







 本文深入解析AlphaFold2中的Evoformer模块,介绍其双塔结构及MSA与Pair堆栈间的交互机制。通过MSA行与列的自我关注、外积平均等操作实现蛋白质结构预测。
本文深入解析AlphaFold2中的Evoformer模块,介绍其双塔结构及MSA与Pair堆栈间的交互机制。通过MSA行与列的自我关注、外积平均等操作实现蛋白质结构预测。
AlphaFold2源码解析(7)–模型之Evoformer
这篇文章我们主要药讲解AlphaFold2的Evoformer的代码细节。
Evoformer Stack
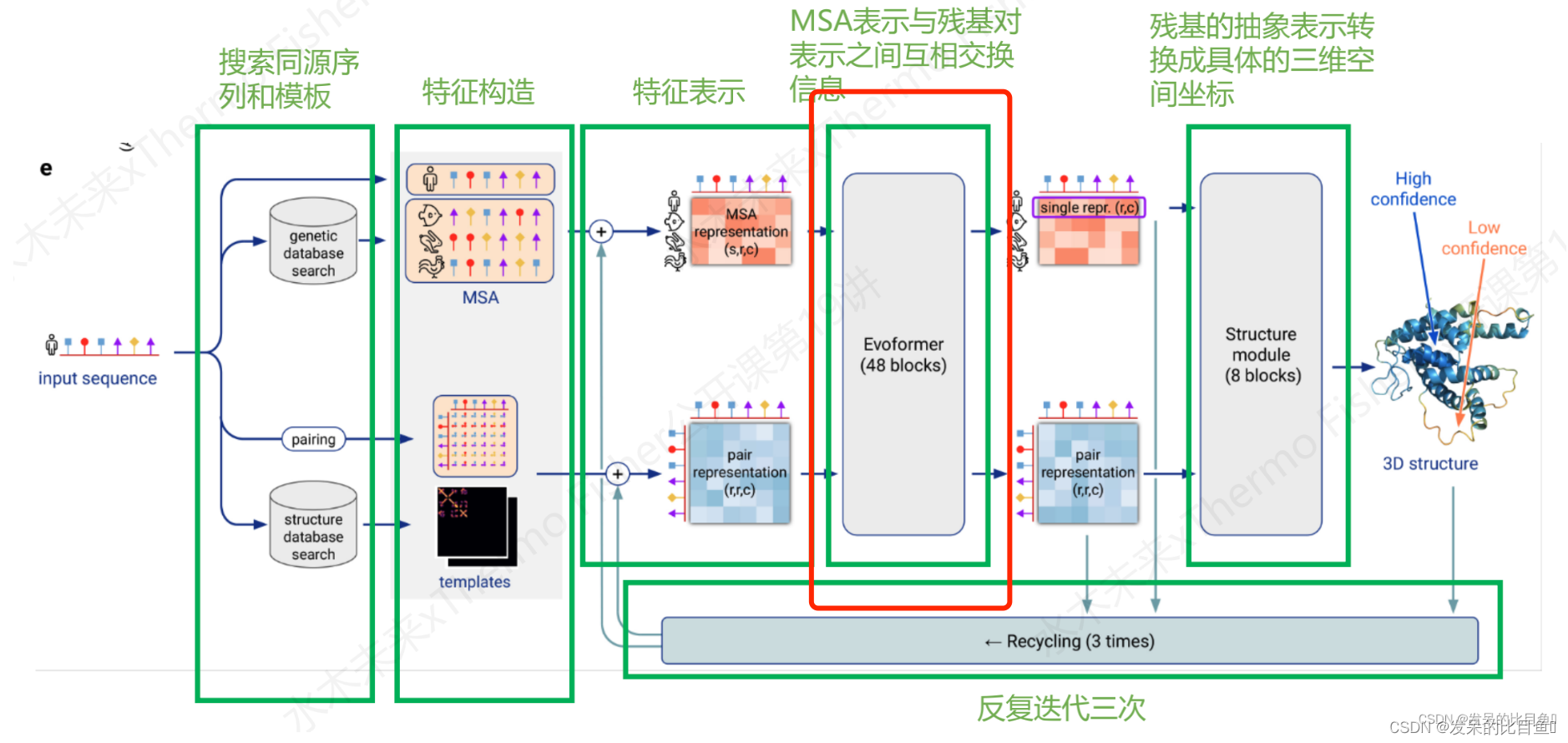
该网络有一个双塔结构,在MSA堆栈中具有轴向的自我注意;在Pair堆栈中具有三角形的乘法更新和三角形的自我注意;以及外积平均和注意偏置,以允许堆栈之间的通信。网络的主干由N_block=48个Evoformer块组成。每个块都有一个MSA表示{m_si}和一个Pair表示{z_ij}作为其输入和输出,并通过几层处理它们。每一层的输出都通过一个剩余连接添加到当前的表示中。一些层的输出在被添加之前要经过Dropout。最后的Evoformer块提供了一个高度处理的MSA表示{m_si}和一个Pair表示{z_ij},其中包含了结构模块\和辅助网络head所需的信息。预测模块也在使用 "单一 "序列表示{s_i},s_i∈R_cs,cs= 384,i∈{1 . . N_res}。这个单一表示是由MSA表示的第一行的线性投影得出的。
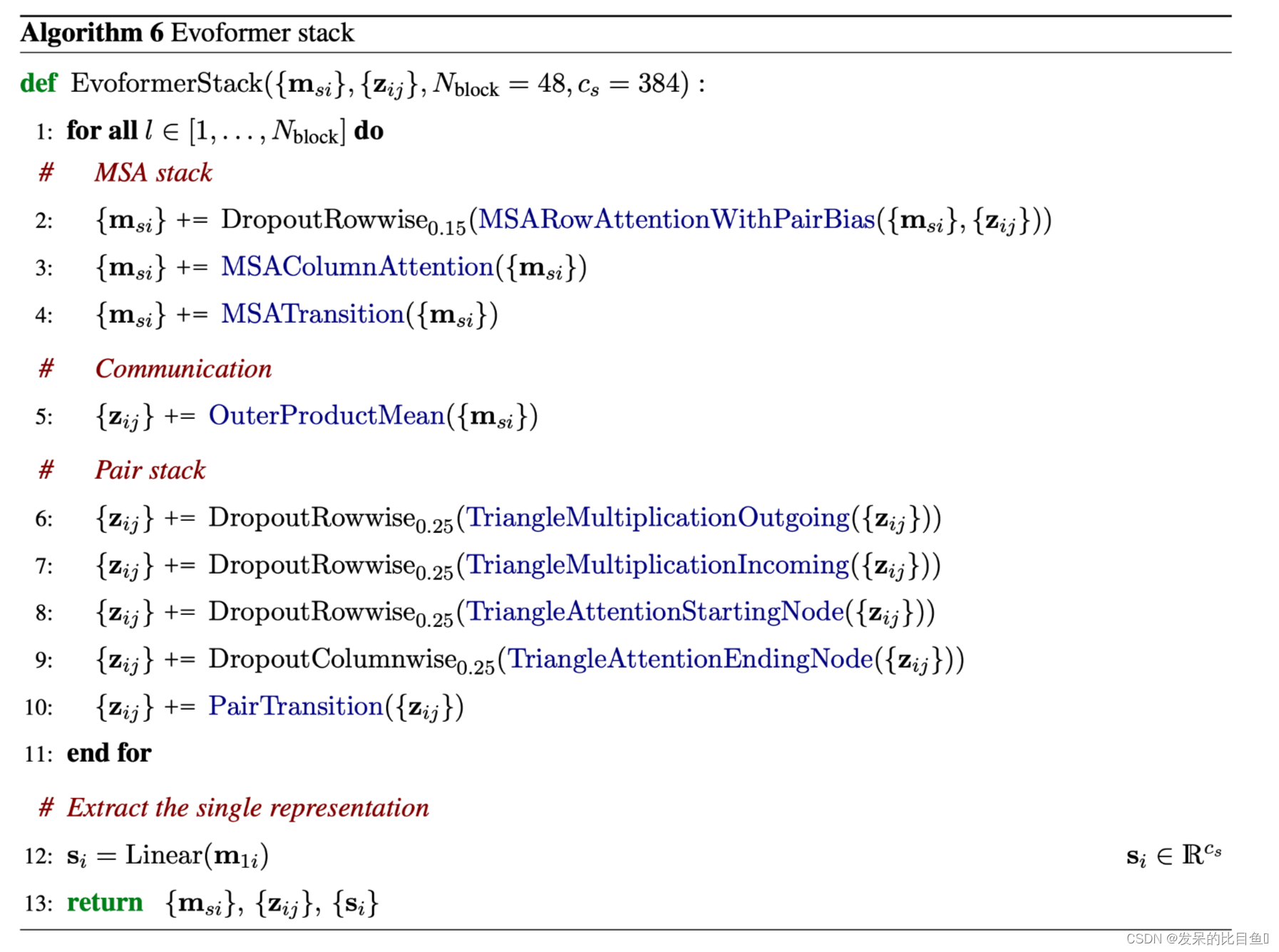
MSA row-wise gated self-attention with pair bias
MSA表征是用连续的门控的行与列的自我注意块来处理的。行向量为残基Pair建立注意力权重,并将来自残基Pair表征的信息整合为一个额外的偏置项。这允许从Pair堆栈到MSA堆栈的信息提取,以鼓励它们之间的一致性。


class MSARowAttentionWithPairBias(hk.Module):
bias = (1e9 * (msa_mask - 1.))[:, None, None, :] # (N_seq, 1, 1, N_res)
assert len(bias.shape) == 4
msa_act = hk.LayerNorm(
axis=[-1], create_scale=True, create_offset=True, name='query_norm')(
msa_act) # (5120, 84, 64)
pair_act = hk.LayerNorm(
axis=[-1],
create_scale=True,
create_offset=True,
name='feat_2d_norm')(
pair_act) # (84, 84, 128)
init_factor = 1. / jnp.sqrt(int(pair_act.shape[-1])) # 初始化因子
weights = hk.get_parameter(
'feat_2d_weights',
shape=(pair_act.shape[-1], c.num_head), # 注意力头的个数
init=hk.initializers.RandomNormal(stddev=init_factor))
nonbatched_bias = jnp.einsum('qkc,ch->hqk', pair_act, weights) # (84, 84, 128) (128, 8) -> (8, 84, 84) LinearNoBias(LayerNorm(zij))
attn_mod = Attention(
c, self.global_config, msa_act.shape[-1])
msa_act = mapping.inference_subbatch(
attn_mod,
self.global_config.subbatch_size,
batched_args=[msa_act, msa_act, bias],
nonbatched_args=[nonbatched_bias],
low_memory=not is_training)
class Attention(hk.Module):
key_dim = self.config.get('key_dim', int(q_data.shape[-1])) # key_dim = 64
value_dim = self.config.get('value_dim', int(m_data.shape[-1])) # value_dim
num_head = self.config.num_head # 8
assert key_dim % num_head == 0
assert value_dim % num_head == 0
key_dim = key_dim // num_head
value_dim = value_dim // num_head
q_weights = hk.get_parameter(
'query_w', shape=(q_data.shape[-1], num_head, key_dim),
init=glorot_uniform()) # (64, 8, 8)
k_weights = hk.get_parameter(
'key_w', shape=(m_data.shape[-1], num_head, key_dim),
init=glorot_uniform()) # (64, 8, 8)
v_weights = hk.get_parameter(
'value_w', shape=(m_data.shape[-1], num_head, value_dim),
init=glorot_uniform()) # (64, 8, 8)
q = jnp.einsum('bqa,ahc->bqhc', q_data, q_weights) * key_dim**(-0.5) # (4, 84, 64) (64, 8, 8) -> (4, 84, 8, 8)
k = jnp.einsum('bka,ahc->bkhc', m_data, k_weights) # (4, 84, 8, 8)
v = jnp.einsum('bka,ahc->bkhc', m_data, v_weights) # (4, 84, 8, 8)
logits = jnp.einsum('bqhc,bkhc->bhqk', q, k) + bias # (4, 84, 8, 8) bqhc (4, 84, 8, 8) bkhc-> (4, 8, 84, 84)bhqk
if nonbatched_bias is not None:
logits += jnp.expand_dims(nonbatched_bias, axis=0)
weights = jax.nn.softmax(logits)
weighted_avg = jnp.einsum('bhqk,bkhc->bqhc', weights, v) # (4, 8, 84, 84) (4, 84, 8, 8) -> (4, 84, 8, 8)
if self.global_config.zero_init:
init = hk.initializers.Constant(0.0)
else:
init = glorot_uniform()
if self.config.gating: ## 添加了门机制
gating_weights = hk.get_parameter(
'gating_w',
shape=(q_data.shape[-1], num_head, value_dim),
init=hk.initializers.Constant(0.0))
gating_bias = hk.get_parameter(
'gating_b',
shape=(num_head, value_dim),
init=hk.initializers.Constant(1.0))
gate_values = jnp.einsum('bqc, chv->bqhv', q_data,
gating_weights) + gating_bias # (4, 84, 8, 8)
gate_values = jax.nn.sigmoid(gate_values) # : g^h_si= sigmoid(Linear(msi))
weighted_avg *= gate_values # (4, 84, 8, 8)
o_weights = hk.get_parameter(
'output_w', shape=(num_head, value_dim, self.output_dim),
init=init)
o_bias = hk.get_parameter('output_b', shape=(self.output_dim,),
init=hk.initializers.Constant(0.0)) # (8, 8, 64)
output = jnp.einsum('bqhc,hco->bqo', weighted_avg, o_weights) + o_bias # (4, 84, 64)
return output
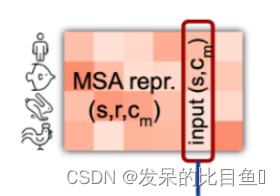
MSA column-wise gated self-attention
逐列关注让属于同一目标残基的元素交换信息。在这两个关注块中,头的数量N_heads=8,k、q和v的尺寸c=32。
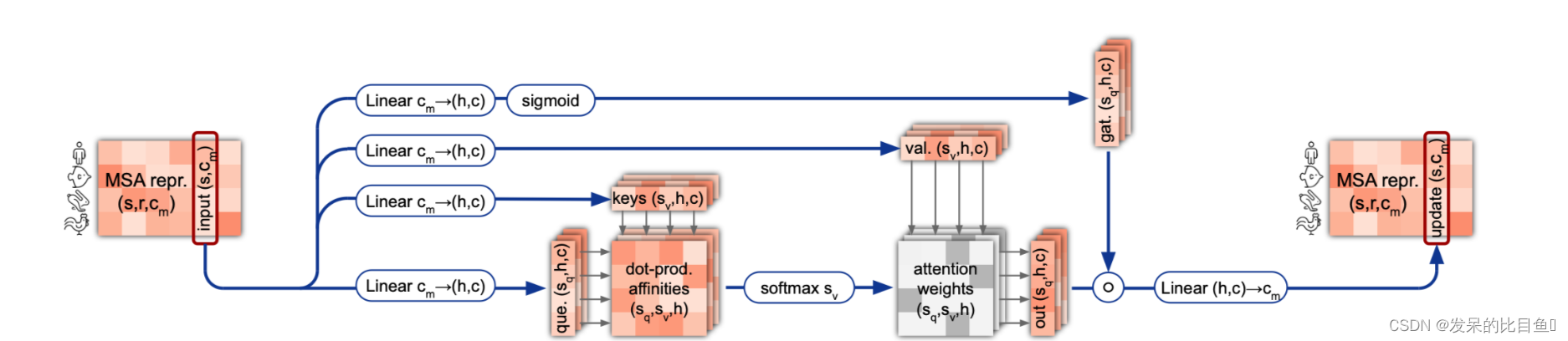

这部分的算法与MSA row-wise gated self-attention with pair bias相似,唯一的区别是输入特征是按照列来取的。
还有需要注意的是 Extract Evoformer Stack 的 column-wise部分使用的是MSAColumn Global Attention,但是Evoformer Stack 的 column-wise部分使用的是MSAColumn Attention
class MSAColumnGlobalAttention(hk.Module):
。。。。。。
bias = (1e9 * (msa_mask - 1.))[:, None, None, :]
assert len(bias.shape) == 4
msa_act = hk.LayerNorm(
axis=[-1], create_scale=True, create_offset=True, name='query_norm')(
msa_act)
attn_mod = GlobalAttention(
c, self.global_config, msa_act.shape[-1],
name='attention')
# [N_seq, N_res, 1]
msa_mask = jnp.expand_dims(msa_mask, axis=-1)
msa_act = mapping.inference_subbatch(
attn_mod,
self.global_config.subbatch_size,
batched_args=[msa_act, msa_act, msa_mask],
nonbatched_args=[],
low_memory=not is_training)
msa_act = jnp.swapaxes(msa_act, -2, -3)
return msa_act
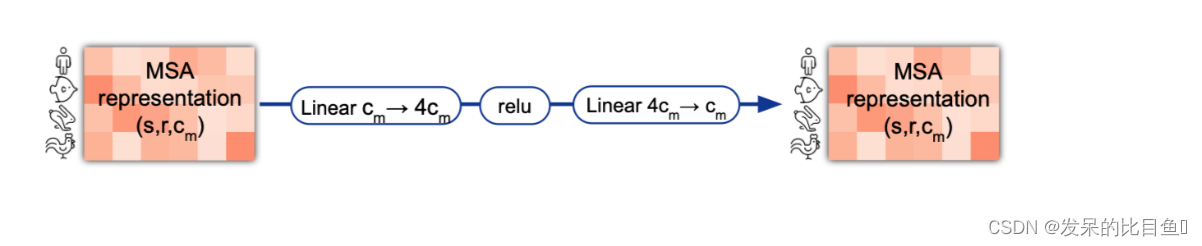
MSA transition
在逐行和逐列注意力之后,MSA栈包含一个2层MLP作为过渡层。中间的通道数将原来的通道数扩大了4倍。

class Transition(hk.Module):
def __call__(self, act, mask, is_training=True):
...........
num_intermediate = int(nc * self.config.num_intermediate_factor) # 256
mask = jnp.expand_dims(mask, axis=-1) #[N_seq, N_res, 1]
act = hk.LayerNorm(
axis=[-1],
create_scale=True,
create_offset=True,
name='input_layer_norm')(
act)#[N_seq, N_res, 64]
transition_module = hk.Sequential([
common_modules.Linear(
num_intermediate, # 256
initializer='relu',
name='transition1'), jax.nn.relu,
common_modules.Linear(
nc, # 64
initializer=utils.final_init(self.global_config),
name='transition2')
])
act = mapping.inference_subbatch(
transition_module,
self.global_config.subbatch_size,
batched_args=[act],
nonbatched_args=[],
low_memory=not is_training)
return act #[N_seq, N_res, 64]
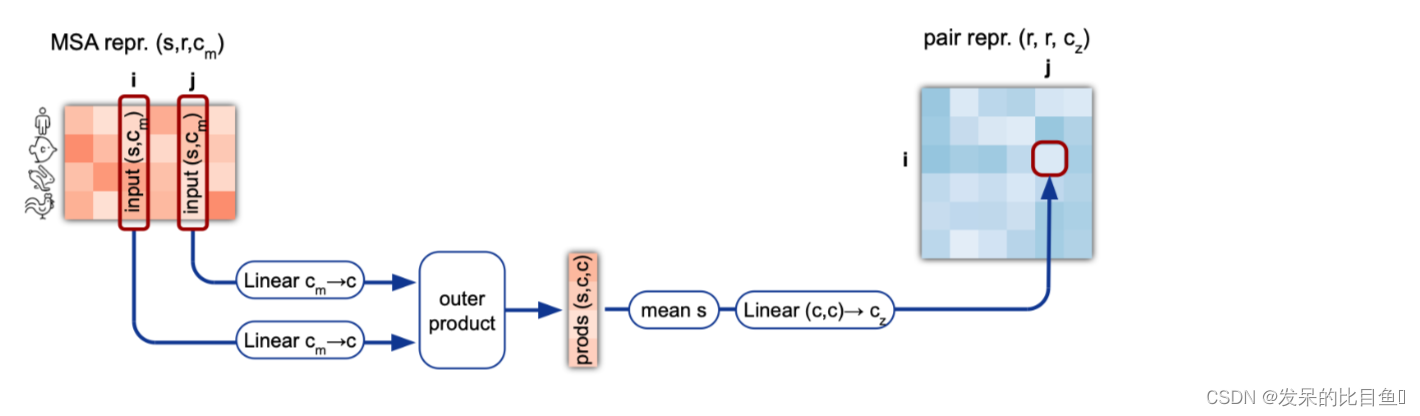
Outer product mean
"外积平均 "块将MSA表示转换为Pair表示的更新。所有的MSA条目都通过两个独立的线性变换被线性地投射到一个较小的维度c=32。来自两列i和j的这些向量的外积在序列上被平均化,并被投射到维度c_z,以获得Pair表示中的条目ij的更新。

class OuterProductMean(hk.Module):
"""Computes mean outer product.
计算平均外积。
"""
def __call__(self, act, mask, is_training=True):
mask = mask[..., None]
act = hk.LayerNorm([-1], True, True, name='layer_norm_input')(act) #(N_seq, N_res, hz)
left_act = mask * common_modules.Linear(
c.num_outer_channel, #32
initializer='linear',
name='left_projection')(
act)
right_act = mask * common_modules.Linear(
c.num_outer_channel, #32
initializer='linear',
name='right_projection')(
act)
if gc.zero_init:
init_w = hk.initializers.Constant(0.0)
else:
init_w = hk.initializers.VarianceScaling(scale=2., mode='fan_in')
output_w = hk.get_parameter(
'output_w',
shape=(c.num_outer_channel, c.num_outer_channel,
self.num_output_channel),
init=init_w)
output_b = hk.get_parameter(
'output_b', shape=(self.num_output_channel,),
init=hk.initializers.Constant(0.0))
def compute_chunk(left_act):
# This is equivalent to
#
# act = jnp.einsum('abc,ade->dceb', left_act, right_act)
# act = jnp.einsum('dceb,cef->bdf', act, output_w) + output_b
#
# but faster.
left_act = jnp.transpose(left_act, [0, 2, 1]) # (N_seq, N_res, hz)-> (N_seq, hz, N_res)
act = jnp.einsum('acb,ade->dceb', left_act, right_act) ##(N_seq, hz, N_res) acd [N_seq, N_res, hz]ade -> [N_res, hz, hz, N_res]
act = jnp.einsum('dceb,cef->dbf', act, output_w) + output_b # [N_res, hz, hz, N_res] dceb [hz, hz, ohz] ->[N_res,N_res, ohz]
return jnp.transpose(act, [1, 0, 2])
act = mapping.inference_subbatch(
compute_chunk,
c.chunk_size,
batched_args=[left_act],
nonbatched_args=[],
low_memory=True,
input_subbatch_dim=1,
output_subbatch_dim=0)
epsilon = 1e-3
norm = jnp.einsum('abc,adc->bdc', mask, mask)
act /= epsilon + norm
return act # (N_res, N_res, 128)
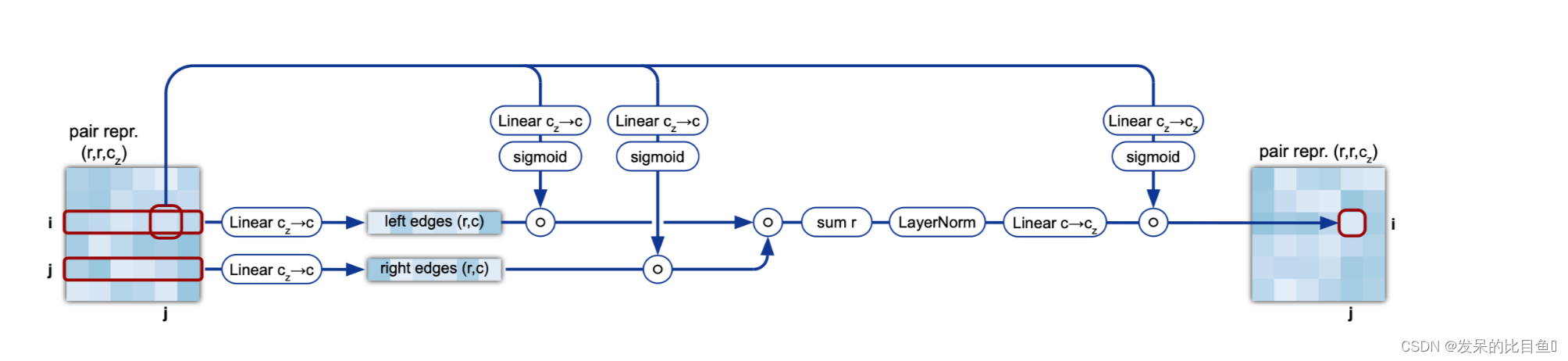
Triangular multiplicative update
三角形乘法更新通过结合每个三角形图边ij、ik和jk内的信息来更新Evoformer块中的Pair表示。每条边ij从所有三角形的其他两条边接收更新,其中涉及到它。有两个对称的版本,一个用于 "传出 "的边,一个用于 "传入 "的边。两者的区别以黄色标出。
这里的Al 11算法与AL 12不同之处是一个按行,一个按列

class TriangleMultiplication(hk.Module):
def __call__(self, act, mask, is_training=True):
"""Builds TriangleMultiplication module.
"""
........
mask = mask[..., None]
act = hk.LayerNorm(axis=[-1], create_scale=True, create_offset=True, name='layer_norm_input')(act)
input_act = act # (N_res, N_res, 128)
left_projection = common_modules.Linear(c.num_intermediate_channel, # 128
name='left_projection')
left_proj_act = mask * left_projection(act) # (N_res, N_res, 128)
right_projection = common_modules.Linear(c.num_intermediate_channel, name='right_projection')
right_proj_act = mask * right_projection(act) # (N_res, N_res, 128)
left_gate_values = jax.nn.sigmoid(common_modules.Linear( c.num_intermediate_channel, bias_init=1.,
initializer=utils.final_init(gc), name='left_gate')(act)) # (N_res, N_res, 128)
right_gate_values = jax.nn.sigmoid(common_modules.Linear(c.num_intermediate_channel, bias_init=1.,
initializer=utils.final_init(gc), name='right_gate')(act)) # (N_res, N_res, 128)
left_proj_act *= left_gate_values
right_proj_act *= right_gate_values
act = jnp.einsum(c.equation, left_proj_act, right_proj_act) # (N_res, N_res, 128)
act = hk.LayerNorm(axis=[-1], create_scale=True, create_offset=True, name='center_layer_norm')(act)# (N_res, N_res, 128)
output_channel = int(input_act.shape[-1])
act = common_modules.Linear(output_channel, initializer=utils.final_init(gc), name='output_projection')(act) # (N_res, N_res, 128)
gate_values = jax.nn.sigmoid(common_modules.Linear(output_channel, bias_init=1.,
initializer=utils.final_init(gc), name='gating_linear')(input_act))
act *= gate_values
return act # (N_res, N_res, 128)
Triangular self-attention
三角形自注意力更新Evoformer块中的Pair表示。起始节点 "版本用来自共享同一起始节点i的所有边的值来更新边ij。决定边ij是否会收到来自边ik的更新不仅由它们的查询键相似度决定,而且还由从这个三角形的第三条边jk衍生的信息bjk调制。此外,我们还用一个从边ij衍生出来的额外的门控gij来扩展更新。这个模块的对称Pair在结束节点周围的边上操作。差异以黄色显示。
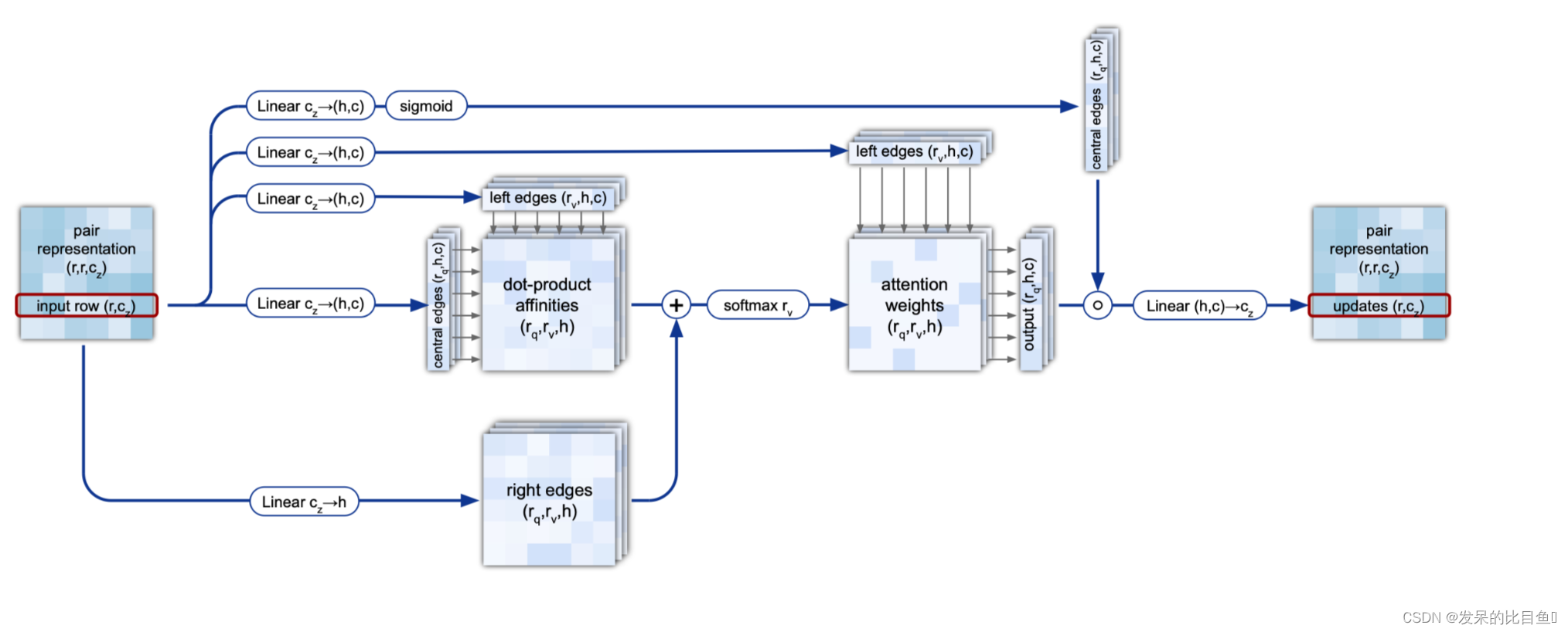
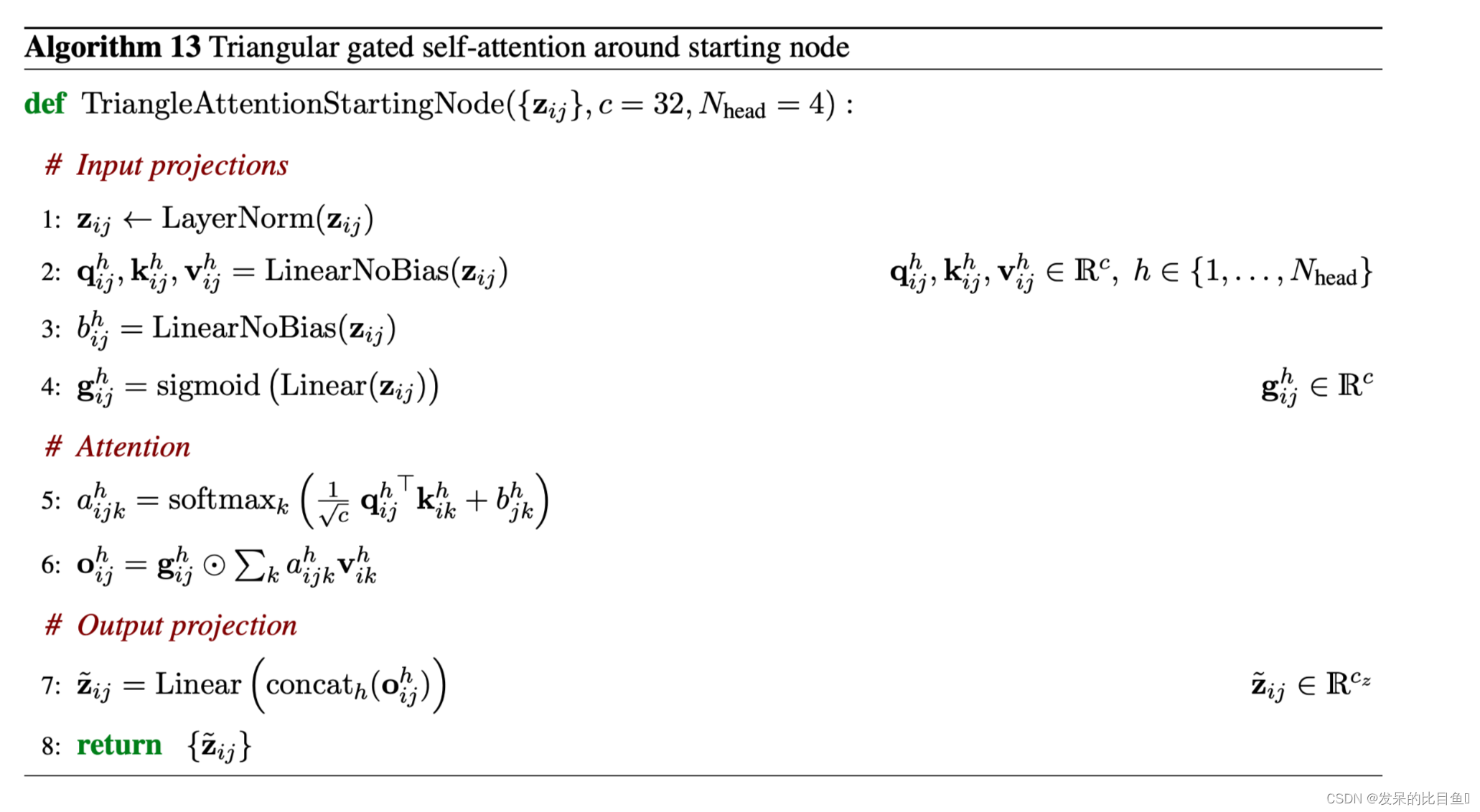

class TriangleAttention(hk.Module):
"""Triangle Attention.
"""
def __call__(self, pair_act, pair_mask, is_training=False):
.......
bias = (1e9 * (pair_mask - 1.))[:, None, None, :]
pair_act = hk.LayerNorm(axis=[-1], create_scale=True, create_offset=True, name='query_norm')(
pair_act) # (N_res, N_res, 128)
init_factor = 1. / jnp.sqrt(int(pair_act.shape[-1]))
weights = hk.get_parameter('feat_2d_weights', shape=(pair_act.shape[-1], c.num_head),
init=hk.initializers.RandomNormal(stddev=init_factor))
nonbatched_bias = jnp.einsum('qkc,ch->hqk', pair_act, weights)
attn_mod = Attention(c, self.global_config, pair_act.shape[-1])
pair_act = mapping.inference_subbatch( attn_mod, self.global_config.subbatch_size,
batched_args=[pair_act, pair_act, bias], nonbatched_args=[nonbatched_bias], low_memory=not is_training)
return pair_act # (N_res, N_res, 128)
Transition in the pair stack
Pair堆栈中的过渡层相当于MSA堆栈中的过渡层:一个2层MLP,中间的通道数将原来的通道数扩大4倍。

act = hk.LayerNorm(
axis=[-1],
create_scale=True,
create_offset=True,
name='input_layer_norm')(
act)#[N_seq, N_res, 64]
transition_module = hk.Sequential([
common_modules.Linear(
num_intermediate, # 256
initializer='relu',
name='transition1'), jax.nn.relu,
common_modules.Linear(
nc, # 64
initializer=utils.final_init(self.global_config),
name='transition2')
])
act = mapping.inference_subbatch(
transition_module,
self.global_config.subbatch_size,
batched_args=[act],
nonbatched_args=[],
low_memory=not is_training)
return act #[N_seq, N_res, 64]
Additional inputs
Template stack
成对的模板特征进行线性投影,形成初始模板表征t_stij,t_stij∈R^ct,ct=64,i,j∈{1 . . N_res},s_t∈{1 . . N_templ}。每个模板表示都是用模板Pair堆栈独立处理的,所有可训练的参数在模板间共享。
输出的表征与模板点对点注意力汇总,其中Pair表征{z_ij}被用来形成查询,并注意力各个模板。这个模块的输出被添加到Pair表征中。
此外,模板扭转角的特征被嵌入一个小的MLP,并与MSA表征相连接,作为额外的序列行。这些额外的行参与所有的MSA堆栈操作,但不参与掩盖的MSA损失。虽然模板扭转角和MSA特征在概念上是不同的量,但它们被嵌入了不同的权重集,因此,学习过程大概会促使嵌入具有可比性,因为它们是由相同的下游模块以相同的权重处理。



if c.template.enabled: # 是否使用模版
template_batch = {k: batch[k] for k in batch if k.startswith('template_')}
template_pair_representation = TemplateEmbedding(c.template, gc)(
pair_activations,
template_batch,
mask_2d,
is_training=is_training)
Unclustered MSA stack
未聚类的MSA序列特征被线性投影以形成初始表征{e_s_{e}i},e_s_{e}i∈Rce,c_e=64,s_e∈{1 . . . N_extra_seq},i∈{1 . . N_res}。这些表示是用包含4个块的Extra MSA堆栈处理的。它们与主要的Evoformer块高度相似,显著的区别是使用了全局的列式自我关注和较小的表示尺寸,以允许处理大量的序列。最终的Pair表征被用作主Evoformer堆栈的输入,而最终的MSA激活是未使用的。
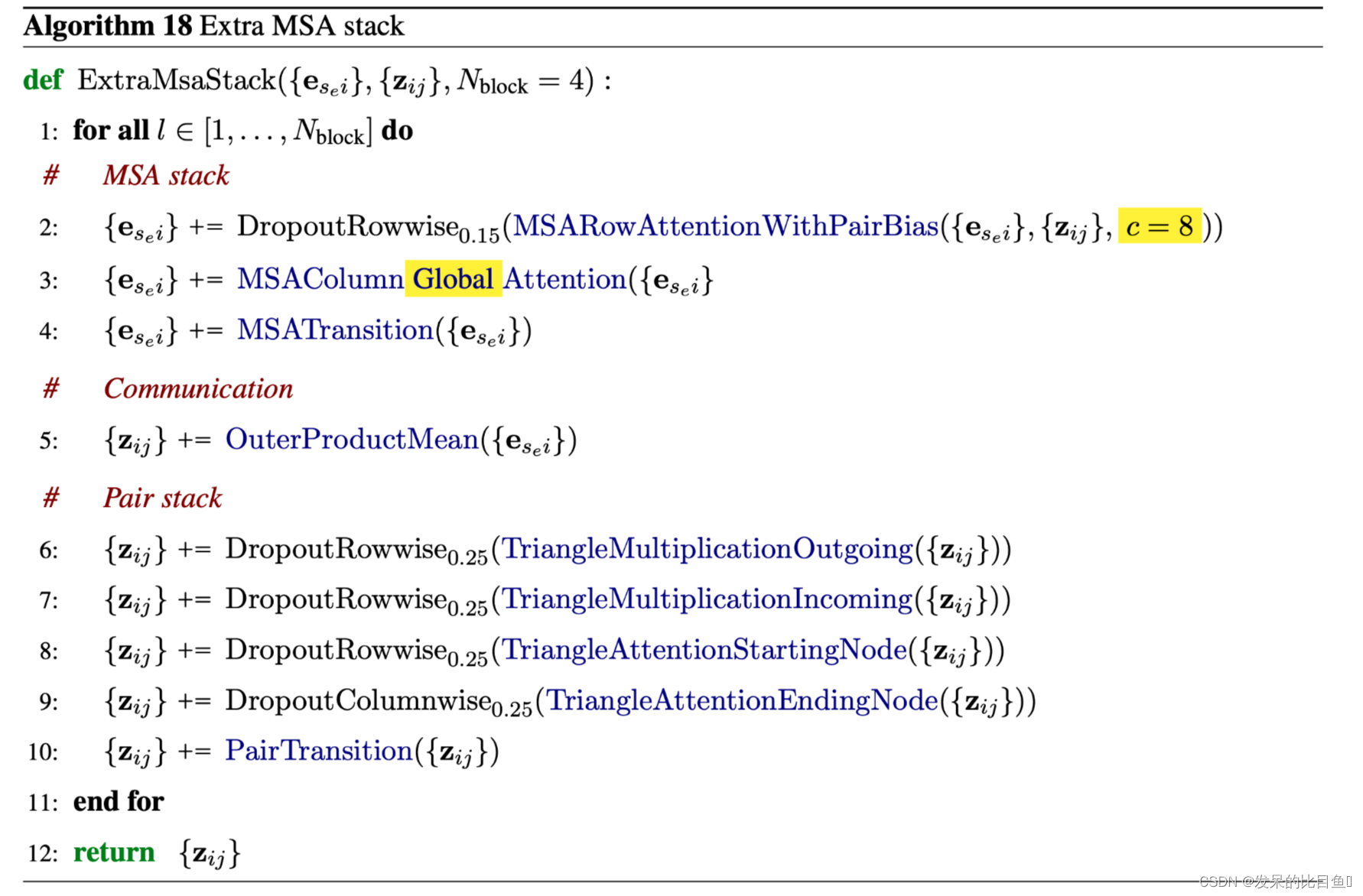

该模块的细节与Evoformer Stack一致,都是使用EvoformerIteration类来做为模型,具体入口如下:
extra_msa_feat = create_extra_msa_feature(batch) #(5120, N_res, 25)
extra_msa_activations = common_modules.Linear(
c.extra_msa_channel,
name='extra_msa_activations')(
extra_msa_feat) # (5120, N_res, 64)
# Extra MSA Stack.
# Jumper et al. (2021) Suppl. Alg. 18 "ExtraMsaStack"
extra_msa_stack_input = {
'msa': extra_msa_activations, # (5120, N_res, 64)
'pair': pair_activations, # (N_res, N_res, 128)
}
extra_msa_stack_iteration = EvoformerIteration(
c.evoformer, gc, is_extra_msa=True, name='extra_msa_stack')


















 1307
1307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











