







【P1】Incorporating External Knowledge through Pre-training for Natural Language to Code Generation
Abstract
开放领域代码生成致力于从自然语言生成通用编程语言(例如Python)。本文探索了将两种外部知识引入NL-to-code生成的有效性:
- 从StackOverflow自动挖掘NL-code对
- 从编程语言API文档自动挖掘NL-code对
The code and resources are available at https://github.com/neulab/external-knowledge-codegen.
1 Introduction
- 语义分析(Semantic parsing)开始应用于通用编程语言的代码生成,之前主要关注有限领域。
- 开放领域代码生成模型准确率不高原因是:现有数据集中可用的人工标注的训练对( training pairs)数量有限,不足以涵盖在代码中实现某些复杂功能的无数方式。
2 Approach
2.1 整体框架
整合外部知识的总体策略是
- 根据从外部资源获得的
NL-code pairs对模型进行预训练(pretraining) - 然后在一个人工标注的小型语料库上微调(fine-tuning)
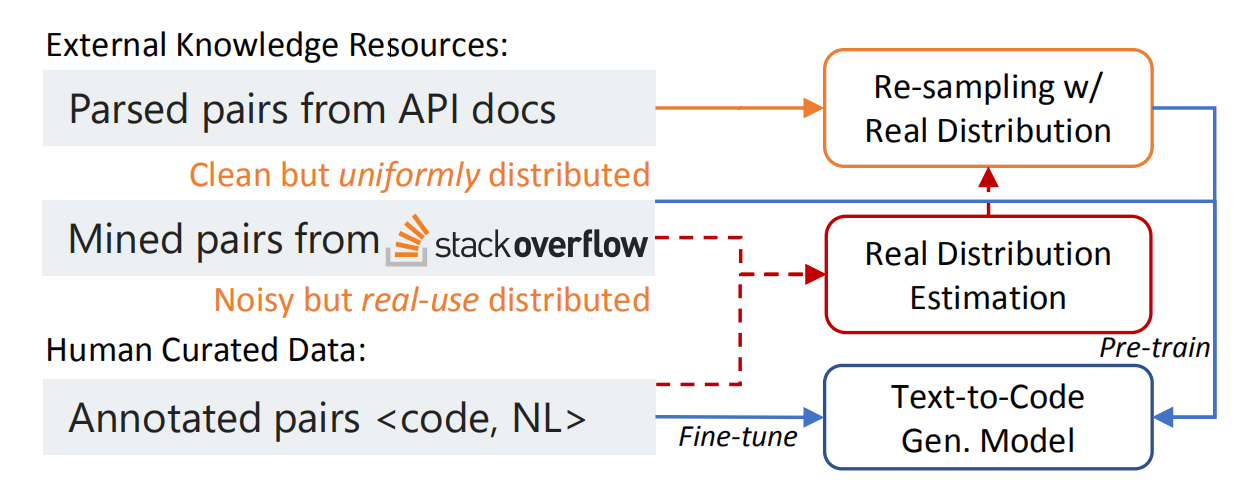
模型可以首先学习大量潜在的嘈杂数据(最终被裁剪成test time建模实际用到的NL和code)。执行预训练,需要将外部数据源转换为NL-code pairs。
2.2 挖掘NL-code pairs
- Yin等人(2018)提出通过训练分类器来判断一个NL-code对是否有效,从而产生一个庞大但有噪声的NL意图和源代码片段(code snippets)并行语料库。
- 该方法所分配的概率可以作为置信度,表示自动挖掘的NL-code对的质量。
2.3 API文档
如下图,将API文档转化为预处理的代码段,包括:
- class constructors(类构造器)
- methods
- top-level functions

其中:
- 红色:必需的位置参数
- 蓝色:可选的位置参数
- 绿色:可选的关键字参数
API文档的处理包括:
- 对可选参数的所有可能组合(有一定的限制)进行排列,并按照正确的语法将它们附加到所需的参数中,来模拟“开发人员通常不提供或只提供其中一些参数”
# e.g.1 如果文档中的code signature是
collections.deque([iterable[,maxlen]])
# 我们将生成所有3种可能的用法:
collections.deque()
collections.deque(iterable)
collections.deque(iterable,maxlen)
# e.g.2 对于关键字参数
“heapq.nlargest(n, iterable, key=None)
# 也将生成:
heapq.nlargest(n, iterable)
- 对于类构造函数和方法,我们基于类名创建一个启发式变量名,以存储实例化的类对象并调用方法。如:
# 对于类初始化器:
d = collections.deque(iterable) # 用小写变量名构造赋值语句,使用类名的第一个字符来存储实例化的类
#对于类方法:
d.append(x) # 在方法调用前添加一个启发式创建的变量名,以模拟实例化类上的实际方法调用
-
为了对创建的每个代码片段进行简洁的描述,只在相应的文档中保留:
(1) 第一个句子:它通常描述API的功能
(2) 对代码片段中出现的每个参数,包含通过字符串匹配提到该参数的第一句话 -
在原始描述中没有找到参数情况下,则将包含这些参数的另一个句子添加到NL片段的末尾,以确保NL覆盖代码中的所有变量。
2.4 Re-sampling API Knowledge
重采样的原因:不同来源的外部知识具有不同的特征。在预训练和微调之间的分布变化会导致性能下降。
例如:
API文档中关于library curses的条目显著多于关于json的(178 vs. 17),而在实际中json被更频繁地询问和使用。
本文提出了一种基于检索的重新采样方法,来缩小API文档和我们想要建模的实际的NL-code对之间的差距。
Re-sampling算法:
对实际使用分布( D a n n D_{ann} Dann[human annotated data]和 D m i n e D_{mine} Dmine[mined data]——他们都是由真实用户产生的)中的每个样本,我们在 D A P I D_{API} DAPI(从API文档中获得的对集合)中检索 k k k个NL-code pairs,并对检索到的每一对 y ∈ D A P I y\in D_{API} y∈DAPI 的频率相加求和: freq ( y ) = ∑ x ∈ D ann+mined δ ( y ∈ R ( x , D A P I , k ) ) \operatorname{freq}(y)=\sum_{x \in \mathcal{D}_{\text {ann+mined }}} \delta\left(y \in R\left(x, \mathcal{D}_{\mathrm{API}}, k\right)\right) freq(y)=x∈Dann+mined ∑δ(y∈R(x,DAPI,k))其中,
- R ( x , D A P I , k ) R(x, D_{API}, k) R(x,DAPI,k):给定 x x x,根据NL意图或代码片段从 D A P I D_{API} DAPI中检索最相似的 k k k个样本。
- δ ( ⋅ ) \delta(·) δ(⋅):Kronecker函数,如果内部条件为真,返回1,否则返回0。
使用BM25检索算法。取上述频率计算平滑后(temperature τ ∈ [1, ∞])的概率分布:
P ( y ) = freq ( y ) 1 / τ / ∑ y ′ ∈ D A P I freq ( y ′ ) 1 / τ P(y)=\operatorname{freq}(y)^{1 / \tau} / \sum_{y^{\prime} \in \mathcal{D}_{\mathrm{API}}} \operatorname{freq}\left(y^{\prime}\right)^{1 / \tau} P(y)=freq(y)1/τ/y′∈DAPI∑freq(y′)1/τ当 τ \tau τ由1变为 ∞ \infty ∞时, P ( y ) P(y) P(y)从与频率成比例的分布变为均匀分布。使用该分布,可以从API文档中抽取出更可能被广泛使用的API调用的NL-code对。
3 Experiments
3.1 Settings
- Dataset and Metric:CoNaLa
- Mined Pairs:使用CoNaLa-Mined数据集,在Python中,它有600K个NL-code对(从StackOverflow自动挖掘出来的),并根据置信度分数取top 100K对。
- API Documentation Pairs:从Python API文档中创建约13K个不同的NL-code对,并为re-sampling设置抽样相同数量的对。
- Methods:选择目前最先进的NL-to-code生成模型TranX,并加入长度归一化(防止定向搜索倾向于更短而不是更长的结果)
- Man:只在CoNaLa上训练
- Man+Mine指:首先对挖掘的数据进行预训练,然后在CoNaLa上微调
- Man+Mine+API:结合了挖掘数据和API文档用于预训练
- dist:基于分布的方法
- direct:从API文档中直接检索前5个NL-code pairs
- Implementation Details:
3.2 Results
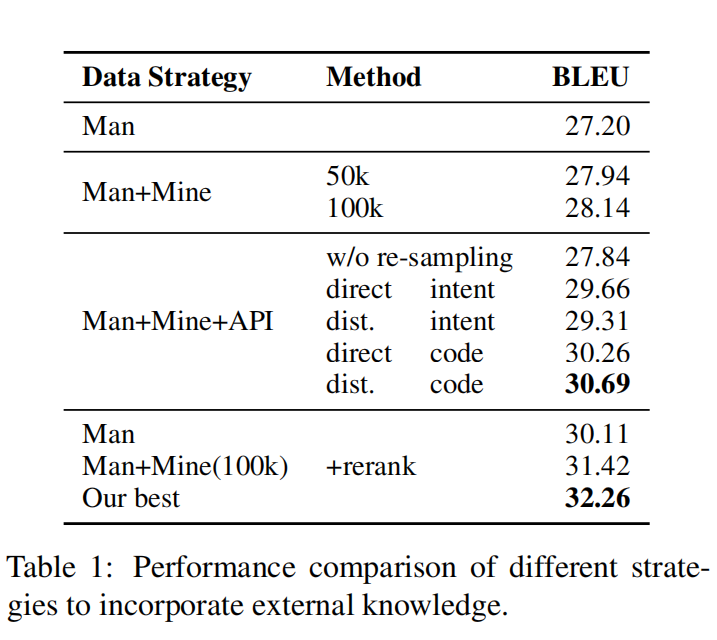
结论:
- 预训练中加入更多的嘈杂的mined data(更大的训练集覆盖率增加)有微小性能提升
- API文档的训练预训练没有重采样会导致性能下降
- 在Man+Mine+API的策略中,以code snippet为检索目标且采用dist.重采样策略的方法效果最好(BLEU 30.69)。原因:
- 使用 code snippets来检索pairs的性能更好,因为它使生成目标(code snippet)更类似于真实的分布,从而更好地训练解码器。
- API描述与开发人员提出的问题本质不同的(他们有更多冗长的措辞),导致意图检索不准确。
- 引入外部知识的策略所带来的改进与假设重新排序( hypothesis reranking)所带来的改进大多是正交的。
3.3 Case Study 案例研究

相比baseline,改进主要有两点:
- 更好的API参数位置
- 更好的选择调用哪个API用于特定的意图
4 Conclusion and Future Work
本文提出了一种基于数据扩充、检索和数据重采样的模型不确定方法,将外部知识纳入代码生成模型中,在CoNaLa开放域代码生成任务中取得了最先进的结果。
将我们的重抽样过程推广到零样本学习(zero-shot)场景也很有用。















 394
394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









