







系列文章目录
文章名称:Eformer: Edge Enhancement based Transformer for Medical Image Denoising
文章地址:https://arxiv.org/abs/2109.08044
代码地址:
发表时间:2021
应用领域:医学图像去噪
核心模块:边缘增强、残差学习、混合损失函数
参考资料:转置卷积
文章目录
摘要
在这项工作中,我们提出了Eformer-基于边缘增强的Transformer,这是一种使用Transformer块构建编码器-解码器网络的新型架构,用于医学图像去噪。基于非重叠窗口的自注意用于Transformer块中以降低计算要求。这项工作进一步结合了可学习的Sobel-Feldman算子来增强图像中的边缘,并提出了一种将他们连接到我们架构的中间层的有效方法。通过比较确定性学习和残差学习对医学图像去噪任务的实验分析。为了确保我们方法的有效性,我们的模型在AAPM-Mayo Clinic低剂量CT大挑战数据集上进行了评估,并实现了最先进的性能,即43.487 PSNR、0.0067RMSE 和0.9861 SSIM.我们相信,我们的工作将鼓励对基于Transformer的架构进行更多研究,以使用残差学习对医学图像进行去噪。
Introduction
CT扫描balabala…医学图像去噪已经引起了广泛关注。最近在这个领域进行了广泛的研究
19、27、4…、尽管这些方法已显示出出色的结果,但他们隐含地将去噪与全局范围内的操作相关联,而不是利用局部视觉信息。我们认为我们可以从构成vison Transformer的基础 patch embeding操作中收益8。最近,vision Transformer(ViT)在许多计算机视觉任务中取得了巨大的成功包括图像恢复,但它们尚未在医学图像数据集上得到应用25。
据我们所知,这是第一项利用Transformer进行医学去噪的工作。本文的主要结构如下:
- 本文提出了一种新的基于Transformer的边缘增强的医学图像去噪体系结构eformer。 我们将可学习的Sobel滤波器用于边缘增强,从而提高了我们整体架构的性能。 我们超越了现有的最先进的方法,并展示了如何Transformer可以用于医学图像去噪。
- 我们根据残差学习范式对网络训练进行了广泛的实验。为了证明残差学习在图像去噪任务中的有效性,我们的模型用确定性方法直接预测图像并展示了结果,在医学图像去噪中,残差学习明显优于传统的学习方法,其直接预测去噪图像变得类似于制定身份映射。
Related Work
低剂量CT(LDCT)图像去噪由于其有价值的临床可用性而成为医学图像去噪中的一个活跃领域。由于数据量的限制以及随之而来的传统方法的低准确性16基于机器学习方法的医学图像去噪研究进展,数据高效的深度学习方法在该邻域具有巨大的潜力。陈等人的开创性工作。6表明,一个简单的卷积神经网络(CNN)可用于抑制LDCT图像的噪声。11(基于卷积去噪自动编码器的医学图像去噪)、REDCNN、CPCE中提出的模型表明,编码器-解码器网络在医学图像去噪方面是有效的。REDCNN将short connection组合到残差编码器-解码器网络中,而CPCE使用conveying-paths连接。诸如Deep
Learning for Low-Dose CT Denoising Using Perceptual
Loss and Edge Detection Layer 的完全卷积网络具有不同扩张率的扩张卷积 。基于GAN的模型,如27使用Wasserstein距离和感知损失来进行图像去噪,mwGAN利用Wasserstein距离和均方差损失(MSE)训练的GAN网络在牙科低剂量CT扫描图像去噪中有较好的去除伪影的性能。最近基于Transformer的架构在ViT开创的计算机视觉领域也取得了巨大的成功,它成功地将Transformer用于图像分类任务。从那时其,已经提出了许多关于Transformer的模型,这些模型已经在许多低级视觉任务中取得了成功的结果,包括图像超分辨率、去噪、去雨和着色。我们的工作也受到这样的去噪Transformer - Uformer的启发,它在前馈网络中采用基于非重叠窗口的自注意力和深度卷积来有效地捕获局部上下文。我们以一种有效的新颖的方式集成了边缘增强模块和类似Uformer的架构,这有助于我们获得最先进的结果。
网络架构
Sobel-Feldman Operator
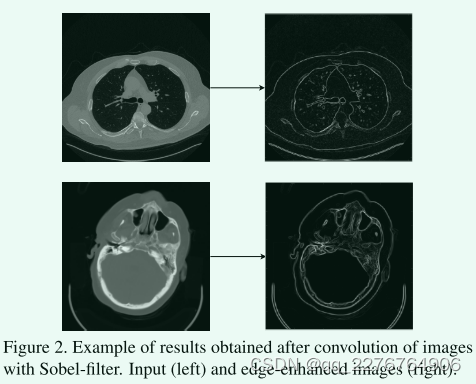
受EDCNN启发,我们使用Sobel-Feldman算子,也称为Sobel滤波器,用于我们的边缘增强块。Sobel滤波器专门用于边缘检测算法,因为它有助于强调边缘。最初,运算符有两种变体 —垂直和水平,但我们还包括类似于EDCNN中的对角线版本(参加补充材料)。边缘增强CT图像的样本结果如图2所示。包含边缘信息的图像特征图集与输入投影和网络的其他部分有效连接。
Transformer based Encoder-Decoder
Denoising Autoencoders(REDCNN、CPCE、Medical image denoising using convo-
lutional denoising autoencoders)、Fully Convolutional Networks (EDCNN、Medical image denoising using convolutional neural network: a residual learning approach、Deep
Learning for Low-Dose CT Denoising Using Perceptual
Loss and Edge Detection Layer)And GANs(Low-Dose CT Image
Denoising Using a Generative Adversarial Network With
Wasserstein Distance and Perceptual Loss、Artifact correction in low-dose dental ct
imaging using wasserstein generative adversarial networks)在过去的医学图像去噪任务中取得了成功,但Transformer尽管在其他领域取得了成功,但在医学图像去噪中还没有被探索过。我们的新型网络Eformer就是朝这个方向迈出一步。我们从Uformer那里获得灵感来完成这项工作。在每个编码器和解码器阶段,卷积特征图通过一个局部增强窗口(LeWin)transformer块传递,该Transformer块有一个基于非重叠窗口的多头自注意力(W-MSA)和一个局部增强的前馈网络(LeFF),集成在一起(参见补充材料)
X
m
′
=
W
−
M
S
A
(
L
N
(
X
m
−
1
)
)
+
X
m
−
1
,
X
m
=
L
e
F
F
(
L
N
(
X
m
′
)
)
+
X
m
′
\begin{array}{l}\mathbf{X}'_m=\mathbf{W-MSA}(\mathbf{LN}(\mathbf{X}_{m-1}))+\mathbf{X}_{m-1},\\ \mathbf{X}_m=\mathbf{LeFF}(\mathbf{LN}(\mathbf{X}'_m))+\mathbf{X}'_m\end{array}
Xm′=W−MSA(LN(Xm−1))+Xm−1,Xm=LeFF(LN(Xm′))+Xm′
这里,LN表示层归一化。如图1所示,transformer block 在每个编码阶段应用在LC2D block之前,在每个解码阶段应用在LC2U block之后,同时也作为瓶颈层。
Downsampling & Upsampling
池化层是在卷积网络中对输入图像信号进行下采样的最常见方式。它们在图像分类任务中表现良好,因为它们有助于捕获基本的结构细节,但代价是在我们的任务中丢失了我们无法承受的更精细的细节。因此,我们在下采样层中选择跨步卷积。更具体地说,我们使用3*3的内核大小,步长为2,padding为1.
上采样可以被认为是使用最近邻等简单技术反池化或池化反向。在我们网络中,我们使用**转置卷积**。转置卷积重建空间维度并像常规卷积层一样学习自己的参数。转置卷积的问题在于它们可能会导致checkerboard artifacts(棋盘伪影),这对图像去噪来说是不可取的。Deconvolution and Checkerboard Artifacts指出,为避免重叠不均匀,内核大小应被stride整除。因此,在我们的上采样层中,我们使用4 * 4的内核和2的步幅。
Residual Learning
残差学习的目标是隐式地去除隐藏层中潜在的干净的图像。我们输入一个有噪声的图像 x = y + v x=y+v x=y+v到我们的网络中,其中,x是噪声图像,在此情况下是低剂量噪声图像;y是干净图像;v是残差噪声。Eformer不是直接输出去噪图像 y ^ \hat{y} y^,而是预测残差图像 v ^ \hat{v} v^,即噪声图像和真实图像之间的差异。根据,当原始映射更像是是恒等映射时,残差映射更容易优化。判别式去噪模型旨在学习 F ( x ) = y ^ F(x)={\hat{y}} F(x)=y^的映射函数,而我们采用残差公式来训练我们的网络学习残差映射 R ( x ) = v ^ R(x)=\hat{v} R(x)=v^,然后我们得到 y ^ = x − R ( x ) ⟹ y ^ = x − v ^ . \hat{y}=x-R(x)\implies\hat{y}=x-\hat{v}. y^=x−R(x)⟹y^=x−v^.。
Optimization(优化)
作为优化过程的一部分,我们使用多个损失函数来获得最佳结果。我们最初使用均方误差(MSE)来计算输出和无噪图像之间的像素距离,定义如下:
L
m
s
e
=
1
N
∑
i
=
1
N
∥
(
x
i
−
R
(
x
i
)
)
−
y
i
∥
2
(
2
)
L_{mse}=\dfrac{1}{N}\sum_{i=1}^{N}\left\|(x_i-R(x_i))-y_i\right\|^2\quad(2)\quad
Lmse=N1∑i=1N∥(xi−R(xi))−yi∥2(2)
然而,它往往会产生不需要的伪像,如过度平滑和图像模糊。为了克服这个问题,我们同时引入了基于多尺度感知损失的ResNet网络(MSP)。MSP可以用下面的等式表示:
L
m
s
p
=
1
N
C
∑
i
=
1
N
∑
s
=
1
C
∥
ϕ
s
(
x
i
−
R
(
x
i
)
,
θ
^
)
−
ϕ
s
(
y
i
,
θ
^
)
∥
2
L_{msp}=\dfrac{1}{NC}\sum_{i=1}^N\sum_{s=1}^C\left\|\phi_s(x_i-R(x_i),\hat{\theta})-\phi_s(y_i,\hat{\theta})\right\|^2
Lmsp=NC1∑i=1N∑s=1C
ϕs(xi−R(xi),θ^)−ϕs(yi,θ^)
2 (3)
ResNet主干网络被用作特征提取器
ϕ
\phi
ϕ。具体来说,在ImageNet数据集[7]上预先训练的Resnet-50的池化层被删除,保留了权重
(
θ
^
)
(\hat{\theta})
(θ^)被冻结的卷积块。 为了计算感知损失,将去噪输出
x
i
−
R
(
x
i
)
x_{i}-R(x_{i})
xi−R(xi),其中
R
(
x
i
)
=
v
^
i
R(x_{i})={\hat{v}}_{i}
R(xi)=v^i(如3.4节所述)和地面真值
(
y
i
)
\begin{pmatrix}y_i\end{pmatrix}
(yi)传递给提取器。 接着,从主干的四个阶段中提取特征映射,如EDCNN所做的那样。 这种知觉损失,结合MSE处理每个像素的相似性和整体结构信息。 我们的最终目标如下:
L
f
i
n
a
l
=
λ
m
s
e
L
m
s
e
+
λ
m
s
p
L
m
s
p
(
4
)
L_{final}=\lambda_{mse}L_{mse}+\lambda_{msp}L_{msp}\quad\quad(4)
Lfinal=λmseLmse+λmspLmsp(4)
其中,
λ
m
s
e
\lambda_{mse}
λmse和
λ
m
s
p
\lambda_{msp}
λmsp是预定义常数。
OVerall Network Architecture(整体网络架构)
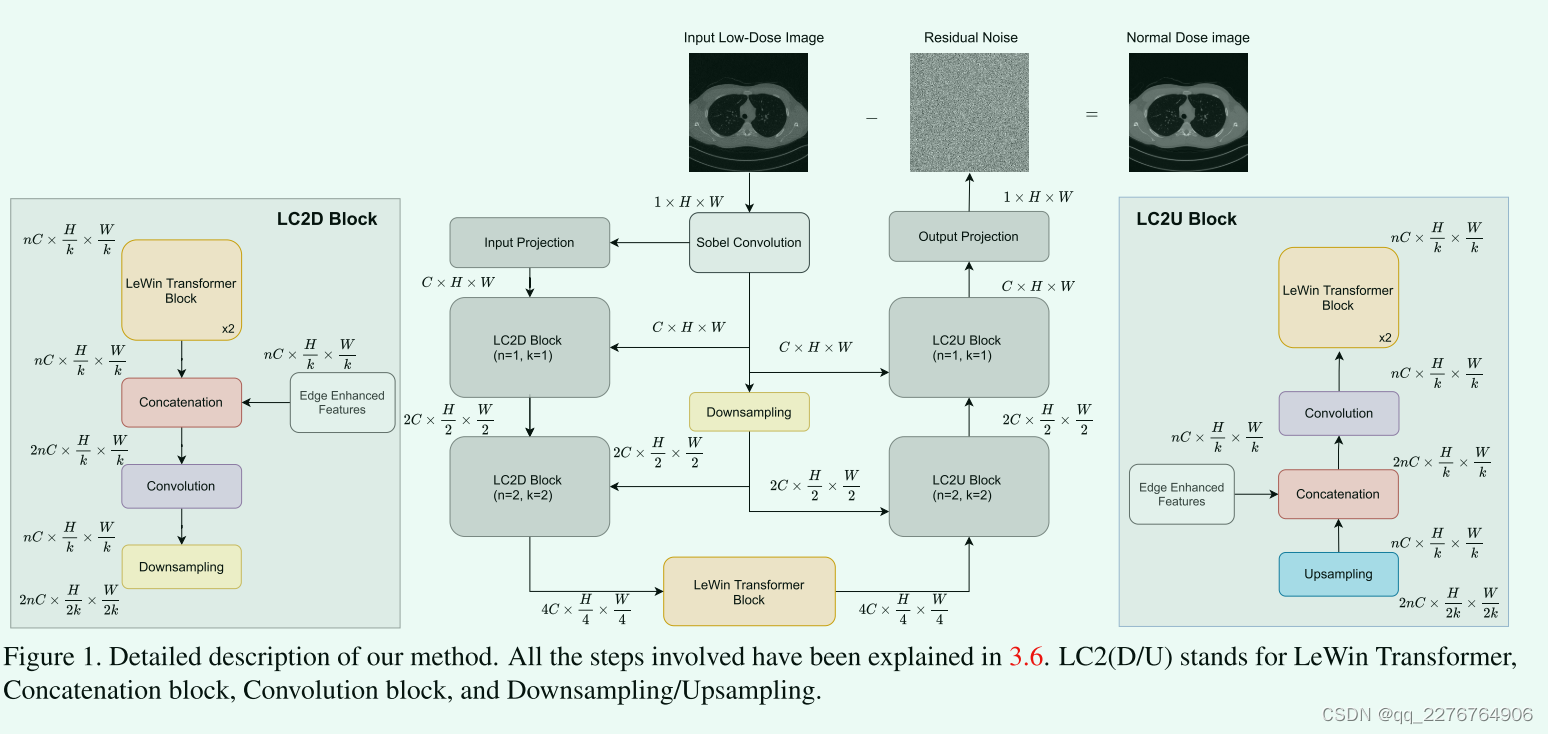
组成前面提到的各个模块,我们的pipeline可以描述如下。 输入图像I首先通过Sobel滤波器以产生S(i),然后是Gelu激活。 作为编码阶段的一部分,在每个阶段,我们将输入通过一个Lewin转换器块,通过与S(I)的串联和随后的卷积操作进行,类似于EDCNN以产生一个编码的特征映射。 然后使用3.3节中描述的过程对特征映射和S(i)进行下采样。 编码后,在bottlenect处,我们将编码器特征图连接到另一个LeWin Transformer块 ,其后连接着跟编码对应阶段的解码器,在解码器的每个阶段,在反卷积后,较早的下采样S(i)本身与上采样的特征图连接,然后通过一个卷积块。解码器阶段可以看作是编码器阶段的对立面,具有共享的S(i)。解码后产生的最终特征图随后通过一个”output project“ 产生所需的残差。这个”output project“是一个卷积层,他只是将c通道特征映射投影到1通道灰度图像。在我们的实验中,我们将LeWin块的深度、Attention heads、和编码器解码器阶段的数量分别设为2.具体架构图见图1
Results and Discussion
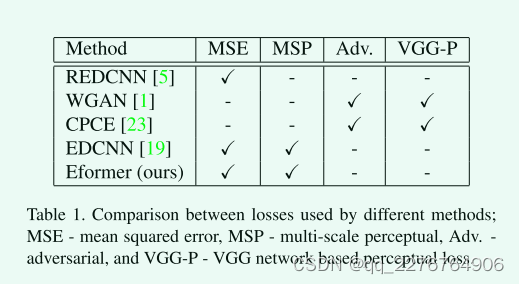
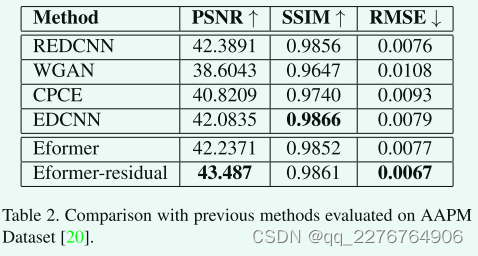
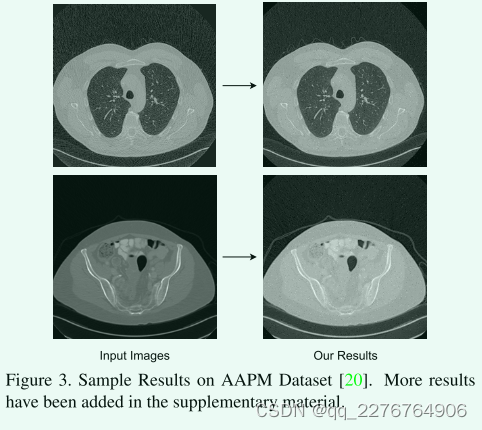
本小节着重介绍通过测量三个不同的指标来判断低剂量CT重建图像的降噪和质量所获得的结果。 我们使用以下指标来评估:峰值信噪比(PSNR)、结构相似度(SSIM)和均方根误差(RMSE)。 PSNR的目标是降噪,是衡量重建质量的一个指标。 SSIM是一种感知度量,它关注图像中可见的结构,是视觉质量的度量。 RMSE跟踪两幅图像之间的绝对像素到像素损失。 我们将我们的结果(如图3所示的示例)与基于卷积体系结构的与我们的模型共享相似之处的体系结构进行比较。 如表1所示,CPCE[23]、WGAN[1]和EDCNN[19]像我们一样使用常用的损失组合来训练模型,而REDCNN[5]只使用MSE。 表2显示,我们提出的模型Eformer和Eformer-Regular在PSNR和MSE指标上都优于现有的方法,表明有效的去噪,我们在SSIM中的类似性能也表明图像的视觉质量很高,并且在重建中没有丢失重要的细节。
experiment
Data details
为了我们的研究工作,我们使用了由癌症影像档案(TCIA)提供的AAPMmayo诊所低剂量CT大挑战数据集[20]。 该数据集包含收集自140例患者的3种类型的CT扫描。 这3种类型的CT扫描分别来自48例、49例和42例患者的腹部、49例胸部和42例头部。 来自每个患者的数据包括与其对应的正常剂量CT扫描配对的低剂量CT扫描。 低剂量CT扫描是在投影数据中插入泊松噪声产生的合成CT扫描。 插入泊松噪声以达到全剂量的25%的噪声水平。 每个CT扫描都是以DICOM(医学数字成像和通信)文件格式给出的。 它是一种标准格式,为不同供应商、计算机和医院之间交换医学图像和相关信息建立了规则。 此格式符合健康信息交换(HIE)标准和HL7标准,用于传输与健康相关的数据。 DICOM文件由头和图像像素强度数据组成。 头部包含存储在分离的“标签”中的关于患者人口统计、研究参数等的信息,图像像素强度数据包含CT扫描的像素数据,在我们的例子中包含大小为512×512的图像的像素数据。 在我们的模型中,为了训练,我们使用PyDICOM库[1]从DICOM文件中提取图像像素数据到NUMPY数组中,然后将NUMPY数组中的像素数据从0缩放到1,以避免不同CT扫描的像素数据的异构跨越。
Parameter Details and Network Training
我们使用PyTorch框架[22]来运行我们的实验。 除Sobel卷积块外,卷积层使用默认方案初始化。 我们强制滤波器参数遵循图4所示的模式,其中α是一个可学习的参数。 我们所有的实验都是在16GB的 NVIDIA TESLA P100 GPU上运行的。 该模型用ADAM[17]优化器训练,使用0.00002的学习率和默认参数。 该模型使用128×128像素的输入大小进行训练,通过将原始大小为512×512的图像调整到128×128像素。 获得的结果如图6所示

conclusion
最后,本文提出了一种基于残差学习的医学图像去噪模型。 我们利用Transformer和边缘增强模块来产生高质量的去噪图像,并使用多尺度感知损失和传统的MSE损失相结合的方法来实现最先进的性能。 我们相信我们的工作将鼓励Transformer在医学图像去噪中的应用。 在未来,我们计划探索我们的模型在许多相关任务上的能力。

















 198
198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









