









Mention Extraction and Linking for SQL Query Generation
Abstract
在 WikiSQL benchmark 上,最先进的 text-to-SQL 系统通常采取槽位填充(slot-fifilling)的方式,为每种类型的槽位建立多个专用模型。这样的模块化系统不仅复杂,而且对于捕捉 SQL 子句之间的相互依赖关系的能力也有限。
本文提出extraction-linking方法,即:
- 先由统一的提取器(extractor)识别问题句中出现的所有类型的槽位提及(slot mentions);
- 再由链接器(linker)将识别到的列(columns)映射到 table schema 中,生成可执行的 SQL 查询。
通过自动生成的注释进行训练,所提出的方法在 WikiSQL 基准测试中取得了第一名的成绩。
1 Introduction
在 WikiSQL 多域单表 text-to-SQL 的基准上,最先进的系统可以正确预测整个 SQL 查询的80%以上。这类系统大多采取基于草图的方法,构建了几个专门的模块,每个模块都致力于预测特定类型的槽位,如 SELECT 中的列或 WHERE 中的过滤器值。
缺点:
- 这种专门的模块很复杂;
- 往往不能捕捉到 SQL 子句之间的相互依赖关系等贡献。 因为每种类型的槽点都是单独建模的。
为了处理这些缺点,本文将 text-to-SQL 以序列标签的方式表述为 extraction 和 linking 问题。在这种新的表述中,合成 SQL 的关键是提取 SQL slot 的 mention 以及它们之间的关系。

考虑例(1)中的问题及其对应的 SQL 查询,schema 中的 headers 为 {LANE, NAME, NATIONALITY, SPLIT (50M), TIME} 。
SQL的 elements 或 slots,如:
- column names of SPLIT (50M) and LANE
- values like “Josefifin Lillhage” and 8
- operators >
都是用形式(form)或意义(meaning)相似的词来 mention 的。此外,slot mentions 之间的关系,如 <lanes,above,8> 形成过滤条件,通过“线性顺序的接近性”或“其他语言提示”来表示。
为此,我们:
- 利用一个统一的基于 BERT 的提取器,从自然语言问题中识别 slot mentions 以及它们的关系;
- 提取器的输出可以被确定地翻译成伪 SQL,然后基于BERT的链接器将 column mentions 映射到 table headers 以获得可执行的SQL查询。所提出的方法面临的一个主要挑战是缺乏对 mention 和 relation 的手动标注。
- 提出了一种基于将 SQL 中的标记与对应的问题对齐的自动标注方法。此外,初步结果表明,预测聚合函数(AGG)限制了模型的性能,这促使我们提出 AGG 预测增强(AE)方法。
2 Method
2.1 Extractor
提取器可以识别:
- slot mentions:包括带有聚合函数的 SELECT 列、带有相应 values 和 operators 的 WHERE 列;
- slot relations:即把每个 WHERE 列与其 operators 和 values 关联起来。

如图1(a),大部分的 SQL slots 会在问题中提到。
至于 slot relations,要注意构成过滤条件关系的 column, value, operator 在问题中通常是以相邻关系出现的。因此,关系的提取相当于对相应text span的标注。如图1(b)所示, mentions 和 relations 的提取可以通过用一组BIO标签标记问题中的每个 token 来表示。
BIO标签:B-begin,I-inside,O-outside
对于我们的任务,定义了两组标签:slot mentions 和 slot relations 的识别都被表述为序列标签。
- 代表 slot mentions 的 SQL role labels
- 代表 slot relations 的 SQL span labels
Model:
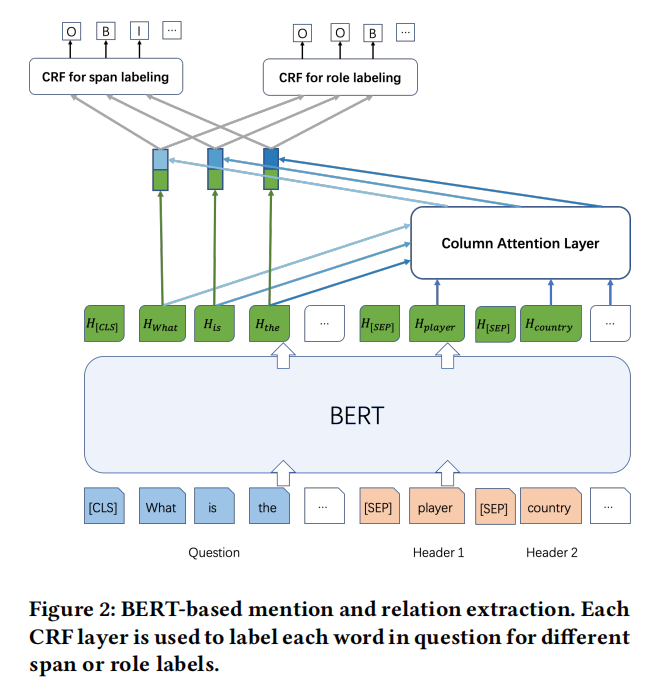
首先对问题(question text)和表头(table headers)进行 encode。采用 BERT(在序列标签标注任务上性能好)来获得 role 和 span 标签的上下文化表示。类似于 SQLova,我们将问题文本与表头连在一起作为 BERT 的输入,形式为
q
1
,
q
2
,
.
.
.
,
q
L
,
[
S
E
P
]
,
c
1
,
1
,
c
1
,
2
,
.
.
.
,
[
S
E
P
]
,
c
2
,
1
,
.
.
.
,
c
M
,
1
.
.
.
q_1,q_2,...,q_L,[SEP],c_{1,1},c_{1,2},...,[SEP],c_{2,1},...,c_{M,1}...
q1,q2,...,qL,[SEP],c1,1,c1,2,...,[SEP],c2,1,...,cM,1...
其中
Q
(
∣
Q
∣
=
L
)
Q (|Q| = L)
Q(∣Q∣=L) 是问题,而
C
=
c
1
,
.
.
,
c
M
(
∣
C
∣
=
M
)
C = c_1, .., c_M (|C| = M)
C=c1,..,cM(∣C∣=M) 是表头。每个表头
c
i
c_i
ci 可能有多个 token,因此使用二维指标
c
i
,
j
c_{i,j}
ci,j。
由于 labeling 是针对问题句的,所以条件随机场(CRF)层只应用于问题段(question segment)。完整的模型描述如式:

- question 和 headers 的 BERT 表征
- 经过注意力层,将 question 的 token 与 schema 中的 columns 进行编码。所得的表征以元素化的方式添加到原始 token 表征中。
- 最后,将得到的 token 表征反馈给 CRF 层,从而得到标签序列。
由于两个 labeling tasks 可以相互受益,我们以多任务学习的方式对 BERT 进行微调。
2.2 Schema Linking as Matching
问题句中提到的列名往往与 table schema 中的规范列名在字符串形式上有所不同,如图1所示,其中:
- 显式 mention:header “SPLIT(50M)”由问题中的 50m splits 提到
- 隐式 mention:header “NAME” 则完全没有提到,问题中只出现了列的值 Josefin Lillhage
为了将 mention 和 relation 提取结果转换为 SQL,我们需要一个 schema linking 模块,将显式和隐式的 column mentions 与 table schema 中的规范 column names 进行链接。
形式上,我们将 linker 定义为文本匹配( text matching )模型,即估计一个函数
f
(
[
C
i
;
s
p
a
n
;
Q
]
)
→
{
0
,
1
}
f([Ci; span; Q]) → \{0, 1\}
f([Ci;span;Q])→{0,1}其中
C
i
C_i
Ci 是表中的 header,span 是提取的 column mention(链接显式)或提取的 value
v
v
v(链接隐式)。
用 [ S ] [S] [S] 和 [ W ] [W] [W] 的特殊标记来区分 SELECT span 和 FILTER span。
- SELECT span:selection relations(在SELECT子句),包括agg、column
- FILTER span:filter relations(在WHERE子句),包括column、operator、value
同样,BERT 被用作底层模型,因为它在文本匹配上的最先进性能。匹配过程可以描述为式(2):

其中的span归为3类:
- question;[S];total sum of 50m splits;
- question;[W];lanes above 8;
- question;[W];[EMPTY];Josefin Lillhage;
2.3 AGG prediction enhancement(增强聚合函数预测)
聚合函数(AGG)预测是我们系统的瓶颈,原因:
- WikiSQL 中的 AGG 注释有高达10%的错误。在这种情况下,由于 extractor 模型必须处理其他类型的 slot,与大多数 SOTA 方法中专用的 AGG 分类器相比,这些额外的约束使得我们的模型更难以匹配有缺陷的数据——数据的特点
- 不是所有聚合函数都以特定的 token 为基础——基于信息提取的模型的局限性
为此,我们采用基于转换( transformation-based)的学习算法,即基于关联规则更新AGG预测,形式为:“change AGG from 𝑥 to 𝑥 ′, given certain word tuple occurrences."。这样的规则由算法从 training data 中挖掘并排序。
例子:https://wenku.baidu.com/view/5560fed0182e453610661ed9ad51f01dc3815768.html
2.4 Automatic Annotation via Alignment
训练extractor的一个挑战是,基准数据集(benchmark datasets)没有 role 和 span 注释。由于手动注释的成本很高,我们采用自动方式。我们的想法是通过将 query 中的 SQL slots 与 question 中的 tokens 对齐来注释提及。图1用箭头和颜色描述了这种对齐方式。具体分两步:
- 对齐(Alignment) x 2:
- alignment 1:对两个 token 列表(Question 和 SQL)的小写版本进行精确的字符串匹配,它将匹配 josefin lillhage、Split、50m等。
- alignment 2:利用 training set 训练一个统计对齐器,对剩余的 SQL slots 进行对齐。选择 Berkeley 对齐器,它的工作原理是估计平行语料库(question-SQL pairs)中 tokens 的共现度。
由于SELECT、WHERE和AND等关键字在自然语言中表达的是SQL语法而非语义,可能会引入噪声,我们将它们从SQL查询中删除,但会跟踪它们的位置。至于聚合函数和运算符,我们使用特殊的标记来表示它们。将这样的转换应用于(a)将产生(b)。那么任务就是将(b)与自然语言问题(c)对齐。校准器的输出如(d)所示,其中 i − j i-j i−j 表示转换后的SQL中的 i T H i_{TH} iTH token(索引从0开始)与自然语言问题中的 j T H j_{TH} jTH token 对齐。例如,0-3 和 0-4 表示 AGG4 与 total sum 对齐,而 10-13 表示第二个运算符 OP1 与 above 对齐。我们看到,统计对齐器在对齐运算符和聚合函数方面做得很好。事实上,对齐器也可以很好地对齐一些常见的别名和许多通过字符串匹配无法找到的语义相似词。统计对齐器偶尔会对一些SQL中的少数token产生空对齐,我们使用另一种基于无监督的词和语义相似性的算法来补充缺失的对齐(https://zhuanlan.zhihu.com/p/126110850)。

- 标签生成(label generation):根据已对齐元素来生成 roles,而 span label 则通过考虑最小文本跨度(minimal text span)来分配,该 span 覆盖了 SELECT/WHERE 子句中的所有元素。
3 Experiment
-
数据集:WikiSQL——由80654对问题和人类验证的 SQL 查询组成。在训练集或验证集中的表永远不会出现在测试集中。
WikiSQL数据形式:https://www.jianshu.com/p/ab5b4e7e438c -
评价指标:
- Logical Form Accuracy (LF),其中 LF = 逻辑形式正确的SQL查询数量 / SQL查询总数
- Execution Accuracy (EX),其中 EX = 执行正确的SQL查询数量 / SQL查询总数
-
采用 Execution guidance decoding (EG) ——前人的工作
-
实现细节:
- 使用 StanfordNLP 进行 tokenization。
- word embeddings 由 BERT 随机初始化,并在训练过程中进行微调。
- 使用 Adam 优化模型,使用默认的超参数。
- 由于资源的限制,选择了 uncased BERT-base 预训练模型,并采用默认设置。
代码在 Pytorch 1.3 中实现,并将公开发布:https://github.com/nl2sql/IE-SQL
3.1 Results
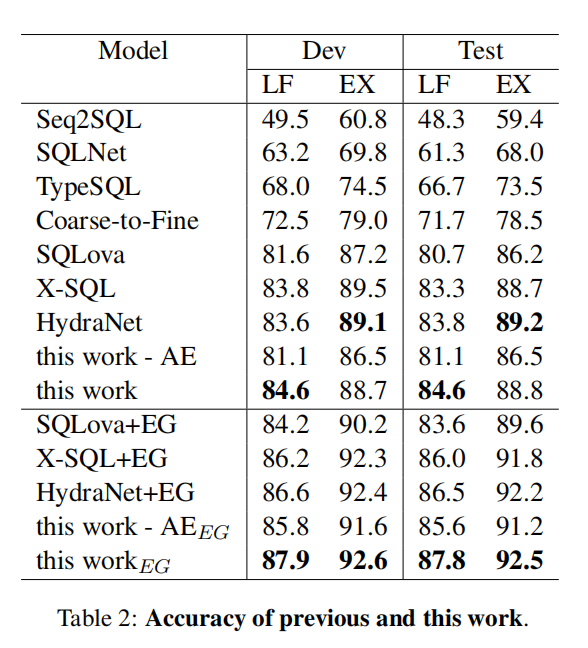
我们将我们的方法与已经在 WikiSQL 任务上报告结果的著名模型进行比较,包括 Seq2SQL、SQLNet、TypeSQL、Coarseto-Fine、SQLova、X-SQL 和 HydraNet,见表2。
-
在没有EG的情况下,我们的 BERT-base 方法优于大多数现有方法。
-
在有EG的情况下,我们的方法优于所有现有的方法。
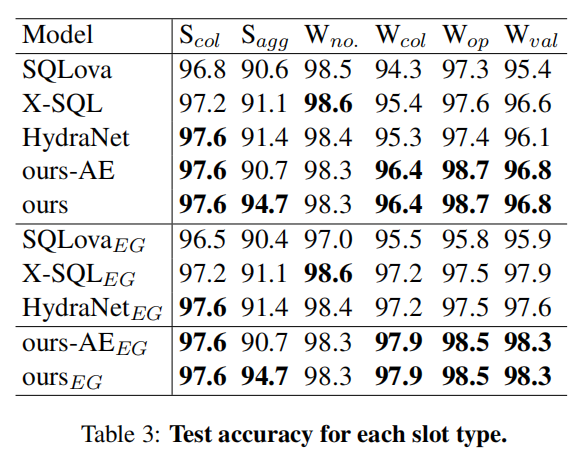
表三显示了 slot type 方面的结果,我们的方法在 Wcol、Wval 和 Wop 的准确度上取得了新的先进结果:
-
由于 operators 和 values 是直接从提取器中得到的,这样的结果证明了我们基于提取的方法的有效性。
-
我们通过 AE 仅使用词的共现特征提高了 AGG 预测精度,也使得整体 SQL 结果达到了新的标准。
-
我们基于序列标注(sequence labeling)的方法的一个局限性是它在一些具有嵌套跨度结构的问题上表现一般,如问题When does the train [arriving at [Bourne]DEST at 11.45]TIME departure? 由于序列标注捕捉的是本质上的平面结构,所以这种情况提出了类似于嵌套NER中情况的挑战。
评估注释质量:
自动标注的质量可以在 oracle extractor 的环境下进行评估,即自动标注的标签而非 extractor 的预测被反馈给 linker。在这种环境下,验证集上的 LF 和 EX 准确率分别达到 92.8% 和 94.2%,高于人类水平精度,说明自动标注的质量相当不错。
4 Related Work
语义解析(Semantic parsing)是将自然语言语句映射到机器可解释的表示形式(如逻辑形式、程序代码和SQL查询)。文本到SQL是语义解析的一个子领域,近年来被广泛研究。
-
早期的工作遵循神经 sequence-to-sequence 范式与注意力机制。Pointer networks 也被普遍采用。这些序列到序列的方法往往存在排序问题,因为它们是为了适应有序序列而设计的,而 WHERE 子句中的条件在本质上是无序的。
-
SQLNet引入了基于草图(sketch)的方法,将SQL合成分解为多个独立的分类子任务,包括 select-aggregation/column 和 where-number/column/operator/value。除了 where-value 通常由 pointer network 预测外,其他子任务都使用自己的专用分类器进行预测。这些基于草图的模型在训练、部署和维护方面提出了挑战。此外,每个子模块解决自己的分类问题,而不考虑与其他子模块建模的SQL元素的依赖关系。最近的进展遵循这种方法,并在 WikiSQL 上取得了比较好的结果,主要是通过使用预先训练的语言模型作为编码器。
-
虽然序列标注方法也是基于预训练的语言模型,但它与最先进的方法不同的是,它明确地从问题中提取 mentions,并且可以从提取的mentions之间的相互依赖性建模中获益。在 question 中,value、operator 和对应 columns 的 mentions 经常以近似的方式出现,因此序列标注模型可以更好地捕捉它们的依赖关系,有利于对它们的识别。此外,我们的 extractor-linker 架构也比基于草图的方法简单得多。
-
最近学术界的趋势开始转向 text-to-SQL 的多表和复杂查询设置,如Spider任务。Spider 上的现状方法通常分为两类:基于语法的方法和基于草图的方法。后者有类似于 WikiSQL 的 SQLNet 的槽位预测模块,同时引入递归模块来处理复杂 SQL 草图的生成,这是 Spider 中的特点,但 WikiSQL 中没有。在高层次上,我们的方法与 SQLNet-RYANSQL 的思路相同,但又与它们不同,因为我们的方法以统一的方式提取 slot,而不是使用专门的模块来预测每个 slot 类型。我们可以将我们的方法扩展到 Spider 任务中,按照 RYANSQL 中现有的草图构造方法,同时用我们的 extractor-linker 方法替换它们的 slot classifification 模块。
5 Conclusion and Future Work
由于简单、统一的 mention 和 relation 提取模型,以及其捕捉 mention 间依赖关系的能力,所提出的方法被证明是一种很有前途的 text-to-SQL 任务的方法。
目前的自动生成的注释仍然是嘈杂的,需要进一步改善自动注释程序。我们还计划扩展我们的方法,以应对 multitable table text-to-SQL 任务 Spider。
SQL的补充知识
RDBMS 术语
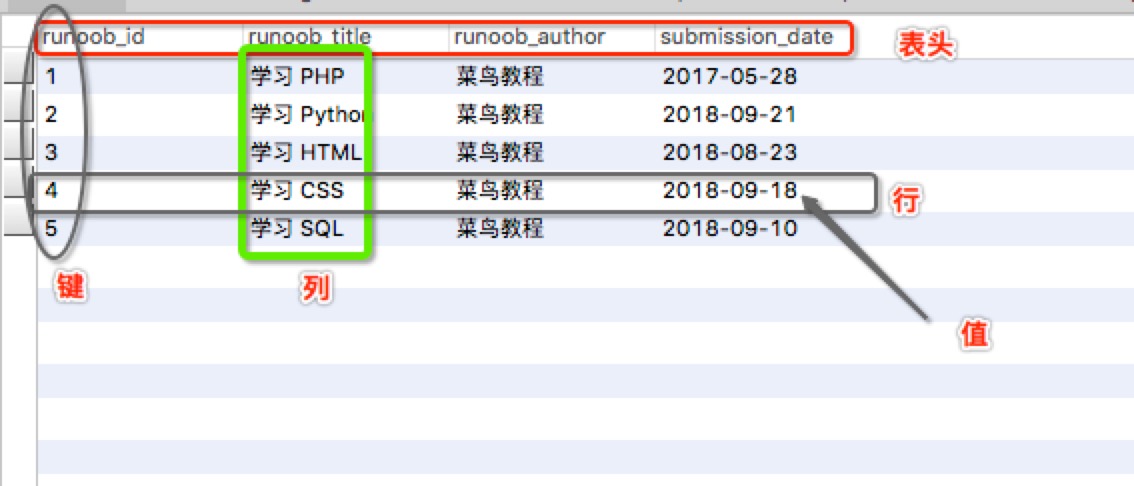
- 数据库(schema/database):数据库是一些关联表的集合。
- 数据表(table):表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。
- 表头(header):每一列的名称;
- 列(col): 具有相同数据类型的数据的集合;
- 行(row): 每一行用来描述某条记录的具体信息;
- 值(value): 行的具体信息, 每个值必须与该列的数据类型相同;
- 键(key): 键的值在当前列中具有唯一性。
AGG(聚合函数)
SQL Aggregate 函数计算从列中取得的值,返回一个单一的值。
有用的 Aggregate 函数:
- AVG() - 返回平均值
- COUNT() - 返回行数
- FIRST() - 返回第一个记录的值
- LAST() - 返回最后一个记录的值
- MAX() - 返回最大值
- MIN() - 返回最小值
- SUM() - 返回总和















 335
335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









