







1.算法思想
算法在度量数据对象的非相似性(或者说距离)时一般使用欧几里得距离,要求每个类的聚类中心与数据对象的距离平方之和最小。用于分群与确定集群中心。
- 这里假设有J个节点,我们要将其分为2 © 个集群,并假设集群的中心为c1,c2。每个节点称为xj,j∈J,设uij为节点属于该集群的可能性。即u1j表示第j个节点到第1个集群中心c1的可能性(称为隶属值)。这里有多少个集群,对于每个节点来说就有多少个隶属值。(这里两个集群的情况下,对于节点j有u1j,u2j两个隶属值)。
同时,u1j+u2j=1。
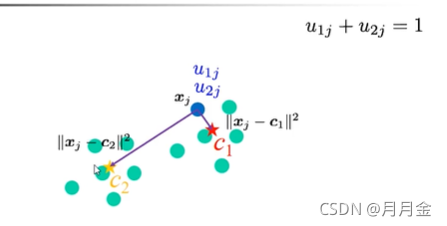
-这里由于我们希望集群内的点越近越好,集群间的点越远越好。所以根据节点隶属哪个群,主要是根据它到各节点的距离来确定。
-这里我们用uij^m ||xj-ci||2**,i∈C,j∈J,这里m控制重要性的大小,这里如果两点距离远,uij就很小(0<uij<1),令m取一个较大的值,此时**uijm ||xj-ci||^2 将会变的很小很小,可能会近似于0。
-对于每个节点,这里会计算第j个点到所有群心考虑进去
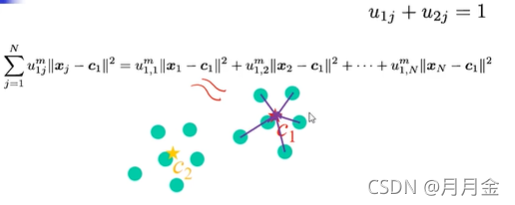
-对于所有节点,该系
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7939
7939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









