) 序列被设计为比标准随机序列具有更低的差异 lower discrepancies。它们在超参数优化方面比标准随机序列表现更好。也就是说他们生成的random序列噪声更少,下图来自这篇介绍低差异序列的博客。
3.3 TPESampler
- 这个是单优化目标的默认sampler方法。
4. optuna的剪枝prune
- optuna有一个默认的剪枝算法,这个剪枝比ray tune默认的早停算法要好多了。。ray tune默认的方法很难调。
- optuna默认的剪枝是
optuna.pruners.MedianPruner,这个的剪枝策略不一定最好但是足够通用,具体可以参考官方文档, - 但是并不是每一次都需要剪枝,不需要剪枝就使用
optuna.pruners.NopPruner():
pruner = optuna.pruners.NopPruner()
study = optuna.create_study(study_name=study_name,direction='minimize',storage=storage_name,load_if_exists=True,sampler=sampler,pruner=pruner)
5. optuna与可视化
5.1 dashboard
-
可视化是为什么我选择optuna的主要原因之一,可视化流程请见相关的官方文档(见0.2 参考),非常轻松加愉快的就执行完毕了。
-
注意:
- 生成的sqlite数据库文件(应该可以这么叫?)的根目录在哪里,就在哪里执行命令打开dashboard
- 实例化study时,参数
study_name指定了数据库文件的名字,如果不指定会默认生成一个,但是注意这个名字的命名规则不允许有空格
optuna.create_study(study_name=study_name,direction='minimize',storage=storage_name,load_if_exists=True,sampler=sampler,pruner=pruner)
-
比如我这里从contour图可以明显看出,
weight_decay这个参数大小的影响:因为metric越小越好(右边的bar中颜色深的是较小值),所以weight decay的值也是越小越好
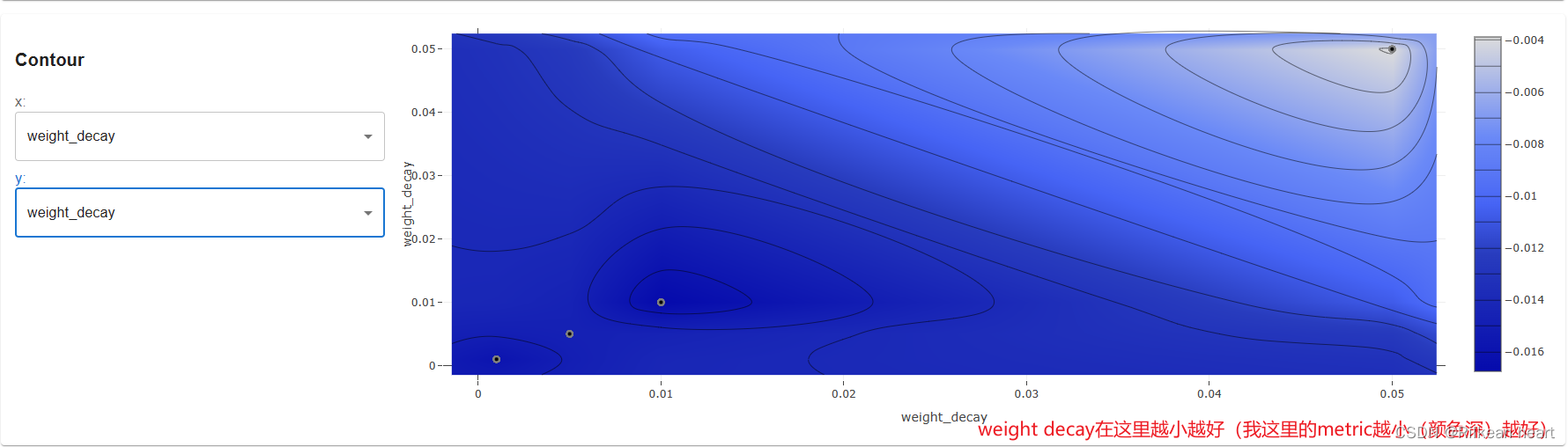
再之,下面的slice图也显示了这一点

-
另外,当我们保存sqlite文件之后,当某次training未完成便被中断后,可以继续train起来:
- 一个是要设置参数
load_if_exists=True,并且记录下study_name
optuna.create_study(study_name=study_name,direction='minimize',storage=storage_name,load_if_exists=True,sampler=sampler,pruner=pruner) - 重新train时,会找到这个
study_name,接着继续之前的training过程:
- 一个是要设置参数
5.2 埋坑: optuna+tensorboard或visdom
- 用过
visdom的朋友应该对optuna dashboard的界面很眼熟,都是plotly风格,一般我绘制loss时会使用visdom,因为实时交互很快。绘制某一层weight或者bias值时,会使用tensorboard。
6. 未完待续
日后希望项目结束可以放上全部代码。希望大家也能留下自己的optuna使用经验。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









