







前言
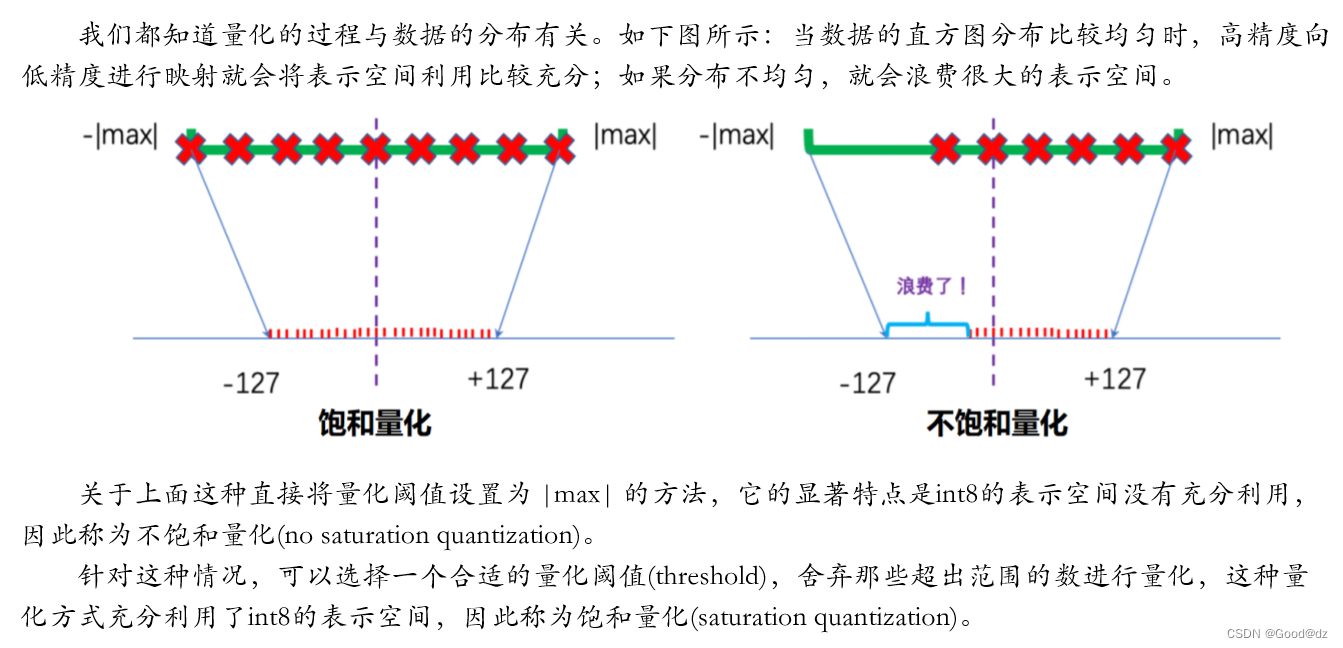
不饱和量化方式的量化范围大,但是可能浪费一些低比特的表示空间从而导致量化精度低
饱和量化方式虽然充分利用低比特表示空间,但是会舍弃一些量化范围。
1. 动态范围的常用计算方法
动态范围(Dynamic Range)指的是输入数据中数值的范围,计算动态范围是为了确定量化时,输入数据中哪些数据需要用于量化。个人理解:考虑到输入数据可能存在数据分布不均,即有些数据偏离过大。而过大的偏离值,会影响求得的scale,进而导致没有充分利用int8的表示空间。
常用的动态范围计算方法方法:
- Max方法:在对称量化中直接取输入数据中的绝对值的最大值作为量化的最大值。这种方法简单易用,但容易受到噪声等异常数据的影响,导致动态范围不准确。
- Histogram方法:统计输入数据的直方图,根据先验知识获取某个范围内的数据,从而获得对称量化的最大值。这种方法可以减少噪声对动态范围的影响,但需要对直方图进行统计,计算复杂度较高。
- Entropy方法:将输入数据的概率密度函数近似为一个高斯分布,以最小化熵作为选择动态范围的准则。这种方法也可以在一定程度上减少噪声对动态范围的影响,但需要对概率密度函数进行拟合和计算熵,计算复杂度较高。
对称量化和非对称量化的选择与动态范围的计算方法有一定的关系:
- 对称量化要求量化的最大值和最小值的绝对值相等,可以采用Max方法或Histogram方法进行计算。
- 非对称量化则可以采用Entropy方法进行计算,以最小化量化后的误差。
下面将对Histogram方法和Entropy方法进行详细介绍
2. Histogram
2.1 直方图的定义
直方图(histogram) 是统计学中常用的一种图形,它将数据按照数值分组并统计每组数据的出现频率,然后将频率用柱状图的方式表示出来。直方图通常用于描述一组数据的分布情况,可以帮助人们了解数据的特征,例如数据的中心位置、离散程度、对称性、峰态等。直方图如下图所示:

生成直方图的代码:
import numpy as np
import matplotlib.pyplot as plt
data = np.random.randn(1000)
plt.hist(data, bins=50)
plt.title("histgram")
plt.xlabel("value")
plt.ylabel("freq")
# plt.savefig("histgram.png", bbox_inches="tight")
plt.show()
2.2 基于Histogram的动态范围实现
为什么要使用Histogram来计算动态范围?
主要在于直方图统计了数据出现的频率,它可以将数据按照一定的区间进行离散化处理,并计算每个区间中数据点的数量。这种方法相对于Max方法来说,能够更好地反映数据的分布情况,从而更准确地评估数据的动态范围。
算法流程
我们假设数据服从正态分布,即离散点在两边,我们可以通过从两边向中间靠拢的方法,去除离散点,类似于双指针的方法,算法具体流程如下:
- 首先,统计输入数据的直方图和范围
- 然后定义左指针和右指针分别指向直方图的左边界和右边界
- 计算当前双指针之间的直方图覆盖率,如果小于等于设定的覆盖率阈值,则返回此刻的左指针指向的直方图值,如果不满足,则需要调整双指针的值,向中间靠拢
- 如果当前左指针所指向的直方图值大于右指针所指向的直方图值,则右指针左移,否则左指针右移
- 循环,直到双指针覆盖的区域满足要求
基于上述算法流程的示例代码:
def scale_cal(x):
max_val = np.max(np.abs(x))
return max_val / 127
# histogram_range函数是基于数据直方图计算缩放因子的。
# 该函数先将数据进行直方图统计。然后,使用双指针算法去除数据直方图中的离散点。最后,通过剩余数据的动态范围计算出缩放因子。
def histogram_range(x):
hist, range = np.histogram(x, 100)
total = len(x)
left = 0
right = len(hist) - 1
limit = 0.99
while True:
cover_percent = hist[left:right].sum() / total
if cover_percent <= limit:
break
if hist[left] > hist[right]:
right -= 1
else:
left += 1
left_val = range[left]
right_val = range[right]
dynamic_range = max(abs(left_val), abs(right_val))
return dynamic_range / 127
if __name__ == "__main__":
np.random.seed(1)
data_float32 = np.random.randn(1000).astype('float32')
# print(f"input = {data_float32}")
scale = scale_cal(data_float32)
scale2 = histogram_range(data_float32)
print(f"scale = {scale} scale2 = {scale2}")
Histogram方法虽然能够解决Max方法中的离散点噪声问题,但是使用数据直方图进行动态范围的计算,要求数据能够比较均匀地覆盖到整个动态范围内。
- 如果数据服从类似正态分布,则直方图的结果具有参考价值,因为此时的数据覆盖动态范围的概率较高。
- 但如果数据分布极不均匀或出现大量离散群,则直方图计算的结果可能并不准确。此时可考虑其它的动态范围计算方法。
3. Entropy
3.1 Entropy的定义
Entropy方法是一种基于概率分布的动态范围计算方法,通过计算概率分布之间的KL散度来选择合适的动态范围。
在模型量化中,通常所用的熵(Entropy)是指量化后的输出值的熵,即量化后的概率分布。因此,使用熵方法计算动态范围就是在计算量化后的概率分布。那么我们该如何度量量化前后的误差呢?可以使用KL散度。
在概率论或信息论中,KL散度(Kullback-Leibler divergence)又称为相对熵(relative entropy),是描述两个概率分布P和Q差异的一种方法。公式如下:
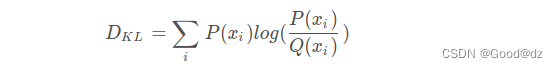
KL散度值越小,代表两种分布越相似,量化误差越小;反之,KL散度值越大,代表二种分布差异越大,量化误差越大。
3.2 基于Entropy的动态范围实现
算法流程
Entropy方法中使用了直方图和概率分布的方法,进而计算动态范围。其流程如下:
- 统计直方图分布。首先,对于待量化的数据,统计其数值分布情况,得到数据的直方图
- 生成p分布和q分布
- 对p和q进行归一化。将p和q的概率分布进行归一化,使其满足概率分布的性质
- 计算p和q的KL散度。使用KL散度方法,计算p和q两个概率分布之间的距离,作为衡量量化误差的指标。KL散度越小表示两个分布越相似,因此在动态范围的选择中,KL散度越小的分布更加合适
在量化操作中,动态范围通常是由P和Q两个概率分布的取值范围决定的。P分布表示原始数据在浮点数表示下的取值范围,Q分布则表示对应的量化数据的取值范围。因此,Entropy方法计算P和Q的KL散度,是为了得到最优的Q分布,而最优的Q分布代表量化数据的最优取值范围,量化数据的最优取值范围和原始数据的取值范围都知道了,那么最优的Scale就确定下来了。
示例代码
下面是通过生成的两组随机数据使用Entropy方法估计数据的动态范围的示例代码:
import numpy as np
import matplotlib.pyplot as plt
# 首先定义了一个计算KL散度的函数cal_kl,用于计算两个概率分布P和Q之间的KL散度
def cal_kl(p, q):
KL = 0
for i in range(len(p)):
KL += p[i] * np.log(p[i]/q[i])
return KL
# 定义了一个kl_test函数,用于使用Entropy方法来估计数据的动态范围。
# 在kl_test中,先随机生成概率分布y,将其归一化后计算与输入的概率分布x之间的KL散度,如果小于阈值,则认为当前的概率分布y最优,结束迭代。否则继续生成一个新的随机概率分布y,重复KL散度计算,直到找到满足条件的最优概率分布
def kl_test(x, kl_threshod = 0.01):
y_out = []
while True:
y = [np.random.uniform(1, size+1) for i in range(size)]
y /= np.sum(y)
kl_result = cal_kl(x, y)
if kl_result < kl_threshod:
print(kl_result)
y_out = y
plt.plot(x)
plt.plot(y)
break
return y_out
if __name__ == "__main__":
np.random.seed(1)
size = 10
x = [np.random.uniform(1, size+1) for i in range(size)]
x /= np.sum(x)
y_out = kl_test(x, kl_threshod = 0.01)
plt.show()
print(x, y_out)
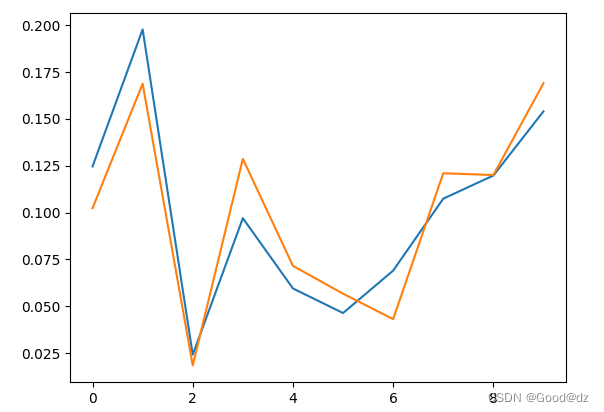
下面是KL散度阈值为0.01时原始数据x(蓝色)和最优概率分布y(橙色)的可视化图,可以看到此时的x和y的分布比较接近:
实际应用
在上面的示例代码,存在一个问题就是求取KL散度有一大前提,就是通过直方图统计的P和Q分布的bin必须要保持一致,而实际情况上不是这样的。比如说假设P是FP32的概率分布,而Q是INT8的概率分布,由于FP32的数据量大,我们可以划分很细(如2048个bin),而INT8的bin数量固定,二者bin并不一致。
我们来看看TensorRT的解决方案,通过下面的示例说明:
假设我们的输入为[1,0,2,3,5,1,7]为8个bin,但Q只能用4个bin来表达,怎么操作才能让Q拥有和P一样的bin来描述呢?
- 数据划分:按照合并后的bin将输入划分为4份即[1,0],[2,3],[5,3],[1,7]
- 对划分的数据求和:sum = [1],[5],[8],[8]
- 统计划分的数据的非0个数:count = [1],[2],[2],[2]
- 求取平均:avg = sum / count = [1],[2.5],[4],[4]
- 反映射:非零区域用对应的均值区域填充即[1,0],[1,1],[1,1],[1,1] * [1],[2.5],[4],[4] = [1,0,2.5,2.5,4,4,4,4]
现在我们通过编写简单的代码进行实验验证,示例代码如下:
def smooth_data(p, eps = 0.0001):
is_zeros = (p==0).astype(np.float32)
is_nonzeros = (p!=0).astype(np.float32)
num_zeros = is_zeros.sum()
num_nonzeros = p.size - num_zeros
eps1 = eps * num_zeros / num_nonzeros
hist = p.astype(np.float32)
hist += eps * is_zeros + (-eps1) * is_nonzeros
return hist
def smooth_data(p, eps = 0.0001):
is_zeros = (p==0).astype(np.float32)
is_nonzeros = (p!=0).astype(np.float32)
num_zeros = is_zeros.sum()
num_nonzeros = p.size - num_zeros
eps1 = eps * num_zeros / num_nonzeros
hist = p.astype(np.float32)
hist += eps * is_zeros + (-eps) * is_nonzeros
return hist
if __name__ == "__main__":
p = [1, 0, 2, 3, 5, 3, 1, 7]
bin = 4
split_p = np.array_split(p, bin)
q = []
for arr in split_p:
avg = np.sum(arr) / np.count_nonzero(arr)
print(avg)
for item in arr:
if item != 0:
q.append(avg)
continue
q.append(0)
print(q)
p /= np.sum(p)
q /= np.sum(q)
print(p)
print(q)
p = smooth_data(p)
q = smooth_data(q)
print(p)
print(q)
print(cal_kl(p, q))
有几个值得注意的点:
- 假设p是直方图统计的频次,其概率计算直接使用p /= sum§
- 在计算KL散度时,要保证q(i) != 0,需要加上一个很小的正数eps
- 由于p和q都是直方图统计的概率分布,它们的和始终为1,因此,单纯的在q(i)==0时加上eps是行不通的,要在其他时刻同时减去一个数,确保最终的概率和为1。smooth_data就是帮我们干这么一件事情。
发现求取KL散度有一个大前提,那就是通过直方图统计的P和Q分布的bin要保持一致,而实际情况是不一致的,不同情况应该怎么解决呢?
# 第一种情况(能整除):
假设input_p=[1,0,2,3,5,6,7,8],dst_bins =4
第一步:计算stride
stride =input.size / bin 取整
第二步:按照stride划分
[1,0] [2,3] [5,6] [7,8]
第三步:判断每一位是否非零
[1,0,1,1,1,1,1,1]
第四步:将多余累加到最后整除的位置上,在上面无多余多,最后整除的位置是[8]。因此,[0+8=8]进行替换
[1,0] [2,3] [5,6] [7,8]
第五步:进行位扩展从而得到output_q
将4的结果和3的非零位进行一个映射得到最终的结果
[1,0] [2.5,2.5] [5.5,5.5] [7.5,7.5]
# 第二种情况(不能整除):
## 示例一
假设input_p=[1,0,2,3,5] dst_bis=4
第一步:计算stride
stride =input.size / bin 取整
第二步:按照stride划分
[1] [0] [2] [3] *[5](多余位)*
第三步:判断每一位是否非零
[1,0,1,1,1]
第四步:将多余累加到最后整除的位置上,在上面无多余多,最后整除的位置是[8]。因此,[0+8=8]进行替换
1] [0] [2] [8]
第五步:进行位扩展从而得到output_q
将4的结果和3的非零位进行一个映射得到最终的结果
[1] [0] [2] [4] [4]
## 示例二
假设input_p=[1,0,2,3,5,6] dst_bis=4
第一步:计算stride
stride =input.size / bin 取整
第二步:按照stride划分
[1] [0] [2] [3] *[5] [6](多余位)*
第三步:判断每一位是否非零
[1,0,1,1,1,1]
第四步:将多余累加到最后整除的位置上,在上面多余位是[5]和[6],最后整除的位置上是[3],因此[5+6+3=14]进行替换
1] [0] [2] [14]
第五步:进行位扩展从而得到output_q
将4的结果和3的非零位进行一个映射得到最终的结果
[1] [0] [2] [4.67] [4.67] [4.67]


















 3103
3103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









