







DirectX11海洋模拟实践
框架基于https://www.cnblogs.com/X-Jun/p/9028764.html
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cZQUaaYD-1659186616921)(C:\Users\Estelle\Documents\MarkDown\图形学\海洋模拟\image-20220730195102893.png)]](https://img-blog.csdnimg.cn/4ec89688df6d4a259c443382b3759173.png)
尽力用最精简的语言描述FFT海洋
总览

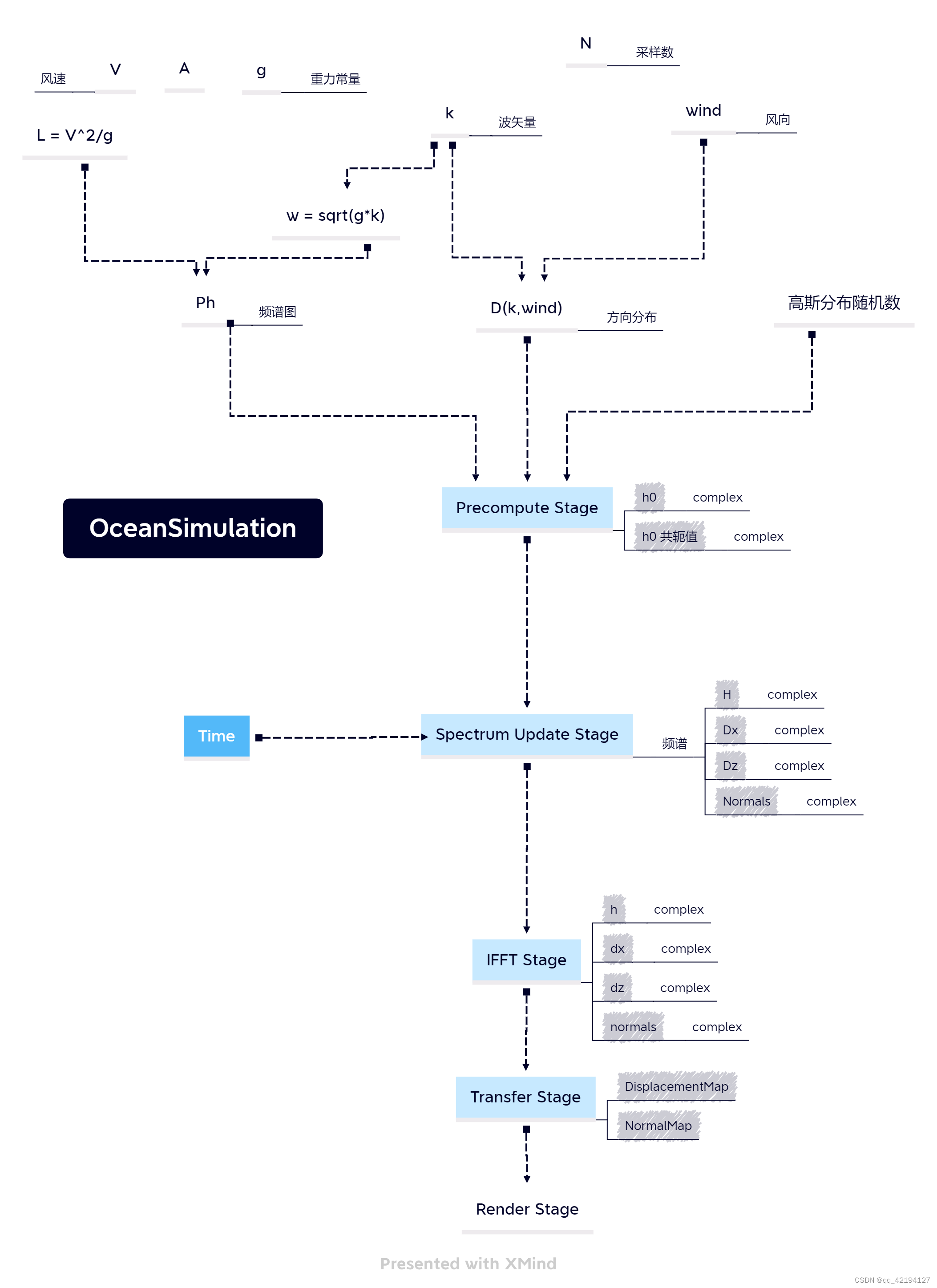
预计算阶段
计算静态海洋频谱值 h0
频谱计算阶段
在此阶段进行更新,引入时间变量
计算高度偏移频谱、水平偏移频谱、法线频谱
逆傅里叶变换阶段
进行二维傅里叶变换
得到偏移数据以及法线数据
最终处理阶段
对数据进行整合
理论
参考https://zhuanlan.zhihu.com/p/64414956
海面的IDFT模型
h ( x ⃗ , t ) = ∑ k ⃗ h ~ ( k ⃗ , t ) e i k ⃗ ⋅ x ⃗ h(\vec{x}, t)=\sum_{\vec{k}} \tilde{h}(\vec{k}, t) e^{i \vec{k} \cdot \vec{x}} h(x,t)=k∑h~(k,t)eik⋅x
此方程为二维逆傅里叶变换
其中k空间的两个分量定义为
k
x
=
2
π
n
L
,
n
∈
{
−
N
2
,
−
N
2
+
1
,
…
,
N
2
−
1
}
k
z
=
2
π
m
L
,
m
∈
{
−
N
2
,
−
N
2
+
1
,
…
,
N
2
−
1
}
\begin{array}{l} k_{x}=\frac{2 \pi n}{L}, n \in\left\{-\frac{N}{2},-\frac{N}{2}+1, \ldots, \frac{N}{2}-1\right\} \\ k_{z}=\frac{2 \pi m}{L}, m \in\left\{-\frac{N}{2},-\frac{N}{2}+1, \ldots, \frac{N}{2}-1\right\} \end{array}
kx=L2πn,n∈{−2N,−2N+1,…,2N−1}kz=L2πm,m∈{−2N,−2N+1,…,2N−1}
海洋频谱
菲利普频谱(Phillips spectrum)
h
~
(
k
⃗
,
t
)
=
h
~
0
(
k
⃗
)
e
i
ω
(
k
)
t
+
h
~
0
∗
(
−
k
⃗
)
e
−
i
ω
(
k
)
t
\tilde{h}(\vec{k}, t)=\tilde{h}_{0}(\vec{k}) e^{i \omega(k) t}+\tilde{h}_{0}^{*}(-\vec{k}) e^{-i \omega(k) t}
h~(k,t)=h~0(k)eiω(k)t+h~0∗(−k)e−iω(k)t
其中
h
~
0
∗
=
c
o
n
j
(
h
~
0
)
\tilde{h}_{0}^{*} = conj(\tilde{h}_{0})
h~0∗=conj(h~0)
即其共轭复数
k
=
∣
k
⃗
∣
ω
(
k
)
=
g
k
k = | \vec{k}| \\\omega(k)=\sqrt{g k}
k=∣k∣ω(k)=gk
更准确来说是(h是海洋深度)
ω
(
k
)
=
g
k
tanh
(
k
h
)
\omega(k)=\sqrt{g k \tanh (k h)}
ω(k)=gktanh(kh)
g是重力常数
h
~
0
(
k
⃗
)
=
1
2
(
ξ
r
+
i
ξ
i
)
P
h
(
k
⃗
)
\tilde{h}_{0}(\vec{k})=\frac{1}{\sqrt{2}}\left(\xi_{r}+i \xi_{i}\right) \sqrt{P_{h}(\vec{k})}
h~0(k)=21(ξr+iξi)Ph(k)
其中 ξr 和 ξi 是相互独立的随机数,均服从均值为0,标准差为1的正态分布。
P
h
(
k
⃗
)
=
A
e
−
1
/
(
k
L
)
2
k
4
∣
k
⃗
⋅
w
⃗
∣
2
P_{h}(\vec{k})=A \frac{e^{-1 /(k L)^{2}}}{k^{4}}|\vec{k} \cdot \vec{w}|^{2}
Ph(k)=Ak4e−1/(kL)2∣k⋅w∣2
风向: ∣ w ⃗ ∣ 2 = 1 风向:|\vec{w}|^{2} = 1 风向:∣w∣2=1
L = V 2 g L=\frac{V^{2}}{g} L=gV2
V为风速
具体含义如下


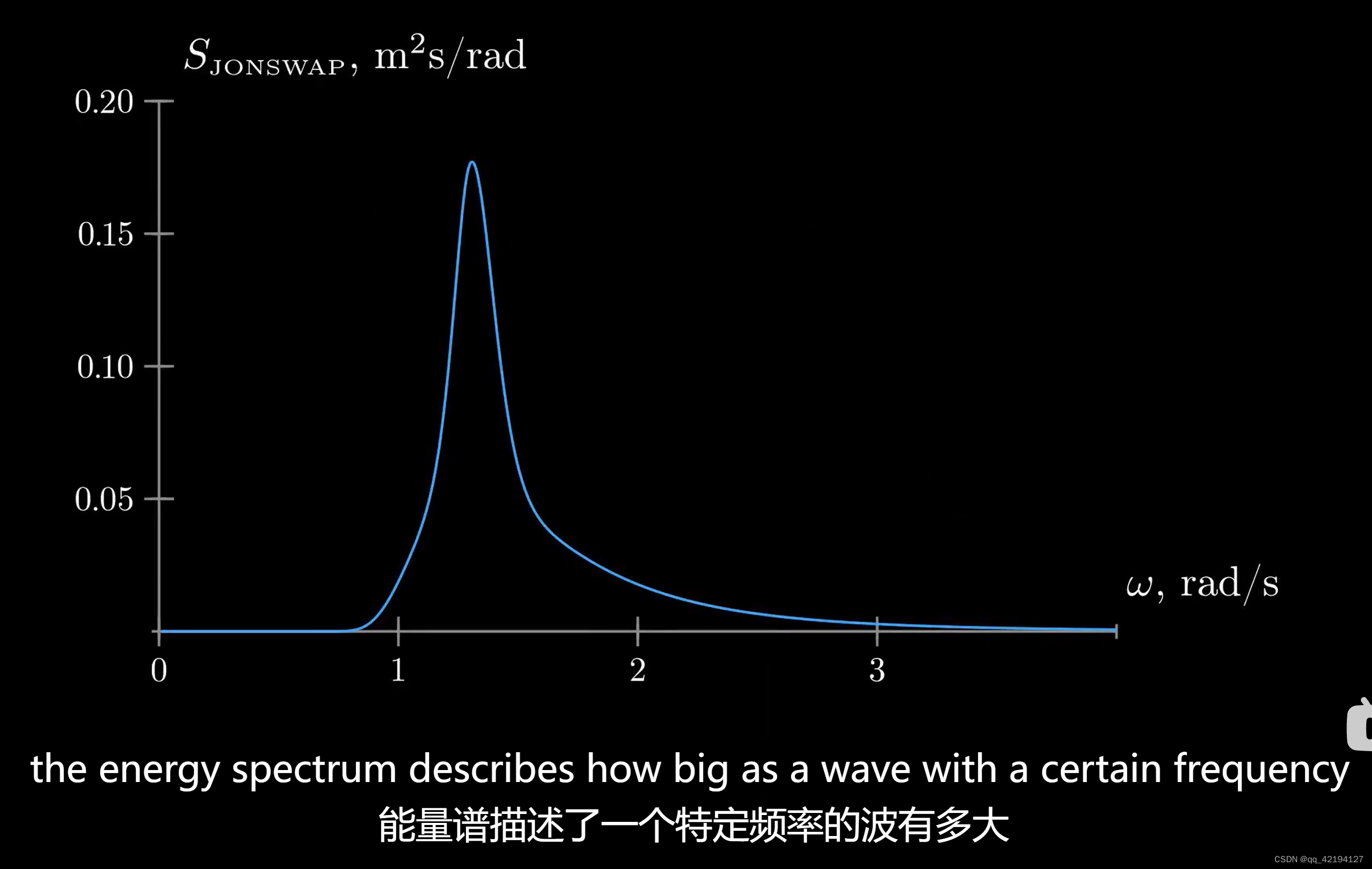
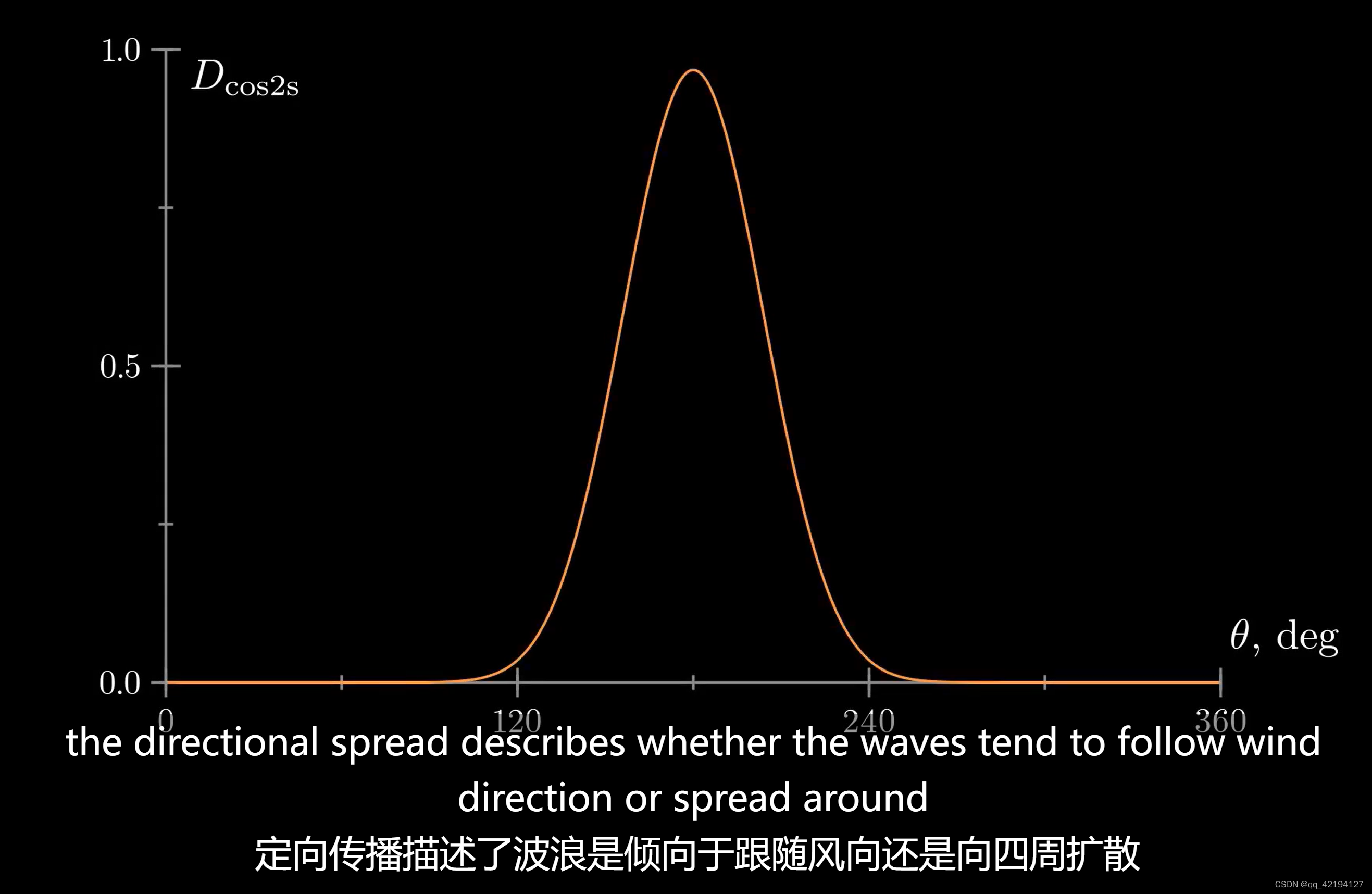
法线
因为求导的线性性质,h的梯度值仍然是IDFT形式,可以用IDFT计算
∇
h
(
x
⃗
,
t
)
=
∑
k
⃗
i
k
⃗
h
~
(
k
⃗
,
t
)
e
i
k
⃗
⋅
x
⃗
\nabla h(\vec{x}, t)=\sum_{\vec{k}} i \vec{k} \tilde{h}(\vec{k}, t) e^{i \vec{k} \cdot \vec{x}}
∇h(x,t)=k∑ikh~(k,t)eik⋅x
N ⃗ = normalize ( ( 0 , 1 , 0 ) − ( ∇ h x ( x ⃗ , t ) , 0 , ∇ h z ( x ⃗ , t ) ) ) = normalize ( − ∇ h x ( x ⃗ , t ) , 1 , − ∇ h z ( x ⃗ , t ) ) \begin{array}{l} \vec{N}=\text { normalize }\left((0,1,0)-\left(\nabla h_{x}(\vec{x}, t), 0, \nabla h_{z}(\vec{x}, t)\right)\right) \\ =\text { normalize }\left(-\nabla h_{x}(\vec{x}, t), 1,-\nabla h_{z}(\vec{x}, t)\right) \end{array} N= normalize ((0,1,0)−(∇hx(x,t),0,∇hz(x,t)))= normalize (−∇hx(x,t),1,−∇hz(x,t))
Gerstner wave
https://www.bilibili.com/video/BV1E64y1D78T?spm_id_from=333.880.my_history.page.click&vd_source=0cfebf737cf740b1e5610209f09e99a8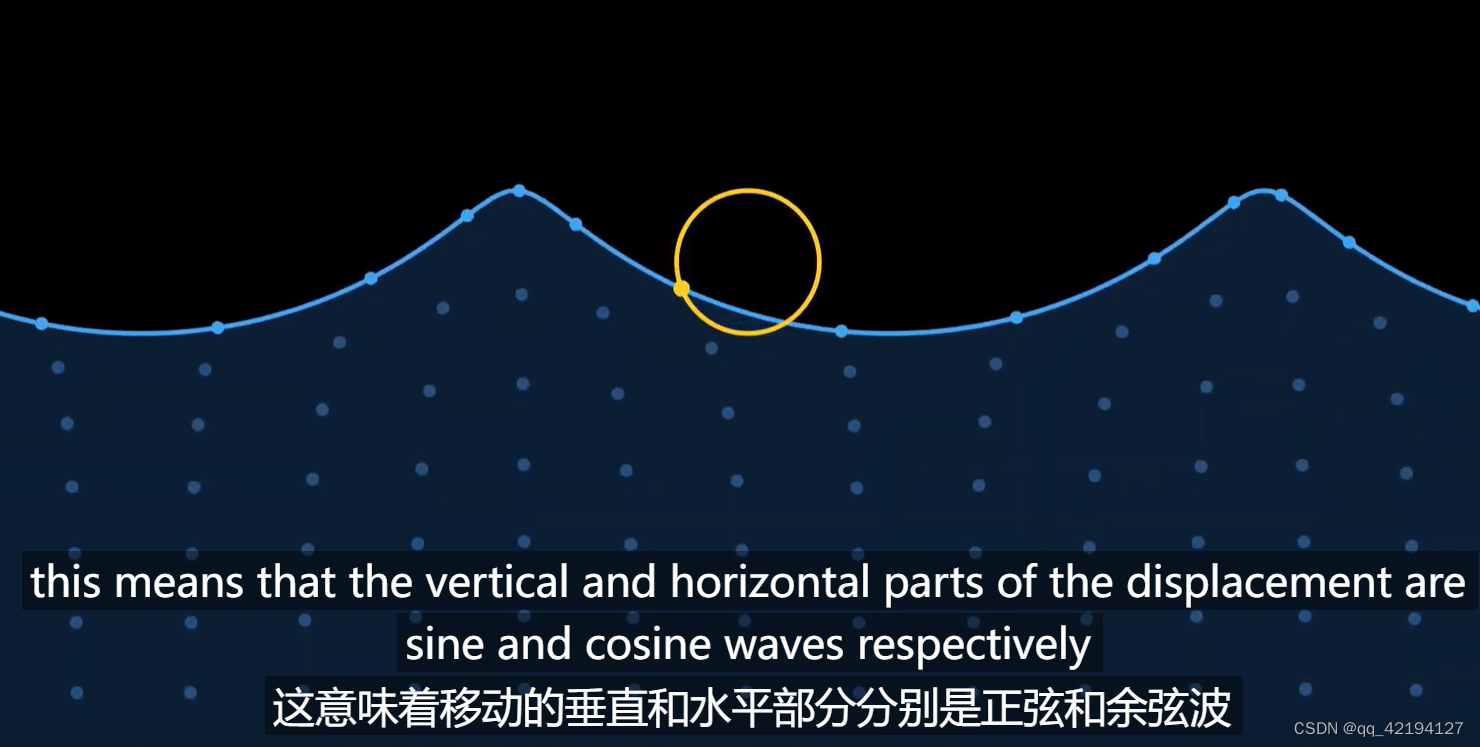 Gerstner wave进行了水平偏移,压缩海浪形成尖角
Gerstner wave进行了水平偏移,压缩海浪形成尖角
P
=
(
x
⃗
+
∑
Q
i
A
i
D
i
⃗
⋅
x
⃗
cos
Φ
i
∑
A
i
sin
Φ
i
)
\mathbf{P}=\left(\begin{array}{l} \vec{x}+\sum\ Q_{i} A_{i} \vec{\mathbf{D}_{i}} \cdot \vec{x} \cos \Phi_{i} \\ \sum A_{i} \sin \Phi_{i} \end{array}\right)\\
P=(x+∑ QiAiDi⋅xcosΦi∑AisinΦi)
Φ
i
=
w
i
D
i
⃗
⋅
x
⃗
+
φ
i
t
\Phi_{i} = w_{i} \vec{\mathbf{D}_{i}} \cdot\vec{x}+\varphi_{i} t
Φi=wiDi⋅x+φit
在IDFT中的形式为
D ⃗ ( x ⃗ , t ) = ∑ k ⃗ − i k ⃗ k h ~ ( k ⃗ , t ) e i k ⃗ ⋅ x ⃗ x ⃗ ′ = x ⃗ + λ D ⃗ ( x ⃗ , t ) \begin{array}{l} \vec{D}(\vec{x}, t)=\sum_{\vec{k}}-i \frac{\vec{k}}{k} \tilde{h}(\vec{k}, t) e^{i \vec{k} \cdot \vec{x}} \\ \vec{x}^{\prime}=\vec{x}+\lambda \vec{D}(\vec{x}, t) \end{array} D(x,t)=∑k−ikkh~(k,t)eik⋅xx′=x+λD(x,t)
快速傅里叶变化 FFT
参见https://www.bilibili.com/video/BV1Y7411W73U?spm_id_from=333.337.search-card.all.click
这方面的知识已经有很多讲解,这里不做详解
对图像进行横纵FFT/IFFT即可得到二维FFT
I
F
F
T
2
=
I
F
F
T
(
I
F
F
T
(
M
a
t
r
i
x
r
o
l
)
c
o
l
)
IFFT2 = IFFT(IFFT(Matrix_{rol})_{col})
IFFT2=IFFT(IFFT(Matrixrol)col)
HLSL实现
注:GPU上将CPU中一起执行的剪刀操作拆分到两个线程中并且使用ping-pong buffer加速计算
因为HLSL不支持float2类型的随机访问贴图,所以将两个频谱打包进行傅里叶变换(也加速了傅里叶变换的过程)
//#define FFT_SIZE_256
#if defined(FFT_SIZE_512)
#define SIZE 512
#define LOG_SIZE 9
#elif defined(FFT_SIZE_256)
#define SIZE 256
#define LOG_SIZE 8
#elif defined(FFT_SIZE_128)
#define SIZE 128
#define LOG_SIZE 7
#else
#define SIZE 64
#define LOG_SIZE 6
#endif
static uint Size = SIZE;
#ifdef FFT_ARRAY_TARGET
RWTexture2DArray<float4> Target;
#else
RWTexture2D<float4> g_Target;
#endif
cbuffer Params
{
uint TargetsCount;
uint Direction;//bool
uint Inverse; //bool
uint Scale; //bool
uint Permute; //bool
};
//两组数据进行打包输入
groupshared float4 buffer[2][SIZE];
float2 ComplexMult(float2 a, float2 b)
{
return float2(a.x * b.x - a.y * b.y, a.x * b.y + a.y * b.x);
}
void ButterflyValues(uint step, uint index, out uint2 indices, out float2 twiddle)
{
const float twoPi = 6.28318530718;
uint b = Size >> (step + 1);
uint w = b * (index / b);
uint i = (w + index) % Size;
sincos(-twoPi / Size * w, twiddle.y, twiddle.x);
if (Inverse)
twiddle.y = -twiddle.y;
indices = uint2(i, i + b);
}
float4 DoFft(uint threadIndex, float4 input)
{
buffer[0][threadIndex] = input;
GroupMemoryBarrierWithGroupSync();
bool flag = false;
[unroll(LOG_SIZE)]
for (uint step = 0; step < LOG_SIZE; step++)
{
uint2 inputsIndices;
float2 twiddle;
ButterflyValues(step, threadIndex, inputsIndices, twiddle);
float4 v = buffer[flag][inputsIndices.y];
//一次执行两个计算
//ak = a0 + w*a1
buffer[!flag][threadIndex] = buffer[flag][inputsIndices.x]
+ float4(ComplexMult(twiddle, v.xy), ComplexMult(twiddle, v.zw));
flag = !flag;
GroupMemoryBarrierWithGroupSync();
}
return buffer[flag][threadIndex];
}
[numthreads(SIZE, 1, 1)]
void CS(uint3 id : SV_DispatchThreadID)
{
uint threadIndex = id.x;
uint2 targetIndex;
if (Direction)
targetIndex = id.yx;
else
targetIndex = id.xy;
#ifdef FFT_ARRAY_TARGET
for (uint k = 0; k < TargetsCount; k++)
{
Target[uint3(targetIndex, k)] = DoFft(threadIndex, Target[uint3(targetIndex, k)]);
}
#else
g_Target[targetIndex] = DoFft(threadIndex, g_Target[targetIndex]);
#endif
}
项目GitHub
https://github.com/StellarWarp/FFT-Ocean















 1304
1304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









