







 本文介绍了ResNet的不同变种,包括ResNet-B/C/D,Res2Net,ResNeXt及ResNeSt,详细阐述了各自的创新点和技术细节,如多尺度特征提取、分组卷积的应用等。
本文介绍了ResNet的不同变种,包括ResNet-B/C/D,Res2Net,ResNeXt及ResNeSt,详细阐述了各自的创新点和技术细节,如多尺度特征提取、分组卷积的应用等。
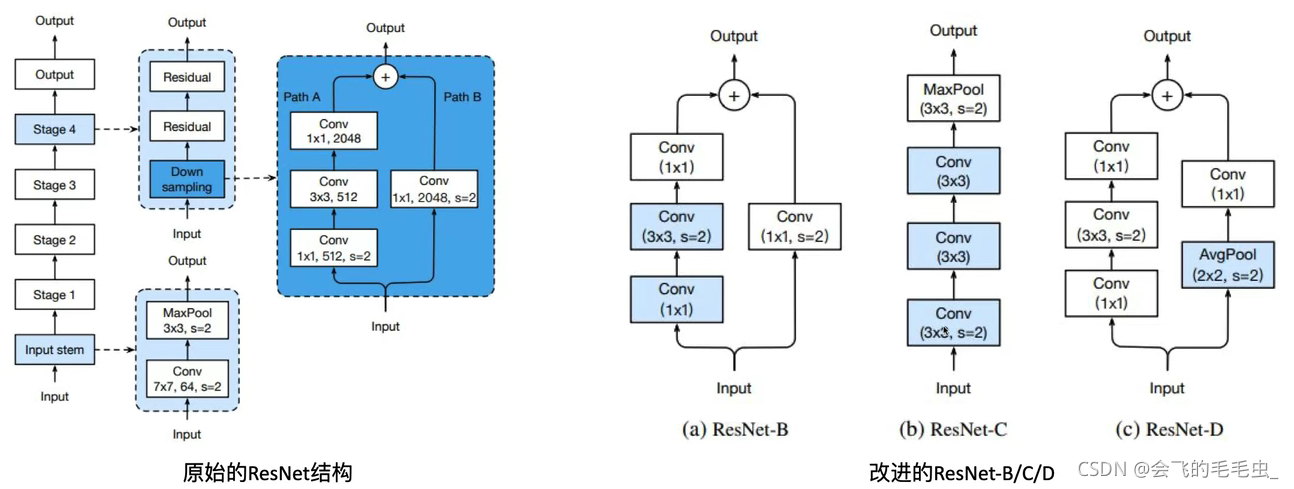
ResNet-B/C/D
-
ResNet-B:将残差分支的下采样移到后面的3×3卷积里,避免了信息的大量流失。因为原始1×1卷积既要降维又要降尺寸,信息流失比较严重,因此做一个解耦。
-
ResNet-C:将输入部分的7×7卷积核替换为3个3×3卷积核,显著降低参数量和计算量。
-
ResNet-D:在ResNet-B的基础上,做了一个解耦,将identity部分的下采样交给avg pool去做,避免出现1×1卷积和下采样同时出现造成信息流失。
Res2Net
-
理解多尺度目标:目标在输入图片里面所占的尺寸是多变的,如果不满足这一要求,就不要在训练中增加多尺度训练和随即裁剪。
-
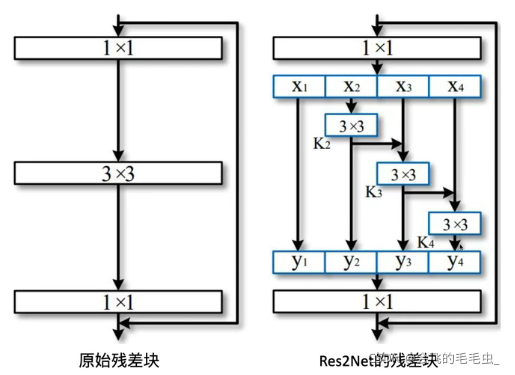
创新点:
① 在更细的粒度来提取多尺度特征
② 用了分组卷积替换正常残差卷积,保证了参数量、计算量和原始残差块相当。
如图所示,K2拿到了3×3的感受野特征,K3拿到了5×5的感受野特征,K4拿到了7×7的感受野特征,因此在一个卷积内部有多种感受野,因此可以捕获多尺度目标。
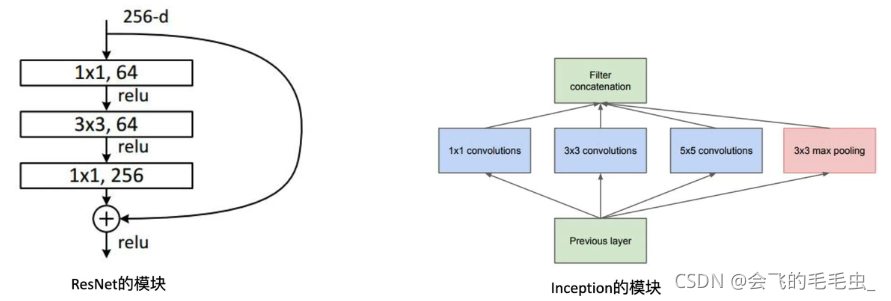
ResNeXt
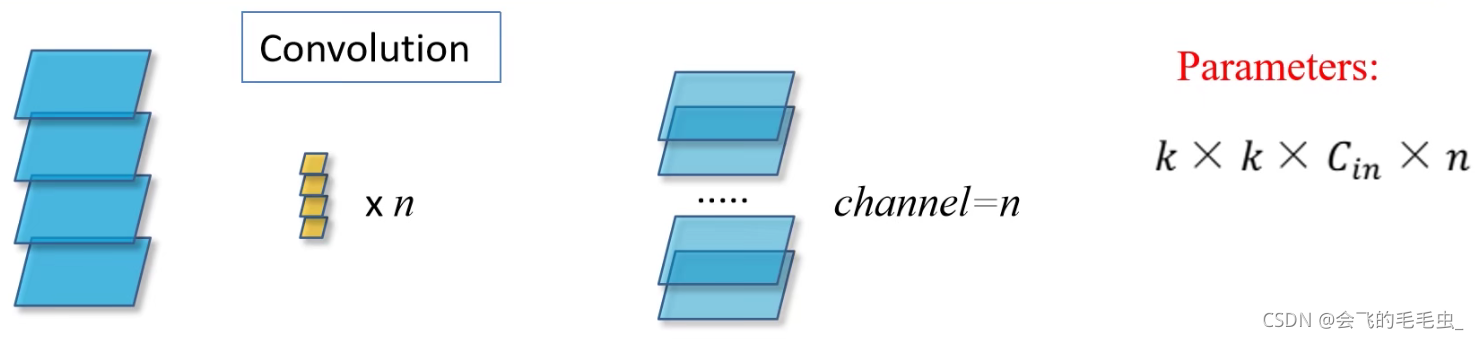
假设输入channel为4,此时对于每一个卷积核,其channel要和输入特征的channel保持一致,而输出特征channel为n,那么就需要n个卷积核来进行卷积处理。 假设每个卷积核的高和宽都是k,输入特征矩阵的channel为Cin,则对于每一个卷积核来说参数个数为K×K×Cin,则n个卷积核的参数量为K×K×Cin×n。
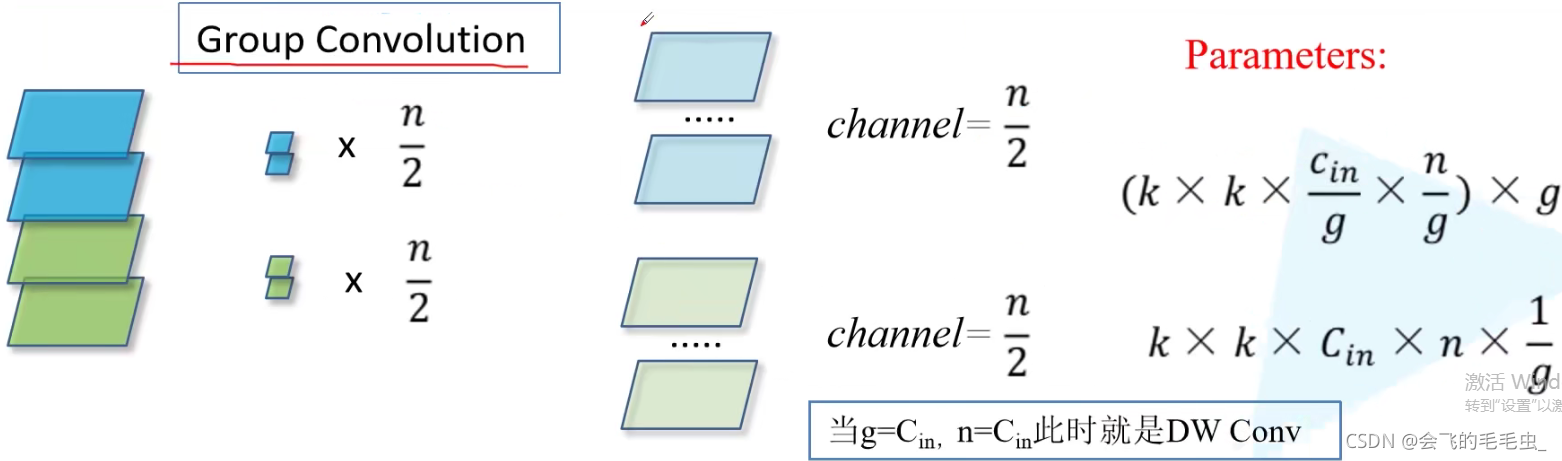
同样假设输入channel为4,但将其划分为两个组,对每一个组分别进行卷积操作,此时对于其中一个组:每一个卷积核,其channel要和输入特征的channel保持一致,则为2。假设使用n/2个卷积核,则能够得到channel为n/2的特征矩阵。最后,将输出矩阵进行concat拼接,最终得到的特征矩阵channel也是为n的。假设每个卷积核的高和宽都是k,输入特征矩阵的channel为Cin,并将其分为g组,则对于每一个卷积核来说参数个数为K×K×Cin/g,对于每一个group而言,n/h个卷积核的参数个数为K×K×Cin/g×n/g,总参数量再×g,最后化简结果如图所示。 可以看出采用组卷积后,其参数量为普通卷积的1/g。
当g和输入特征的channel和输出特征的channel均相等时,则就相当于对输入特征矩阵的每一个channel都分配了一个channel为1的卷积核进行卷积,也就是MobileNet中的DW卷积。
-
创新点:将ResNet的计算模式和Inception的计算模式进行合并。ResNet计算模式为shortcut分支,Inception的计算模式分为三步,分别是split-transform-merge,其存在问题就是手工设计痕迹太重。
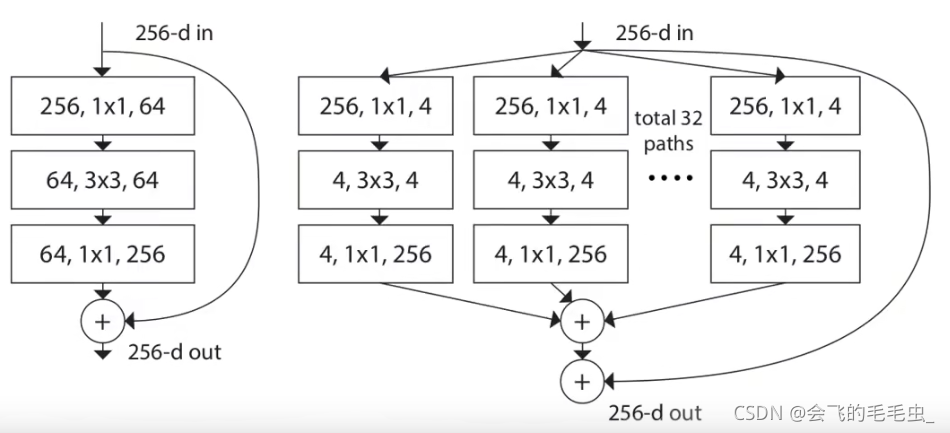
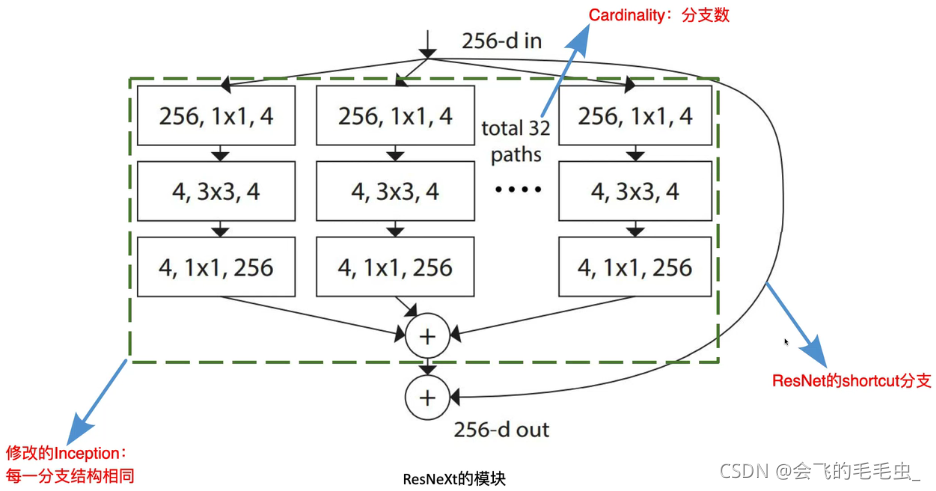
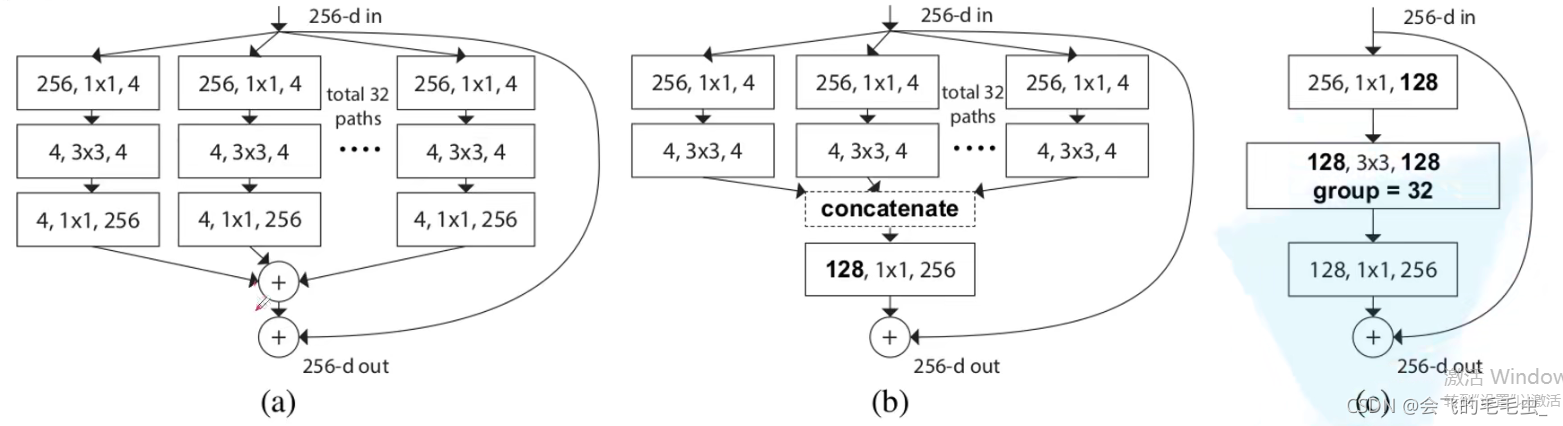
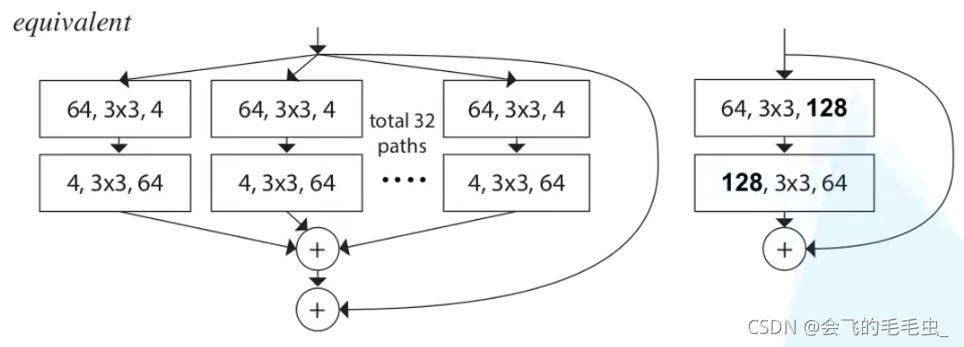
b的每一层模块都和c互相等价,输入是channel为256的特征矩阵,随后经过32个分支(32个group组),每个分支都经过了1×1,卷积核个数为4的卷积层,随后经过3×3卷积后对输出做concat拼接。a和b的区别就是最后对每个group进行1×1的卷积后然后相加。
-
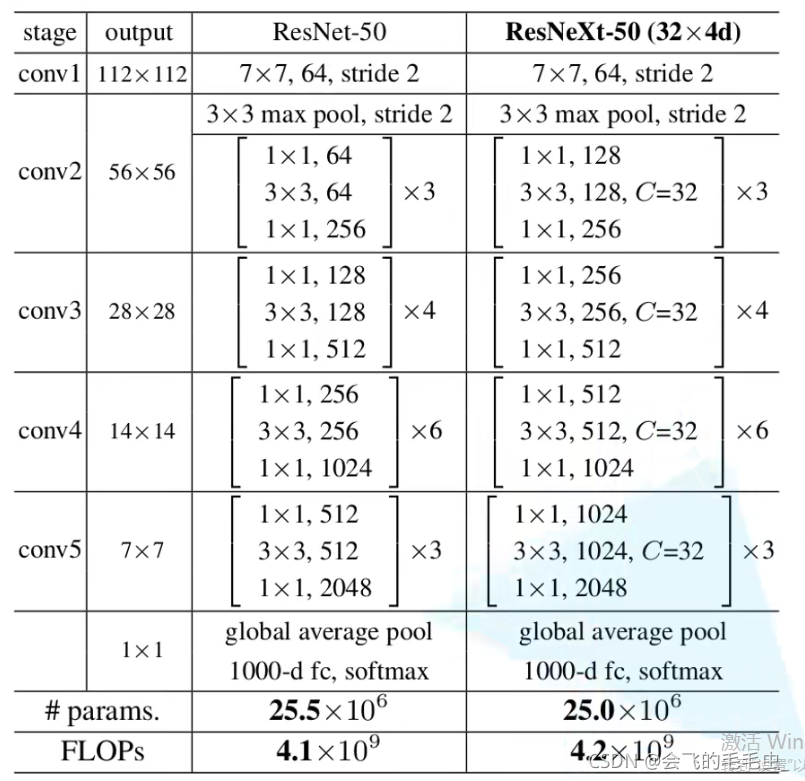
下表为 ResNeXt-50的参数列表:二者原理基本类似,都是将block进行大量的堆叠。 32为Group数,4代表conv2一系列组卷积中每一个组所采用卷积核的个数,即128/32=4。二者的计算量也类似。为什么Group中要设置为32呢?原论文中作者发现随着Group的不断增加,精确度是越来越高的。注意:对于block小于3的结构而言,上述结构是没有作用的,也就是resnet-18之类的网络。
ResNeSt
-
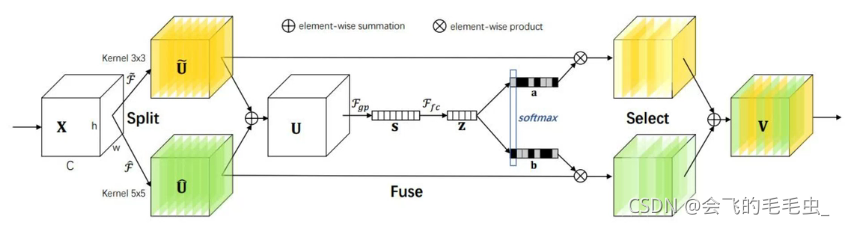
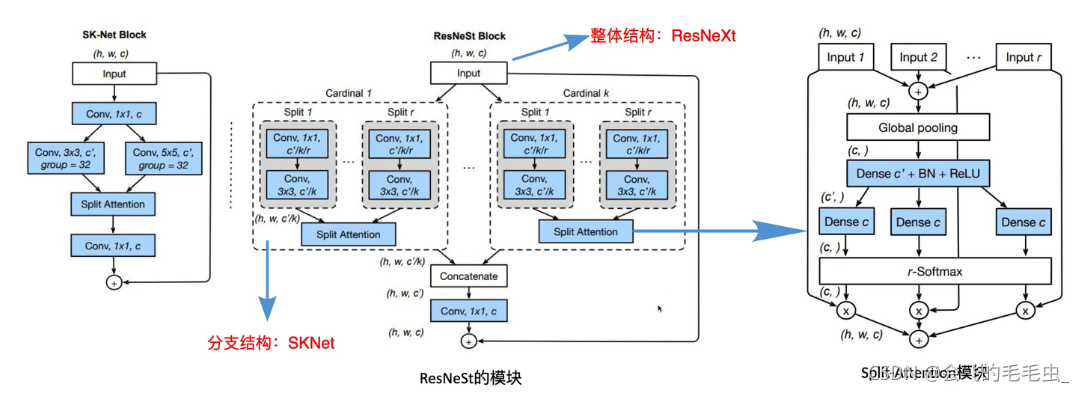
下图是ResNeSt网络结构:Dense c’可以是全连接层也可以是卷积层。Dense c是1×1的卷积层,r-Softmax是不同分支同一通道的Softmax,最后得到注意力模块,将其与原始特征相乘。



















 1928
1928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











