







论文原文:https://arxiv.org/pdf/1912.05656.pdf
自己也翻译了一下,方便之后看呀:https://blog.csdn.net/qq_42366123/article/details/108122664
目录
(2)运动判别器 Motion Discriminator.
一、介绍
1、之前的方法与局限性
方法
- 将室内3D数据集与具有2D地面真实或伪地面真实关键点标注的视频相结合;
局限性
- 室内三维数据集在对象数量、运动范围和图像复杂度方面受到限制;
- 用地面真实二维姿态标记的视频量仍然不足以训练深层网络;
- 伪地面真实二维标签对于三维人体运动建模不可靠。
2、现有方法的问题
- 缺乏带标注的3D人体姿态和形态估计的数据集
- 现有的方法不够完善,无法捕获到人类实际运动的复杂性和可变性,以及准确又自然的运动序列;预测的形态不够逼真,在运动学上不够合理。
3、解决方法
- 利用大规模3D运动捕捉数据集(AMASS)训练基于视频的人体姿态和形态的GAN(基于序列的生成对抗网络)模型。
4、创新点
- 对抗性学习框架;
- 利用AMASS数据集进行VIBE的对抗训练,来区分真实的人体运动和由本文的时间姿势和形状回归网络产生的运动,这鼓励回归器产生逼真和精确的运动。
二、需要了解的一些相关知识
1、生成对抗网络GANs
参考文章
https://zhuanlan.zhihu.com/p/42029261
https://zhuanlan.zhihu.com/p/24989446
2014年,arXiv上面刊载了一篇关于生成对抗网络的文章,名为《Generative Adversarial Nets》,作者是深度学习领域的大牛Ian J. Goodfellow. 该文提出了一种估计生成模型的新框架:同时训练两个模型,分别为用于捕获数据分布的生成模型  和用于判别数据是真实数据还是生成数据(伪数据)的判别模型
和用于判别数据是真实数据还是生成数据(伪数据)的判别模型  .
.
GAN 启发自博弈论中的二人零和博弈(two-player game),GAN 模型中的两位博弈方分别由生成式模型(generative model)和判别式模型(discriminative model)充当。给定一些无标签的样本数据,生成模型 G 捕捉样本数据的分布,用服从某一分布(均匀分布,高斯分布等)的噪声 z 生成一个类似真实训练数据的样本,追求效果是越像真实样本越好;判别模型 D 是一个二分类器,估计一个样本来自于训练数据(而非生成数据)的概率,如果样本来自于真实的训练数据,D 输出大概率,否则,D 输出小概率。可以做如下类比:生成网络 G 好比假币制造团伙,专门制造假币,判别网络 D 好比警察,专门检测使用的货币是真币还是假币,G 的目标是想方设法生成和真币一样的货币,使得 D 判别不出来,D 的目标是想方设法检测出来 G 生成的假币。
在训练的过程中固定一方,更新另一方的网络权重,交替迭代,在这个过程中,双方都极力优化自己的网络,从而形成竞争对抗,直到双方达到一个动态的平衡(纳什均衡),此时生成模型 G 恢复了训练数据的分布(造出了和真实数据一模一样的样本),判别模型再也判别不出来结果,准确率为 50%,约等于乱猜。公式如下:
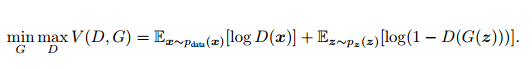
当固定生成网络 G 的时候,对于判别网络 D 的优化,可以这样理解:输入来自于真实数据,D 优化网络结构使自己输出 1,输入来自于生成数据,D 优化网络结构使自己输出 0;当固定判别网络 D 的时候,G 优化自己的网络使自己输出尽可能和真实数据一样的样本,并且使得生成的样本经过 D 的判别之后,D 输出高概率。
2、人体模型SMPL
参考文章
https://www.jianshu.com/p/24a35377ef3e
SMPL(Skinned Multi-Person Linear)人体模型是德国马普所的研究人员提出的一种骨架驱动的参数化人体模型,可以进行任意的人体建模和动画驱动。
SMPL人体模型是一个从大量人体数据中学习得到的基于顶点的加性人体模型,其包含N=6980个顶点,13776个三角面片,并包括一个拥有K=24个关节点的人体骨架,通过骨架可以驱动模型做出各种人体姿态。
SMPL采集不同姿势的真实人体网格,要建立形状参数(shape)、姿势参数(pose)和网格(mesh)之间的对应关系,输入是posture,输出是mesh。
3、VAE
参考文章
https://blog.csdn.net/antkillerfarm/article/details/80648805
变分自编码器(Variational Auto-Encoder,VAE)是Autoencoder的一种扩展。
通常我们会拿VAE跟GAN比较,都属于深度学习的生成模型,它们两个的目标基本是一致的——希望构建一个从隐变量Z生成目标数据X的模型,但是实现上有所不同。具体的讲解参考引用中的文章。
4、MLP
参考文章
https://blog.csdn.net/u010165147/article/details/82851717
当CNN卷积核大小与输入大小相同时其计算过程等价于MLP,也就是说MLP等价于卷积核大小与每层输入大小相同的CNN(如输入图片为100x100,卷积核大小为100x100),所以MLP是CNN的一个特例。
三、本文方法
1、VIBE总体框架
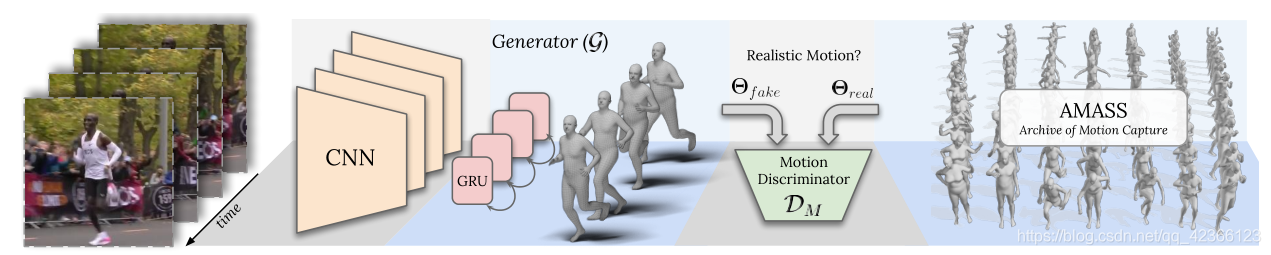
VIBE流程:
- 输入视频:
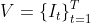 ,长度为T,单人视频;
,长度为T,单人视频; - 提取特征:使用预先训练好的CNN提取每一帧
 的特征,这里CNN网络用
的特征,这里CNN网络用  表示,为每个帧
表示,为每个帧 输出一个向量
输出一个向量;
- 时间编码器输出每帧姿势和形状参数:训练一个由双向门控递归单元(GRU)组成的时间编码器(用作生成器generator)。将特征提取后的输出
 产生潜在特征向量
产生潜在特征向量 。,然后,我们将作为具有迭代反馈的T回归器的输入,并在每次迭代k中将当前参数
。,然后,我们将作为具有迭代反馈的T回归器的输入,并在每次迭代k中将当前参数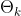 与特征一起作为输入,在每个帧中输出相应的姿势和形状参数;也就是输出包含过去和未来帧的信息的潜在变量。
与特征一起作为输入,在每个帧中输出相应的姿势和形状参数;也就是输出包含过去和未来帧的信息的潜在变量。 - SMPL人体模型:利用GRU输出的信息,对每一时刻的SMPL人体模型参数进行回归,估计姿态和形状(用到SMPL参数回归器),输出一个定常的三维网格(这里理解为输出三维的人体模型);
- 2-4步描述的模型称为时间生成器
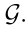 ,输出
,输出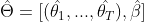 ,
,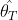 是时间点t的姿态参数,
是时间点t的姿态参数, 是序列的单一体型预测。输出也可以理解为GAN对抗网络中的生成数据;
是序列的单一体型预测。输出也可以理解为GAN对抗网络中的生成数据; - 将Generator(g)的输出
 和来自AMASS的样本输出
和来自AMASS的样本输出 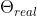 一起赋予运动判别器
一起赋予运动判别器(motion discriminator),用于判断真假样本。
2、时间编码器
使用循环体系结构的一个原因是:未来帧可以从过去的视频姿态信息中受益,当一个人的姿势不明确或身体在给定的框架中被部分遮挡时,尤其有用。
总体而言,当时间编码器可用时,其损失由2D(x)、3D(X)、pose(θ)和shape(β)损失组成。这与对抗性损失相结合。具体而言,g的总损失为:
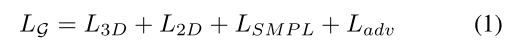
其中每项计算如下:
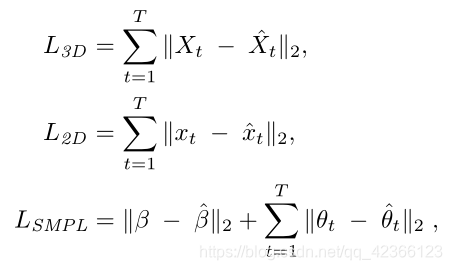
其中 是下文解释的对抗性损失。
是下文解释的对抗性损失。
3、运动判别器
单图像约束不足以说明姿势序列。当忽略运动的时间连续性时,多个不正确的姿势可能会被视为有效。因此为了减轻这种情况,使用运动判别器来判断生成的姿势序列是否对应于现实序列。
(1)运动判别器的结构
- GRU模型估计潜在特征
 :生成器的输出
:生成器的输出  作为输入提供给Figure 3所示的多层GRU模型
作为输入提供给Figure 3所示的多层GRU模型;这个模型在
 的每个时间步长
的每个时间步长  估计潜在编码 ;
估计潜在编码 ; - 使用 self attention,聚合隐藏状态
![[h_{i},...,h_{T}]](https://i-blog.csdnimg.cn/blog_migrate/dab2b82f0b379799d36f242c5bcc5993.gif) :权值
:权值  由线性MLP层
由线性MLP层  学习得到,
学习得到,  是隐藏状态的组合(需要注意的是,代表每帧隐藏状态的特征 被平均化并最大化,然后,将这两种表示形式
是隐藏状态的组合(需要注意的是,代表每帧隐藏状态的特征 被平均化并最大化,然后,将这两种表示形式 和
连接起来,构成最终的静态向量
,用于 - softmax规范化,形成概率分布,真假决策:线性层预测一个值
![\in [0,1]](https://i-blog.csdnimg.cn/blog_migrate/be3c325162804932022a6a29741487a7.gif) ,该值表示
,该值表示 属于合理的人类运动集合的概率。
属于合理的人类运动集合的概率。
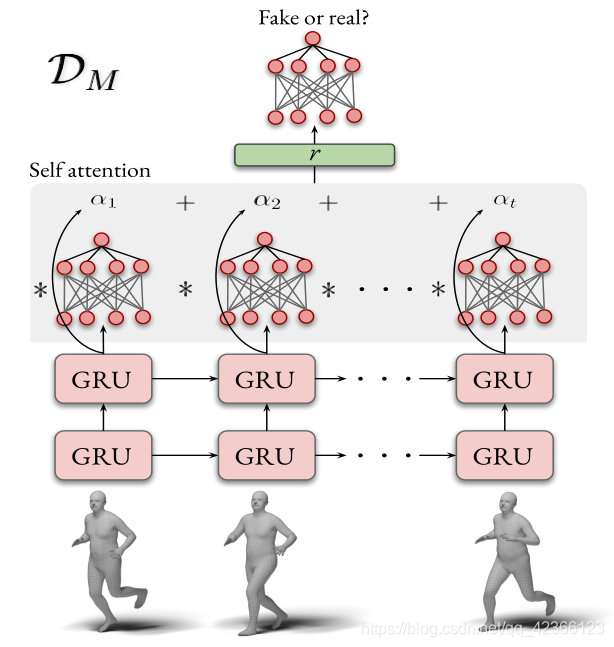
Figure 3:运动判别器.
(2)反向传播到g的对抗损失
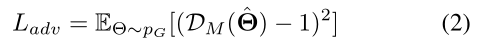
(3)运动判别器的目标
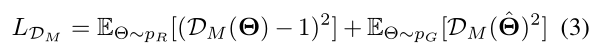
其中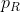 是来自AMASS数据集的真实运动序列,而
是来自AMASS数据集的真实运动序列,而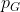 是生成的运动序列。
是生成的运动序列。
4、网络结构详细介绍
(1)姿势生成器 Pose Generator.
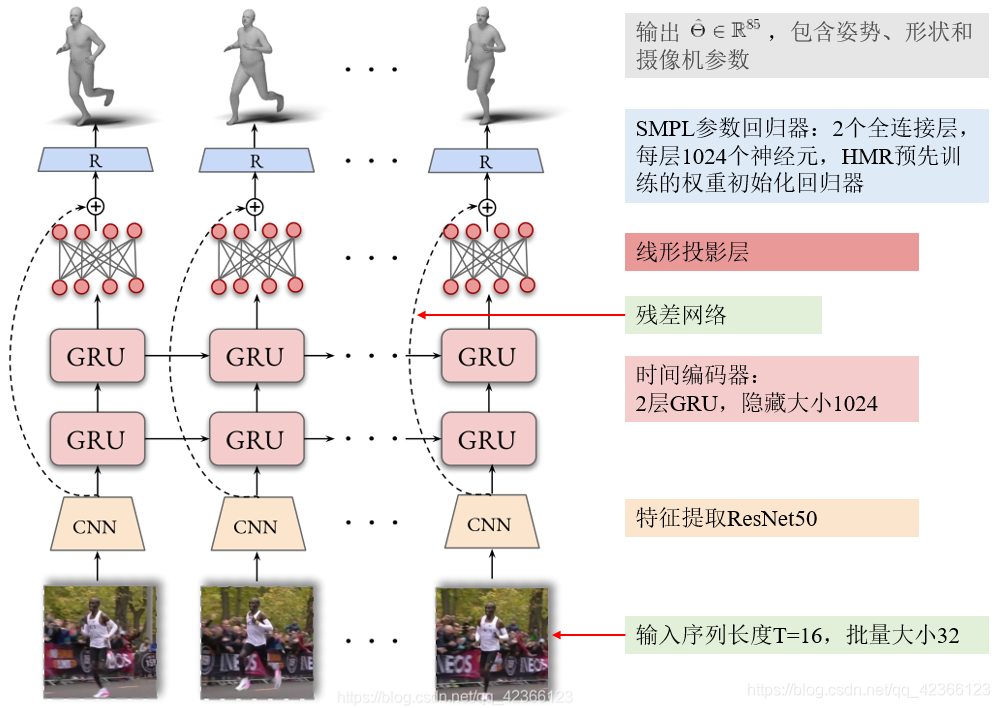
(2)运动判别器 Motion Discriminator.
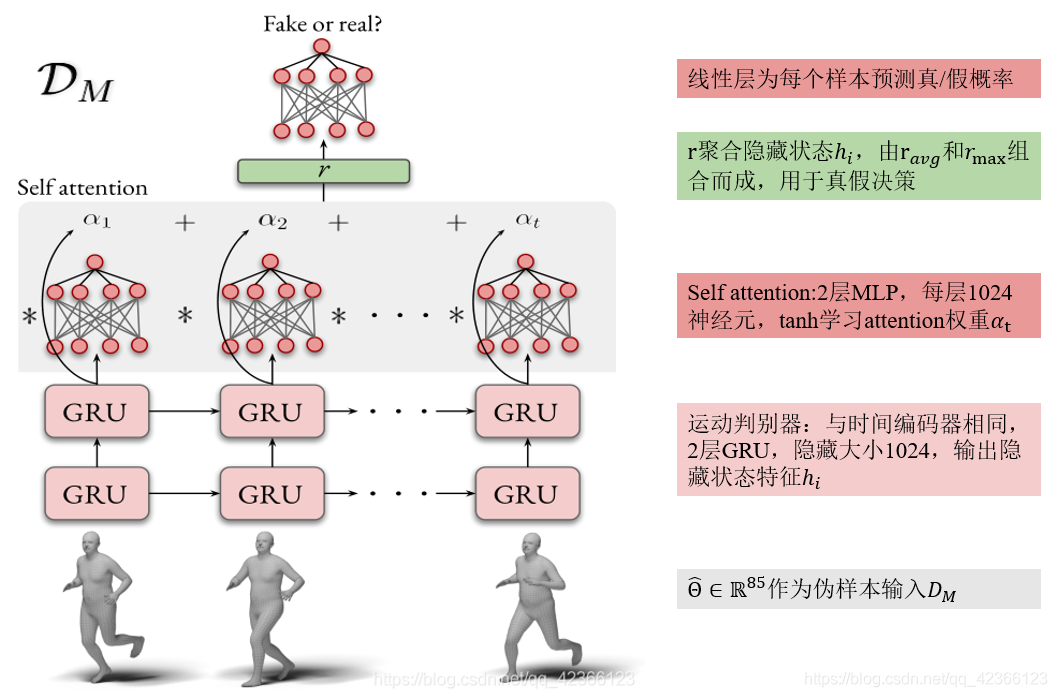
(3)其他补充
Adam优化器,g和的学习率分别为5×10−5和1×10−4。
损失函数的每个时期,使用不同的权重系数。当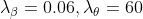 时,2D和3D关键点损失系数分别为
时,2D和3D关键点损失系数分别为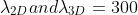 。我们将运动判别器对抗损失项设置为
。我们将运动判别器对抗损失项设置为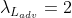 。我们使用2个GRU层,其隐藏尺寸为1024。
。我们使用2个GRU层,其隐藏尺寸为1024。
四、实验
1、数据集
- PennAction 和 PoseTrack——地面真实2D视频数据集;
- InstaVariety 和 Kinetics-400 ——2D关键点检测器标注的伪地面真实数据集;
- MPI-INF-3DHP 和 Human3.6M——3D联合标签;
- 3DPW 和 Human3.6M——提供了用于计算
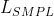 的SMPL参数;
的SMPL参数; - AMASS——用于对抗训练,以获得3D人体运动的真实样本。
2、评估指标
- PA-MPJPE——Procrustes-aligned的平均每个关节位置误差;
- MPJPE——平均每个关节位置误差;
- PCK——正确关键点的百分比;
- PVE——每个顶点误差;
- 加速度误差(mm/s2)
3、结果比较
(1)VIBE与之前最新的基于帧和时间的方法比较
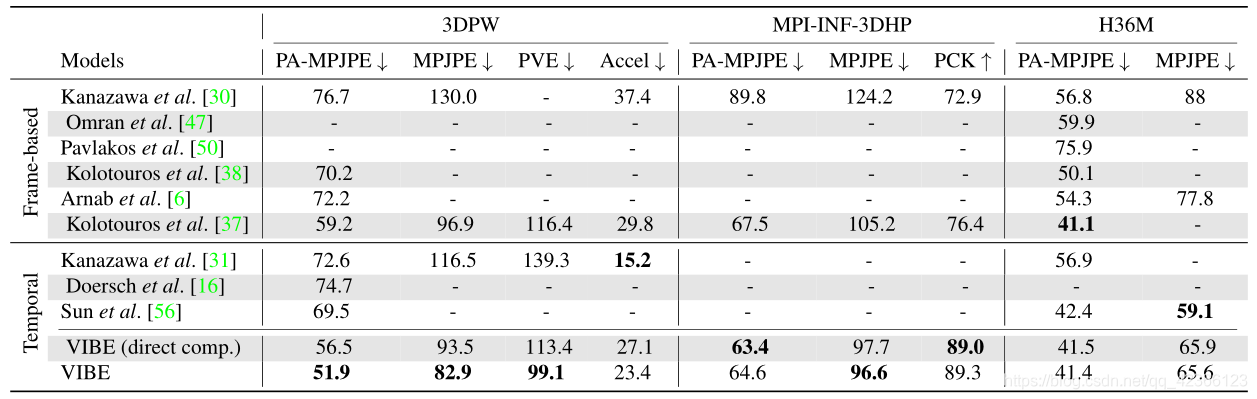
VIBE(direct comp.)是我们提出的在视频数据集上训练的模型,可以看到,VIBE在具有挑战性的户外数据集(3DPW和MPI-INF-3DHP)上优于包括SPIN[37]在内的所有最新模型,并在Human3.6M上获得可比结果。
(2)VIBE与Temporal-HMR定性比较

VIBE(顶部)和Temporal-HMR(底部)之间的定性比较。这个具有挑战性的视频包含快速运动、极端姿势和自遮挡。VIBE产生的姿势比 Temporal HMR更精确。
4、消融实验
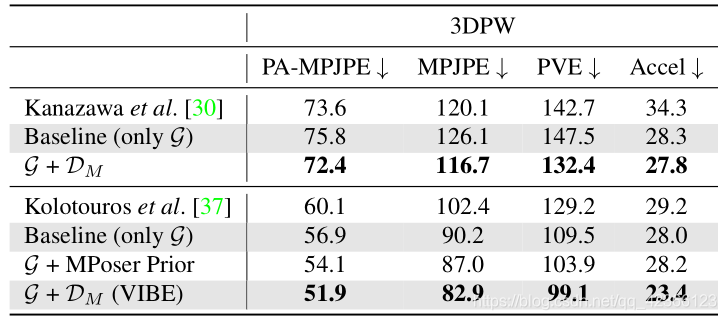
(1)运动判别器的消融实验
使用HMR[30]和SPIN[37]作为预训练的特征提取器,并将时间生成器  与
与一起添加,可以看到,只添加生成器g时,由于缺乏足够的视频训练数据,得到的结果比基于帧的模型稍差,但更平滑(Accel),加入运动判别器,有助于提高g的性能,同时产生更平滑的预测。
(2)self-attention的消融实验
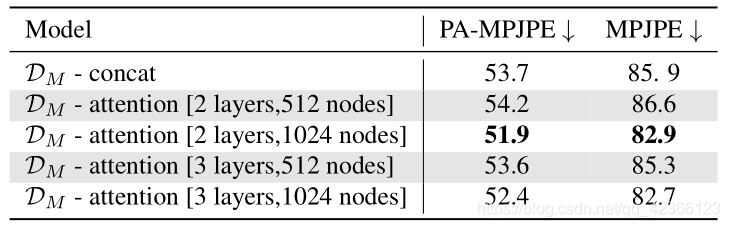
尝试了几种 self-attention的配置,并将我们的方法与静态池化(-concat)相比,可以看到,在3DPW数据集上,不同MLP层数和隐藏大小对实验结果的影响,进一步说明2层MLP网络,1024隐藏大小是最好的。
一些补充
对抗网络到底有什么作用?
开始一直没搞明白为什么需要对抗网络,也就是运动判别器,因为前面生成器g就已经可以表示出人体姿态,读到实验突然有点明白了,由于可以用于训练的数据集比较少,因此如果只采用生成器的话,训练出来的人体姿态识别精度比较低(参考运动判别器
的消融实验的baseline(only g)),所以加入
,在有限的数据基础上,通过与真实姿态比较(对抗),来进一步改善识别效果,得到更精确的人体姿态识别。(不知道理解的对不对,欢迎指正~)

















 734
734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









