







定义 cross-entropy函数

以前的Cost 函数
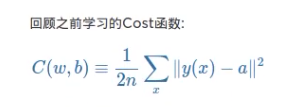
对比与总结


补充:
利用cross-entropy cost代替quadratic cost来获得更好的收敛
——说白了,就是cross-entropy cost比quadratic cost学得更快,因为不怎么涉及到权重
方差代价函数说起(Quadratic cost)
y是我们期望的输出,a为神经元的实际输出【 a=σ(z), where z=wx+b 】。
在训练神经网络过程中,我们通过梯度下降算法来更新w和b,因此需要计算代价函数对w和b的导数:
然后更新w、b:
w <—— w - η* ∂C/∂w = w - η * a *σ′(z)
b <—— b - η* ∂C/∂b = b - η * a * σ′(z)
因为sigmoid函数的性质,导致σ′(z)在z取大部分值时会很小(如下图标出来的两端,几近于平坦),这样会使得w和b更新非常慢(因为η * a * σ′(z)这一项接近于0)。
为了克服这个缺点,引入了交叉熵代价函数(下面的公式对应一个神经元,多输入单输出):
交叉熵代价函数(cross-entropy cost function)
其中y为期望的输出,a为神经元实际输出【a=σ(z), where z=∑Wj*Xj+b】
与方差代价函数一样,交叉熵代价函数同样有两个性质:
- 非负性。(所以我们的目标就是最小化代价函数)
- 当真实输出a与期望输出y接近的时候,代价函数接近于0.(比如y=0,a~0;y=1,a~1时,代价函数都接近0)。
另外,它可以克服方差代价函数更新权重过慢的问题。我们同样看看它的导数:
可以看到,导数中没有σ′(z)这一项,权重的更新是受σ(z)−y这一项影响,即受误差的影响。所以当误差大的时候,权重更新就快,当误差小的时候,权重的更新就慢。这是一个很好的性质。
以上说的是单层的,如果多层:
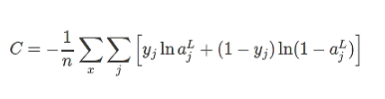















 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









