







论文
backbone:
- i3d: https://arxiv.org/abs/1705.07750
- non-local: https://arxiv.org/abs/1711.07971
- slowfast: https://arxiv.org/abs/1812.03982
- csn: https://arxiv.org/abs/1904.02811
- video-swin: https://arxiv.org/abs/2106.13230
dataset:
- kinetics: https://deepmind.com/research/open-source/kinetics
- ava: https://research.google.com/ava/
- activitynet: https://github.com/activitynet/ActivityNet
- hacs: http://hacs.csail.mit.edu/
proposal
localization
- BMN:https://arxiv.org/pdf/1907.09702.pdf
- GTAD:https://arxiv.org/pdf/1911.11462.pdf
- TCANET:https://arxiv.org/pdf/2103.13141.pdf
I3D
i3d: https://arxiv.org/abs/1705.07750
摘要
现在在视频领域内的人体动作分类任务由于数据集数量的不足,使得大多数模型在已存的benchmark上只能得到相似的结果。这篇论文重新评估了SOTA方法在Kinetics数据集上的效果。Kinetics数据集有两套量级的数据,400中人物动作种类,每个种类超过400张切片,数据均来自于真实的具有挑战性的Youtube视频。
同时本文也提出了一个新的双流膨胀3D卷积网络(I3D),从2D卷积网络膨胀而来:深层图像分类卷积网络中的过滤器和池化核被膨胀到3D,使从视频中学习到无间隔的时空特征成为可能,同时还产出了ImageNet架构的设计并平滑了其参数。
任务领域
视频人体动作分类
创新点
使用3D卷积网络对视频中的帧和光流信息进行双流卷积学习。
数据集
kinetics
模型框架


性能
non-local
创新点
参考了自注意力机制,引入了一个non-local block,使特征图的每一个特征都从整个视频在时空3D中的每个像素特征中提取。
模型

Slowfast
摘要
提出了slowfast network,包含:
- 一条慢路,以一个较慢的帧率来提取视频的空间语义。
- 一条快路,以一个较高的帧率来捕获精细时间分辨率下的动作。
此外快路还可以通过减少通道容量来实现轻量化。
关键词
视频动作分类、视频检测、时空双通道
框架


- 慢路:由一个3D残差网络组成,从64帧的原始视频中以16的采样率得到每秒4帧的图像输入。在模型前段,不采用与时间相关的卷积核。只在 r e s 4 res_4 res4 和 r e s 5 res_5 res5中采用时间维度长度大于1的3D卷积核。据称过早地引入时间信息会降低准确率。
- 快路:同样是3D残差网络,但可以采用时间3D卷积,因为它就是要采集时间信息。
- 横向链接:方向从快到慢。三种方法:(都是降低T维度)
- 将时间维度整合到通道上。
- 对时间维度进行采样。
- 进行3D的
5
∗
1
∗
1
5*1*1
5∗1∗1,步长为
α
\alpha
α的卷积。
最后将快慢特征进行求和或拼接。
两个通道的输出通过平均池化层处理后拼接到一起输入到全连接层,最终输出概率。
创新点
- 快路具有高时间分辨率特征。(不采用与时间相关的池化和卷积)
- 快路具有低信道容量。(参考框架图,快路的空间维度是慢路的1/8,这部分是信道容量,时间维度是慢路的8倍,相当于舍弃空间信息,提取时间信息。)卷积计算复杂度 O = C i n ∗ K 2 ∗ H ∗ W ∗ C o u t O=C_{in}* K^2*H* W*C_{out} O=Cin∗K2∗H∗W∗Cout
- 横向连接。用于混合信息。
CSN
摘要
分组卷积在2D图像分类中在减少计算量方面发挥了很大的作用。这篇论文研究了3D分组卷积网络在视频分类任务中的集种不同的设计选择。我们先入为主地认为卷积的通道数量对3D分组卷积的准确率有很大影响。我们的实验有两个主要发现。首先是,将3D卷积按照通道维度和时空维度进行分离可以提高准确率并降低计算成本。第二,3D通道分离卷积提供了一个约束,使训练的准确率降低但提高了测试准确率。这两种发现引导我们设计了一个结构——Channel-Separated Convolutional Network(CSN)。
关键词
视频分类、分组卷积
模型

P3D、R(2+1)D、S3D等模型,他们使用了一个2D卷积和一个1D卷积组合来替代3D卷积,这种方法可以提高准确率并减少计算量。
在图片领域,分离卷积将2D的
k
∗
k
k*k
k∗k的卷积核分成了一个pointwise的
1
∗
1
1*1
1∗1卷积加depthwise的
k
∗
k
k*k
k∗k卷积。当通道数看作
k
2
k^2
k2时,FLOPs也可以减少大约
k
2
k^2
k2。而对3D视频卷积核,FLOP减少量达到
k
3
~k^3
k3。
本文受分离卷积启发,设计了3D Channel-Separated Networks (CSN),其中所有的卷积操作都由
1
∗
1
∗
1
1*1*1
1∗1∗1的pointwise卷积层和或
3
∗
3
∗
3
3*3*3
3∗3∗3的depthwise卷积层来实现。
- 普通卷积:卷积层接受的信息来自于每一个通道。
- 分组卷积:卷积层接受的信息来自于组内的几个通道。
- Depthwise卷积:当每个通道作为一组时,分组卷积变成了Depthwise卷积。
分组卷积的优点:可以降低计算的复杂度,分为 G G G个group时,复杂度降低了G倍。
分组卷积的缺点:限制了信息交互,只有组内的通道信息进行了信息交互。
创新点
我们的论文证明了通道交互设计的重要性。
结果

由fig(b)组成的网络称为ip-CSN结构。
由fig©组成的网络称为ir-CSN结构。

Resnet3D的网络结构,和使用了其他bottleneck的Resnet3D的网络结构。

当模型深度比较深时,减少了通道间交互的模型性能反而提升了。作者认为减少交互也减少了模型过拟合的可能性,提高了模型的泛化性能。

Video Swin Transformer
摘要
将swin transformer从图像应用到视频。提出了一个纯transformer的backbone结构来解决视频识别问题。通过利用视频信息中内在的时空位置信息,时空距离越近的两个像素他们的相关性越高,实现了对因式分解类模型的超越。
swin transformer为了得到空间定位信息和层级、平移不变性,合并了归纳误差。
本文模型严格遵循原始swin transformer,但将局部注意力从空间领域扩展到了时空领域。
当局部注意力在不重叠窗口中计算时,原来Swin Transformer窗口变换机制也改变来适应时空维度的输入。
模型框架

输入视频数据:
T
∗
H
∗
W
∗
3
T*H*W*3
T∗H∗W∗3
patch大小:
2
∗
4
∗
4
∗
3
2*4*4*3
2∗4∗4∗3
patch数量:
T
2
×
H
4
×
W
4
\frac{T}{2} \times \frac{H}{4} \times \frac{W}{4}
2T×4H×4W.其中每个patch包含96维特征。
将patch通过一个线性embedding层得到任意维度
C
C
C的向量。
模型并不沿时间维度进行降采样,这使得我们能继续使用swin transformer的层级结构,因此模型保留了4层的结构,并在每层的patch merging层,进行两倍的空间降采样。patch merging层合并了每组 2 ∗ 2 2*2 2∗2的空间上相连的patches特征,并采用一个线性层将合并后的特征映射到他们维度的一半。例如,线性层会将第二层中每个token的4C维度特征映射到2C维度。
整个架构的主要组成部分是Video Swin Transformer block,其将常规transformer层中的多头自注意力模块替换成基于多头自注意力模块的3D变换窗口模块,并保持其他结构不变。
一个video transformer block 包括一个基于MSA的3D窗口变换和一个反馈网络,包括一个两层的MLP和非线性的GELU激活层。在每个MSA模块前都采用了Layer Normalization层,并在每个模块都采用FFN和差分连接。
3D shifted Window based MSA Module
由于视频数据多出了时间维度,再进行全局的自注意力机制会产生大量的计算需求。因此引入了位置归纳偏置。
MSA on non-overlapping 3D windows:
将图片识别中的2D MSA扩展到3D.
给定视频的3D tokens
T
′
×
H
′
×
W
′
T' \times H' \times W'
T′×H′×W′和3D窗口
P
×
M
×
M
P \times M \times M
P×M×M,窗口可以不重叠的覆盖视频。可以说,视频被窗口分成了
⌈
T
′
P
⌉
×
⌈
H
′
M
⌉
×
⌈
W
′
M
⌉
\lceil{\frac{T'}{P}}\rceil \times \lceil{\frac{H'}{M}}\rceil\times\lceil\frac{W'}{M}\rceil
⌈PT′⌉×⌈MH′⌉×⌈MW′⌉个部分。对于第二层的自注意力模块窗口的划分方式从前一层那种变换成沿着时间、高度和宽度轴划分为
(
P
2
,
M
2
,
M
2
)
(\frac{P}{2},\frac{M}{2},\frac{M}{2})
(2P,2M,2M)个tokens。

模型计算过程:


3D 相对位置偏置
3D QKV注意力公式:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
S
o
f
t
m
a
x
(
Q
K
T
/
d
+
B
)
V
Attention(Q,K,V)=Softmax(QK^T/\sqrt{d}+B)V
Attention(Q,K,V)=Softmax(QKT/d+B)V
TSP
摘要
由于未剪辑的视频所占用的内存容量过大,目前主流的视频定位方法都基于预计算过的视频切片特征来处理的。这些特征往往从视频编码器(由trimmed video分类任务训练)提取出来.本文提出了一个针对切片特征的有监督预训练范式,不仅训练分类活动,还考虑切片背景和全局视频信息来提升时间敏感度。
贡献
- TSP,针对时间敏感监督预训练任务的视频编码器。包含一个能够准确区分未剪辑视频中前景和后景切片的编码器。
- 通过三个视频定位问题展示了TSP的性能。
- 做了额外的实验来展示TSP对时间的敏感性和将前景后景分离的能力。
框架
传统预训练策略
使用trimmed action classification 作为预训练模型来预测untrimmed video的action localization。现在的SOTA的TAL方法对时间维度上下文信息十分敏感,它并不能很好的区分出动作实例和其相关的背景上下文。
如何合并时间敏感度
TAC预训练编码器只从正例中学习。一个好的编码器在面对未剪辑视频时,应当既能区分动作和其上下文也能区分不同的动作。因此我们提出预训练编码器应当能1、对前景切片的类别进行分类,2、判断切片是在动作内还是动作外。
TSP
输入数据。使用未剪辑视频进行预训练。输入数据
X
X
X的形状为
3
×
L
×
H
×
W
3 \times L \times H \times W
3×L×H×W.
X
X
X的标签有两种1.如果切片来自一个前景片段,那么它应当由动作类别标签
y
c
y^c
yc。2.二进制时间领域标签
y
r
y^r
yr表示切片来自前景或动作(
y
r
=
1
y^r=1
yr=1)或者背景或无动作(
y
r
=
0
y^r=0
yr=0)。
局部和全局特征编码。
E
E
E是视频编码器,将切片
X
X
X转换为特征向量
f
f
f,
f
f
f即为局部特征。我们将最大池化特征
f
g
=
m
a
x
(
E
(
X
I
)
)
f^g=max(E(X_I))
fg=max(E(XI))作为全局特征。使用这俩特征来帮助学习区分前景后景。
使用两个分类头。第一个分类头用于分类动作类别;第二个分类头利用局部特征和全局特征,产生一个时序区域逻辑向量
y
^
c
\hat{y}^c
y^c.
损失函数:
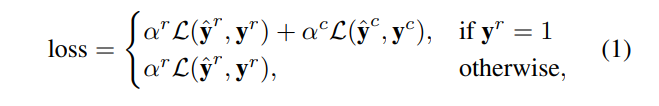
其中
L
L
L为交叉熵损失函数,
α
\alpha
α为平衡权重。
优化细节。时序标记的视频在样本上有天然的不平衡。为了缓解这种不平衡,我们再次下采样了视频切片使前后景的样本数量相同。为了节省显存,我们在训练时在初始化阶段预计算了每个视频的GVF,并冻结了它。

BMN
摘要
参考BSN方法,通过BM confidence map的方式来解决BSN效率低、容易保留边界和多层级但不统一的问题。
框架
















 9162
9162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









