







训练神经网络 part II
梯度检查(Gradient checks)
健全性检查(Sanity checks)
- 先单独检查data loss(将正则化强度设置为0)。进行第二次sanity check,增加正则化强度应导致损失增加。
- 先从小量数据开始,去掉正则化项,能否将损失训练至0,能则完成了完整性检查,可以用所有数据开始训练。
监视学习过程(Babysitting the Learning Processing)
损失函数(Loss Function)
训练过程中可用于跟踪的第一个量是损失,它是在前进过程中对各个批次(batch)进行评估的。
学习率低时,改进是线性的。学习率升高,改进更像指数。较高的学习率将更快地降低损失,但会陷于更坏的损失值(绿线)。这是因为优化中存在太多的“能量”,并且参数混乱地跳动,无法在优化过程中找到一个合适的位置。
训练/验证准确度(Train/Val accuracy)
训练分类器时要跟踪的第二个重要量是 validation/training准确性。

训练和验证准确性之间的差距表明过度拟合的程度。两种可能的情况:
- 与训练精度相比,蓝色的验证误差曲线显示出非常小的验证精度,表明强烈的过拟合(验证精度有可能在某个点之后甚至开始下降)。可增加正则化(更重的L2权重惩罚,更多的dropout)或收集更多数据。
- 另一种可能的情况是,验证准确性很好地跟踪了训练准确性。这种情况表明模型容量不够高:通过增加参数数量来使模型更大。
参数更新(Parameter updates)——优化方法
一阶方法
SGD
即最原始的版本:
# Vanilla update
x += - learning_rate * dx
SGD的问题:
如果遇到局部最小值和鞍点(saddle point),则梯度为0,停止更新。注意,在高维“鞍点”更为常见。
SGD with Momentum(动量)
相比原始SGD有更快的收敛速度。它模拟的是物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向。
可以理解成一个小球下降时遇到局部最优或鞍点时没有停止,而是具有一定的速度继续运动,从而摆脱局部最优:

实际的更新可以看作速度和梯度的矢量和:

即相比原始SGD,只是用(速度和梯度)合成的新速度代替了原始梯度:
rho为摩擦衰减系数,此变量会衰减速度并降低系统的动能,否则粒子将永远不会停在山底。 typically rho=0.9 or 0.99。
note中给出的实现如下,mu和上述的rho是一样的:
# Momentum update
v = mu * v - learning_rate * dx # integrate velocity
x += v # integrate position
SGD with Nesterov Momentum
是动量更新的一个略有不同的版本。它对凸函数具有更强的理论收敛性保证,并且在实践中它始终比标准动量稍好。
如右图,具体过程为: 首先,按照原来的更新方向更新一步(绿线),然后在该位置计算梯度值(红线),然后用这个梯度值修正最终的更新方向(蓝线)。
直观的实现:

x_ahead = x + mu * v #绿线
# evaluate dx_ahead (the gradient at x_ahead instead of at x)
v = mu * v - learning_rate * dx_ahead #得到蓝线
x += v
但是,在实践中,人们倾向于将更新表示为与原始SGD相似,或者尽可能与以前的动量更新相似。利用变量替换:

v_prev = v # back this up
v = mu * v - learning_rate * dx # velocity update stays the same
x += -mu * v_prev + (1 + mu) * v # position update changes form
SGD,SGD+Momentum,SGD+Nesterov Momentum对比:

自适应学习率
AdaGrad
思想:
- 在优化过程中,对每一步梯度的平方和进行持续累计
- 当更新参数时,将除以该平方和
# Assume the gradient dx and parameter vector x
cache += dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps) # eps为平滑项,用来保证分母非0,通常设置在1e-4至1e-8的某个范围内
这使得其具有如下特点:
- 接收高梯度的weights将降低其有效学习率,即降低高梯度上的学习速度(movement)
- 接收较小或不经常更新的weights将提高其有效学习率,即加速低梯度上的学习速度(movement)
缺点:
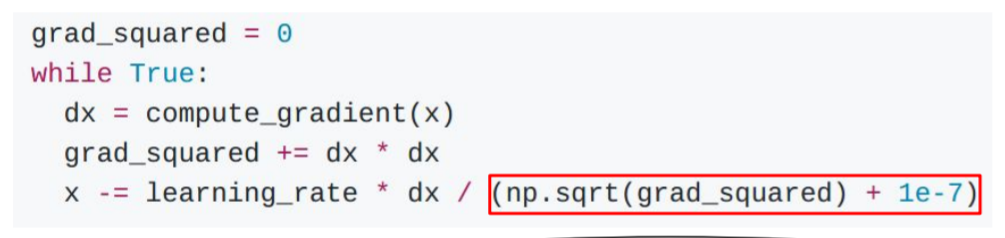
随着训练迭代次数增多,累计梯度平方和单调递增,故分母项越来越大,step会越来越小,这会引起提前停止学习。
RMSProp
解决Adagrad学习率急剧下降(步长急剧减小)的问题,RMSProp改变了二阶动量计算方法,即用窗口滑动加权平均值计算二阶动量。
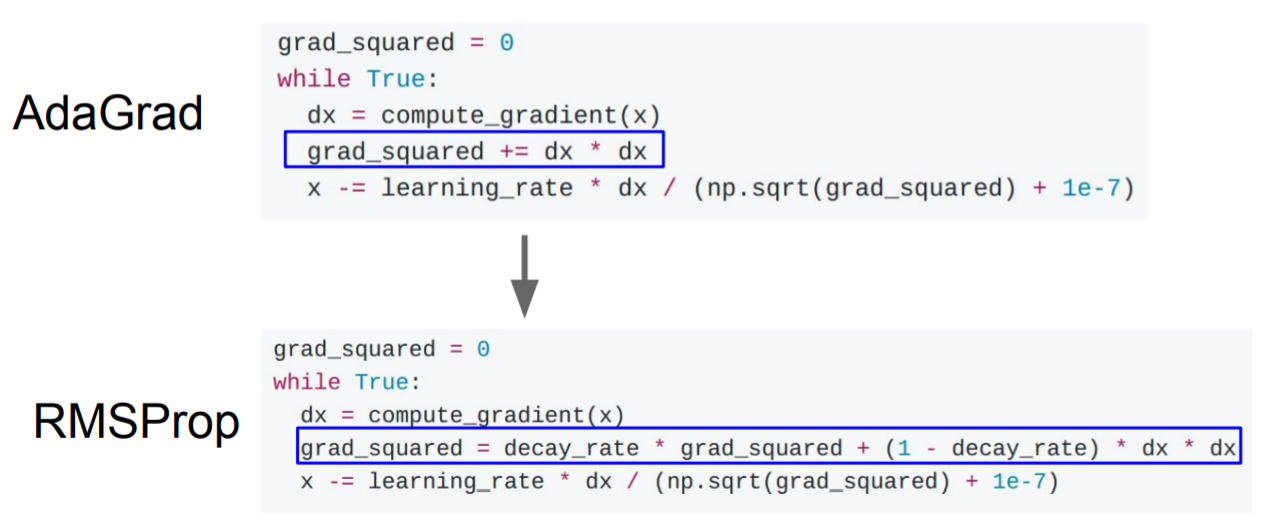
cache = decay_rate * cache + (1 - decay_rate) * dx**2 # decay_rate是一个超参数,典型值为[0.9,0.99,0.999]。
x += - learning_rate * dx / (np.sqrt(cache) + eps)
Adam——RMSprop和动量法的结合体
Adam = Adaptive + Momentum,顾名思义Adam集成了SGD的一阶动量和RMSProp的二阶动量。
# Momentum
m = beta1*m + (1-beta1)*dx
# RMSprop
v = beta2*v + (1-beta2)*(dx**2)
x += - learning_rate * m / (np.sqrt(v) + eps)
完整的Adam更新还包括偏置校正机制:
# t is your iteration counter going from 1 to infinity
# Momentum
m = beta1*m + (1-beta1)*dx
mt = m / (1-beta1**t) # Bias correction
# RMSprop
v = beta2*v + (1-beta2)*(dx**2)
vt = v / (1-beta2**t) # Bias correction
x += - learning_rate * mt / (np.sqrt(vt) + eps)
经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。
Adam with beta1 = 0.9,beta2 = 0.999,and learning_rate = 1e-3 or 5e-4 is a great starting point for many models!
Demo动画

- 左:损失表面的轮廓和不同优化算法的随时间演变。注意基于动量的方法的“过冲”行为,这使优化看起来像是滚下山坡的球。
- 右:优化场景中的鞍点的可视化,其中沿不同维度的曲率具有不同的符号(一个维度向上弯曲,另一个向下弯曲)。请注意,SGD很难打破对称性,并且卡在顶部。相反,诸如RMSprop之类的算法将在鞍形方向上看到非常低的梯度。由于RMSprop更新中的分母项,这将提高此方向上的有效学习率,从而有助于RMSProp进行。

二阶方法
先看一阶优化,在稍大的区间一阶逼近不成立:
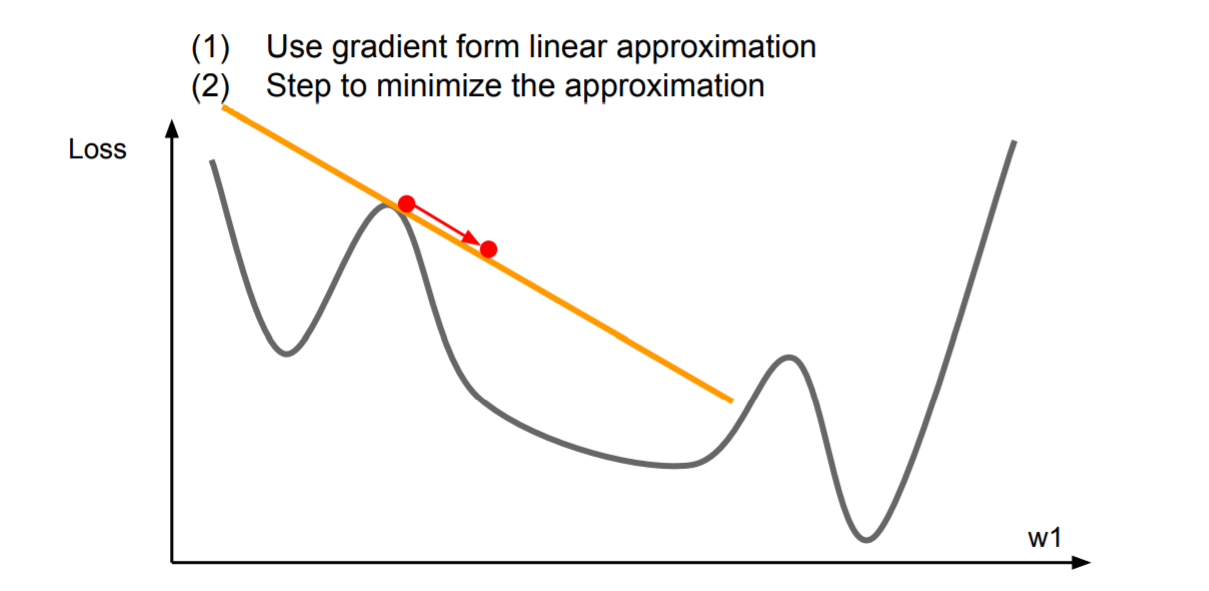
于是考虑二阶逼近,可以一步到达二阶逼近的最小值点:
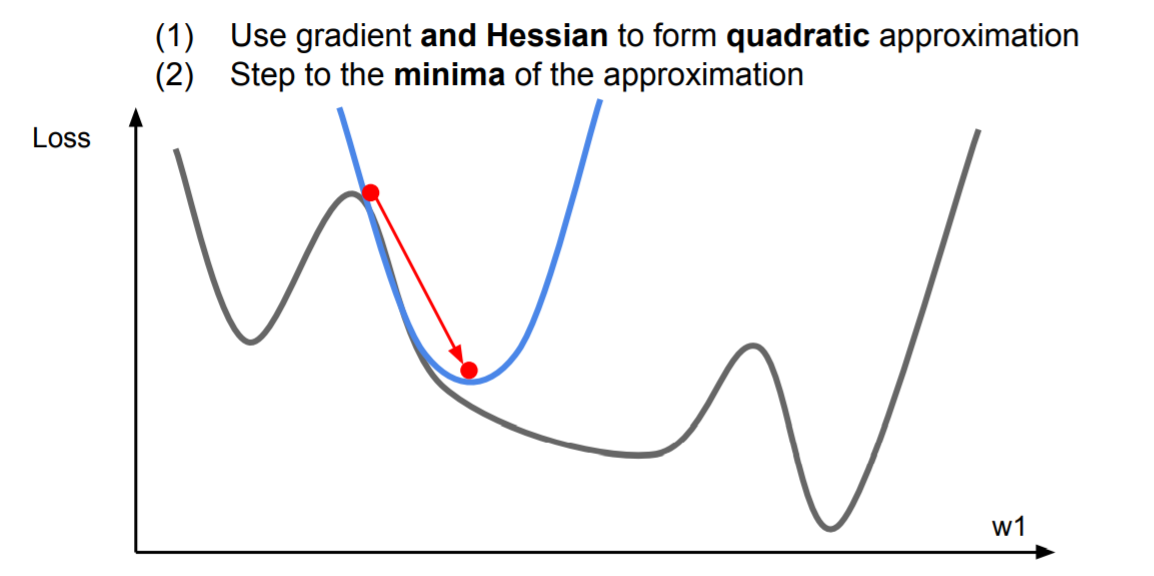
将该思想推广至多维的情况,得到牛顿步长(通过计算海森矩阵,即二阶偏导矩阵,并求逆,可直接到达二阶逼近的最小值点):
x
←
x
−
[
H
f
(
x
)
]
−
1
∇
f
(
x
)
x \leftarrow x - [H f(x)]^{-1} \nabla f(x)
x←x−[Hf(x)]−1∇f(x)
其中
H
f
(
x
)
H f(x)
Hf(x)是海森矩阵(Hessian matrix),大小是
N
×
N
N\times N
N×N,
N
N
N表示网络中参数的数量。
对于大多数深度学习应用程序而言,上述更新是不切实际的,因为进行Hessian的计算(和求逆)在空间和时间上都是非常昂贵的过程。因此,用拟牛顿法代替牛顿法,逼近Hessian的逆而非求该矩阵的逆。其中,最流行的是L-BFGS。
超参数优化(Hyperparameter Optimization)
神经网络中最常见的超参数包括:
- 初始学习率
- 学习率衰减时间表(例如衰减常数)
- 正则化强度(L2罚分,dropout 强度)
执行超参数搜索的一些trick:
- Prefer one validation fold to cross-validation
在大多数情况下,一个适当大小的验证集可以极大地简化代码库,而不需要使用多个fold进行交叉验证。 - Prefer random search to grid search
通常情况下,某些超参数比其他参数重要得多(如图中important parameter和unimportant parameter)。通过执行随机搜索而不是网格搜索,可以更精确地发现good values for the important ones。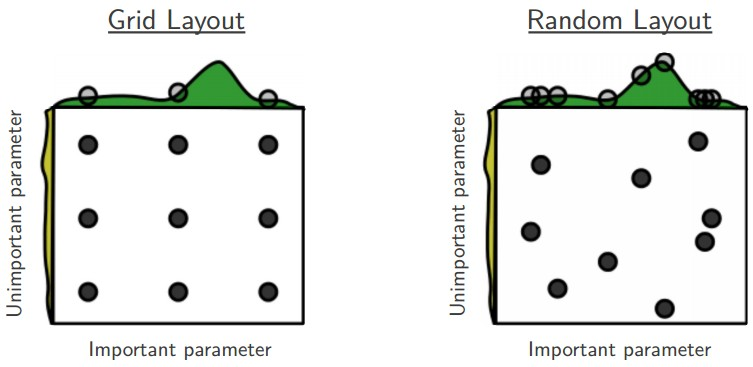
- 将搜索从粗略过渡到精细
实际上,首先在较粗略的范围内搜索(例如10 ** [-6,1]),然后根据出现最佳结果的位置缩小范围。
迁移学习(Transfer Learning)
迁移学习(Transfer Learning)的目标是将从一个环境中学到的知识用来帮助新环境中的学习任务。把已训练好的模型参数迁移到新的模型来帮助新模型训练。考虑到大部分数据或任务都是存在相关性的,所以通过迁移学习我们可以将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型从而加快并优化模型的学习效率不用像大多数网络那样从零学习。
为什么要迁移学习?
- 站在巨人的肩膀上 :前人花很大精力训练出来的模型在大概率上会比你自己从零开始搭的模型要强悍,没有必要重复造轮子。
- 训练成本可以很低 :如果采用导出特征向量的方法进行迁移学习,后期的训练成本非常低,用CPU都完全无压力,没有深度学习机器也可以做。
- 适用于小数据集 :对于数据集本身很小(几千张图片)的情况,从头开始训练具有几千万参数的大型神经网络是不现实的,因为越大的模型对数据量的要求越大,过拟合无法避免。这时候如果还想用上大型神经网络的超强特征提取能力,只能靠迁移学习。
迁移学习的方式
- Transfer Learning :冻结预训练模型的全部卷积层,只训练自己定制的全连接层。
- Extract Feature Vector :先计算出预训练模型的卷积层对所有训练和测试数据的特征向量,然后抛开预训练模型,只训练自己定制的简配版全连接网络。
- Fine-tune(微调) :冻结预训练模型的部分卷积层(通常是靠近输入的多数卷积层),训练剩下的卷积层(通常是靠近输出的部分卷积层)和全连接层。
- 数据集1:数据量少,但数据相似度非常高
在这种情况下,我们所做的只是修改最后几层或最终的softmax图层的输出类别。- 数据集2:数据量少,数据相似度低
在这种情况下,我们可以冻结预训练模型的初始层(比如k层),并再次训练剩余的(n-k)层。由于新数据集的相似度较低,因此根据新数据集对较高层进行重新训练具有重要意义。- 数据集3:数据量大,数据相似度低
在这种情况下,由于我们有一个大的数据集,我们的神经网络训练将会很有效。但是,由于我们的数据与用于训练我们的预训练模型的数据相比有很大不同。使用预训练模型进行的预测不会有效。因此,最好根据你的数据从头开始训练神经网络(Training from scatch)。- 数据集4:数据量大,数据相似度高
这是理想情况。在这种情况下,预训练模型应该是最有效的。使用模型的最好方法是保留模型的体系结构和模型的初始权重。然后,我们可以使用在预先训练的模型中的权重来重新训练该模型。
reference
[1]深度学习不得不会的迁移学习Transfer Learning
[2]深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)















 7201
7201











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









