






决策树是机器学习中最基本的一个模型,即能做分类也能做回归。
决策树重点
决策树其实就是一棵树,其每一个节点都是一个决策判断。数据在进入这棵树后,每个节点会使用输入特征中的其中一个特征进行判断,将数据分流到其不同的子节点中去。
我们构建决策树的主要工作是确定特征判断的先后顺序(比如使用信息增益选择当前使用哪个特征作为当前节点的特征判断)。
决策树的基本想法是随着深度的增加,节点的熵迅速地降低。熵降低的速度越快越好,这样我们就有望得到一颗高度最矮的决策树。
基础知识点
(决策判断条件 的 先后顺序 选择依据)
熵
同交叉熵损失函数中的熵是一个意思(文章末尾写有交叉熵中的熵的详细叙述)。但是这里一般是用来表示集合中元素的混乱程度。(值越大表明集合越混乱,即其中类别越多)。
Gini系数:Gini(p) = 1-Σpk^2
(Gini系数和熵的作用是一样的,使用方式也差不多:值越大表明集合越混乱 即 其中分类越多,pk表示事件k发生的概率)
信息增益
信息增益 = 原始的熵值 – 按新节点分类后的熵值
(bug:如果按信息增益进行决策树构建,那么如果存在这样的一列(如记录ID)其本身是和最终结果没有任何关系的,但是按其进行分类后的信息增益却是最大的(即每一个记录一个分类,这样每个分类内部的熵都为0,再将所有分类乘上其所在分类中记录占总记录的比例仍然为0,最后的总和也是0),所以就有了使用信息增益率来进行判断了)
信息增益率
信息增益率( 举例说明)=信息增益/分类本身的熵
(分类本身的信息增益是指将每一个子节点作为一种类别,其中的记录数/总记录数作为其概率,该分类下的所有子节点作为一个集合 所计算出来的熵)
评价函数:Σ叶子节点中的记录个数 * 叶子节点的熵
决策树构建具体过程
先分别对每一个属性进行 如果其为根节点,其后续的信息增益率 的计算,然后选择信息增益率最大的一个。其子节点也重复这个过程,直到完成决策树的构建。
举例
当前有以下学生是否去上课的历史数据,一开始的熵值为0.598。
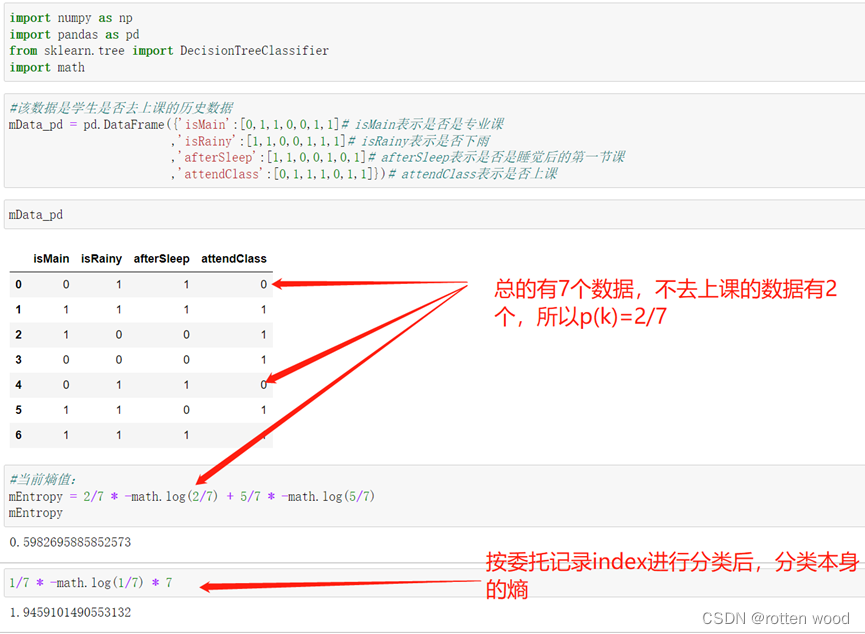
如果我们按其记录ID进行判断分类,则会将其每一条数据分到一个子节点。此时因为每一个子节点中的数据都是一个类别(因为只有一个记录),所以此时每一个子节点内部的熵值都为0,所以此时总的熵值为(1/7 * 0) * 7 = 0,所以此时的信息增益为0.598 = 0.598 – 0。信息增益率为 0.598/((1/7 * -log(1/7)) * 7) = 0.598/1.946(因为7个都是一样的,所以*7)。
熵详述
要了解熵,那么你需要先了解信息量。
信息量
首先是信息量。假设我们听到了两件事,分别如下:
事件A:巴西队进入了今年世界杯决赛圈。
事件B:中国队进入了今年世界杯决赛圈。
显而易见事件B的信息量比事件A的信息量要大。究其原因,是因为事件A发生的概率很大,事件B发生的概率很小。所以当越不可能的事件发生了,我们获取到的信息量就越大。越可能发生的事件发生了,我们获取到的信息量就越小。那么信息量应该和事件发生的概率有关。所以我们有如下信息量I的定义:
I(x0) = -log(p(x0))。
(x0表示某一个事件的一种可能发生情况,p(x0)表示事件x0发生的概率)
熵
一个事件有n种可能性,而熵表示该事件的信息量的期望。
如事件A有3种可能结果(x0,x1,x2),其各种情况发生的概率p(x0)、p(x1)、p(x2)为(0.4,0.3,0.3),则其各种情况的信息量为I(x0)=-log(0.4)、I(x1)=-log(0.3),I(x2)=-log(0.3),其熵为H(X)=p(x0)*I(x0) + p(x1)*I(x1) + p(x2)*I(x2)。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









