







Eformer:医学图像去噪
Abstract
本文提出的Eformer是一种边缘增强的Transformer结构,通过Transformer模块构建用于医学图像去噪的编解码网络。本文使用了非重叠的基于窗口的SA模块用来减少计算量,进一步加入了可学习的Sobel-Feldman算子来增强图像中的边缘信息,并提出了一种有效连接二者的方法。通过进行残差学习和对比学习本文进行了医学图像去噪实验,在低剂量CT挑战赛上达到了SOTA,峰值信噪比为43.487 PSNR, 0.0067 RMSE, 0.9816 SSIM. 我们相信本文的工作将鼓励更多关于Transformer的研究,以及使用残差学习用于医学图像去噪。
1. Introduction
借助计算机诊断疾病近年来发展迅速,如CT扫描经常帮助诊断如骨折、心脏病、肺气肿等疾病。CT扫描是一种X光射线扫描的方法,通过射出一束X光束并且在关键部位背面防止一个高灵敏度的探测器,最后通过数学等算法获得最终身体某部位的二维切片信息,这一过程会不断重复从而获得多个切片。
虽然CT扫描可以帮助疾病诊断,但确实需要暴露在放射性环境中,使得医疗辐射成为仅次于环境辐射的第二大辐射源,因此最好能够在扫描过程中减少X射线的剂量。
但这又会导致噪声增加、边缘/角/突出特征对比度下贱以及图像过度平滑等问题。
本文提出一种可以更好保留信息同时又能减少噪声的低剂量扫描方法,使其可以称为一种提到高剂量扫描的方案。
医学图像去噪在CV领域吸引了诸多研究者的目光,目前已经进行了广泛的研究;虽然取得了优异的成果但是他们都是在全局上进行的操作,并没有利用局部的视觉信息。
而本文则认为可以从Vision Transformer进行patch embedding操作中获益。
近年来ViT在图像修复等诸多任务中取得了巨大的成功,但尚未在医学图像数据集上得到充分利用。据我们所知我们的工作是首次利用Transformer进行医学图像去噪。本文的主要贡献如下:
-
本文提出一种新的边缘增强的Transformer模型(Eformer)用于医学图像去噪,结合了可学习的Sobel滤波器来进行边缘增强,从而提升整体架构的性能。本文的方法优于目前最先进的方法,并展示了Transformer如何用于医学图像去噪。
-
本文证明了残差学习在医学图像去噪中的有效性;此外本文还使用了一种确定性的方法即直接预测去噪图像;来进行对比。实验结果显示残差学习明显优于传统的学习方法,直接预测去噪图像更像identity mapping.
2. Relate
低剂量CT图的去噪重建是十分热门的一个研究方向,但是受限于训练数据以及基于卷积的方法提升效果有限,如何设计data-efficient的深度学习方法非常值得探索。
Chen等人发现y一个简单的CNN就可以用来抑制LDCT图像中的噪声,也有一些工作搭建了编解码网络结构。REDCNN在网络中引入了shortcut connection,CPCE则使用了conveying_paths connections。
还有借助结合了空洞卷积的FCN网络和残差学习来进行医学图像去噪的以及使用生成对抗网络的。
近期基于Transformer的网路结构在CV领域取得了巨大的成功,也被广泛用于SR,去噪,去雨等任务。Uformer使用了不重叠的wW-MSA模块以及在FFN中使用深度卷积有效捕获了局部信息,本文受Uformer启发将边缘增强模块结合进了Uformer来帮助图像去噪。
# 3. Approach
## 3.1Sobel-Feldman Operator
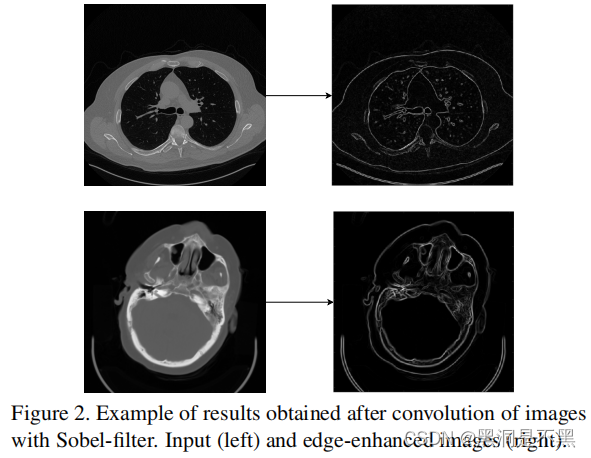
受Edcnn的启发本文使用Sobel滤波器进行边缘增强。Sobel专门用于边缘检测算法可以有效强调图像的边缘部分。进行边缘增强后的CT 如Fig 2所示,这样将包含边缘信息的图像特征可以更有效的作为网络和其他投影部分的输入。
3.2 Transformer based Encoder-Decoder
去噪自编码器,FCN,GAN都被用于医学图像去噪任务,但是还没有探索果将Transformer应用其中。该部分的灵感主要来自于Uformer。在每个编码和解码的阶段,卷积特征图都通过一个局部增强窗口(LeWin)Transformer block。这个block包括一个基于非重叠窗口的多头自注意力模块(W-MSA)和一个局部增强馈送前向网络(LeFF)。总体的数学表达公式如下,LN表示Layer Normlization:
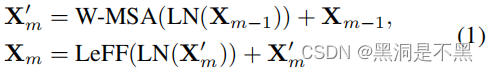
由图1所示,在每个编码阶段,本transformer block在 LC2D 块之前被应用,在每个解码阶段在 LC2U 块之后被应用,也用作瓶颈层。
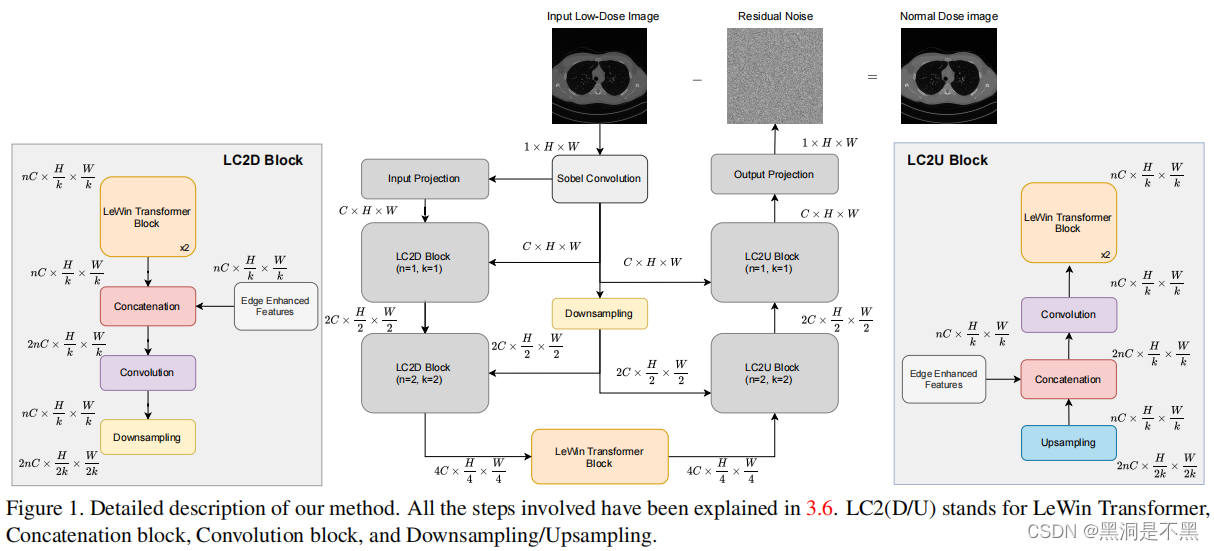
3.3. Downsampling & Upsampling
池化是卷积神经网络中最常用的下采样方法,可以有效捕获结构信息,但是代价就是损失了细节信息。因此本文则使用步长卷积作为下采样层,卷积核为3x3,步长为2,padding = 1.
上采样可以看做是upooling或反池化操作,通常使用最近邻操作等;本文使用的是专制卷积来恢复图像分辨率,并且可以学习参数。转置卷积的问题是会产生棋盘格伪影现象,为了避免重叠不均匀,kernel size应该能被步长整除,因此在上采样的转置卷积使用的是kernel-size = 4,stride=2.
3.4. Residual Learning
残差学习的目标是隐式的去除隐藏层中的clean image。本文将噪声图像 x = y + v x = y+v x=y+v 输入网络,y就是真值,v是残差噪声,因此Transformer的输出不是去噪后的图像 y ^ \hat{y} y^ ,而是预测的残差图像 y ^ \hat{y} y^. 也就是噪声图像与真值图像之间的差异。 当原始映射更接近identity mapping时残差映射更容易优化。 因此常规去噪模型学习的映射是: F ( x ) = y ^ F(x)=\hat{y} F(x)=y^ ,而本文学习的是残差映射 R ( x ) = v ^ R(x)=\hat{v} R(x)=v^,则可得 y ^ = x − R ( x ) ⇒ y ^ = x − v ^ \hat{y}=x-R(x)\Rightarrow \hat{y}=x-\hat{v} y^=x−R(x)⇒y^=x−v^
3.5 Optimization
作为优化过程的一部分,我们使用多个损失函数来获得可能的最佳结果。我们首先使用均方误差(MSE),它计算输出和地面真实图像之间的像素级距离,定义如下:
L
m
s
e
=
1
N
∑
i
=
1
N
∥
(
x
i
−
R
(
x
i
)
)
−
y
i
∥
2
(2)
L_{m s e}=\frac{1}{N} \sum_{i=1}^{N}\left\|\left(x_{i}-R\left(x_{i}\right)\right)-y_{i}\right\|^{2}\tag{2}
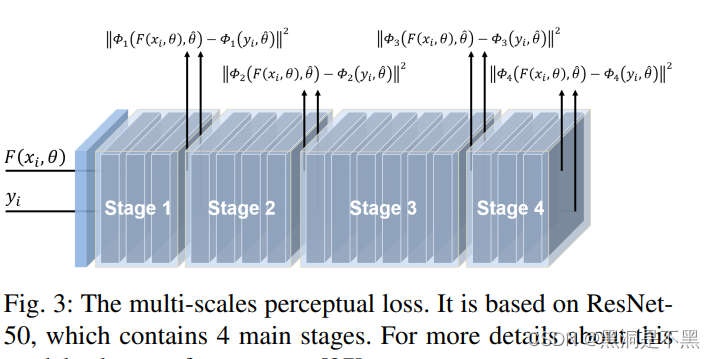
Lmse=N1i=1∑N∥(xi−R(xi))−yi∥2(2)但是仅使用这一种损失函数容易产生伪影,如图像模糊;因此本文还使用了基于ResNet的多尺度感知损失(MSP):
L
m
s
p
=
1
N
C
∑
i
=
1
N
∑
s
=
1
C
∥
ϕ
s
(
x
i
−
R
(
x
i
)
,
θ
^
)
−
ϕ
s
(
y
i
,
θ
^
)
∥
2
(3)
L_{m s p}=\frac{1}{N C} \sum_{i=1}^{N} \sum_{s=1}^{C}\left\|\phi_{s}\left(x_{i}-R\left(x_{i}\right), \hat{\theta}\right)-\phi_{s}\left(y_{i}, \hat{\theta}\right)\right\|^{2}\tag{3}
Lmsp=NC1i=1∑Ns=1∑C∥∥∥ϕs(xi−R(xi),θ^)−ϕs(yi,θ^)∥∥∥2(3)将ResNet50作为特征提取器,将去噪后的输出结果与GT一同输入ResNet中,提取ResNet不同阶段的输出来计算感知损失,这样既可以约束像素级别的损失也可以约束结构上的损失。因此最终的损失函数为:
L
final
=
λ
m
s
e
L
m
s
e
+
λ
m
s
p
L
m
s
p
(4)
L_{\text {final }}=\lambda_{m s e} L_{m s e}+\lambda_{m s p} L_{m s p}\tag{4}
Lfinal =λmseLmse+λmspLmsp(4)
3.6. Overall Network Architecture
整体处理流程:
输入图像法I首先经过Sobel filter获得边缘增强后并且GELU激活后的结果S(I);然后在Encoder的每一个staget都会将输入经过一个LeWin模块处理,然后与S(I)级联后的结果送去进行后续的卷积操作。然后使用3.3中描述的对特征图和S(I)进行下采样。
编码后会在Botteleneck部分将编码后的特征映射传递给下一个LeWin模块,继续进行编码。
Decoder会进行相应的阶码,然后通过反卷积进行上采样操作。同一level的encoder和decoder输入同样的S(I);解码后的组中输出会通过一个“输出映射”产生相应的残差结果,将C通道的特征映射投影到1通道的灰度图。
此外本文将LeWin块的深度、注意力头数、编解码的深度分别设置为2。
4. Results and Discussions
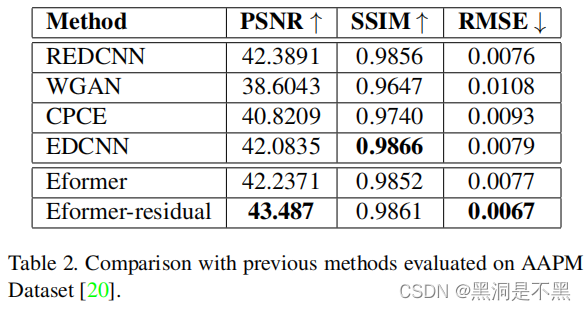
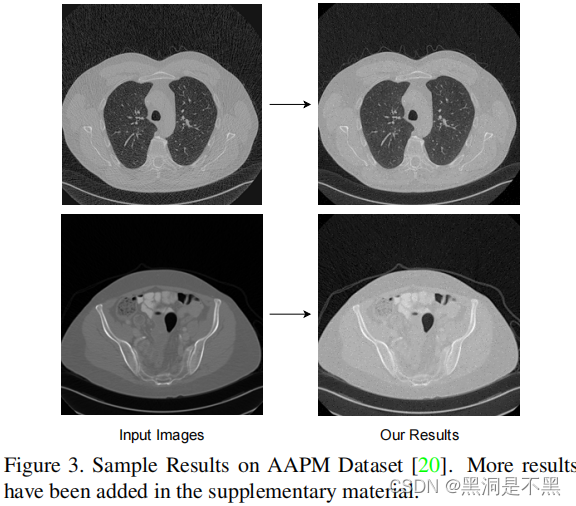
本小节展示恢复低剂量CT图像的结果,评价指标分别是:PSNR,SSIM,RMSE。
Table 2展示了与其他卷积网络结构的对比,比如CPCE,WGAN,EDCNN均使用了混合损失,REDCNN只是用了MSE。















 2340
2340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









