







目录
本文采用数据集为iris,将iris.txt放在程序的同一文件夹下。请先自行下载好。
模糊理论
模糊控制是自动化控制领域的一项经典方法。其原理则是模糊数学、模糊逻辑。1965,L. A. Zadeh发表模糊集合“Fuzzy Sets”的论文, 首次引入隶属度函数的概念,打破了经典数学“非0即 1”的局限性,用[0,1]之间的实数来描述中间状态。
很多经典的集合(即:论域U内的某个元素是否属于集合A,可以用一个数值来表示。在经典集合中,要么0,要么1)不能描述很多事物的属性,需要用模糊性词语来判断。比如天气冷热程度、人的胖瘦程度等等。模糊数学和模糊逻辑把只取1或0二值(属于/不属于)的普通集合概念推广0~1区间内的多个取值,即隶属度。用“隶属度”来描述元素和集合之间的关系。
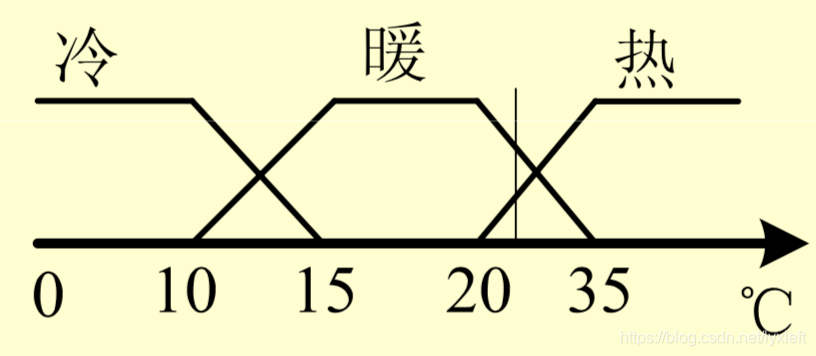
如图所示,对于冷热程度,我们采取三个模糊子集:冷、暖、热。对于某一个温度,可能同时属于两个子集。要进一步具体判断,我们就需要提供一个描述“程度”的函数,即隶属度。
例如,身高可以分为“高”、“中等”、“矮”三个子集。取论域U(即人的身高范围)为[1.0,3.0],单位m。在U上定义三个隶属度函数来确定身高与三个模糊子集的关系:
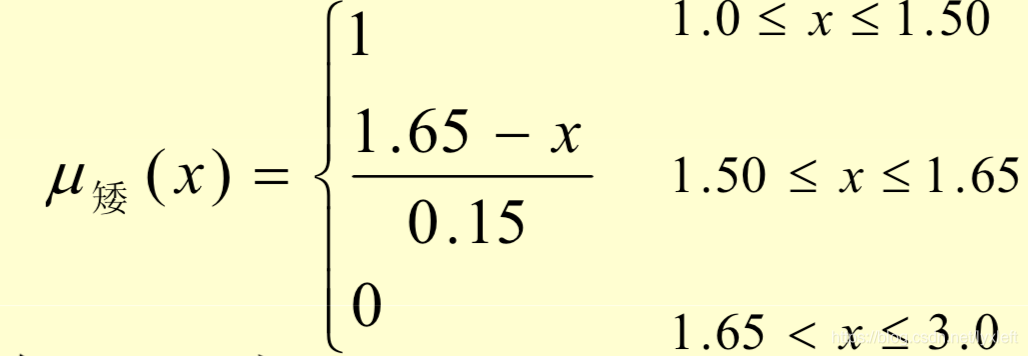
模糊规则的设定:
(1)专家的经验和知识
– 藉由询问经验丰富的专家,在获得系统的知 识后,将知识改为IF....THEN ....的型式。
(2)操作员的操作模式
– 记录熟练的操作员的操作模式,并将其整理为IF....THEN ....的型式。
(3)自学习
– 设定的模糊规则可能存在偏差,模糊控制器能依设定的目标,增加或修改模糊控制规则
Fuzzy C-Means算法原理
模糊c均值聚类融合了模糊理论的精髓。相较于k-means的硬聚类,模糊c提供了更加灵活的聚类结果。因为大部分情况下,数据集中的对象不能划分成为明显分离的簇,指派一个对象到一个特定的簇有些生硬,也可能会出错。故,对每个对象和每个簇赋予一个权值,指明对象属于该簇的程度。当然,基于概率的方法也可以给出这样的权值,但是有时候我们很难确定一个合适的统计模型,因此使用具有自然地、非概率特性的模糊c均值就是一个比较好的选择。
简单地说,就是要最小化目标函数Jm:(在一些资料中也定义为SSE即误差的平方和)
![]()
其中m是聚类的簇数;i,j是类标号;表示样本
属于j类的隶属度。i表示第i个样本,x是具有d维特征的一个样本。
是j簇的中心,也具有d维度。||*||可以是任意表示距离的度量。关于有哪些基于距离的度量,可参考我的另一篇博文《数据的相似性和相异性的度量》。
模糊c是一个不断迭代计算隶属度和簇中心
的过程,直到他们达到最优。
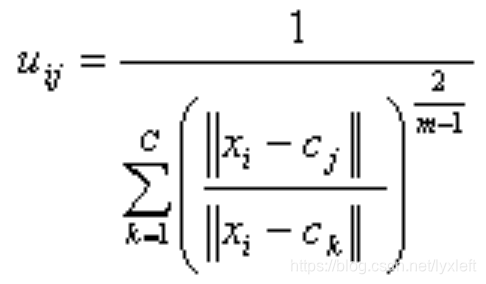 ,
,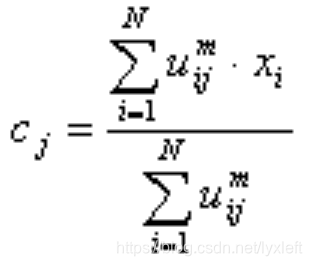
注:对于单个样本,它对于每个簇的隶属度之和为1。
迭代的终止条件为:
![]()
其中k是迭代步数,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3099
3099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









