






题目:Communication in Multi-Agent Reinforcement Learning: Intention Sharing
出处:International Conference on Learning Representations (ICLR,2021),深度学习顶级会议。
摘要:在多智能体系统中,通信是学习协调行为的核心组件之一。在本文中,我们提出了一种新的通信方案,名为意图共享(IS),用于多智能体强化学习,以增强智能体之间的协调。在提出的IS方案中,每个agent通过对环境动力学和其他agent的行为进行建模,生成一条想象的轨迹。想象的轨迹是基于环境动力学和其他agent的学习模型的每个agent的模拟未来轨迹,代表每个agent的未来行动计划。每个智能体压缩该想象轨迹,捕捉其未来行动计划,通过应用注意机制,根据从其他智能体接收到的消息,了解想象轨迹中组件的相对重要性,从而生成其通信意图消息。数值结果表明,在多智能体强化学习中,该方案明显优于其他通信方案。
1,引言
强化学习(RL)在机器人和游戏等各种复杂控制问题上取得了显著的成功(Gu等人(2017);Mnih等人(2013年);Silver等人(2017年)。多智能体强化学习(MARL)将RL扩展到多智能体系统,对许多实际问题进行建模,如互联汽车和智能城市(Roscia et al.(2013))。由于多智能体学习的本质,MARL中存在着几个明显的问题(Gupta等人(2017年);Lowe等人(2017年)。其中一个问题是如何学习多个智能体之间的协调行为,已经提出了解决这个问题的各种方法(Jaques等人(2018年);佩斯和蒙大拿州(2019年);Kim等人(2020年)。学习协调行为的一种有希望的方法是学习多个智能体之间的通信协议(Foerster等人(2016);Sukhbatar等人(2016年);江路(2018);达斯等人(2019年)。最近关于MARL沟通的研究采用基于差异沟通渠道的端到端训练(Foerster等人(2016);江路(2018);达斯等人(2019年)。也就是说,在每个智能体上定义一个消息生成网络,并通过通信信道连接到其他智能体的策略或批评网络。然后,网络中的批评者使用梯度来训练信息的生成。通常情况下,消息生成网络以当前观测或以观测作为输入的循环网络的隐藏状态为条件。因此,经过训练的消息对过去和当前的观察信息进行编码,以最小化其他智能体的策略或批评损失。研究表明,由于共享观测信息的能力,在部分可观测环境中,这种通信方案与MARL中广泛使用的无通信MARL算法(如独立学习)相比具有良好的性能。
在本文中,我们考虑以下问题在MARL中进行通信:如何利用交流带来的好处,而不仅仅是分享部分观察。
我们建议将每个智能体的意图作为消息的内容来解决上述问题。在人类社会等自然多智能体系统中,使用通信来共享意图已经得到了广泛的应用。
例如,司机使用信号灯通知其他司机他们的意图。如果左车道的驾驶员打开右信号灯,则汽车驾驶员可能会减速。在这种情况下,信号灯对驾驶员的意图进行编码,这表明驾驶员未来的行为,而不是当前或过去的观察,如视野。通过使用信号灯分享意图,驾驶员可以相互协调驾驶。在本文中,我们形式化并提出了一种新的MARL通信方案,名为意向共享(IS),以超越现有的MARL通信观测共享方案。所提出的IS方案允许每个智能体以编码的想象轨迹的形式与其他智能体共享其意图。也就是说,每个智能体通过对环境动力学和其他智能体的行为建模,生成一个想象的轨迹。然后,每个智能体使用注意模型,根据从其他智能体接收到的消息,学习想象轨迹中组件的相对重要性。注意模型的输出是一个编码的想象轨迹,捕捉了agent的意图,并用作通信消息。我们在多个需要多智能体协调的多智能体环境中对所提出的IS方案进行了评估。数值结果表明,该方案明显优于其他现有的MARL通信方案,包括最先进的算法,如ATOC和TarMAC。
2,相关工作
在训练和执行阶段之间学习资源不对称的情况下,最新的MARL研究采用了集中训练和分散执行(CTDE)框架,该框架假设训练阶段所有系统信息的可用性和执行阶段的分布式策略(Lowe et al.(2017);福斯特等人(2018年);伊克巴尔和沙(2018);Kim等人(2020年)。在CTDE框架下,学习通信协议被认为可以提高各种多智能体任务在分散执行阶段的性能(Foerster et al.(2016);江路(2018);达斯等人(2019年)。为此,Foerster等人(2016)提出了可微的智能体间学习(DIAL)。DIAL通过将消息生成网络连接到其他智能体的Q网络,并在训练阶段允许通过通信通道的梯度流来训练消息生成网络。然后,在执行阶段,生成消息并通过通信通道传递给其他智能体。Jiang&Lu(2018)提出了一个名为ATOC的注意沟通模型,以了解何时进行沟通,以及如何通过基于注意机制的沟通整合从其他智能体接收到的信息。Das等人(2019年)提出了有针对性的多智能体通信(TarMAC)来学习消息生成网络,以便根据基于签名的注意模型为不同的智能体生成不同的消息。上述算法中的消息生成网络以当前观测或LSTM的隐藏状态为条件。在部分可观测的环境下,这种对过去和当前观测进行编码的信息是有用的,但不会捕获任何未来信息。在我们的方法中,我们不仅使用当前信息,还使用未来信息来生成消息,并且根据环境自适应地学习当前信息和未来信息之间的权重。这将进一步提高性能,我们将在第5节中看到。
在我们的方法中,捕捉每个智能体意图的编码想象轨迹被用作MARL中的通信消息。想象的轨迹也用于其他问题。Racani`ere等人(2017年)利用想象轨迹将其扩展到政策和批评中,以便在单智能体RL中结合基于模型和无模型的方法。结果表明,在性能和数据效率方面,任意想象的轨迹(使用随机策略或自己的策略推出的轨迹)对于单智能体RL是有用的。Strouse et al.(2018)引入了信息正则化器,以便在多目标MARL环境中,向其他智能体共享或隐藏智能体的意图,其中一些智能体知道目标,而其他智能体不知道目标。通过最大化(或最小化)目标和行动之间的相互信息,知道目标的智能体学会在合作(或竞争)任务中向不知道目标的其他智能体分享(或隐藏)其意图。他们表明,在合作的情况下,分享意图是有效的。
除了我们的方法之外,心理理论(ToM)和对手建模(OM)也使用意图的概念。Rabinowitz et al.(2018)提出了心理网络理论(ToM net),通过元学习预测其他主体的行为。Raileanu等人(2018年)提出了自我-其他建模(SOM),以在线方式推断其他智能体的目标。ToM和OM都利用预先预测其他智能体的行为来捕捉意图。我们的方法和上述两种方法是我们用交流来分享意图,而不是推理。也就是说,我们方法中的智能体允许其他智能体通过通信直接了解他们的意图,而ToM和OM中的智能体应该自己了解其他智能体的意图。此外,我们的方法中的信息包括通过推出策略获得的未来信息,而 ToM 和 CM 仅预测当前或下一时间步信息。
3,系统模型
我们考虑了一个部分可观测的N-agent马尔可夫博弈(LITTMAN(1994)),并假设Agent之间的通信是可用的。在时间步
,智能体
观察自己的观察
,它是全局环境状态
的一部分,基于自己的观察
加上从其他智能体收到的消息
,选择动作
和信息
。我们假设智能体
被发送到所有其他智能体,并在下一个时间步,即时间步
,在其他智能体处可用。在
的联合作用产生下一个环境状态
,并根据转移概率
和奖励函数
,分别,其中
和
分别是环境状态空间和联合行动空间。Agent
最大化其折扣收益
。因此,Agent
其中
,
分别是共同策略和折扣因子。
4,未来意图分享
IS方案背后的关键思想是,多个智能体通过发送隐含的未来计划与其他智能体进行通信,这些计划承载了他们的意图。接收到的捕获其他智能体意图的消息使智能体能够与其他智能体协调其操作。我们现在描述所提出的IS方案的体系结构。在时间步
还有一条消息
根据自己的观察
,其中
是智能体
- 想象轨迹生成模块(ITGM):每个agent通过ITGM生成一个想象的轨迹,并通过AM学习想象轨迹中每个想象步骤的重要性。
- 保持模块(AM):AM的输出是一个编码的想象轨迹,反映了想象步骤的重要性,并用作通信信息。所提出的IS方案的总体架构如图1所示。
4.1,想象轨迹生成模块(ITGM)
ITGM的作用是产生下一个设想的步骤。ITGM将收到的消息、观察结果和行动作为输入,并将预测的下一次观察结果和预测的行动作为输出。通过叠加ITGM,我们生成了一个想象的轨迹,如图1所示。对于时间步长
长度的想象轨迹定义为:
其中
是时间步长
的想象步长。注意,
是观察和行动的真实值,但除了
之外的想象步骤是预测值。
ITGM由一个推出策略和两个预测因子组成:其他智能体的行动预测因子
(我们将此预测因子简称为行动预测因子)和观察预测因子
。首先,我们对动作预测器进行建模,该预测器将观察作为输入,并生成其他智能体的预测动作。动作预测器的输出如下所示:
注意,动作预测器可以通过对手建模方法进行训练,可以将收到的消息作为输入。接下来,我们对观察预测因子
进行建模,这取决于观察结果
和动作预测器
的输出。这里,我们采用动力学函数来预测下一次观测和当前观测之间的差异
而不是(Nagabandi et al.(2018))中提出的下一个观察结果
,以减少学习早期的模型偏差。因此,下一个观察结果可以写成:
通过将预测的下一个观察结果和接收到的消息注入ITGM中的推出策略,我们获得了预测的下一个动作
。在这里,我们使用当前策略作为推出策略。结合
和
,我们在时间步长
。为了产生
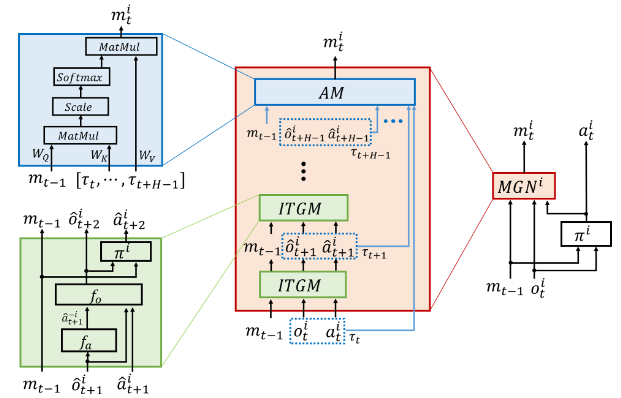
4.2,注意模块(AM)
而不是使用想象的轨迹
直接作为信息,我们运用注意机制来学习想象步骤的相对重要性,并根据相对重要性对想象轨迹进行编码。我们采用(Vaswani et al.(2017))中提出的缩放点产品关注度作为我们的AM。我们的AM由三个组件组成:查询、键和值。AM的输出是值的加权和,其中值的权重由查询和相应键的点积决定。在我们的模型中,查询由接收到的消息组成,键和值由想象的轨迹组成。对于时间步
其中
,
并且
是可学习的参数,操
表示向量的串联。用于信息的注意模型的输出
其中,权重向量
计算为:
每个值的权重由相应键和查询的点积计算。由于想象的轨迹和接收到的消息的投影分别用于键和查询,因此可以将权重解释为给定接收到的消息的想象步骤的相对重要性。请注意,
,
和
是通过其他智能体的梯度更新的。
4.3,训练
我们在MADDPG(Lowe et al.(2017))的基础上实现了提议的IS方案,但它可以应用于其他MARL算法。MADDPG是一种著名的MARL算法。为了处理连续状态动作空间,参与者、批评者、观察预测器和动作预测器通过深度神经网络进行参数化。对于Agent
和
分别作为参与者、批评家、观察预测者和动作预测者的深层神经网络参数。让
作为智能体
将被更新,以最小化以下损失:
其中
和
是Agent
,
参数化。更新策略以最大限度地减小策略梯度:
由于MGN连接到智能体自己的策略和其他智能体的策略,因此通过来自所有智能体的梯度流来训练注意模块参数
。Agent
其中
和
分别是之前的观察和收到的消息。将链式规则应用于策略梯度,得到注意模块参数的梯度。
动作预测器和观察预测器均基于监督学习进行训练,agent
5,实验
为了评估该算法并与其他通信方案进行公平比较,我们在用于该方案的同一MADDPG上实现了现有的基线。考虑的基线如下。
- MADDPG(Lowe et al.(2017)):我们可以从这一基线评估引入沟通的收益。
- DIAL(Foerster et al.(2016)):我们将基于Q-learning的DIAL修改为我们的设置,将消息生成网络连接到其他智能体的策略,并允许梯度流通过通信通道。
- TarMAC(Das等人(2019)):我们采用了TarMAC的关键概念,即智能体使用基于签名的注意模型发送目标消息。
- 通信OA:信息由自己的观察和行动组成。
- ATOC(Jiang&Lu(2018)):学习何时需要交流以及如何组合智能体信息的注意交流模型。
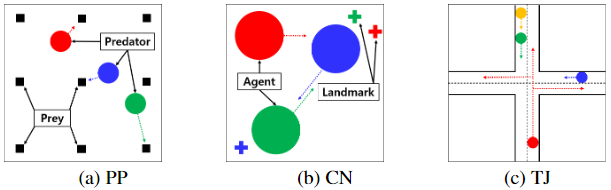
我们考虑了三种多智能体环境:捕食者-食饵环境、合作导航环境和交通枢纽环境,并对传统环境进行了轻微修改,以要求智能体之间进行更多的协调。
图2:考虑的环境:(a)捕食者-食饵(PP),(b)合作导航(CN)和(c)交通枢纽(TJ)
5.1,环境
捕食者-食饵(PP)捕食者-食饵环境是多智能体系统中的一项标准任务。我们使用了一个PP环境,该环境由N个捕食者和固定的M个猎物组成,处于一个连续状态作用域。我们控制捕食者的行动,目标是在给定的时间内捕获尽可能多的猎物。每个智能体都会观察捕食者和猎物的位置。当C捕食者同时捕获一个猎物时,猎物被捕获,所有捕食者得到共享奖励。每次捕获所有猎物时,猎物都会复活,共享奖励值R1增加1,初始值为1,以加快给定时间内的捕获速度。我们模拟了三种情况:(N=2,C=1),(N=3,C=1)和(N=4,C=2),所有M=9个猎物的固定位置如图2(a)所示。在(N=2,C=1)和(N=3,C=1)的情况下,所有捕食者的初始位置都是相同的,并且是随机确定的。因此,捕食者不仅应该学会如何捕捉猎物,还应该学会如何展开。在(N=4,C=2)的情况下,所有捕食者的初始位置都是独立随机确定的。因此,捕食者应该学会两人一组捕捉猎物。
合作导航(CN)(Lowe et al.(2017))中介绍的合作导航的目标是让N个智能体覆盖L个地标,同时避免智能体之间的碰撞。我们修改了原始环境,以便更容易发生碰撞。我们设置了L=N,增加了智能体的大小,并为每个智能体指定了一个特定的地标(即,每个智能体应该覆盖图2(b)中相同颜色的地标)。每个智能体都会观察捕食者和地标的位置。智能体接收共享奖励R1,它是每个智能体在每个时间步与相应地标之间的距离和成功奖励N′×R2的总和,其中N′是覆盖地标的编号。与其他智能体发生冲突的智能体将获得负奖励R3。我们用N=L=3、R1=1/3、R2=1和R3=−5。
交通枢纽(TJ)我们将Sukhbatar等人(2016)中介绍的交通枢纽修改为连续状态行动域。在一集开始时,每个智能体随机位于预定义的初始位置,并分配三条路线中的一条:左、右或直,如图2(c)所示。每个智能体的观察由所有智能体的位置(没有其他智能体的路由信息)和2个热向量组成,热向量对智能体的初始位置和分配的路由进行编码。每个智能体的动作都是(0,1)中的实数,表示从当前位置沿指定路线行进的距离。目标是尽可能快地到达目的地,同时避免与其他智能体发生冲突。为了实现这个目标,我们设计了三个组成部分的奖励。如果每个智能体到达目的地时没有与目标发生任何冲突,则会收到成功奖励R1其他智能体,碰撞负奖励R2(如果其位置与其他智能体重叠),时间负奖励R3以避免交通堵塞。当一个智能体到达目的地时,该智能体被分配一个新的初始位置和路线。当T个时间步过去时,一集结束。我们设定R1=20,R2=−10和R3=−0.01τ,其中τ是智能体初始化后的总时间步长。
5.2,结果
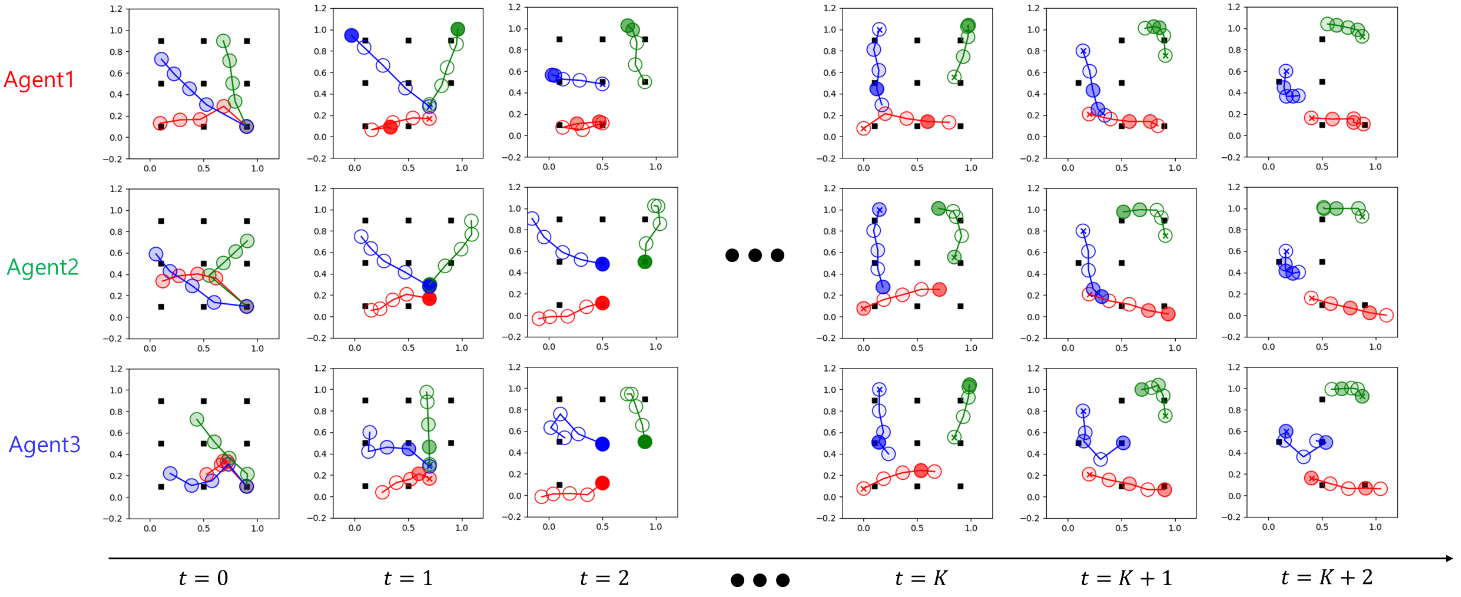
想象轨迹该方案使用编码后的想象轨迹作为消息内容。每个智能体基于自己的策略和经过训练的模型(包括动作预测器和观察预测器)推出一个想象的轨迹。由于无法访问其他智能体的策略,真实轨迹和想象的轨迹可能不匹配。特别是,在一集开始时,不匹配非常大,因为每个智能体都没有从其他智能体接收任何消息(在这种情况下,我们将零向量而不是接收到的消息注入策略)。我们预计,随着事件的进展,不匹配将逐渐减少,这可以解释为智能体之间的协调过程。图5显示了N=3捕食者的捕食者-被捕食者在一个事件中所有智能体的位置以及每个智能体在时间步长上的想象轨迹,其中训练结束后(t=0)智能体的初始位置在地图的右下方。请注意,每个智能体都会估计其他智能体的未来位置及其由于完全可观测的假设,拥有自己的未来位置。图5的第一、第二和第三行分别显示了智能体1(红色)、智能体2(绿色)和智能体3(蓝色)的所有智能体的想象轨迹。请注意,每个智能体的想象轨迹代表了其对环境的未来计划。如图5所示,在t=0时,智能体1和智能体3的意图都是向左移动以捕捉猎物。在t=1时,所有智能体都从其他智能体接收消息。据观察,智能体3改变了其未来计划,以捕捉中心周围的猎物,而智能体1则维持其未来计划。此过程显示智能体1和智能体3之间开始协调。可以看出,随着时间的推移,每个智能体粗略地预测其他智能体的未来行动。
我们进行了实验,以检查想象轨迹长度H的影响。图4显示了所提出方法在不同H值下的性能。可以看出,与H=3或H=5相比,当H=7时,训练速度会降低。然而,最终的表现都优于基准线。
注意在该方案中,基于注意模块对想象轨迹进行编码,以捕获想象轨迹中各分量的重要性。回想一下,智能体
,如(7)所示,其中
表示
的重要性,这是编码的想象步骤。注意,之前提出的通信方案是对应于
的特例。在图5中,每个圆圈的亮度与注意力权重成正比。在时间步长
时,其中
,
是最高的,这表明当药剂1移动到底部中间的猎物时。此外,
是最高的,它表明当Agent
移动到左侧中间的猎物时。因此,当智能体靠近猎物时,它倾向于发送未来的信息。在时间步长
和
中也捕捉到了类似的注意力权重倾向。
如上所述,IS方案的目的是根据其他智能体的未来计划与他们进行通信。未来的重要性取决于环境和任务。为了分析未来计划重要性的趋势,我们在完全可观察的PP环境(有3个智能体)和部分可观察的PP环境(有3个智能体)上平均了轨迹上的注意力权重,其中每个智能体知道其他智能体在特定范围内的位置。结果总结在表1中。
表1:在时间步长k时轨迹上的平均注意力权重
Imaginet k k+1 k+2 k+3 k+4 Fully observable PP(N=3) 0.33 0.18 0.15 0.14 0.20 Partially observable PP(N=3) 0.32 0.22 0.17 0.15 0.14 可以观察到,当前信息(时间
)和最远未来信息(时间
)主要用作完全可观测情况下的消息内容,而当前信息和当前旁边的信息(时间
)主要用于部分可观测环境。这是因为在部分可观测的情况下,共享观测信息比在完全可观测的情况下更为关键。该方案的一个关键方面是,它使用注意模块,根据环境自适应地选择最重要的步骤作为消息内容。我们对注意力模块进行了消融研究,结果如图4所示。我们比较了有无注意模块的IS方案。我们取代了具有平均层的注意力模型,这是对应于
的特例。图4显示,与没有注意模块的方案相比,具有注意模块的拟议IS方案产生更好的性能。这说明了注意力模块的必要性。在有4个智能体的PP环境中,在没有注意模块的情况下,单独想象的轨迹可以提高训练速度,而最终性能与MADDPG相似。在有3个智能体的TJ环境中,没有注意模块的想象轨迹可以提高最终性能和训练速度。
6, 结论
在本文中,我们提出了一种新的通信协议IS方案,该协议基于MARL中多个代理之间的共享意图。该方案中的消息生成网络由ITGM和AM组成,前者用于生成预测的未来轨迹,后者基于接收到的消息学习想象步骤的重要性。该方案中的消息被编码为捕捉agent意图的轨迹,使得通信消息既包含未来信息,也包含当前信息,并且根据环境自适应地确定它们的权重。我们研究了想象轨迹和注意力权重的例子。据观察,该方案产生了有意义的想象轨迹和注意权重。数值结果表明,该方案优于包括最新算法在内的其他通信算法。此外,我们期望该方案的核心思想是与其他通信算法(如ATOC和TarMAC)相结合,将产生更好的性能。

















 618
618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









