







《Beyond Part Models: Person Retrieval with Refined Part Pooling》
论文连接:https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1711.09349
github:https://github.com/syfafterzy/PCB_RPP_for_reID(不过作者好像没有提供模型checkpoints,也就是需要自己训练)
PCB-RPP是针对Person ReID任务提出的一种简单有效的框架,其核心是两个部分:Part-based Convonlutional Baseline(PCB)和Refined Part Pooling(RPP)。

-
背景简介:
当前Person ReID领域的SOTA模型一般是“part-informed deep features”(也就是用深度学习的方法提取人体各个部分的特征),基于这种策略的模型性能十分依赖于划分策略(partition strategies)。当前的划分策略大致可分为两类:
第一类使用外部信息,比如利用人体姿态估计来做划分;抛开代价不说,当前人体姿态估计和人物检索的数据集存在一些偏差,从而对在人物图像上的语义划分造成困扰。或者说,姿态估计的检测结果存在噪声,这会干扰ReID部分的性能。
第二类则不需要语义部分的信息,即“require no part labeling”,本文的模型就是属于这一类。 -
PCB:
Part-based Convonlutional Baseline,采取的是一种“硬划分”策略,即将输入图片的卷积特征水平划分为6部分,并对每个部分做Average Pooling、1*1 Conv,得到6个列向量特征(这6个向量进行拼接即可作为图像的特征描述子)。最终分别接入6个分类器做ID预测即可(分类器由FC层和Softmax组成)。

-
RPP:
Refined Part Pooling,这部分则是一种“软划分”策略,它是基于PCB硬划分后的一次refine,使各个part的划分更准确。RPP的基本思想是,每个part的信息应该是连续的(consistent),而基于PCB划分的part中通常会有一些局外信息(outliers),这些信息或许应属于临近的其他part(即inconsistency)。因此,RPP的做法是,将这些outliers重定位到邻近的part来强化within-part consistency (Fig.3:within-part inconsistency)。

具体来说,基于bacnbone和PCB划分的输出特征Tesnsor T(见Fig.1.),作者使用分类器来判定Tensor T中每个列向量特征f(见Fig.1. “a column vector f”)更应属哪一个Part(分类器即Softmax(WiT*f))。基于分类结果来对每个f重定位,从而实现基于PCB“硬”划分的“软”refine。
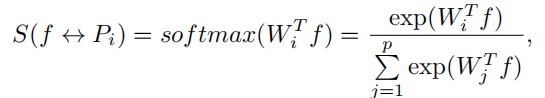
有了这种思路,那么在“no part labeling”情况下,RPP是如何训练的呢?这也是本文的一大亮点,其算法如下图(Algorithm 1,原文Section 3.4)。即,先训练PCB结构,然后将part classifier接入到Tensor T后面,即将其作为新的part strategy。固定其他参数而只开放part classifier的参数,继续训练直到收敛。最后,开放所有参数进行finetune。
这里的Step 3是RPP训练的核心,它利用PCB的预训练信息作为诱导(induction)来使part classifier的预测结果趋近于PCB原本的硬划分策略(original uniform partition)(即若某个f本身属于Part1,,若classfier将其分类为Part5,则很可能受到惩罚),而softmax分类器本身又趋向于将类似的信息归为一类。通过这两个作用的叠加来使得part classifier既能将f重定位到原硬划分Part的附近,又将f划分到更合理的附近Part上。
另外,作者在Section 4.5也说明了这种诱导式训练(Induction)和注意力机制(Attention Mechanism)的区别,并用实验证实了诱导式训练的有效性。

-
总结:
最终,模型的整体框架如下图(Fig.4.)。PCB部分比较常规,主要是是用了硬划分策略,并通过实验证实,使用卷积描述子比全连接描述子更有效(Convolutional Descriptor VS FC Descriptor)。RPP部分的思路很新颖,且足够简单(不需要外部信息,也不需要额外标注),只需要增加一些训练步骤即可达到优秀的效果。另外,RPP的诱导式训练策略很新颖,这是很值得思考和借鉴的部分(类似于弱监督版的注意力机制训练)。
不过,个人认为这种part-level的特征提取策略对于实际人物特征变化的鲁棒性是一个值得存疑的部分。

-
实验结果:
















 351
351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









