









1 需要搞清楚的几个问题
1 .1 变分推断求的是什么
变分推断(Variational Inference, VI)是贝叶斯近似推断的一种方法,将后验推断问题巧妙的转换为优化问题进行求解。贝叶斯公式求解posterior distribution
P
(
Z
∣
X
)
P(Z|X)
P(Z∣X)
P
(
Z
∣
X
)
=
p
(
X
,
Z
)
∫
z
p
(
X
,
Z
=
z
)
d
z
P(Z \mid X)=\frac{p(X, Z)}{\int_{z} p(X, Z=z) d z}
P(Z∣X)=∫zp(X,Z=z)dzp(X,Z).这个公式难以求解的地方在于分母的求解,分母是一个积分,
∫
z
p
(
X
,
Z
=
z
)
d
z
{\int_{z} p(X, Z=z) d z}
∫zp(X,Z=z)dz,而
Z
Z
Z通常是一个高维的随机变量,所以积分难求。其中
P
(
x
,
z
)
=
p
(
z
)
p
(
x
∣
z
)
P(x,z)=p(z)p(x|z)
P(x,z)=p(z)p(x∣z)
另外,这个贝叶斯公式中,
P
(
X
)
P(X)
P(X)表示先验分布。p(x|z)表示似然函数,
p
(
x
)
=
∫
z
p
(
X
,
Z
=
z
)
d
z
p(x)={\int_{z} p(X, Z=z) d z}
p(x)=∫zp(X,Z=z)dz(也称之为evidence)。p(x)是和观测数据x有关系的,因此在计算的时候把他认为是一个常数。
1.2 变分推断是什么
变分推断方法,想求解分布难以确定的p,可以通过寻找易表达和求解的p,当p和q分布接近(距离接近)的时候,我们可以认为q是p的近似分布。因此通过变分推断的思想将求分布的推断问题转换为了求解“缩小距离”的优化问题。
2 求解变分推断的步骤:
2.1 首先构造一个容易求解的分布
q
(
z
;
λ
)
q(z;\lambda)
q(z;λ)
2.2 调整q分布中的参数
λ
\lambda
λ,使得分布q不断的去接近分布p,通常采用KL散度去衡量两个分布之间的距离,因此这个优化问题就转换为如下的形式:
min
λ
K
L
(
q
(
z
;
λ
)
∥
p
(
z
∣
x
)
)
\min _{\lambda} K L(q(z ; \lambda) \| p(z \mid x))
minλKL(q(z;λ)∥p(z∣x))
但是这个KL散度中还是包含着
P
(
Z
∣
X
)
P(Z \mid X)
P(Z∣X)这个后验分布,所以依然难求。
通过等价变化,我们可以将上面这个KL散度转化为如下的形式:
log
P
(
x
)
=
K
L
(
q
(
z
;
λ
)
∥
p
(
z
∣
x
)
)
+
E
q
(
z
;
λ
)
log
p
(
x
,
z
)
q
(
z
;
λ
)
\log P(x)=K L(q(z ; \lambda) \| p(z \mid x))+\mathbb{E}_{q(z ; \lambda)} \log \frac{p(x, z)}{q(z ; \lambda)}
logP(x)=KL(q(z;λ)∥p(z∣x))+Eq(z;λ)logq(z;λ)p(x,z)
通常下,
l
o
g
p
(
x
)
logp(x)
logp(x)可以看成是常量,所以最小化
min
λ
K
L
(
q
(
z
;
λ
)
∥
p
(
z
∣
x
)
)
\min _{\lambda} K L(q(z ; \lambda) \| p(z \mid x))
minλKL(q(z;λ)∥p(z∣x))等价于:
max
λ
E
q
(
z
;
λ
)
log
p
(
x
,
z
)
q
(
z
;
λ
)
\max _\lambda \mathbb{E}_{q(z ; \lambda)} \log \frac{p(x, z)}{q(z ; \lambda)}
maxλEq(z;λ)logq(z;λ)p(x,z)
因此变分推断的进一步目标转换为:
max
λ
E
q
(
z
;
λ
)
[
log
p
(
x
,
z
)
−
log
q
(
z
;
λ
)
]
\max _\lambda \mathbb{E}_{q(z ; \lambda)}[\log p(x, z)-\log q(z ; \lambda)]
maxλEq(z;λ)[logp(x,z)−logq(z;λ)]
E
q
(
z
;
λ
)
[
log
p
(
x
,
z
)
−
log
q
(
z
;
λ
)
]
\mathbb{E}_{q(z ; \lambda)}[\log p(x, z)-\log q(z ; \lambda)]
Eq(z;λ)[logp(x,z)−logq(z;λ)]称为 Evidence lower Bound(ELBO),
P
(
X
)
P(X)
P(X)称之为evidence 而
K
L
(
P
∣
∣
Q
)
>
0
KL(P||Q)>0
KL(P∣∣Q)>0,所以
p
(
x
)
>
=
E
q
(
z
;
λ
)
[
log
p
(
x
,
z
)
−
log
q
(
z
;
λ
)
]
p(x)>=E_{q(z ; \lambda)}[\log p(x, z)-\log q(z ; \lambda)]
p(x)>=Eq(z;λ)[logp(x,z)−logq(z;λ)],因此称之为ELBO
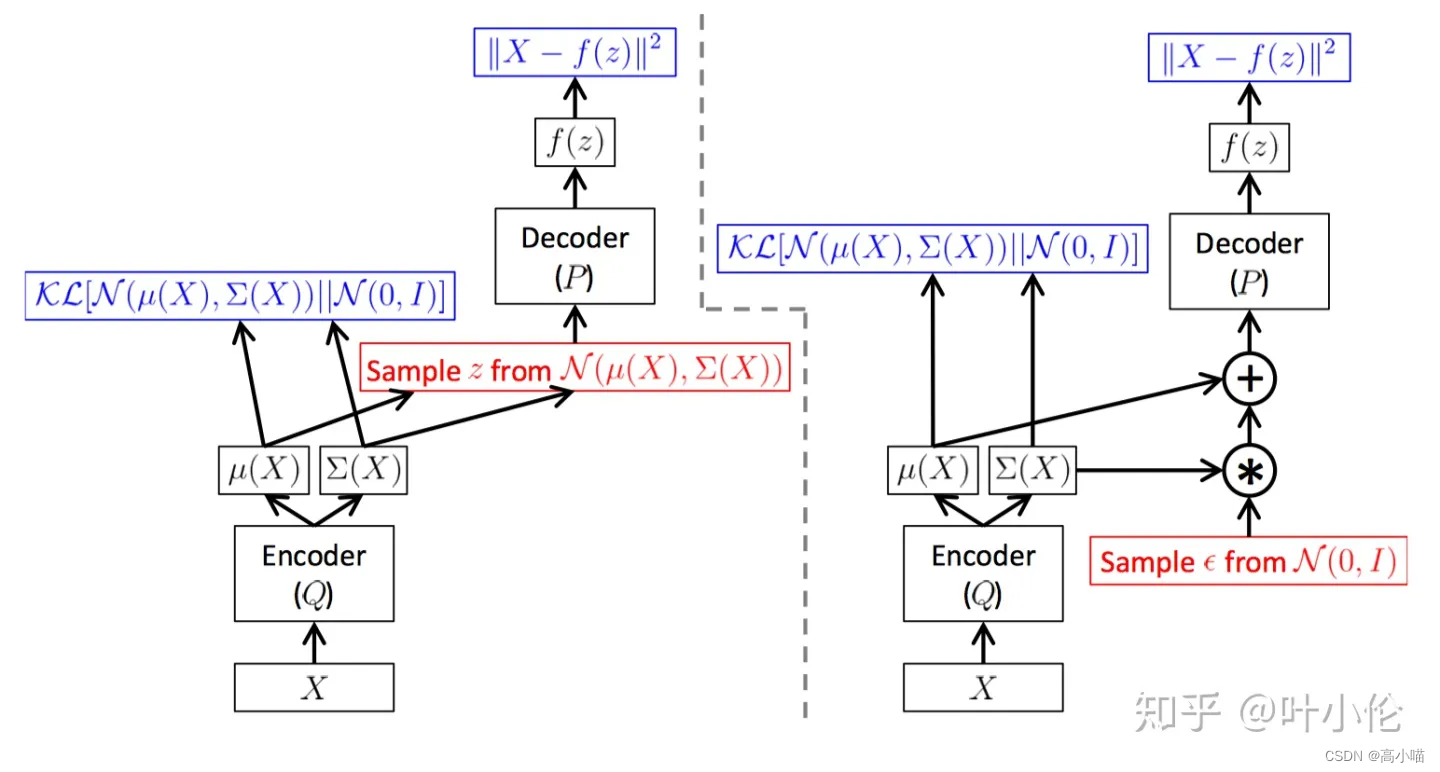
通过下面这个公式可以看出VAE的计算流程以及为了优化VAE网络参数所需要的两个loss
其一是:重构损失:
∣
∣
x
−
f
(
z
)
∣
∣
2
||x-f(z)||^{2}
∣∣x−f(z)∣∣2,第二项是编码约束损失
K
L
[
N
(
μ
(
X
)
,
Σ
(
X
)
)
∣
∣
N
(
0
,
I
)
]
\mathcal{K} \mathcal{L}[\mathcal{N}(\mu(X), \Sigma(X))|| \mathcal{N}(0, I)]
KL[N(μ(X),Σ(X))∣∣N(0,I)]
参考blog:
https://www.zhihu.com/question/41765860














 4744
4744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









